
日本でコロナウイルスの感染が確認されてから、半年以上経ちましたが、未だにコロナ関連の報道が止むことはありません。
毎日のように「東京都で新たに〇〇人の感染確認」などと報道されていたり、最近では北海道の感染者数が増加傾向と言われたりもしています。しかし、日本では実際にコロナウイルスの感染が拡大しているのでしょうか。
実は自分の手でデータを使ってこういった疑問に答えていくことができます。というのも世界中のコロナウイルスに関するデータは誰でも簡単に取得できるようになっているため、日本を含む世界で起きている状況はすぐに確かめることができるのです。
しかし、ここで大きな問題がたち塞がります。せっかく手にしたデータは多くの場合、可視化したり分析したりするために適した形になっていません。そこで、様々な手法を使ってデータをきれいにし、可視化そして分析しやすい形に整えていく必要があります。
こうした一連の作業をデータラングリングと呼びます。
データサイエンスというと、機械学習などを思い浮かべがちですが、実はデータサイエンスの作業にかかる時間の80%はこの「データラングリング」に費やされていると言われています。
それでは、ここで簡単な例として、世界で最も使用されているジョンズホプキンス大学(JHU)のコロナウイルスのデータを取得し、そのデータをデータラングリングして整えたり加工することで以下の3つの質問に答えてみたいと思います。
- コロナウイルスによる死亡者数は増加しているのか?
- もしそうならどの国で増加しているのか?
- 日本は他の国と比べて死亡者数は多いのか?
データはこちらからダウンロードすることができます。
この記事の中で使っているツールはExploratoryというデータサイエンスのUIプロダクトです。(ちなみに、私はそのExploratoryでカスタマーサクセスを担当しています。)
コロナウイルスによる死亡者数は増加しているか?
