TL;DR
cudnnConvolutionBackwardFilter()を1000通りのパラメータでプロファイルし、
GTX1060のルーフラインモデルにプロットした。
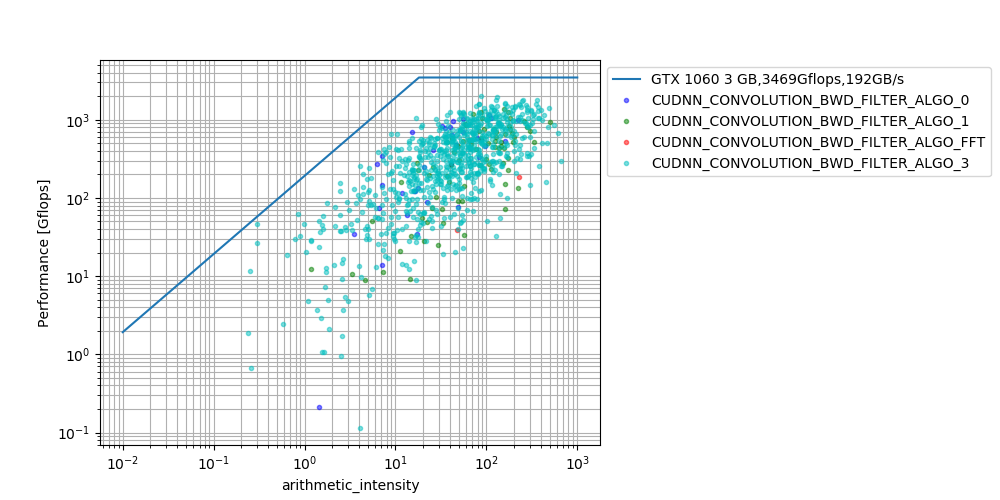
多くの場合で、100Gflops以上の性能が出る一方で、極端に性能劣化するパラメータが存在することがわかった。
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_FFTも一応使われることがあることがわかった。
評価対象
| Machine | nVIDIA GeForce GTX1060 3G |
|---|---|
| ピーク演算性能 | 3.469Tflops |
| ピークバンド幅 | 192GB/sec |
| CUDA | v10.0 |
| cuDNN | v7.4 |
評価条件(パラメータ)
1000通りのパラメータをランダムに生成。値域は下表の通り。
| パラメータ | 値域 |
|---|---|
| バッチサイズn | randint(1, 32) |
| 入力チャネルci | randint(1, 20) |
| 入力画像サイズHi | randint(1, 122) |
| 入力画像サイズWi | randint(1, 122) |
| ストライドu(h方向) | randint(1, 7) |
| カーネルkernel_h | randint(1, 7) |
| カーネルkernel_w | randint(1, 7) |
| パディングpad_h | randint(0, 8) |
| パディングpad_w | randint(0, 8) |
| dilation_h | 1固定 |
| dilation_w | 1固定 |
※ アルゴリズムは、1000通りのパラメータそれぞれに対し最速のアルゴリズムを選択している。
→ cudnnGetConvolutionBackwardFilterAlgorithm(..., CUDNN_CONVOLUTION_BWD_FILTER_PREFER_FASTEST,...)
評価式
- Performance [Gflops] = (演算回数) / (実行時間)
- Arithmetic intensity [GB/sec] = (演算回数) / (入出力データサイズ)
- (演算回数): c++でconvolution backward filterを愚直に書いて数え上げた。mulとaddは2operationとしてカウントしている。
- (実行時間):cudaEventElapsedTime()を用いてcudnnConvolutionBackwardFilter()単体の実行時間を測定した。
- (入出力データサイズ) = (ncihiwi + ncohowo + cocikernel_h*kernel_w)*4 [Byte]
評価環境
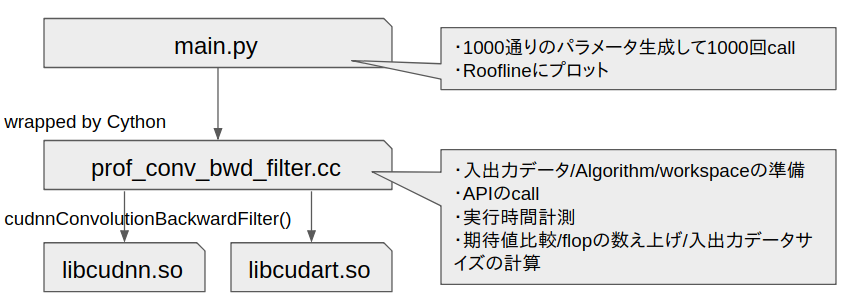
ソースコード一式
※ Cythonのsetpu.pyだけはいろいろハードコーディングしているのでリポジトリに入れていません。すみません。
参考文献
- ルーフラインモデルについて:
- Cythonによるc++のWarp方法について:
- CUDA Runtimeによる実行時間測定について: