4月から機械学習の勉強を始めて特定の人物の顔画像があればいいなと思うことがあったのでwebスクレイピングで収集することにしました。おそらく探せばそういうデータセットは見つかるとは思いますがどうせなら好きな人の顔写真でやりたいな~と思ったのがきっかけです。
openCVの顔検出だけでは顔じゃない部分が抜き出されたり関係ない人の顔画像まで集まってしまうので顔認証システムを付与して特定の人物の顔画像だけを収集するのが目的です。
プログラムを実行する前に
注意事項
webスクレイピングは色々グレーなところなので実行する場合はサーバーに負荷をかけないように十分注意して行いましょう
環境・バージョン
Winsows10
Anaconda3
Python 3.5.6
cmake 3.17.1
dlib 19.19.0
face-recognition 1.3.0
opencv-python 4.2.0.34
実行結果について
結果などは後で詳しく書きますが今回のプログラムは顔認証を用いて顔画像を収集しますが、僕が実験してみた感じ外国人の顔だとほぼ100%の精度で特定の人の顔画像が得られましたが、日本人の顔(というかアジア人)だとそこそこ精度が落ちてしまいます。日本人の顔を収集するときは実行後に手動で選別する必要があります。
プログラム使用方法
プログラムコードはgithubに公開したのでそこからダウンロードしてください。
「説明なんかいいから実行したい」って人はgithubに簡単な手順が書いてあるのでそれを読んで実行してください
今回は日本で一番かわいい篠崎愛ちゃんの顔画像を収集したいと思います
ライブラリをインストール
今回はface_recognizeというライブラリを使います。これはドキュメントに書いてあるようにcmakeとdlibが必要です。あとは必要なライブラリを入れるだけです。
主な関数の説明
getExternalLinks
def getExternalLinks(page):
externalLinks = []
for url in search(name, lang="jp", start=(page-1)*10, stop=10,pause = 2.0):
externalLinks.append(url)
return externalLinks
google-searchのライブラリを用いて検索ワードで出てきたサイトのURLを10個取得して返す関数です。今回は検索ワードを「篠崎愛 画像」とし、変数nameに格納。
DownloadImage
先ほどの関数で得られたリンクから実際にアクセスし、そこにアップされている画像を取得します。
def DownloadImage(externalLinks):
for url in externalLinks:
global num
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.3'}
req = Request(url, headers=header)
try:
html = urlopen(req).read()
except HTTPError as err:
return None
bs = BeautifulSoup(html, 'html.parser')
#get path of image
downloadList = bs.find_all('img')
for download in downloadList:
try:
#convert relative path to absolute path
fileUrl = getAbsoluteURL(url, download['src'])
except:
continue
if fileUrl is not None:
#get all faces in the picture
face_list = face_detect(fileUrl)
print(fileUrl)
if face_list is None:
continue
for face in face_list:
#judge face
result = face_recog(face)
true_num = 0
#when the number of True is more than the threshold, write the image in local
for i in result:
true_num += i*1
if true_num >= threshold:
