purrr難しい
-
purrr::mapってよくわかんないですよね。
-
for loopよりも繰り返し処理が早いらしい - list型に適用できるらしい
- とはいうものの正直「で, どう使えばいいの」と思っていました。
-
-
すでにいくつかの先人達が簡単にまとめてくれています
-
「とりあえず触ってみてごらん」という気持ちで記事にしました。
- すでにdplyrやggplotは使っているがpurrrはまだという人のために足掛かりになるような記事になれば幸いです。
purrrとは何か
-
purrrとは繰り返し処理やリスト型への処理をより簡潔に描けるようにしたパッケージです。 (https://rpubs.com/christianthieme/589762])- 繰り返し処理といえば
for loopを思い浮かべると思います。しかし,R言語においてfor loopは遅く,ビッグデータに対しては効率が悪いという問題があります。 - base関数の中にも並列処理,繰り返し処理を関数によって実装した
apply系関数がありますが,使い方は多様であるがゆえに,初学者にとっては理解が難しいという問題もあります。 - そこで
purrrの登場です。これはtidyverseパッケージの中の一つです。したがって,tidyverseに含まれるほとんどの関数と併用して用いることができます。 - 実際,
tibble::tibble()やtidyr::nest(),dplyr::mutate(),ggplot2::ggplot()などと組み合わせて使うことが可能です。 - 今回はこれらを併用した方法についていくつか紹介します。
- 繰り返し処理といえば
- 繰り返しになりますが,
purrrでできることは繰り返し処理,一括処理になります。
list型という大敵
- purrrがよくわからない最大の原因はlist型だと思っています。
- しかしながら,data.frame型やtibble型もlistの一種です。
- data.frameは1セルに一つの値という制限付きのlistと考えて良いです。
-
tibbleはdata.frameの拡張版です。
- 1セルに一つの値という制約がありません。1セルの中にdata.frameやベクトルなどを含むことができます。例えば,以下のようなものです。
# A tibble: 4 × 2
ID data
<int> <list>
1 1 <tibble [53 × 7]>
2 2 <tibble [54 × 7]>
3 3 <tibble [43 × 7]>
4 4 <tibble [50 × 7]>
- 上記のようにtibbleの中にtibbleなど階層構造を持つことができます。
- このとき,data列の中身は列数や行数が一致していなくてもかまいません。
- ここではあんまり深く考えません。
-
listはtibbleよりもさらに制限が少なく,色々格納できるやつくらいに思っていてください。 - (偉い人に怒られそう)
とりあえず,使ってみる
- 何はともあれやってみます。
同じデータセットに対して,異なる引数を指定する。
-
例えば,下記のデータを用いてクラスタリングを行います。今回は
k-meansを用います。k-meansは予めクラスタ数を指定し,その数に基づいて分けてくれます。しかし,探索的にクラスタリングを行う場合は,クラスタリング後,評価指標を用いながら最適なクラスタ数を判断することになると思います。- 「とりあえず2~5くらいで試してそれぞれAICとかBICとか見ておこか」という感じだと思われます。
-
今回は,下記のデータ(
mtcars)を用いてクラスタリングを行います。
library(tidyverse)
data(mtcars)
mtcars %>%
head
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
for loopで実装
- こんな感じで書けると思います。
for (i in 2:5) {
assign(paste0("kmeans_seg", i),
kmeans(mtcars, i))
}
-
今回は
assign()を使ってオブジェクトにそれぞれの結果を格納しています。kmeans_seg2、kmeans_seg3...というオブジェクト名にそれぞれの結果が格納されています。 -
短いコードなので、そこまで複雑ではないですが、分析回数分のオブジェクトを作ることになるので、Environment Paneが汚くなりがちです。また、オブジェクトをrdsファイルなどに保存する際にはそれぞれのオブジェクトごとに保存することになるので、管理が面倒になります。
- ※もちろん、list型のオブジェクトの中に
kmeans_seg2などの結果を格納し、rdsファイルを保存することもできますが、そんなことするくらいならapply系やpurrrを使うのと大差ありません。
- ※もちろん、list型のオブジェクトの中に
purrrの関数
-
purrrを用いる上で最も重要な関数はpurrr::map()です。- やりたいことや求める出力によって、
purrr::map()の亜種であるpurrr::map_dbl()やpurrr::map2()などを使用していくことになります。
- やりたいことや求める出力によって、
dplyr::mutate()との併用
- 上述しましたが、purrrはtidyverseの中の一つですので、その他のtidyverseの関数と併用することができます
- 例えば
dplyr::mutate()です。 -
dplyr::mutate()はすでにある列(変数)を用いて、それに基づく処理を行い、新たな列(出力)を作成します。 - 基本的に
