はじめに
PilotPDGのPython TOPsを使ってどういったことが出来るか…、の前に、どういったPython関連ノードがあるかをリストして、それぞれの機能と役割を比べてみるというもの。
やはり、Pythonで色々と分類分けができるのは、書きやすいということもあれば、ツールとしてまとめやすいのもあるので、今のうちにまとめておこう!とうのが動機。
気づきがあれば、また追記したりします。
Houdini 17.5.173
Pilot PDG 17.5.173
Python Nodes
現状は以下のPython系のTOPsノードがある。
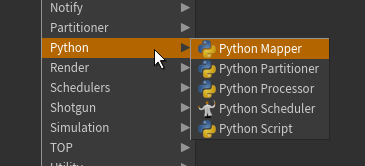
- Python Script
- Python Processor
- Python Mapper
- Python Partitioner
- Python Scheduler
Python Script
基本的に、Pythonの処理機構はこのノードに書いていく、ベースとなるノード。
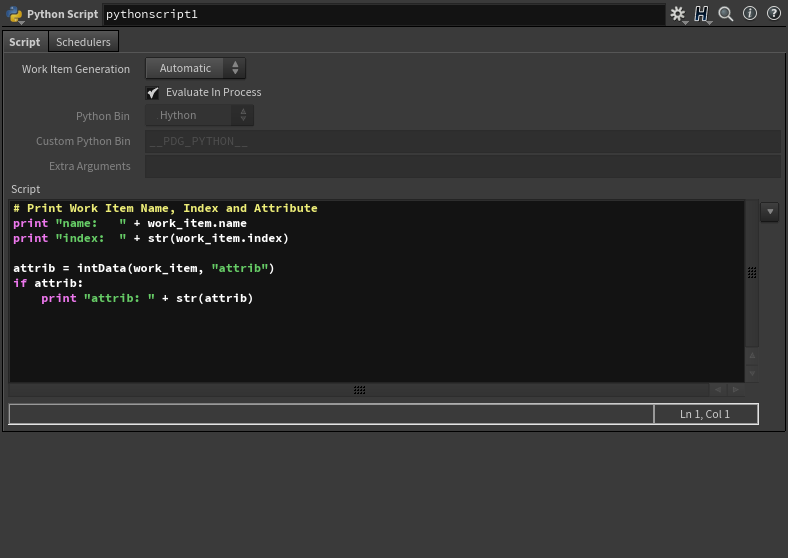
Python Bin
デフォルトでは Hython が指定されているが、これを Custom にすると、下の Custom Python Bin と Extra Arguments が有効になる。
ここで、 Custom Python Bin にPython3の実行バイナリのパスを指定してあげると、スクリプトを指定した実行バイナリで処理ができる。
つまり、Python3もここで使うことができる。
しかしながら、Houdiniの基本プロセス上ではPython 2.7用のモジュールパスが通ってしまっているので、環境変数の再設定が必要。
ここら辺に関しては別途まとめる。
まとめた。
-> Procedural Dependency GraphでPython3を使う
Python Processor
Python Scriptと役割は同じだが、Python APIを使用してプロセスをカスタムする場合のノード。