try:
if ".png" in fileUrl:
cv2.imwrite(downloadDirectory+str(num)+".png", face)
else:
cv2.imwrite(downloadDirectory+str(num)+".jpg", face)
num += 1
except:
print("Fail to save")
time.sleep(1)
return None
まず、サイトにアップされている画像をすべて取得し、それぞれから顔画像を切り取り、取得します。そしてその顔画像に対して本人であるかどうかをface_recog関数で定義しています。
face_recog
def face_recog(face):
#load some images that contain target's face
sample_image = face_recognition.load_image_file("sample_image/<image file>")
sample_image1 = face_recognition.load_image_file("sample_image/<image file>")
sample_image2 = face_recognition.load_image_file("sample_image/<image file>")
sample_image3 = face_recognition.load_image_file("sample_image/<image file>")
sample_image4 = face_recognition.load_image_file("sample_image/<image file>")
sample_image = face_recognition.face_encodings(sample_image)[0]
sample_image1 = face_recognition.face_encodings(sample_image1)[0]
sample_image2 = face_recognition.face_encodings(sample_image2)[0]
sample_image3 = face_recognition.face_encodings(sample_image3)[0]
sample_image4 = face_recognition.face_encodings(sample_image4)[0]
try:
unknown_image = face_recognition.face_encodings(face)[0]
except:
return [False]
known_faces = [
sample_image,
sample_image1,
sample_image2,
sample_image3,
sample_image4
]
results = face_recognition.compare_faces(known_faces, unknown_image)
return results
顔認証をするためにあらかじめ取りたい人の顔が映っている画像を取得します。今回は精度を上げるため5枚取得し、それぞれと入力である顔画像を比較しそれぞれの結果を返します。
そして今回は5枚中2枚以上Trueである場合その画像を保存することにします。(1枚だとたまたまマッチした違う人が保存され、5枚中5枚とかだと精度は上がりますがその分数が少なくなります)
そしてgithubのほうでは最後に全く同じの画像を削除する処理も入れてます。
結果
篠崎愛ちゃんの場合
google検索1ページ分のサイトを対象に画像を収集した結果がこちらです。

見ての通り結構違う人の顔画像が保存されているのがわかります。
Scarlett Johanssonの場合
続いて海外で一番セクシーで綺麗なScarlett Johanssonで実験してみます。
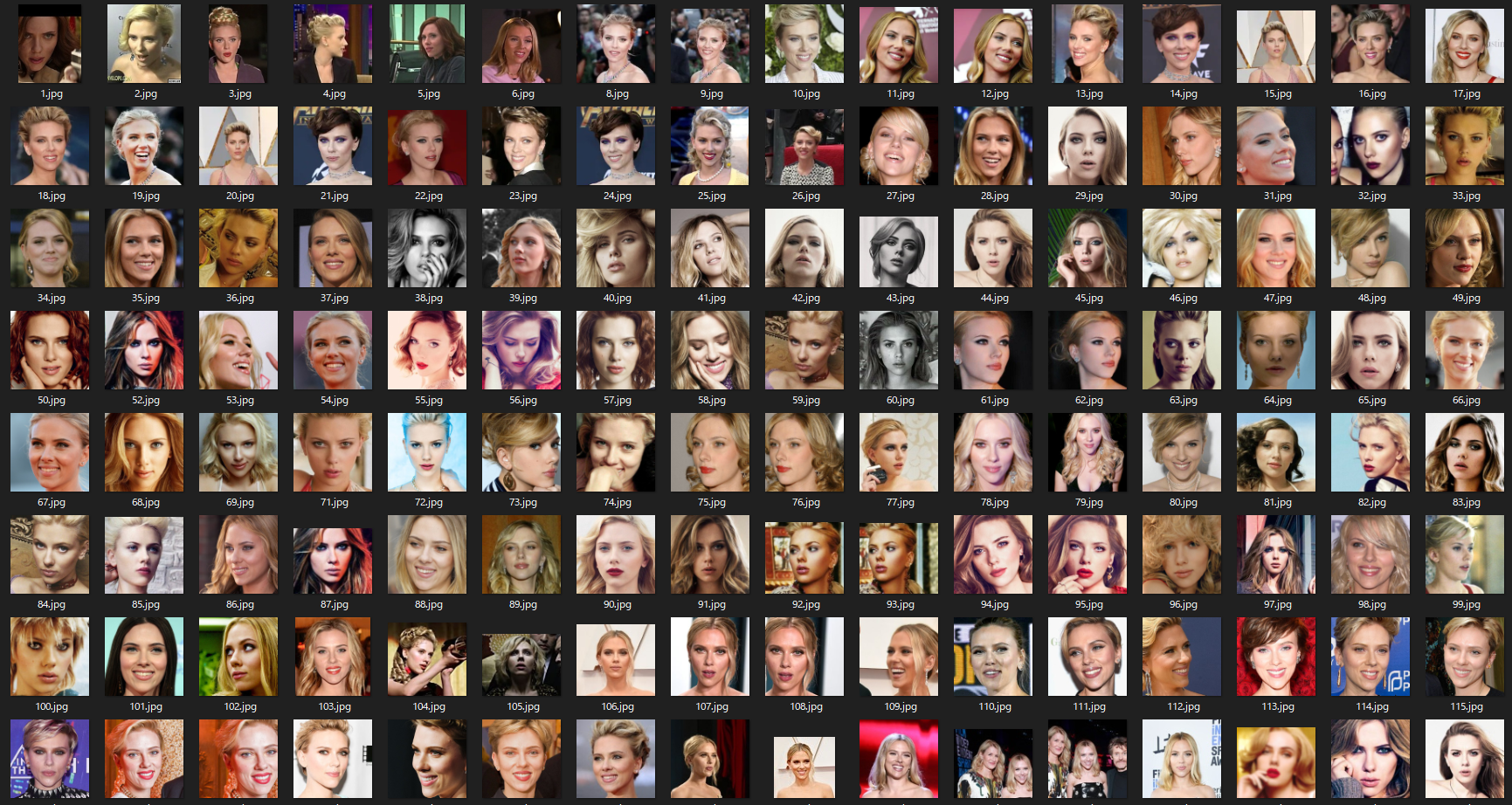
こちらは見事にScarlett Johanssonで埋め尽くされ,
具体的には343枚中342がScarlett Johanssonでした。これは篠崎愛ちゃんの時に比べかなりの精度です。たぶんですがface_recongnizeライブラリは海外の人の顔向けでアジア人の顔を識別するのは向いてないのかな~という感じでした。
今後色々な人で実験して試してみたいと思います