はじめに
実践DDD本の第4章で扱われるアーキテクチャについて整理する。
また、以下に著者によるJavaとC#のサンプルがGitHubに公開されているので、サンプル実装を参考にするとよいと思われる。
DDDにおけるアーキテクチャ
DDDの利点は、特定のアーキテクチャに依存しない。
品質要求がどのアーキテクチャを採用するかの原動力になるべきであり、リスク駆動の手法として有益。
何らかのアーキテクチャを採用するに当たって、機能要件(ユースケースやユーザーストーリー、ドメインモデルに固有のシナリオなど)が分からなければ、適切なアーキテクチャを選択できない。
以上を踏まえて最適な選択をすることが目標。
レイヤ化アーキテクチャ
N層システムのアーキテクチャであり、いわゆる2層アーキテクチャ(クライアント・DB)や3層アーキテクチャ(webサーバー・アプリケーションサーバー・DBサーバー)もこの一種。
以下にレイヤ化アーキテクチャを使ったDDDアプリケーションの例を示す。

レイヤ化アーキテクチャは、どのレイヤも同じレイヤか、その下位レイヤとしか結合しない。
下位レイヤが上位レイヤを直接参照することはない。
例えば、下位レイヤで定義されているインターフェースを元に上位レイヤが実装し呼び出す。
UI層
ユーザーへの表示やユーザーからのリクエストに関するコードだけ書く。
ドメインロジックは含めない。
UI層でのバリデーションは粗いレベルに留めて、業務に関する知識をモデルの中で表現する。
ドメインモデルのオブジェクトを使う場合は、そのままレンダリングするだけに留める。
場合によって「プレゼンテーションモデル」を利用して、ビューがドメインオブジェクトに影響することを防げる。
アプリケーション層
「アプリケーションサービス」が存在する。
ドメインモデルの直接の利用者であるが、アプリケーション層自身はビジネスロジックを持たない。
非常に軽量で「集約」などのドメインオブジェクトに対する操作を調整したりする。
ドメイン層
ビジネスロジックを実装するレイヤ。
ドメインモデルを提供し、「集約」や「ファクトリ」のインスタンスを作成する。
ドメインサービスが存在し、ステートレスな操作でドメイン固有のタスクを実行できるようになっている。
「ドメインイベント」を公開するドメインイベントも存在する。
インフラストラクチャ層
「リポジトリ」を使用して、永続化やメッセージング機構などを提供する。
依存関係逆転の原則(DIP)
Robert C. Martinが提唱した依存関係逆転の原則(DIP:Dependency Inversion Principle)によってレイヤ化アーキテクチャを改良する方法がある。
公式な定義は以下のとおり。
上位のモジュールは下位のモジュールに依存してはならない。どちらのモジュールも、抽象に依存すべきである。
抽象は、実装の詳細に依存すべきではない。実装の詳細が、抽象に依存すべきである。
つまり、下位層のサービスが提供するコンポーネントは、上位層のコンポーネントが定義するインターフェースに依存すべきということ。
例にすると以下のような構成になる。
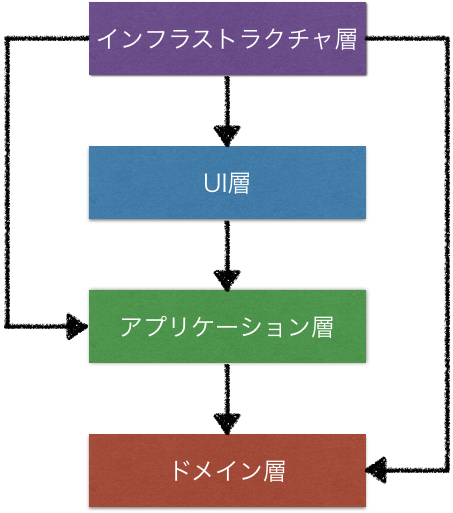
例えば、ドメインのモデルを定義した抽象(インターフェース)に対して、インフラストラクチャの実装が依存するようになる。
したがって、ドメインが他のレイヤに依存しなくなるので、ドメイン層がシンプルになる。
実装としては依存性の注入(DIコンテナ)、サービスファクトリ、プラグインなどが存在する。
ヘキサゴナル(ポートとアダプター)アーキテクチャ
Alistair Cookburnが、対称性を生み出すためのスタイルとしてまとめたもの。
ドメインモデルを内包したアプリケーションを中心に据えて、どんなクライアントが操作を入力しても、どんなシステムの出力があっても、それぞれ専用のアダプターが様々な変換に対応する。
ヘキサゴナルアーキテクチャは以下のような視点で捉える。
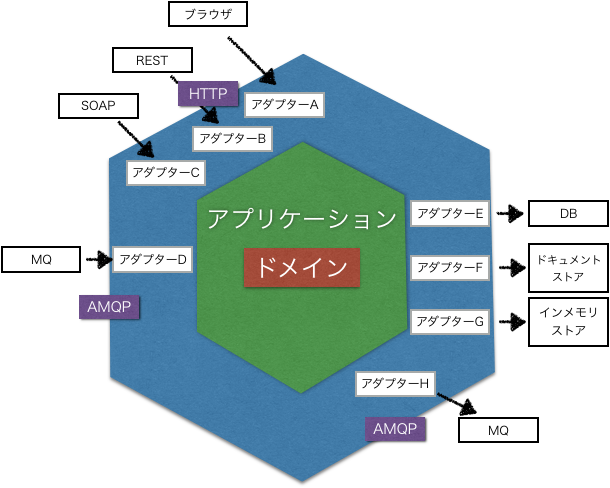
六角形の各辺が別の種類のポートに対応し、入力・出力に対応している。
例では、入力にはアダプターA・B・Cは同じHTTPのポート(ブラウザやREST・SOAP)を利用、アダプターDでは別のAMQPのポート(RabbitMQなど)を利用している。
出力には、アダプターE・F・Gのように、リレーショナルデータベース用・ドキュメントストア用・分散キャッシュ用・インメモリストア用のリポジトリ実装を用意したり、アプリケーションから外部にドメインイベントのメッセージを送った場合には、アダプターHのメッセージングようのアダプターを利用している。