プロセスの処理順などをこのノード内でやってのける。つまり、独自にディペンデンシーを組んだりとかが出来る。
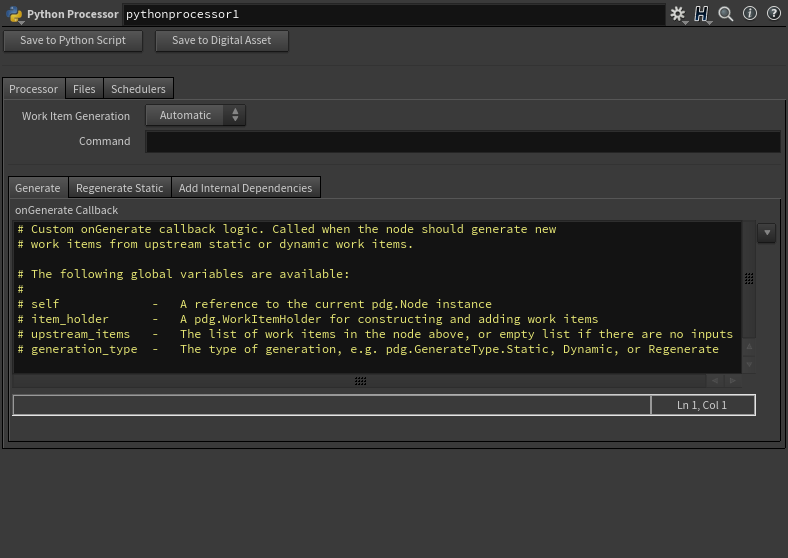
サンプルコード
for upstream_item in upstream_items:
item_holder.addWorkItem()
item_holder.addWorkItem()
item_holderを上流工程の数に応じて二回ずつ登録していく。
dependency_holder.addDependency(internal_items[1], internal_items[0])
0番目に対して、1番目を依存させる。といったディペンデンシーを組む。
Python Partitioner
Partition by ExpresionのPython版。
アトリビュートに応じて分類わけを行って、順々に処理をスケジューリングしたい場合といったアトリビュート等のレベルでのプロシージャル性を担保したい上で使う感じ。
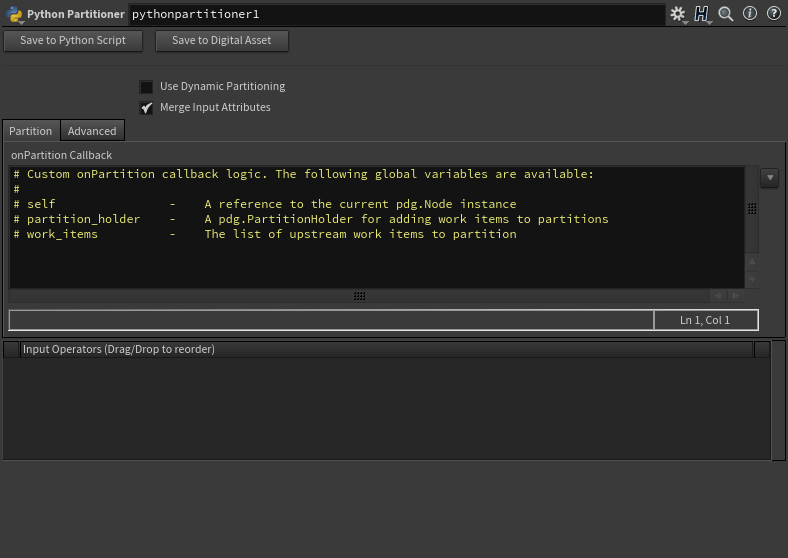
サンプルコード
for work_item in work_items:
if not work_item.data:
continue
attrib = work_item.data.intData("attrib", 0)
if not attrib:
attrib = 0
partition_holder.addItemToPartition(work_item, attrib)
上流工程のworkアイテムのそれぞれに対して、"attrib"アトリビュートが存在するかをチェック。
存在しない場合には"attrib = 0"グループとして分類する。
以下の選択しているindexはそれぞれ"attrib"の値 0〜4 を持っているが、2つの入力(attributecreate)に対して、 "attrib" の値に応じて分類分けをしている感じ。