mutate()で作成される新たな列は1つの値が前提ですが、purrr::map()を用いるとリスト型での出力やdata.frameでの出力が可能です。
- 例えば
-
purrr::mapには2つの引数(.x, .f)を指定します- .xには使用する変数、.fには使用する関数を指定します。
- これらを用いて新たな列を作ります。
- 例題の実装
- 分けたいクラスタ数の列を適当に作り(segment列: 4行×1列)
- データセットmtcarsを用いて、k-meansクラスタリングを実装しています。
-
kmeans()の引数には、purrr::map()でした引数.xを入力します
result <- tibble(segment = 2:5) %>%
mutate(kmean = purrr::map(.x = segment,
.f = ~kmeans(mtcars, .x)))
出力
- 出力はリスト型になります。
result
# A tibble: 4 × 2
segment kmean
<int> <list>
1 2 <kmeans>
2 3 <kmeans>
3 4 <kmeans>
4 5 <kmeans>
- 全てのkmeansの出力を確認するのであれば,以下のように
result$kmean
[[1]]
K-means clustering with 2 clusters of sizes 18, 14
Cluster means:
mpg cyl disp hp drat wt qsec vs am gear carb
1 23.97222 4.777778 135.5389 98.05556 3.882222 2.609056 18.68611 0.7777778 0.6111111 4.000000 2.277778
2 15.10000 8.000000 353.1000 209.21429 3.229286 3.999214 16.77214 0.0000000 0.1428571 3.285714 3.500000
Clustering vector:
Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive Hornet Sportabout Valiant
1 1 1 1 2 1
Duster 360 Merc 240D Merc 230 Merc 280 Merc 280C Merc 450SE
2 1 1 1 1 2
Merc 450SL Merc 450SLC Cadillac Fleetwood Lincoln Continental Chrysler Imperial Fiat 128
2 2 2 2 2 1
Honda Civic Toyota Corolla Toyota Corona Dodge Challenger AMC Javelin Camaro Z28
1 1 1 2 2 2
Pontiac Firebird Fiat X1-9 Porsche 914-2 Lotus Europa Ford Pantera L Ferrari Dino
2 1 1 1 2 1
Maserati Bora Volvo 142E
2 1
Within cluster sum of squares by cluster:
[1] 58920.54 93643.90
(between_SS / total_SS = 75.5 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss" "betweenss" "size" "iter"
[9] "ifault"
[[2]]
K-means clustering with 3 clusters of sizes 9, 16, 7
Cluster means:
mpg cyl disp hp drat wt qsec vs am gear carb
1 14.64444 8.000000 388.2222 232.1111 3.343333 4.161556 16.40444 0.0000000 0.2222222 3.444444 4.000000
2 24.50000 4.625000 122.2937 96.8750 4.002500 2.518000 18.54312 0.7500000 0.6875000 4.125000 2.437500
3 17.01429 7.428571 276.0571 150.7143 2.994286 3.601429 18.11857 0.2857143 0.0000000 3.000000 2.142857
## 長くなるので、ここで切ります
- 関数の前にチルダ(~)を付けるのを忘れずに、
- 今回は
kmeans()関数を使いましたが、自作関数でもラムダ式でもよいです。- ラムダ関数、ラムダ式については以下が参考になります。
- https://necostat.hatenablog.jp/entry/2023/08/01/155011
とりあえずこれでOK
-
purrr::map()の使い方はそこまで難しくないです。 - ただし、現状では出力されたものはリスト型になっていますので、注意してください。リスト型ではなく、他の型にする方法については後述します。
異なるデータセットに対して、同じ処理をする
-
先ほどは同一のデータセットに対して異なる引数を指定する方法をやってみました。
-
次は異なるデータセットに対して、同じ処理を施す場合です。
-
例えば、
- デモグラフィックスごとに変数AとBで回帰を行いたいとしましょう。