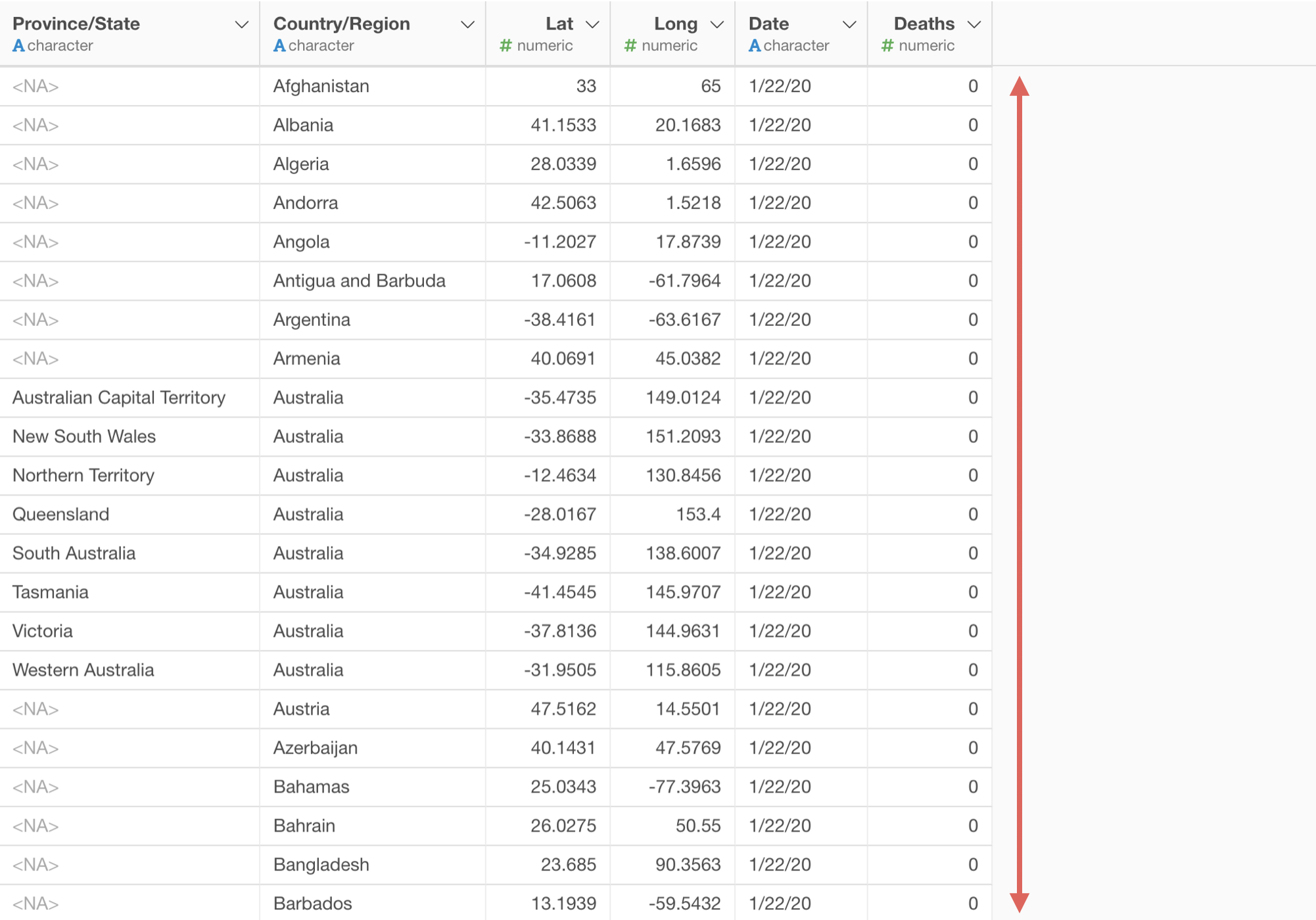
このデータは1行が1ヵ国のデータとなっており、1日ごとに列があるデータです。
例えば、世界の死亡者数の推移をラインチャートを使って可視化したいとします。
多くの可視化ツールで同じように、X軸に日付を割り当てようとしても、1日単位で列があるデータでは一つの列しか選べないためうまく可視化ができません。
実はデータにはワイド型とロング型の2つの持ち方があります。
今回のデータのように値の列が横長になっているデータのことをワイド型と言います。
値の列が一列にまとまっている縦長のデータのことをロング型と言います。
データ分析にはロング型のデータが適していると言われています。なぜなら、ロング型のデータでは一つの列を一つの変数として使うことができ、チャートなどで扱いやすくなるからです。
Exploratoryでは、ロング型にしたい列を選んだ状態で、列ヘッダメニューからワイド型からロング型へを簡単に呼び出して使用できます。
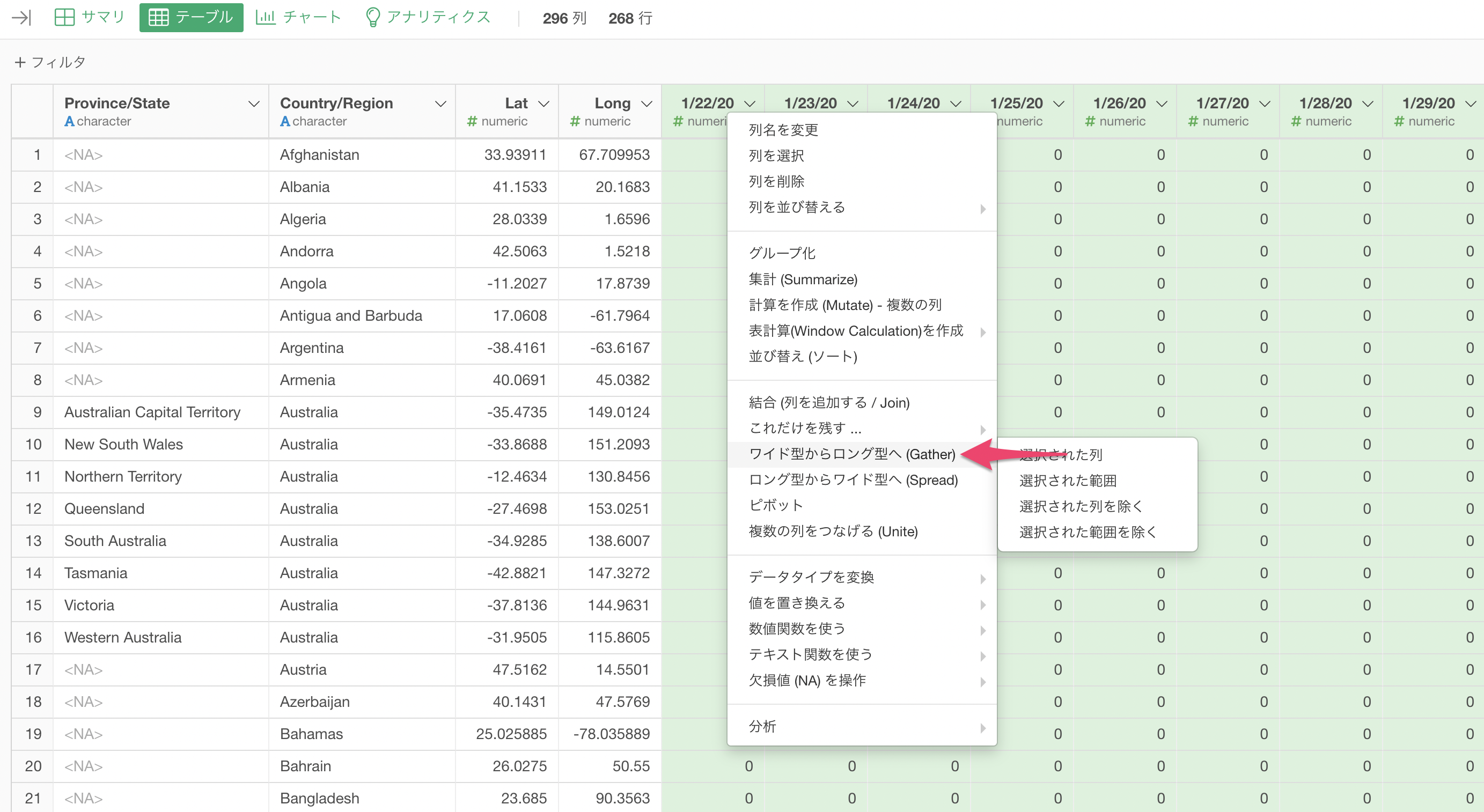
ワイド型からロング型へのダイアログが表示されるため、列名を指定して実行するだけです。
これにより、日ごとに列があるワイド型のデータを、日付と死亡者数をそれぞれ一つに列にまとめたロング型のデータにすることができます。
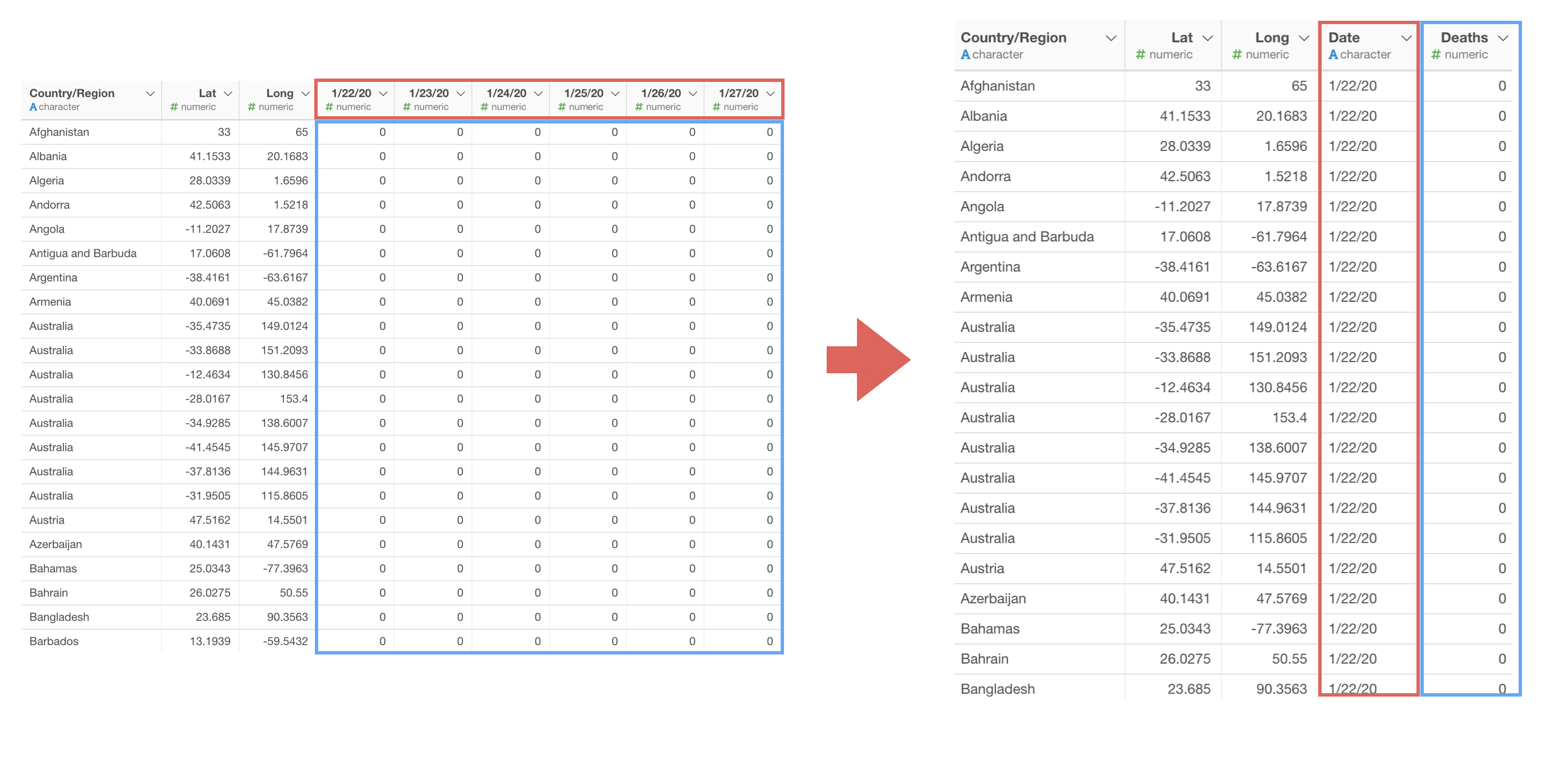
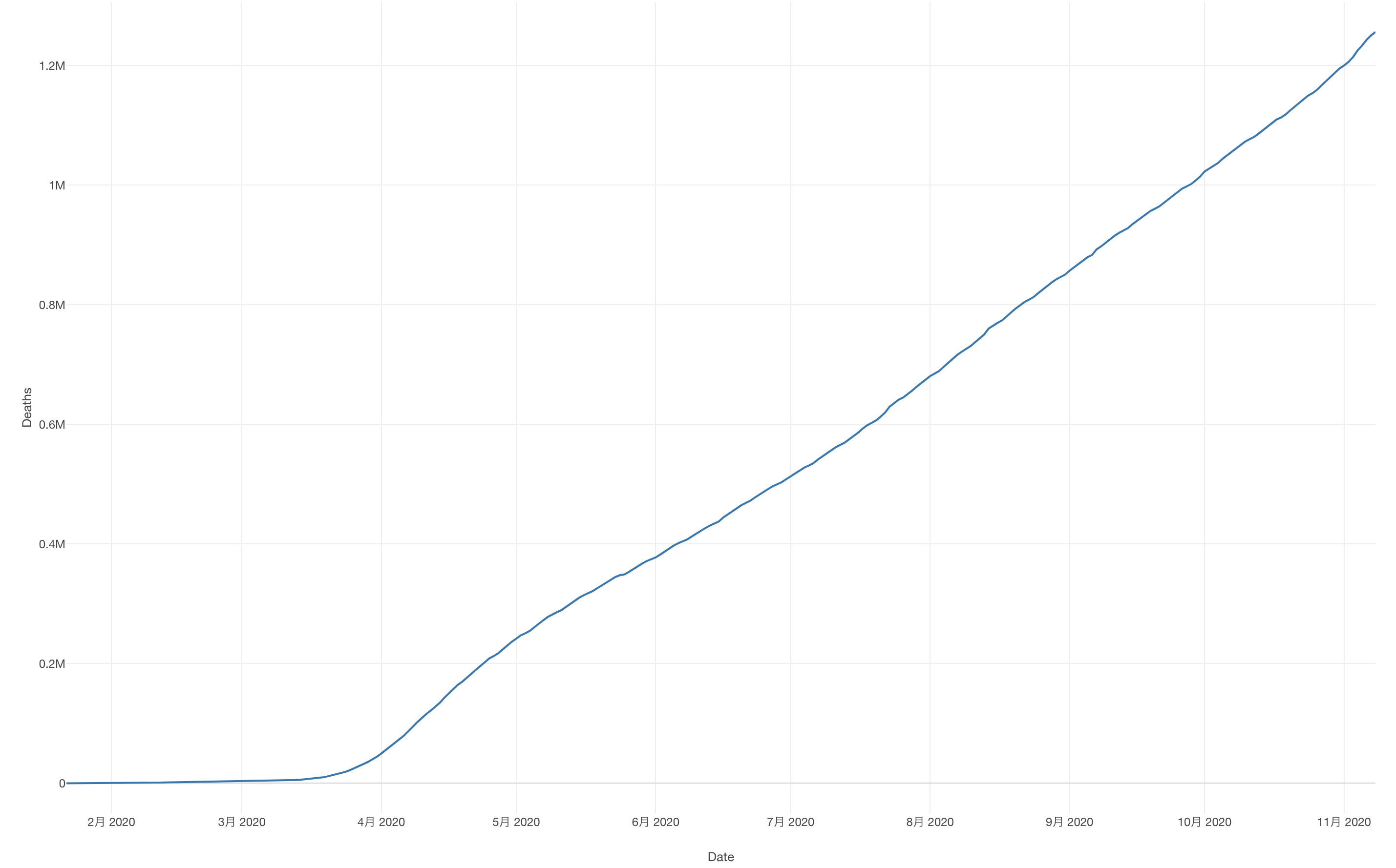
あとは、ラインチャートのX軸に日付の列を、Y軸に死亡者数の列を割り当てることで、死亡者数の推移を可視化できます。
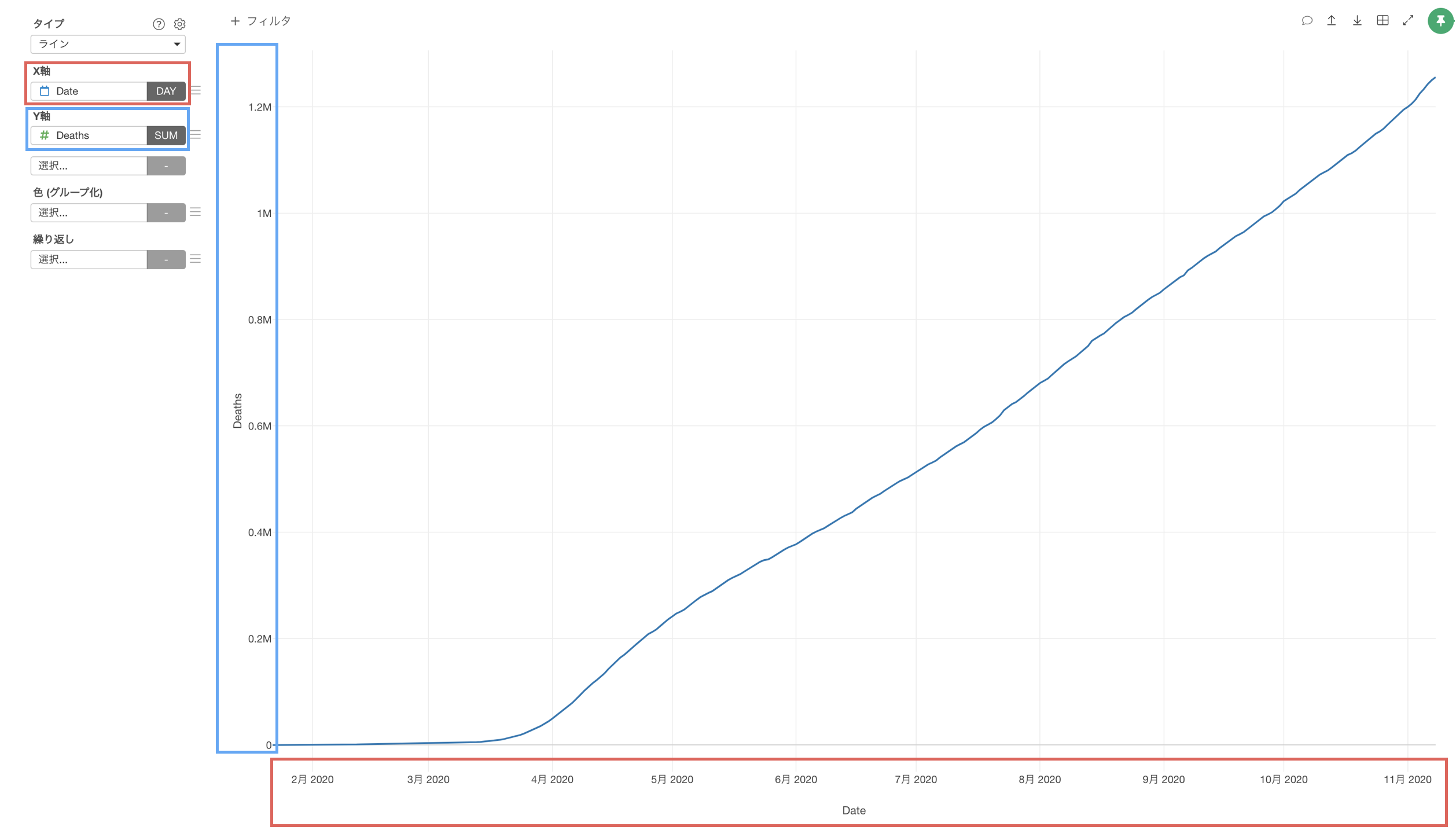
世界的に見ると、死亡者数は現在も増えており、11月の時点で120万人を超えているようです。
どの国で死亡者数が増加しているのか?
どの国で死亡者数が増加しているのか見る際に、Exploratoryでは色(グループ化)に国の列を割り当てることで、国(グループ)に分けて死亡者数の推移を可視化することができます。
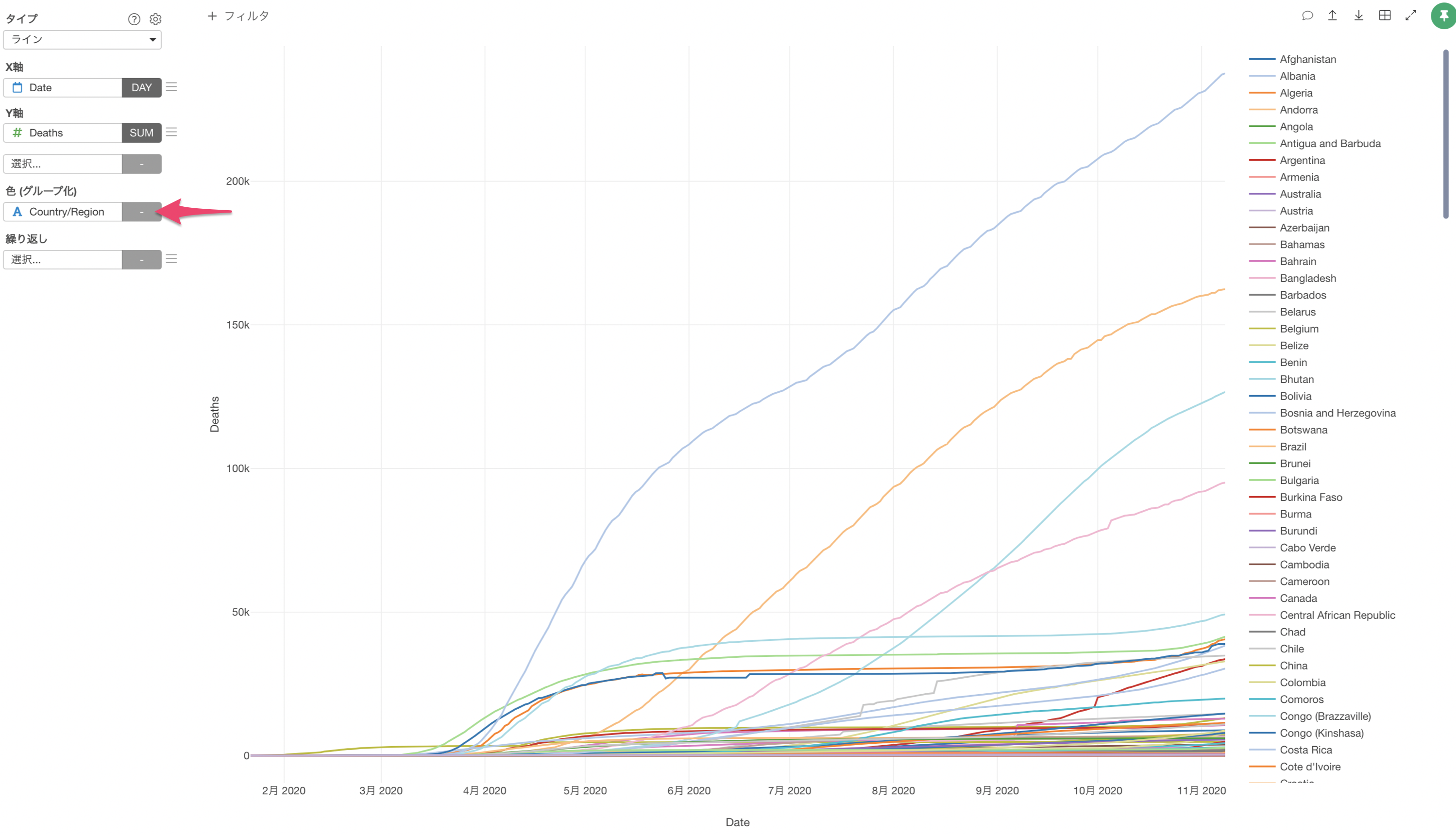
しかし、このチャートには一つ問題点があります。多くの国では、死亡者数が1万人に達しておらず、死亡者数が多い国に注目したい時には余計な情報になってしまうことです。
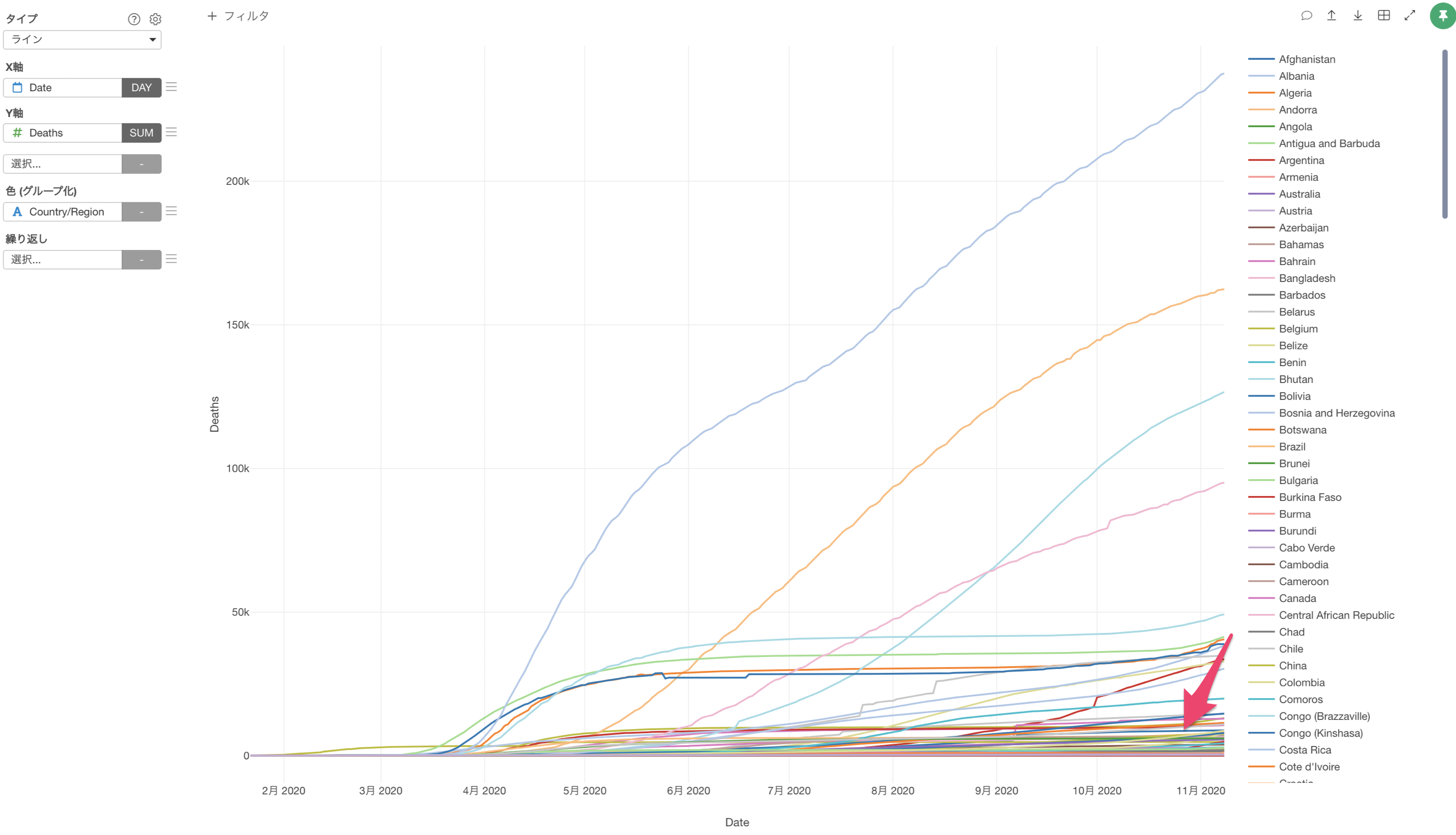
死亡者数が多い国だけのトレンドを見るためには、死亡者数が多い上位Nヵ国のデータのみを残すという加工が必要になります。
1行が国ごとに1日単位で分かれているデータでは、単純にフィルタで死亡者数が多い国にすることはできません。
今回は簡単にできる方法として、チャートにある表示する値の制限という機能を使用します。チャートから使用できますが、裏ではデータを加工・集計してくれています。
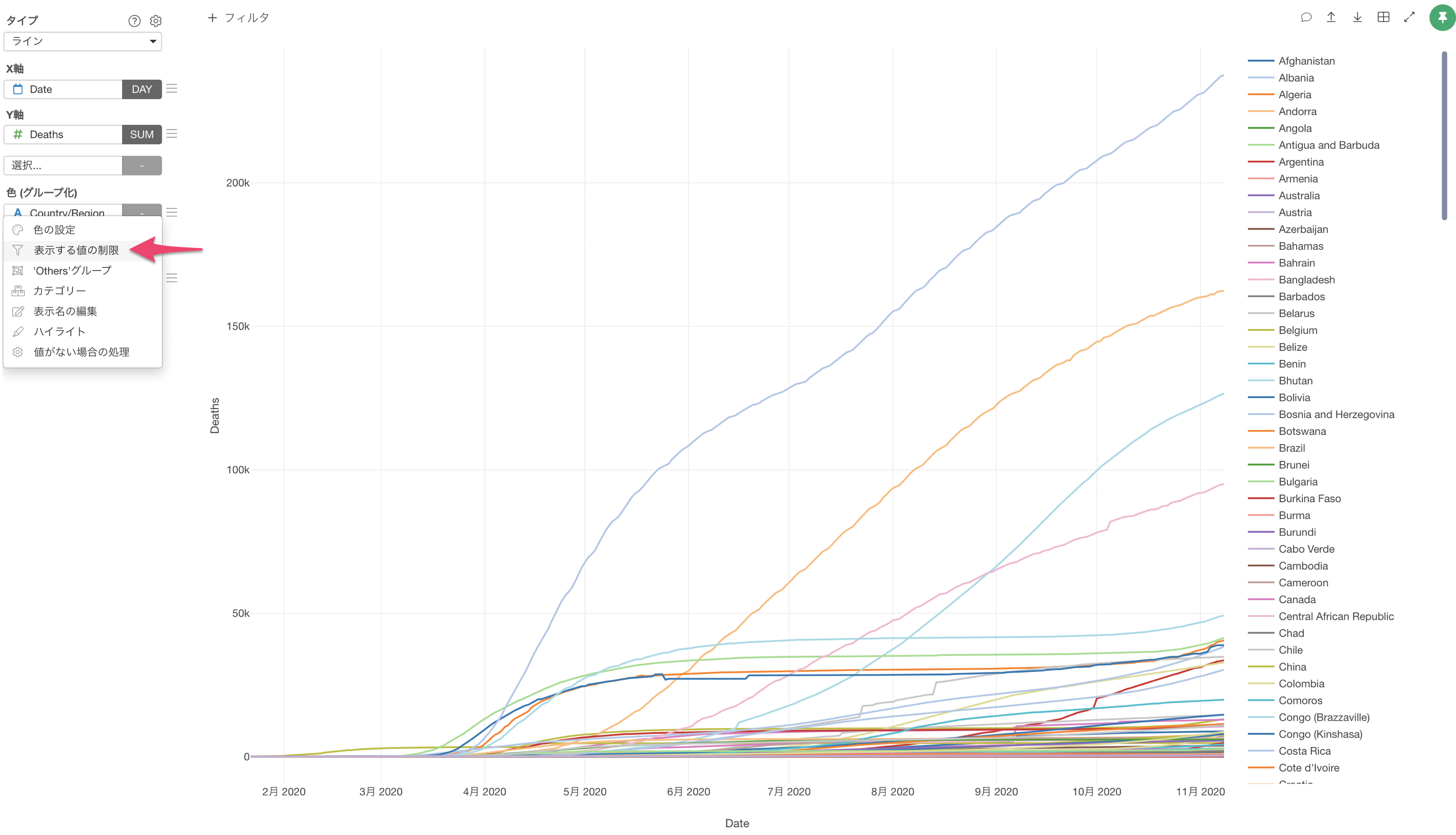
表示する値の制限では、死亡者数の最大値の上位20のグループのみを残すという設定をしています。
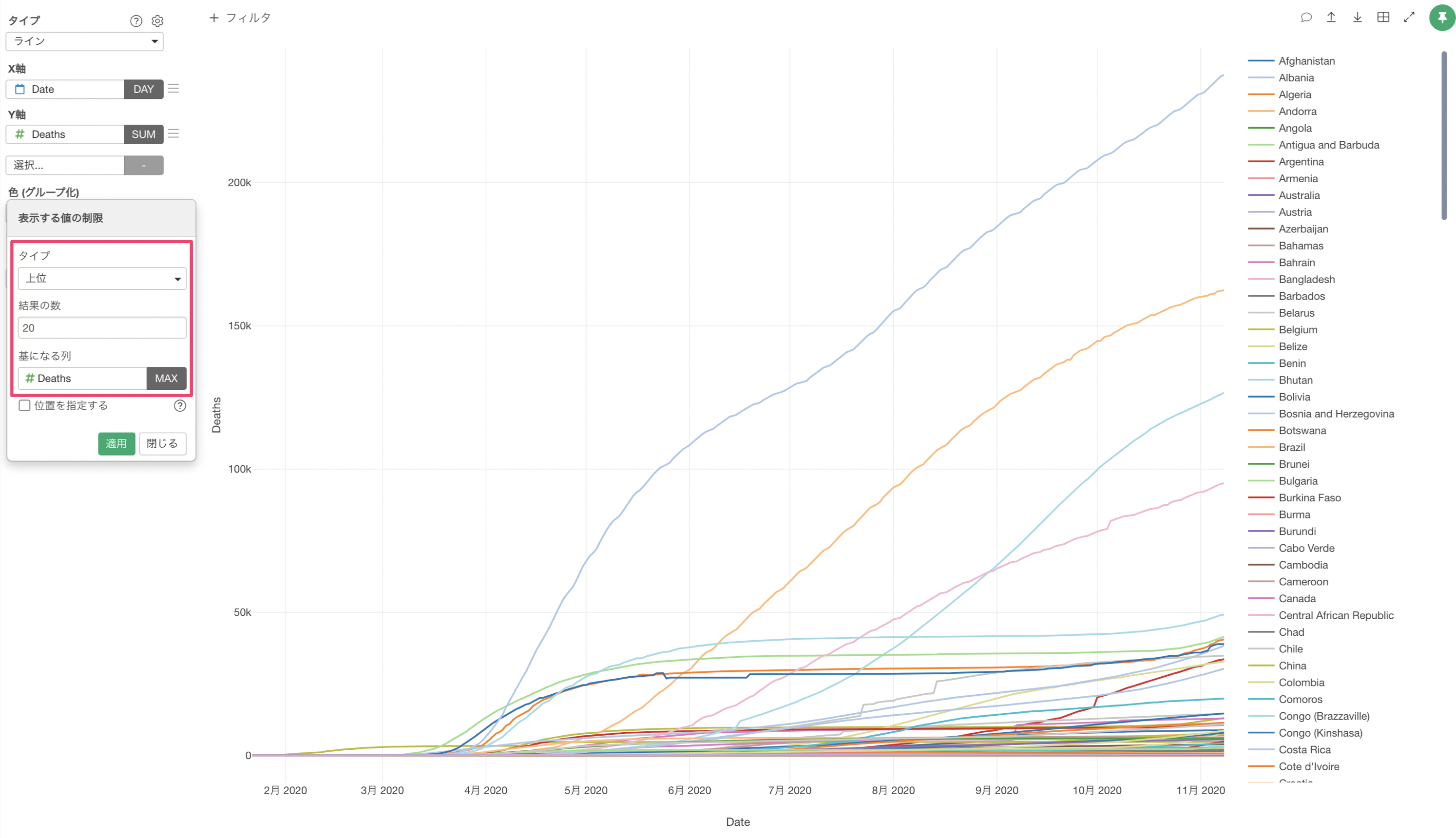
死亡者数が多い上位20ヵ国のみで可視化することができました。
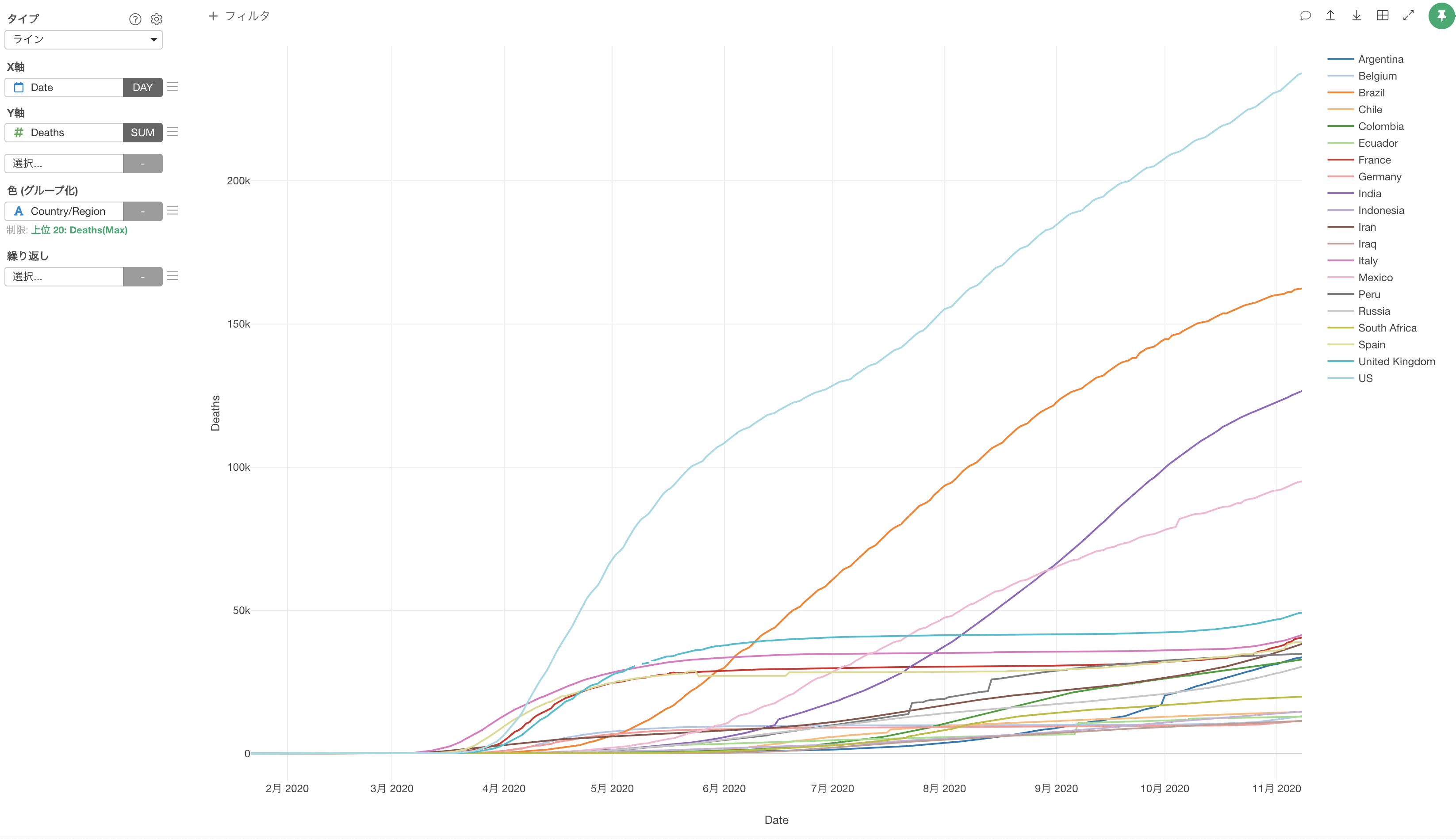
アメリカ、ブラジル、インド、メキシコは死亡者数が多く、現在も増加していることが確認できます。
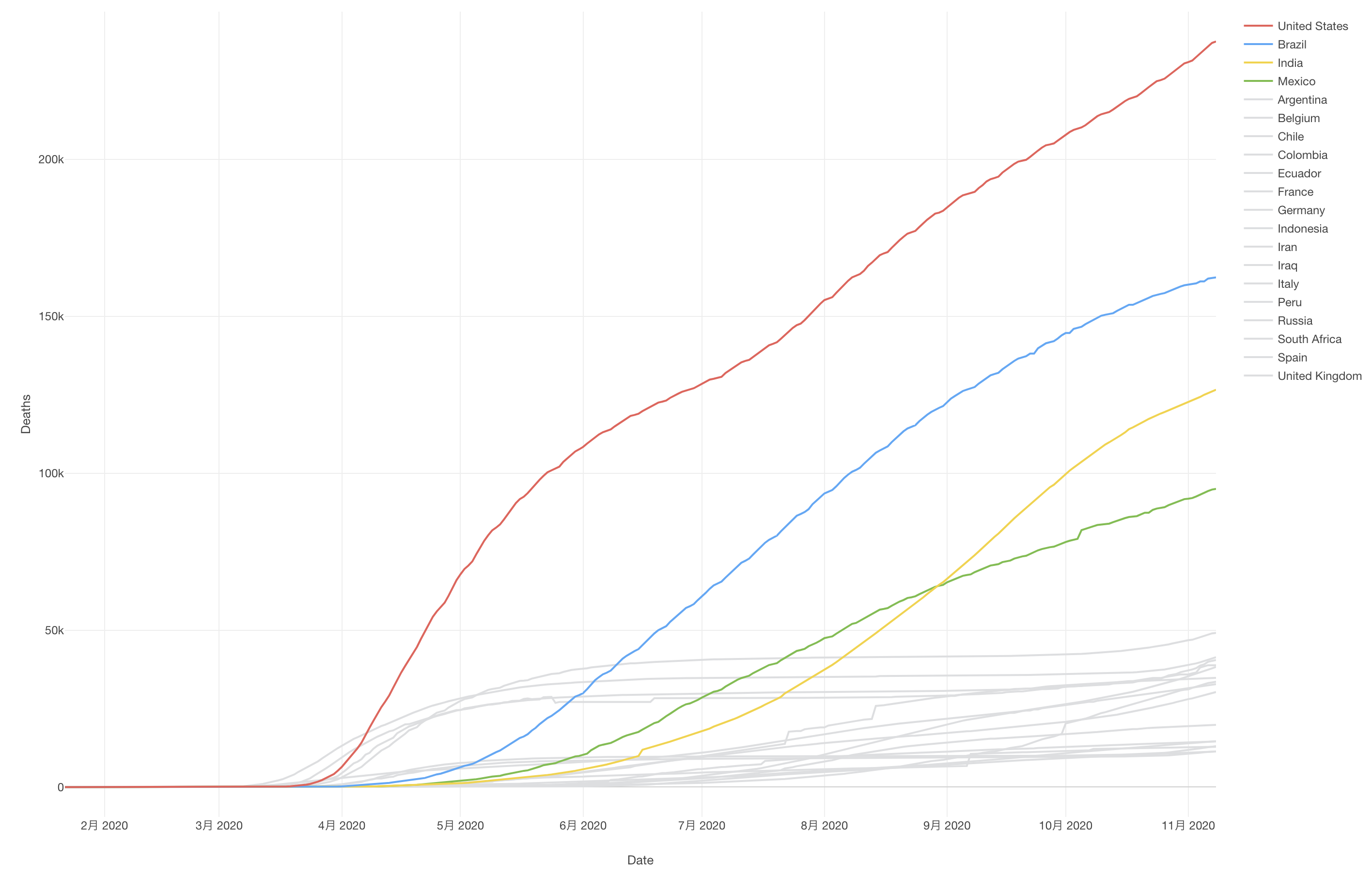
日本は他の国と比べて死亡者数は多いのか?
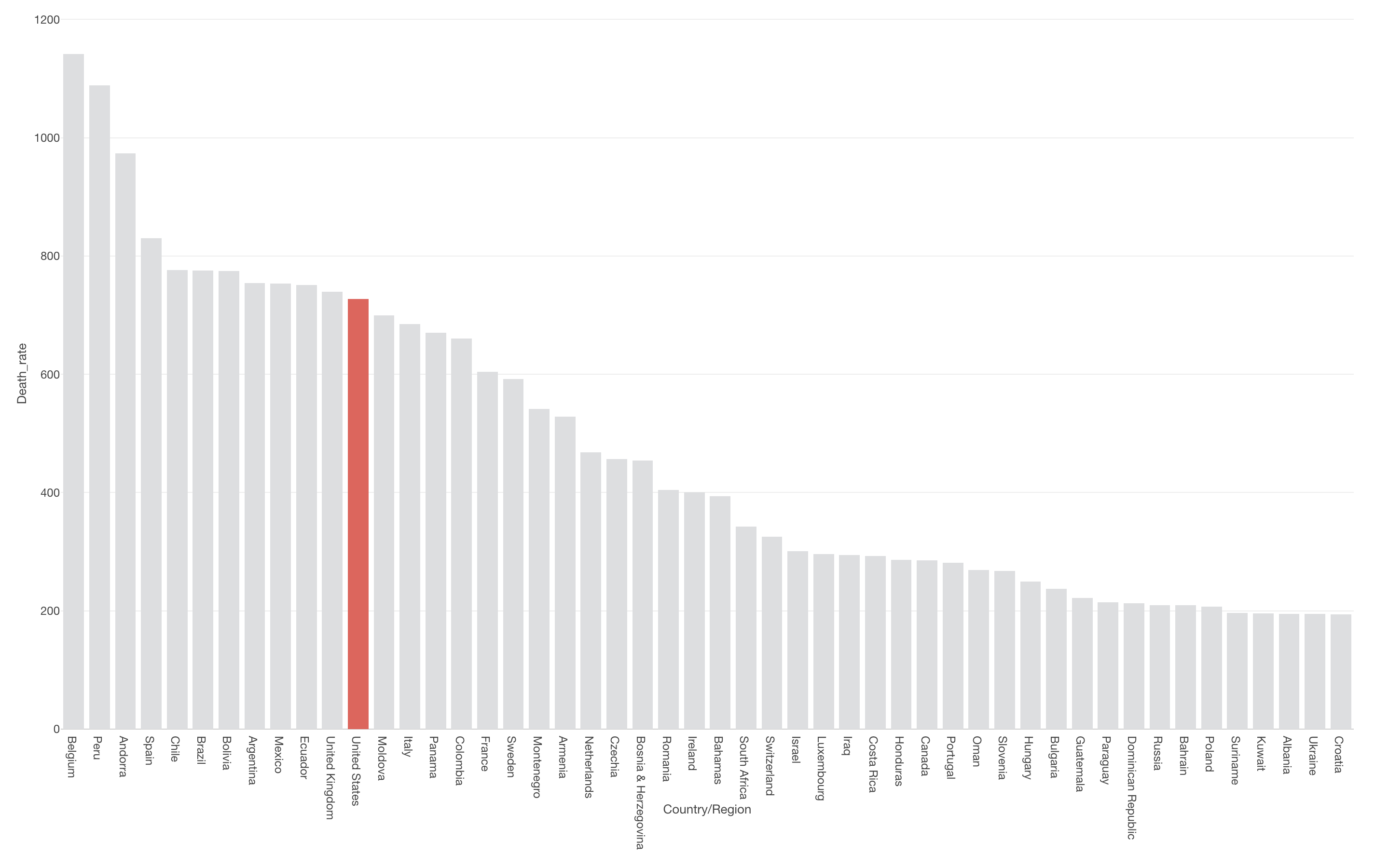
日本のコロナウイルスの死亡者数は多いのか少ないのかを知るためには、他の国と比べる必要があります。そこで、バーチャートを使い死亡者数が多いのか少ないのか可視化します。
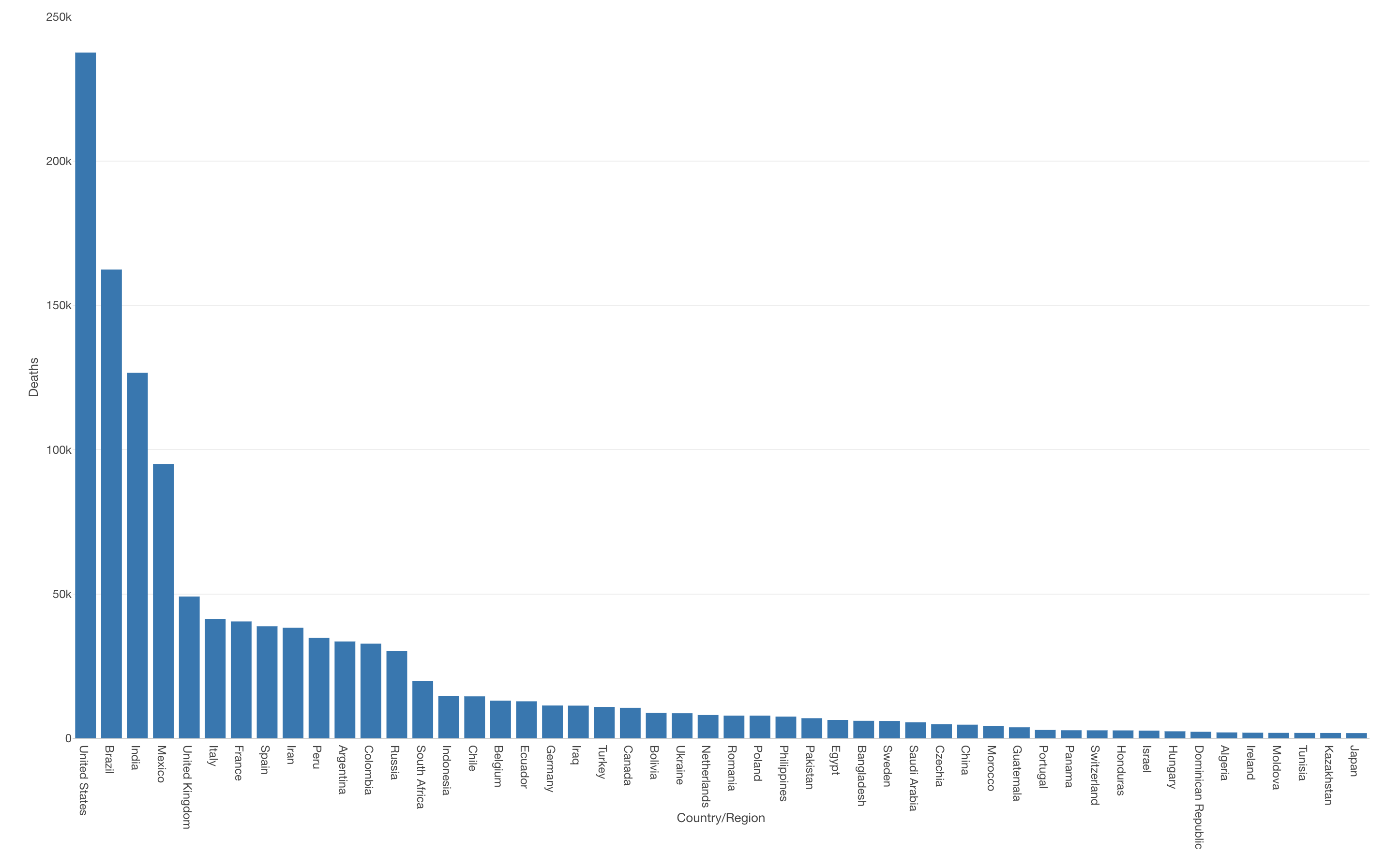
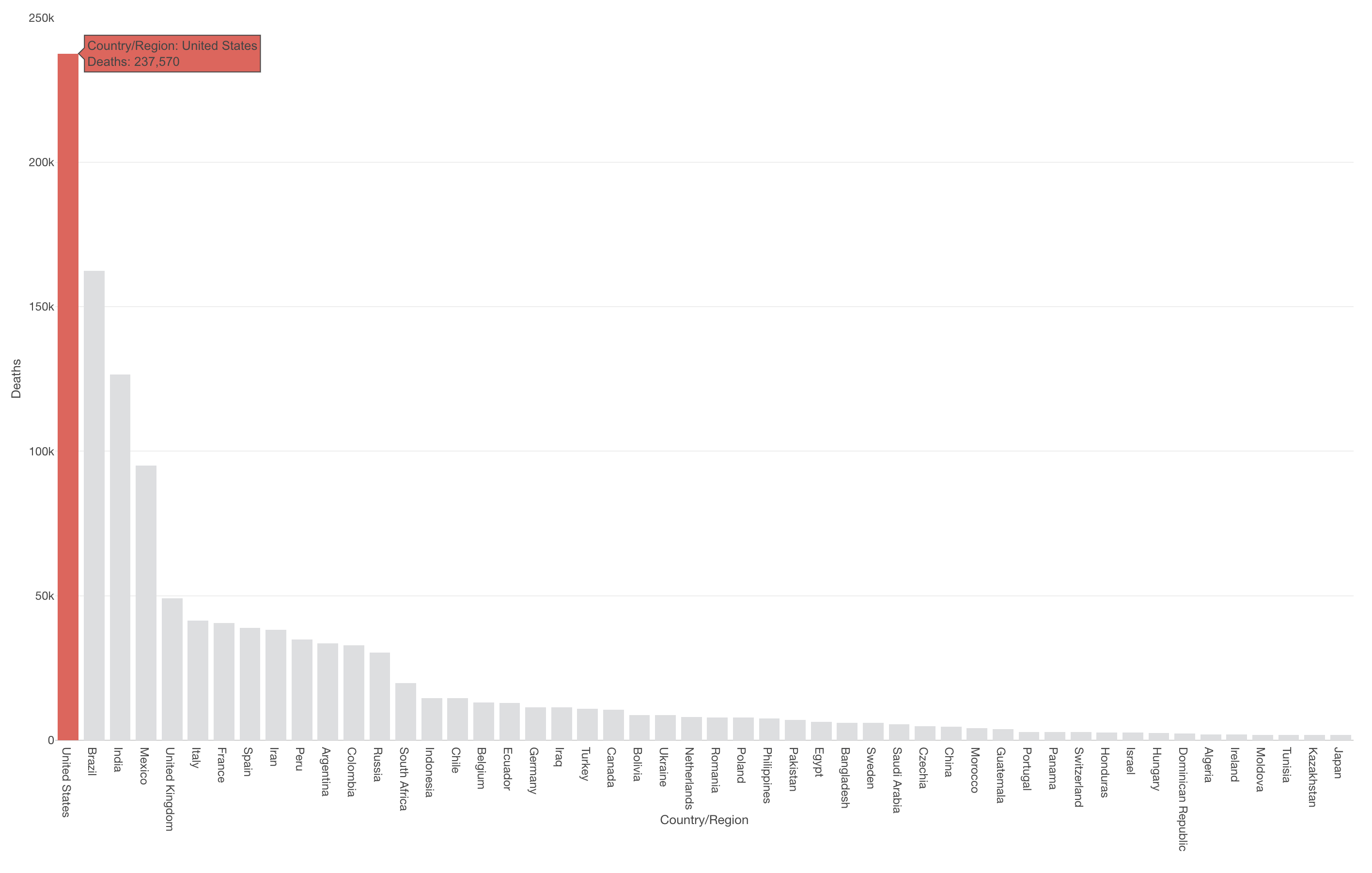
現時点(2020年11月9日)での死亡者数が最も多いのはアメリカで、23万人と他国に比べてダントツで多いことがわかります。
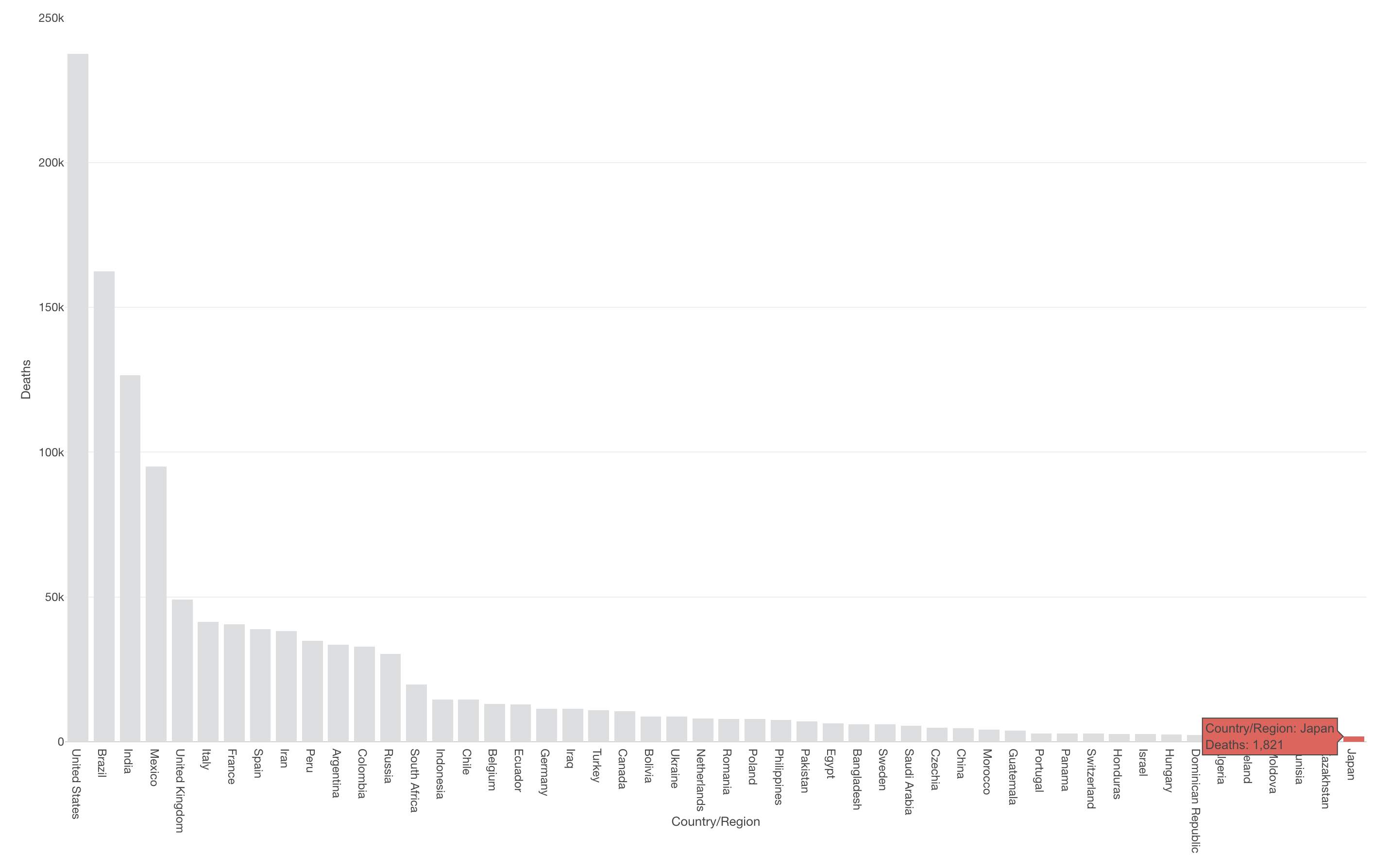
日本での死亡者数は1,821人と他国に比べて非常に少ないようです。国別に見た死亡者数の順位は50位になります。
よく、報道ではアメリカの感染者数や死亡者数に目が行きがちですが、国によって人口は大きく異なることに注意する必要があります。単純に死亡者の数だけで比べると、人口の多い国はコロナウイルスでの死亡者数も多くなり、結果として人口の多い国ではコロナウイルスの被害が拡大していると勘違いしてしまいます。
そこで、コロナウイルスのレポートの中では人口比を算出して比べているものもあります。では、人口比で見るとどの国が死亡率が高いのかといった質問に答えたいときに、またデータラングリングの問題にぶつかります。