下流工程で、この分類分けを利用して個別に処理をかけることが可能。
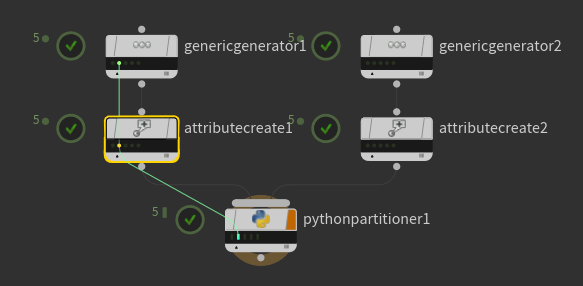
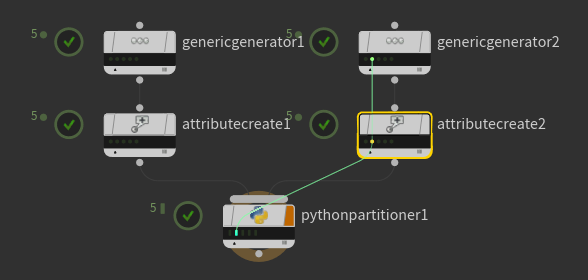
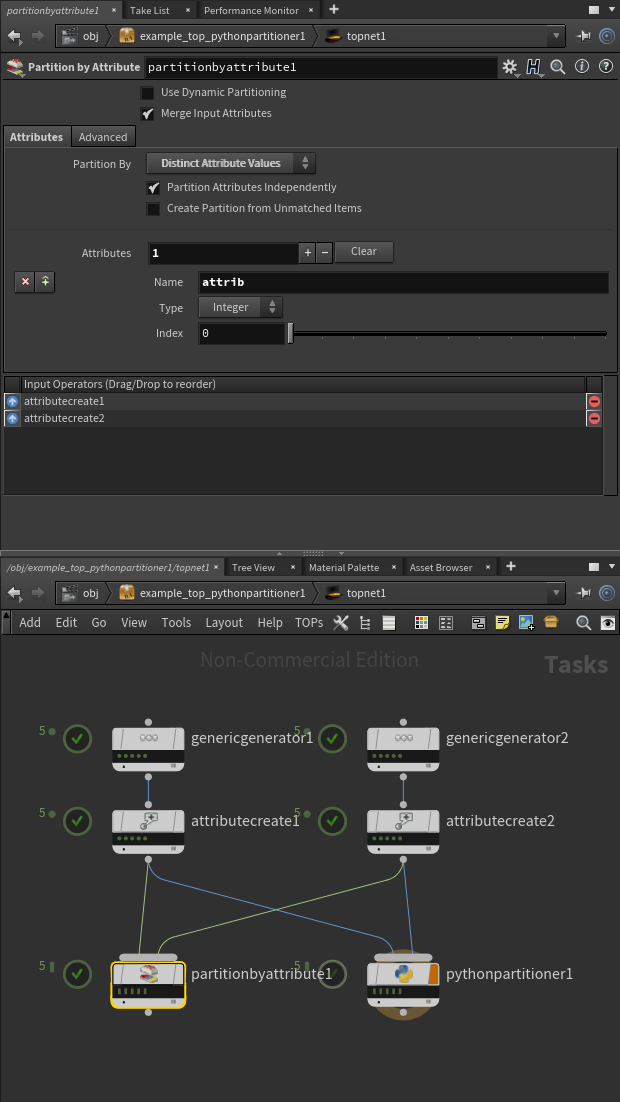
Partition by Attributeでやる場合はこんな感じで、これをPythonでやった場合が上記
Python Mapper
Map by Expression TOPノードのPython版。
Partitionerとの違いは、Partitionerは上流工程をもとに分類わけを行い下流工程で使用する、いわゆる明示的なプロシージャルを前提とした使い方だが、Mapperの場合はまったく別で、上流工程からの処理の流れはほしいが、Mapperの上流と下流でのプロシージャル性を担保するものではない処理を接続する目的で使う。
実際のところ、用途的には上流と下流の処理回数を分裂させたいのに使うだけなので、Python Mapper使わなくても(そもそもMap by Expressionも使うケース少ないかも)、Map by Rangeで繰り返し回数をコントロールするので良さげ ![]()
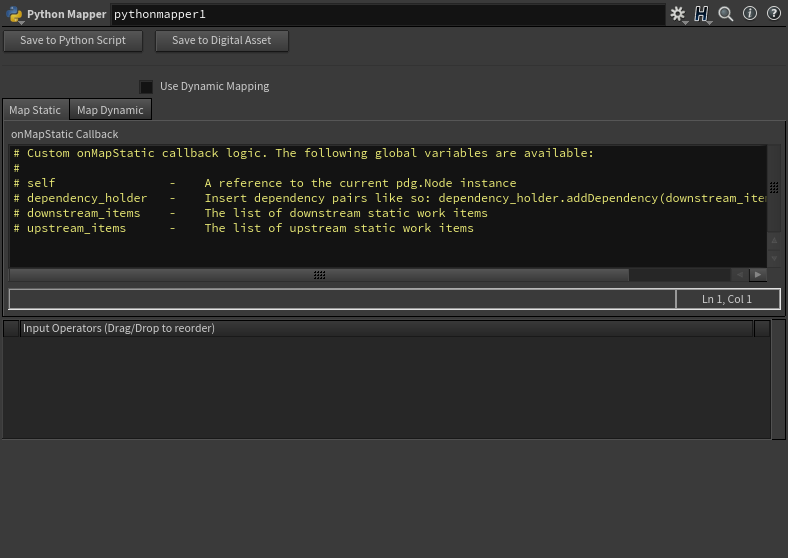
サンプルコード
for us_item in upstream_items:
for ds_item in downstream_items:
if us_item.index == ds_item.index:
dependency_holder.addDependency(ds_item, us_item)
上流と下流工程のindexを比較し、それぞれによってディペンデンシーの分類分けを行っている。
ディペンデンシーがある場合
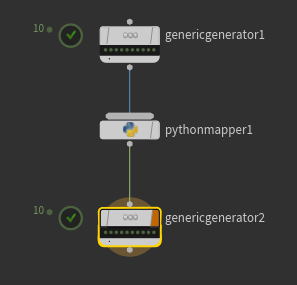
ディペンデンシーがない場合