- 今回は住んでいる地域にします。
df
# A tibble: 5 × 3
A B Location
<dbl> <dbl> <fct>
1 -0.498 1.40 Tokyo
2 0.489 0.473 Tokyo
3 -0.125 -0.863 Osaka
4 -0.0860 2.96 Osaka
5 -0.391 -1.08 Tokyo
- まず最初に行う必要があるのは、デモグラフィックスごとにデータセットを分ける必要があります。
- 異なるオブジェクトにデータセットを分けることもできますが、先ほども申し上げた通り、管理が面倒になりますので、1つのオブジェクトの中で完結させます。
- 一つにまとめるには
tidyr::nest()を使います。 - そして、グループ化して分けるには
dplyr::group_by()を用います。 - 以下のようにします。
- 一つにまとめるには
df %>%
dplyr::group_by(Location) %>%
tidyr::nest(data=c(A,B))
# A tibble: 2 × 2
# Groups: Location [2]
Location data
<fct> <list>
1 Tokyo <tibble [50 × 2]>
2 Osaka <tibble [50 × 2]>
-
これでデモグラフィックスごとにデータセットを分けることができました・
-
tidyr::nest()でまとめたい列名を指定し(今回はA列とB列)、まとめた状態の新しい列名を指定します(今回はdata列)
-
-
まとめたい列名をすべて指定するのが面倒なときは、
dplyr::select()の関数を用いるときと同様にします。- 例えば、列名の最初がQのものだけを指定したい場合は
dplyr::starts_with("Q")などとします。
- 例えば、列名の最初がQのものだけを指定したい場合は
-
このdata列を用いて単回帰を行うには以下のようにします。
df %>%
group_by(Location) %>%
nest(data=c(A,B)) %>%
mutate(LM = map(.x = data,
.f = ~lm(data = .x,
A~B)))
# A tibble: 2 × 3
# Groups: Location [2]
Location data LM
<fct> <list> <list>
1 Tokyo <tibble [50 × 2]> <lm>
2 Osaka <tibble [50 × 2]> <lm>
-
これでデモグラフィックスごとに単回帰を行うことができました。
-
tidyr::nest()という関数を用いて、データセットを分け、それぞれのデータに対して単回帰を当てはめています。- オブジェクトの中身、構造が非常にわかりやすいのではないかと思います。
-
dplyr::filter()などを使って、データを分けて実行することは可能ですが、この方法を用いれば、無駄にオブジェクトを増やさずに実行することができます。 -
ちなみに、nestされたデータを元に戻す場合は
unnestを用います。
df %>%
dplyr::group_by(Location) %>%
tidyr::nest(data=c(A,B)) %>%
tidyr::unnest(cols = data) #列名は指定する。指定せずとも動作はするが、warningが出る。
map_**()
-
上述しましたが、
purrr::map()の出力はリスト型です。 -
リスト以外の出力を求める場合は以下のようなものを使います。
map_lgl(.x, .f, ...)map_int(.x, .f, ... )map_dbl(.x, .f, ... )map_chr(.x, .f, ... )map_vec(.x, .f, ... )
-
それぞれの関数の名称通り、整数型で出力してほしいのであれば
map_int()、ベクトルとして返してほしいのであればmap_vec()を用います。
例題
- 例えばdouble型で出力してほしいとしましょう。
- 先ほどのk-meansクラスタリングでAICを算出します。
- デフォルトではAICは算出してくれないので、自作関数を作ります。
- こちらを参考にしました。
- https://tjo.hatenablog.com/entry/2021/04/20/173000
kmeansAIC <- function(fit){
m <- ncol(fit$centers)
n <- length(fit$cluster)
k <- nrow(fit$centers)
D <- fit$tot.withinss
return(AIC = D + 2*m*k)
}
- この関数はkmeansの結果を入力すればAICを算出してくれます。
kmeans(mtcars, 2) %>%
kmeansAIC()
[1] 152608.4
- 先ほどクラスタリングした結果についてこの自作関数を用いてAICを算出してみましょう
tibble(segment = 2:5) %>%
mutate(kmean = purrr::map(.x = segment,
.f = ~kmeans(mtcars, .x))) %>% ### ここまではさっきと同じ
mutate(AIC = purrr::map_dbl(.x = kmean,
.f = ~kmeansAIC(.x)))
# A tibble: 4 × 3
segment kmean AIC
<int> <list> <dbl>
1 2 <kmeans> 152608.