それが、現在のデータには人口の情報がないということです。
こういった問題はコロナウイルスのデータに限らず、ビジネスの場面でもよく遭遇する問題です。顧客の属性情報のデータと、売上や解約のデータは別々になっているという体験をした方もいるでしょう。
データ分析する際には、異なるデータフレームを結合して組み合わせることで、得られるインサイトの幅も広がります。
ちなみに、データを組み合わせる処理をするためにExcelではvlookupという関数がありますが、国と日付のように複数条件にマッチさせようとすると式が複雑になってしまったり、少しでも式やセルの内容が変わった時に壊れてしまいます。
Exploratoryでは、UIから簡単に異なるデータフレームを結合をすることができます。
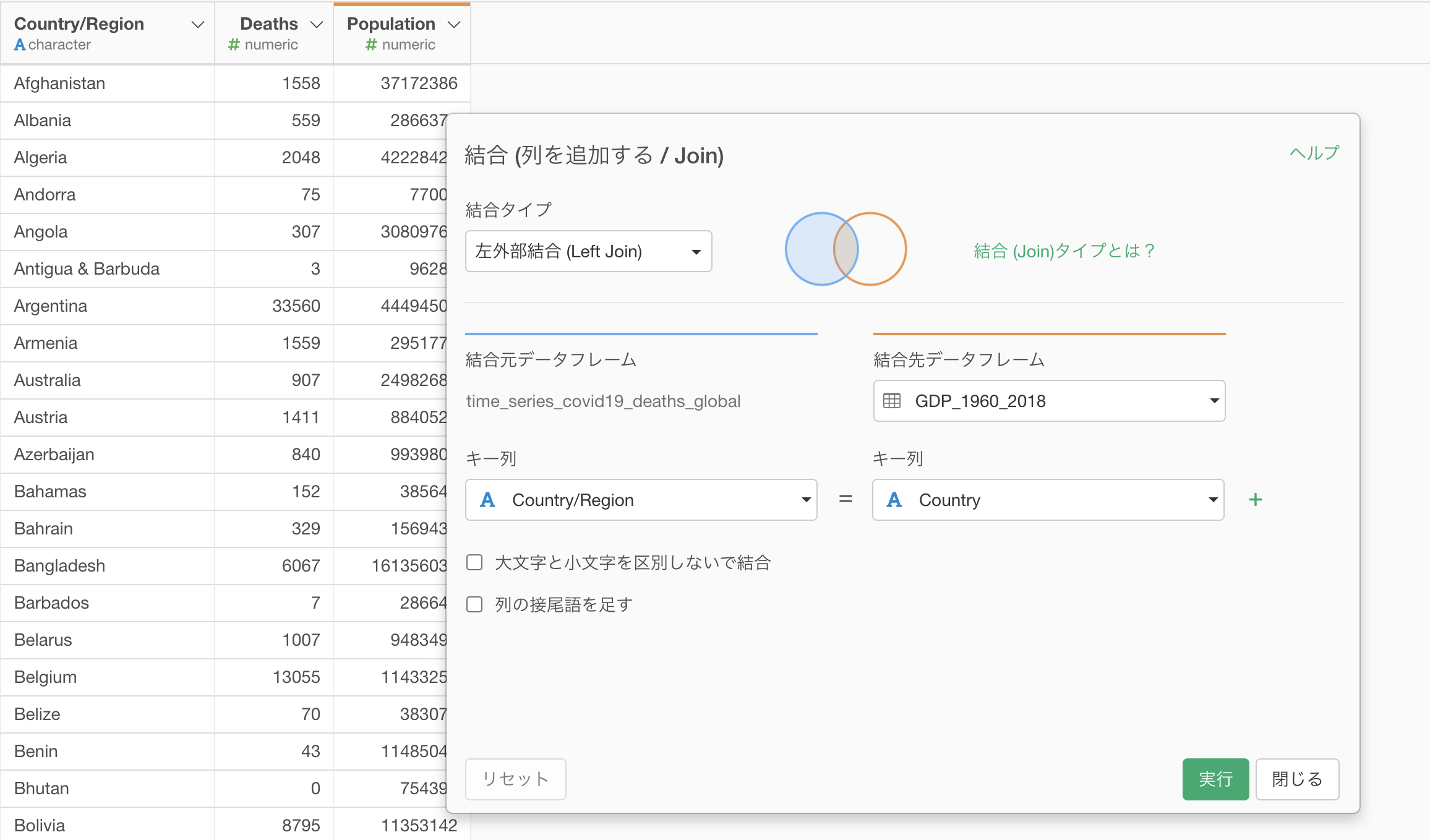
結合を使ってコロナウイルスのデータに人口のデータを追加します。
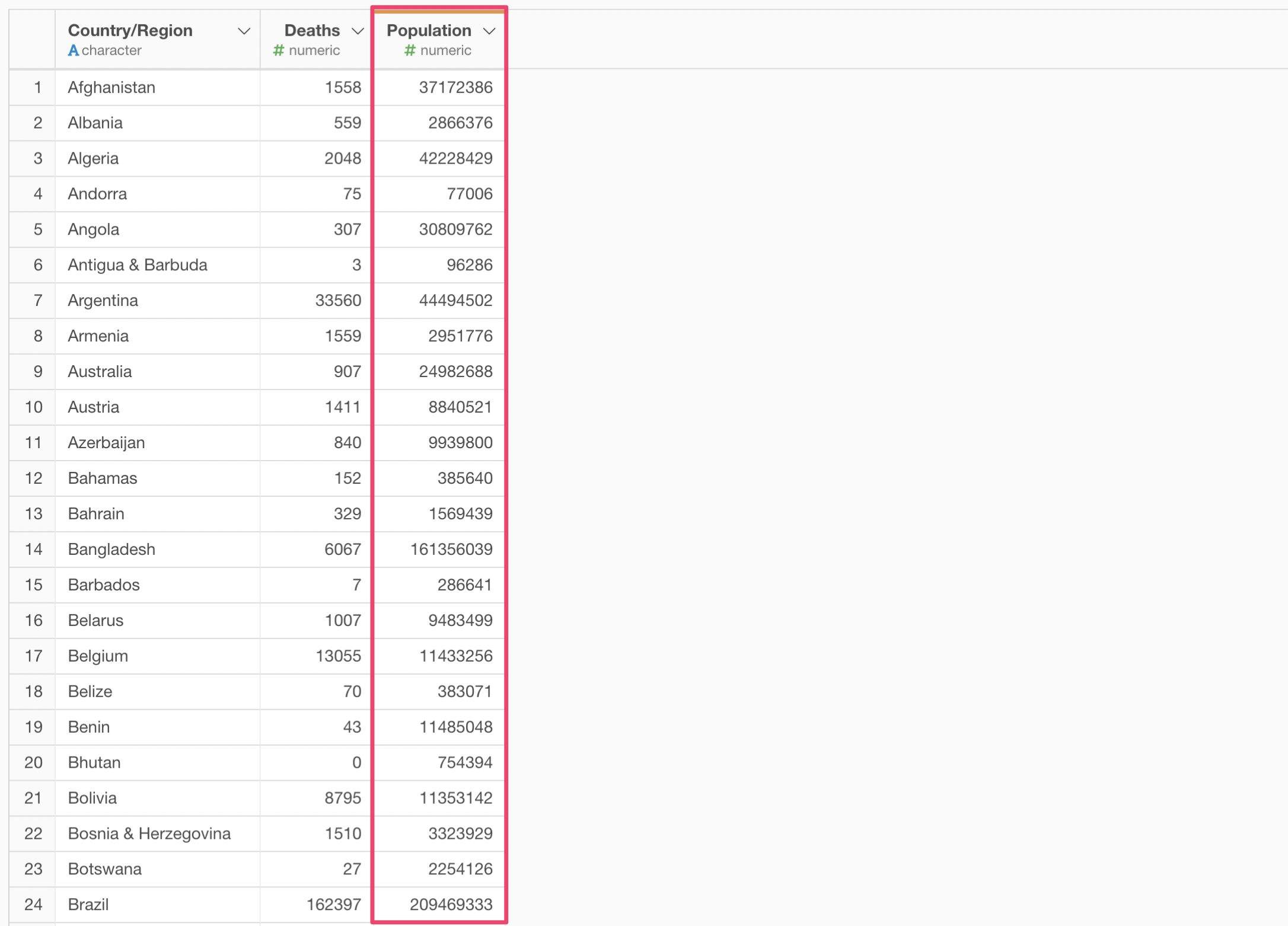
これにより、死亡者数を人口で割った人口比を求めることができます。補足情報ですが、死亡者数を人口で割ると人口一人当たりの死亡者数になり値は極端に小さくなり、理解しにくいものとなります。そこで100万をかけて、100万人あたりの死亡者数とすることが多いです。
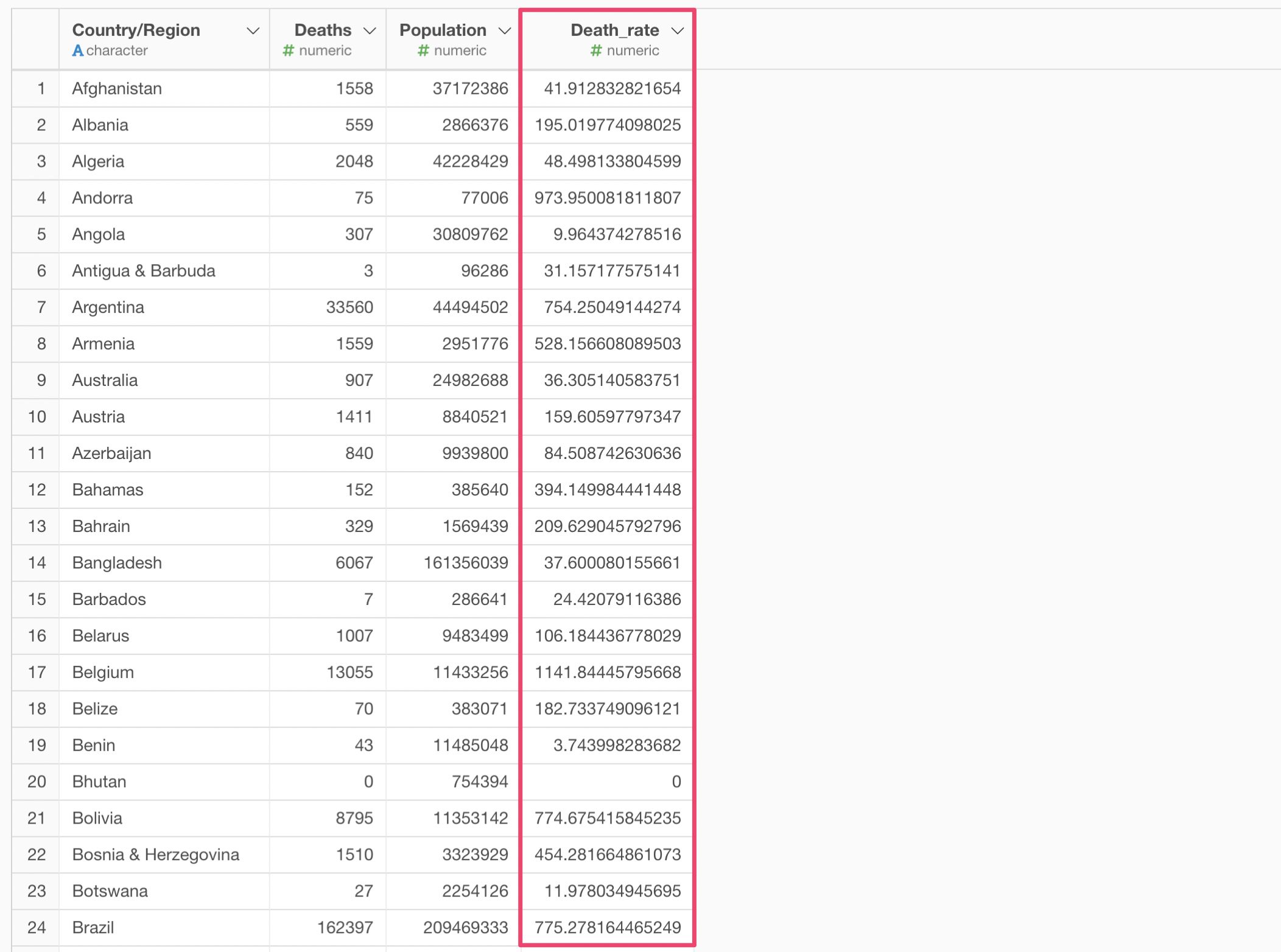
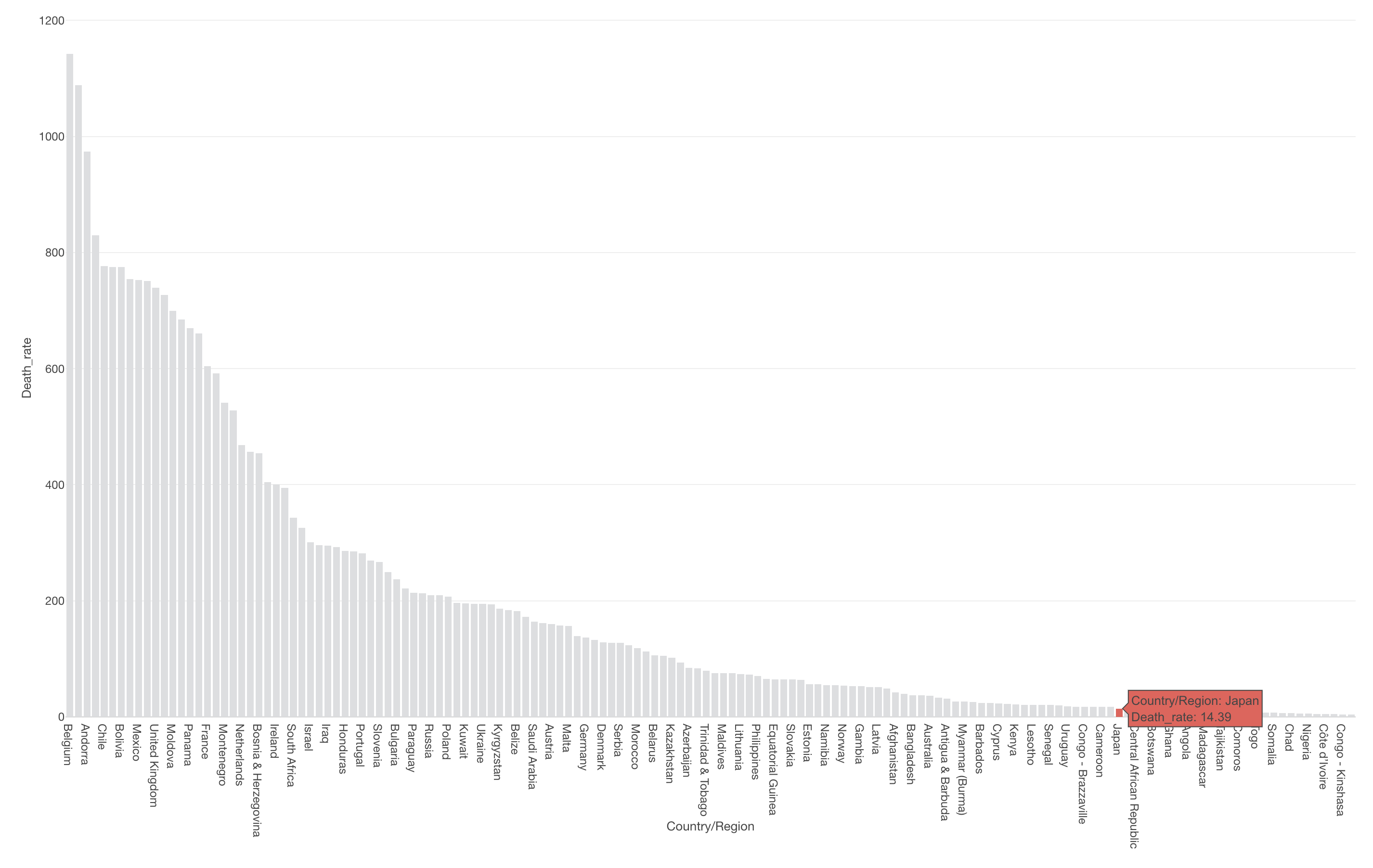
100万人あたりの死亡者数を求めることができると、どの国の死亡率が高いのか低いのかを比べていくことができます。
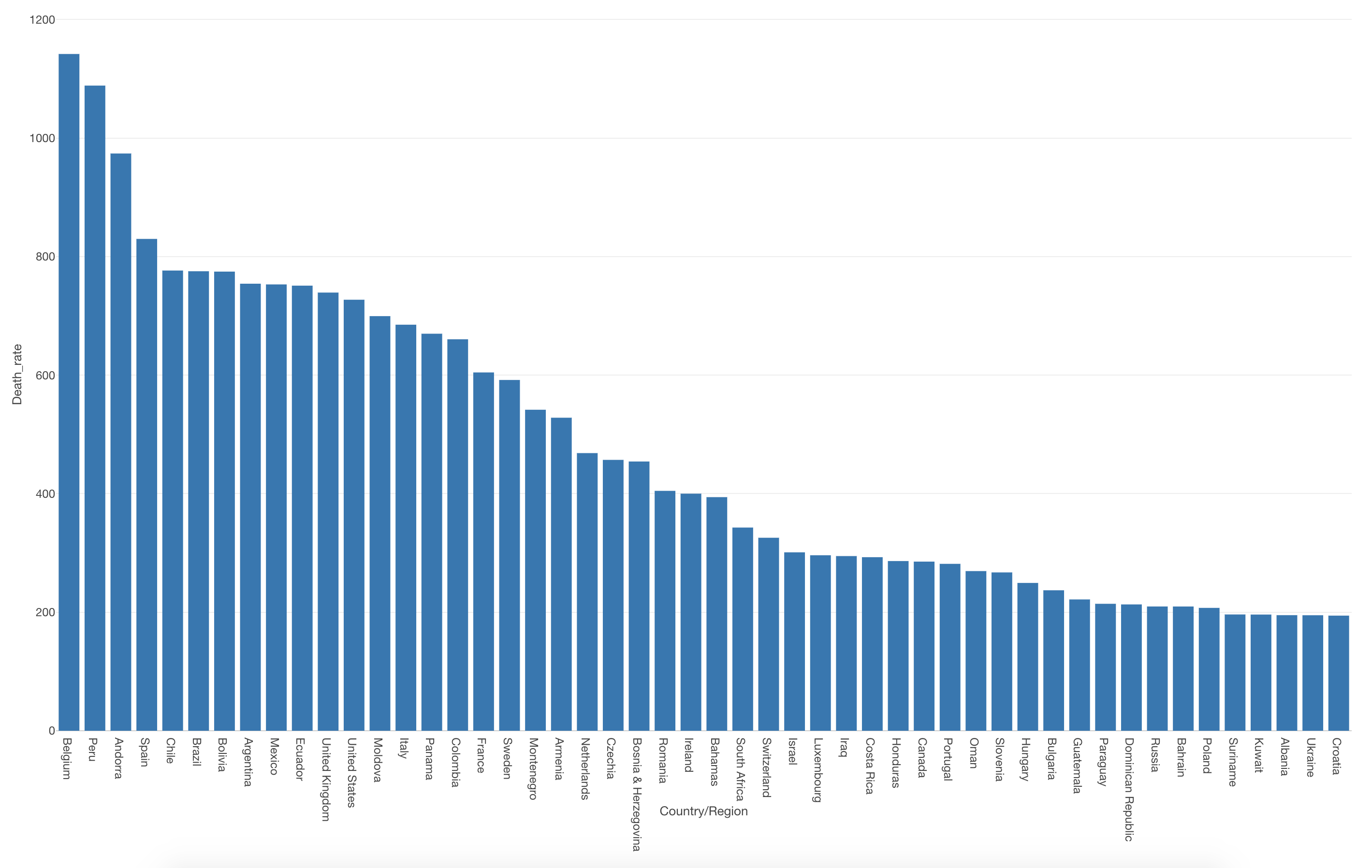
単純な死亡者数で見るとアメリカは最も死亡者数が多い国でしたが100万人あたりの死亡者数で見るとそうではないようです。
ちなみに、日本の100万人あたりの死亡者数は14.39人となります。この値は他の国と比べてかなり低く、順位としては123位となります。
今回は、コロナウイルスでの死亡者数は増加しているのか、日本は他国と比べて死亡者数が多いのかという質問に答えるためのデータラングリングの方法について紹介しました。
"garbage in garbage out"という言葉があるように、データ分析する際に、データが汚かったり意味のないデータを分析しても、いくら時間をかけたり高度な分析手法を使っても、結果は意味のないものとなります。
データもダイヤモンドの原石のように、データを綺麗にし、可視化や分析しやすい形に整えていくことで真価を発揮します。
データラングリングは、実はデータを使ってビジネスの質問に答えていくための必須スキルとなります。
データラングリング・トレーニング、12月開催決定!
この度、データラングリング(データの加工)の手法を1から体系的に、そして効果的に身に着けてもらおうという思いから、データラングリング・ワークショップというトレーニングの提供を開始することになりました。
まずは第一弾ということで、12月の17日、18日の2日間、オンラインで開催します。
ぜひこの機会に参加をご検討ください!
詳細はこちらのページにあります。