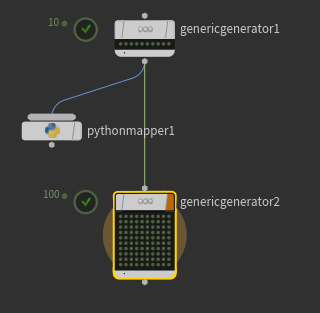
ディペンデンシーがないと、上流indexに応じて毎度繰り返しを行ってしまう。
上流の情報はほしいが、下流の工程で、上流工程のindexにかかわらず任意のindex分つくたい場合に使う感じ。
Python Scheduler
デフォルトのLocal SchedulerをPythonでカスタムできるようにしたもの。
用途としては、(DeadlineやHQueueなど用意されているもの以外の)レンダーファームに投げる処理を書く場合、こちらでJOB登録の処理などを記述することでカスタムのPDG処理が書ける。
このSchedulerは、Pythonファイルへの書き出しが可能で、デフォルトでは /home/houdini17.5/pdg/typeの下に保存され、Houdiniの起動時に認識される。つまり、新しいPython Schedulerを作成した場合は、Houdini(or Pilot PDG)の再起動が必要。
一つ注意点なのが、このノード、現在Houdini ApprenticeのTOPネットワーク上では作れない。
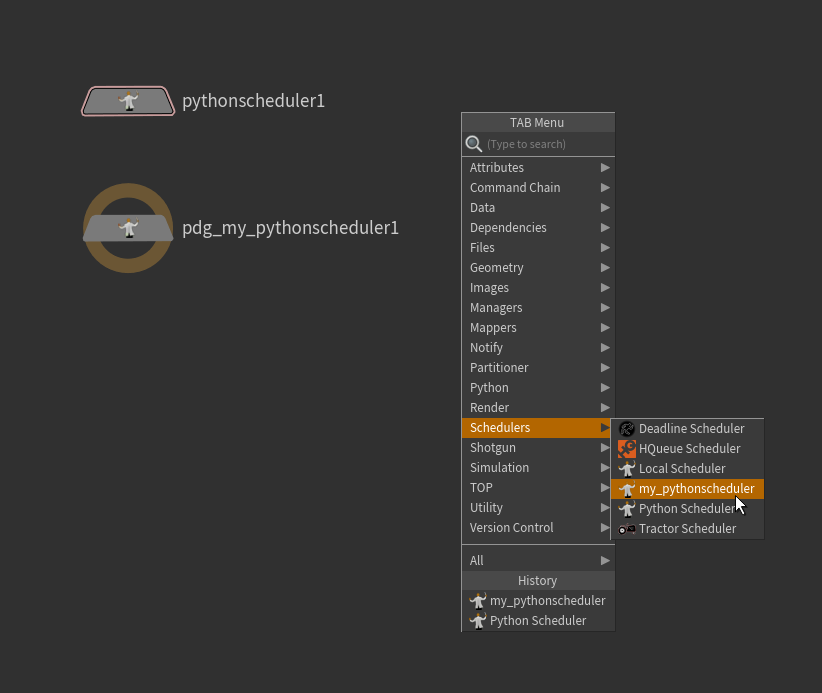
Python Schedulerを使って、カスタムのSchedulerを作る
-
Python Schedulerで、Save to Python Scripotを実行する。
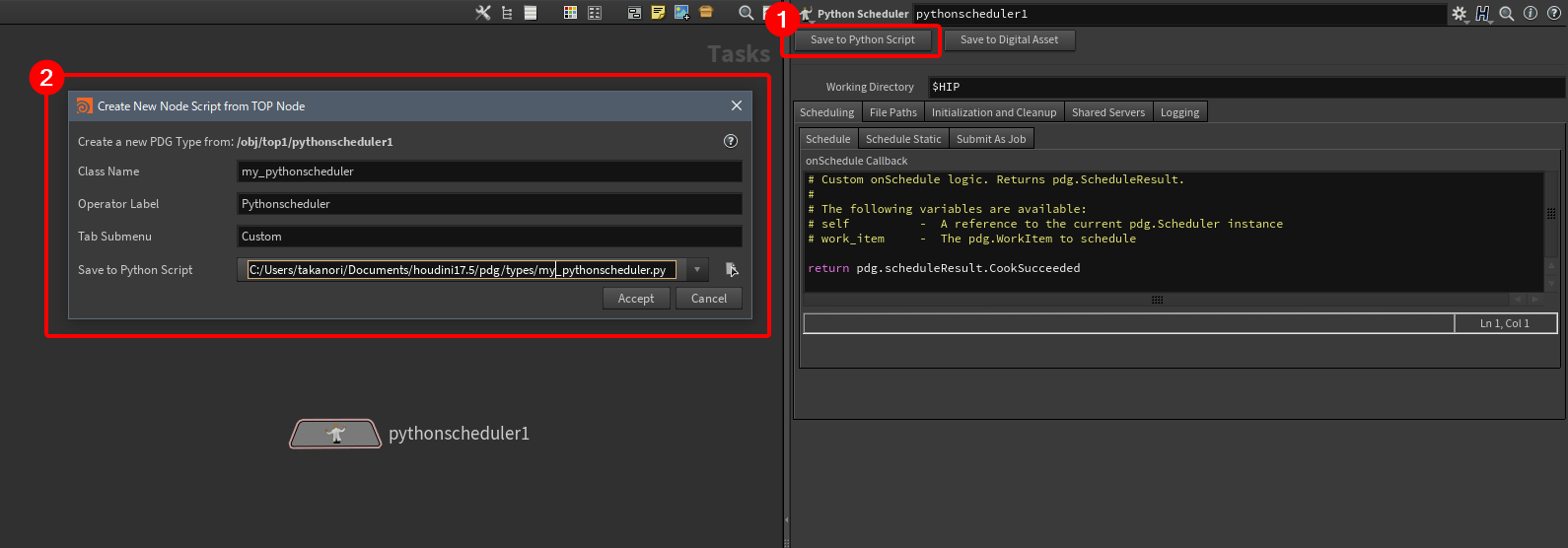
-
ダイアログから必要項目を設定し、ホームディレクトリ(Windowsだとドキュメントディレクトリ内)から、houdini17.5/pdg/typeの下に保存する。
-
Houdiniを再起動する。
-
Tabメニューで作成したSchedulerを作成する。
Python系TOPsでのPythonスクリプトの書き方
Python系TOPsでは、それぞれグローバル変数を持っており、あらかじめ定義されている。
定義されているグローバル変数は、Pythonのコードブロックにも書かれているが、ドキュメントにも使い方が記載されているので、そこを読むのも良い。
例えば、Python Processorだと、以下のようなものが記載されている。
# Custom onGenerate callback logic. Called when the node should generate new
# work items from upstream static or dynamic work items.
# The following global variables are available:
#
# self - A reference to the current pdg.Node instance
# item_holder - A pdg.WorkItemHolder for constructing and adding work items
# upstream_items - The list of work items in the node above, or empty list if there are no inputs
# generation_type - The type of generation, e.g. pdg.GenerateType.Static, Dynamic, or Regenerate
なので、使う際には、
for upstream_item in upstream_items:
new_item_index = upstream_item.index * 5
item_holder.addWorkItem(index=new_item_index)
といった感じで使う。
突然、 upstream_items といった感じで、そのコードブロック内での明示的な宣言は記述しないが、グローバル変数として暗示的に宣言されているので使えるといった感じ。
ちなみに、Callbackの種類によってグローバル変数の種類に変動があるため、そこはドキュメント必読。