2 3 <kmeans> 119513.
3 4 <kmeans> 111511.
4 5 <kmeans> 55706.
- dbl形で出力されていますね。
- ちなみに、
map_dblではなく、mapで行うと以下のような出力になります。
- ちなみに、
tibble(segment = 2:5) %>%
mutate(kmean = purrr::map(.x = segment,
.f = ~kmeans(mtcars, .x))) %>% ### ここまではさっきと同じ
mutate(AIC = purrr::map(.x = kmean,
.f = ~kmeansAIC(.x)))
# A tibble: 4 × 3
segment kmean AIC
<int> <list> <list>
1 2 <kmeans> <dbl [1]>
2 3 <kmeans> <dbl [1]>
3 4 <kmeans> <dbl [1]>
4 5 <kmeans> <dbl [1]>
- リストで出力されていますね。
- リストの中にdbl型が一つ格納されています。
purrr::map2()
-
さてここまでが基本的なmapの使い方です。
- これまでは引数が1つの場合の例でした
- 引数が2つの場合ももちろんあるでしょう。そんなときは
purrr::map2()を用います。- 具体的には.xと.f だけでなく、.yも指定します。
-
ここでは、nestの例で扱ったデータをplotします。
- purrrはggplotについても同様に扱うことができます。
-
データはこんな感じでした。
hoge <- df %>%
group_by(Location) %>%
nest(data=c(A,B)) %>%
mutate(LM = map(.x = data,
.f = ~lm(data = .x,
A~B)))
hoge
# A tibble: 2 × 3
# Groups: Location [2]
Location data LM
<fct> <list> <list>
1 Tokyo <tibble [50 × 2]> <lm>
2 Osaka <tibble [50 × 2]> <lm>
-
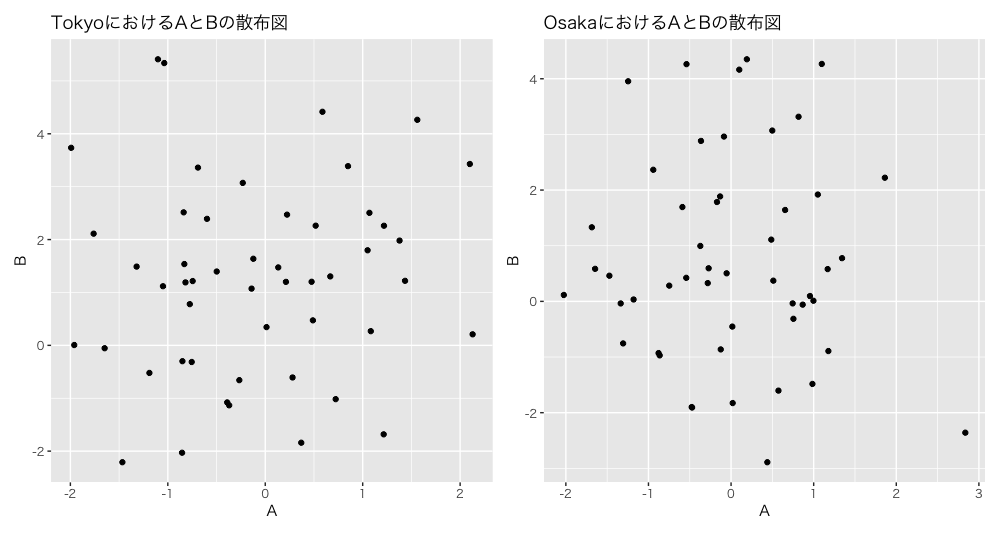
デモグラフィックスごとにAとBの散布図を作成します。
- その際に、plotのタイトルを指定してあげます
-
まずは、自作関数を作っておきます。
make_scatter <- function(df, name){
ggplot(data = df,
mapping = aes(x = A,
y = B))+
geom_point()+
labs(title = paste0(name, "におけるAとBの散布図"))
}
- この自作関数を用いて、新たな列ggを作ります。
hoge <- hoge %>%
mutate(gg = map2(.x = data,
.y = Location,
.f = ~make_scatter(df=.x,
name=.y)))
hoge$gg
- もちろん自作関数ではなく、.fのところに直接書いても問題ありません。
- 例えば、以下のようになります。
hoge %>%
mutate(gg = map2(.x = data,
.y = demographics,
.f = ~ggplot(data = .x,
mapping = aes(x = A,
y = B))+
geom_point()+
labs(title = paste0(.y, "におけるAとBの散布図"))))
-
長くなるので、あまり読みやすくはないですね。
- まずは直接書いた方が作成者的には楽かもしれませんが、読む側にとっては難解です
- まずは、直接書いて、見やすくするために、自作関数に直すという方が良いかもしれません
- プロジェクトごとに統一するのが望ましいでしょう
- また、自作関数にするメリットは同じ列名を持ったデータセットならすべてのデータセットに適用できるという点も魅力です。
- 一つ自作関数を作ってしまえば、その関数を読み込んでもらえば、プロジェクトメンバー全員が異なるデータセットに対して同じ処理を施すことが可能になります。
-
map2にはmapと同様に
map2_dbl(),map2_lgl()といった亜種が存在します。- お好みの出力に合わせて適宜使用してください。
purrr::pmap()
-
mapでは引数が1つ、map2では引数が2つでした。
-
それ以上の引数(3とか4とか、それ以上の数かもしれません)を用いたいときもあるでしょう
- そんなときは
pmap()を用います。
- そんなときは
-
pmapでは与えたい引数もリストで渡します。
- 例えば、以下のように書きます。
pmap(.l = list(x = A,
y = B,
z = C),
.f = ~ x*y*z)
- 今回は引数名をx,y,zと適当につけましたが、わかりやすいように変えてもよいです。
例題
- 例えば、デモグラフィックスのplotについて、年代の情報もあるとしましょう
demographics
# A tibble: 100 × 4
A B Location age
<dbl> <dbl> <fct> <int>
1 -0.176 -1.09 Tokyo 50
2 0.552 -0.875 Tokyo 30
3 -0.822 -1.51 Tokyo 30
4 -0.773 1.72 Tokyo 20
5 1.04 -1.01 Tokyo 40
6 0.0678 2.65 Tokyo 20
7 0.322 -2.09 Tokyo 30
8 -1.16 -1.85 Tokyo 30
9 -0.303 -0.488 Tokyo 40
10 1.21 3.26 Tokyo 40
# … with 90 more rows
# ℹ Use `print(n = ...)` to see more rows
- 地域、年代ごとにnestします
nested_demographics <- demographics %>%
group_by(Location,age) %>%
nest(data = c(A,B))
nested_demographics
# A tibble: 10 × 3
# Groups: Location, age [10]
Location age data
<fct> <int> <list>
1 Tokyo 50 <tibble [2 × 2]>
2 Tokyo 30 <tibble [19 × 2]>
3 Tokyo 20 <tibble [14 × 2]>
4 Tokyo 40 <tibble [14 × 2]>
5 Tokyo 10 <tibble [1 × 2]>
6 Osaka 30 <tibble [20 × 2]>
7 Osaka 40 <tibble [6 × 2]>
8 Osaka 10 <tibble [2 × 2]>
9 Osaka 20 <tibble [17 × 2]>
10 Osaka 50 <tibble [5 × 2]>
-
こちらにおいても散布図を作成します。
- 図のタイトルには、地域と年齢を記載しましょう。
- 使う引数はdata, Location, ageで3つあります
-
まずは自作関数を作ります
make_scatter2 <- function(first, second, third){
return(ggplot(data = first,
mapping = aes(x = A,
y = B))+
geom_point()+
labs(title = paste0(second,"かつ",third,"年代のAとBの散布図"))+
theme(text = element_text(size=12))
)
}
nested_demographics <- nested_demographics %>%
mutate(gg = pmap(.l = list(first = data,
second = sex,
third = age),
.f = make_scatter2)) # ここで引数は指定せず、チルダも不要
nested_demographics
# A tibble: 10 × 4
# Groups: Location, age [10]
Location age data gg
<fct> <int> <list> <list>
1 Tokyo 50 <tibble [2 × 2]> <gg>
2 Tokyo 30 <tibble [19 × 2]> <gg>
3 Tokyo 20 <tibble [14 × 2]> <gg>
4 Tokyo 40 <tibble [14 × 2]> <gg>
5 Tokyo 10 <tibble [1 × 2]> <gg>
6 Osaka 30 <tibble [20 × 2]> <gg>
7 Osaka 40 <tibble [6 × 2]> <gg>
8 Osaka 10 <tibble [2 × 2]> <gg>
9 Osaka 20 <tibble [17 × 2]> <gg>
10 Osaka 50 <tibble [5 × 2]> <gg>
nested_demographics$gg[[1]]
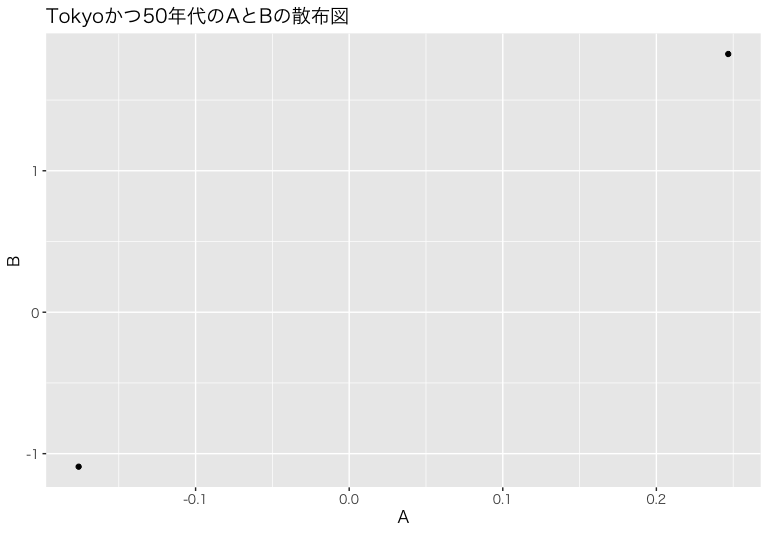
-
(適当に作ったらデータポイント2つしかないなこれすみません。)
-
省略した書き方もできますが、わかりにくくなってしまうので、個人的にはしっかりと書くべきだと思います。
- 省略した書き方は以下のサイトが参考になります。
- https://yoshidk6.hatenablog.com/entry/2018/08/06/154117
-
pmap()にもpmap_dbl()といった亜種はありますので、求める出力に応じて使い分けてください
furrr
-
purrrでは並列処理を可能にしました。「CPUってマルチスレッドなんだから、並列処理するときにスレッドごとで別の計算をさせたほうが早いんじゃね?」を実現させたパッケージです。
-
基本的にpurrrで用いた関数に
future_**と最初につければよい。- 例えば、
furrr::future_map(),future_map_dbl()といった具合です。
- 例えば、
-
事前にfuture系の関数を使用する際はマルチスレッドで動かすことを明示しておく必要があります。
-
plan(multisession, workers = 2)などと指定します。 - Rstudioサーバーを使っている場合は、他の人に迷惑が掛からない程度にすればよいと思います。
- 最大コア数にすると逆に遅くなるという事態がしばしばあります。
- 不必要に増やすと解析も遅くなり、他のメンバーに迷惑を変えるという呪いがあるので、よく考えて使いましょう
- 一人で使う場合は最大コア数 - 1 としたりします。
-
library(furrr)
plan(multisession, workers = 2)
tibble(segment = 2:5) %>%
mutate(kmean = future_map(.x = segment,
.f =~kmeans(mtcars, .x),
.options = furrr_options(seed=TRUE)))
-
また、単純に実行すると同じseedから乱数を発生することになるので、気を付けなければなりません。
- それぞれseedはランダムに変更するのであれば、上記のように指定します。
- このときのランダム化の方法も選ぶことができます。
-
他にもfurrr_optionsではいろいろ設定が可能なので、使う前に確認しておいてください。
終わりに
-
とりあえず、ざっとpurrrの使い方を書いてみました。
-
purrrで便利なのは、出力される型にとらわれないことです。
- summariseは複数の値の出力などができません。
-
他にも,チームの人などに結果を共有する際は、trelliscopejsパッケージが有用です。
- purrrで作成したggplotを見やすく出力してくれます。
- ぜひ使ってみてください。