ヘキサゴナルアーキテクチャは柔軟なアーキテクチャなので、他のアーキテクチャをうまく取り込むことができる。
テスト用のアダプターが簡単に作れるので、使用するクライアントやストレージが決まっていなくてもアプリケーション全体やドメインモデルの開発が行える。
上手に設計すれば、アプリケーションやドメインモデルが外部のパーツに漏れることなく、ユースケースを実装できる。
サービス指向アーキテクチャ(SOA)
サービス指向アーキテクチャ(SOA:Service Oriented Architecture)とは、常に相互運用可能であり、
Thomas Erlが定めた以下の8つの設計原則を兼ね備えたもの。
| No. | 原則 | 説明 |
|---|---|---|
| 1. | 標準化 | サービスの説明を契約(インターフェース)で示す。 |
| 2. | 疎結合性 | 依存関係を最小限にし、依存するものだけ認識する。 |
| 3. | 抽象性 | 自身の契約(インターフェース)だけを公開し、内部実装は公開しない。 |
| 4. | 再利用性 | 他のサービスからも再利用可能。 |
| 5. | 自立性 | 一貫性と信頼性を持ち、独立して成り立つ。 |
| 6. | ステートレス性 | 利用者側で状態を管理する。 |
| 7. | 発見可能性 | メタデータを記述して、他から発見可能にする。 |
| 8. | 構成可能性 | 大きいサービスに組み込み可能で、大きさや複雑度に制限がない。 |
ここでは、SOAの項目にDDDを上手く当てはめる一つの方法として提示している。
技術的サービス(RESTやSOAP、メッセージングなど)とビジネス戦略を表すビジネスサービスを組み合わせていく。
DDDでは、「ユビキタス言語」や「境界づけられたコンテキスト」を不自然に分断していないか確認することができる。
REST
REST(Representational State Transfer)は、Roy T. Fieldingによる論文によって提唱されたアーキテクチャ。
以下に特徴を整理する。
-
リソースをURIで識別する
URIにより一つのリソース識別する。例えば、顧客・プロダクト・検索結果などをURIで識別できる。 -
ステートレスな通信
各リクエストが独立していて、以前の状態を持たないので、毎回のリクエストに必要な全て情報が含まれる。 -
リソース操作
「GET」、「POST」、「PUT」、「DELETE」などのHTTPメソッドを用いてリソースを操作する。HTTPの各メソッドの定義は、HTTPの仕様に明記されており、例えば、GETメソッドは、データの読み込み、キャッシュ可能な振る舞いをする。 -
関連する操作方法を提供するハイパーメディア
ハイパーメディアを用いて、レスポンスにリンクを埋め込み、クライアントがエンドポイントを知らなくても次の操作を可能にする。Fieldingの論文では、HATEOAS(Hypermdia as the Engine of Application State)と呼んでいる。
RESTとDDD
RESTベースのシステムは理解しやすく、疎結合でスケーラブルなサービス提供に適している。
インターフェースを提供するに当たっては、ドメインモデルを変更するたびに、インターフェースに影響するため、RESTで直接公開するのは望ましくない。
直接公開する以外に以下の2通りの方法がある。
-
コアドメインとインターフェースモデルを切り離す
システムのインターフェース層を境界づけられたコンテキストとして分離して、インターフェースモデルから実際のコアドメインにアクセスする。こうすることで、コアドメインを修正しても、その変更をインターフェースモデルに反映させるかは、ケースに応じて判断できる。 -
標準のメディアタイプを利用する
ical(カレンダー形式)のような汎用フォーマットを利用し、フォーマットに合わせたドメインモデルを作成する。作成したモデルは同じフォーマットを扱うシステムであれば再利用できる。
特化したソリューションであれば、第一の手法、汎用的なソリューションで、標準化を進めるのであれば第二の手法が適している。
コマンドクエリ責務分離(CQRS)
CQRS(Command Query Responsibility Segregation)は、コマンドモデルとクエリモデルの二つに分け、更新と取得のそれぞれの処理を実装するもの。
Bertrand Mayerが提唱した、コマンドとクエリを分離するCQSの考え方をアーキテクチャに持ち込んだもの。
DDDでは、書き込みと読み込みを分けることによって、関心事を分離し、洗練されたビューを提供するという問題を解決する一つの方法として提示している。
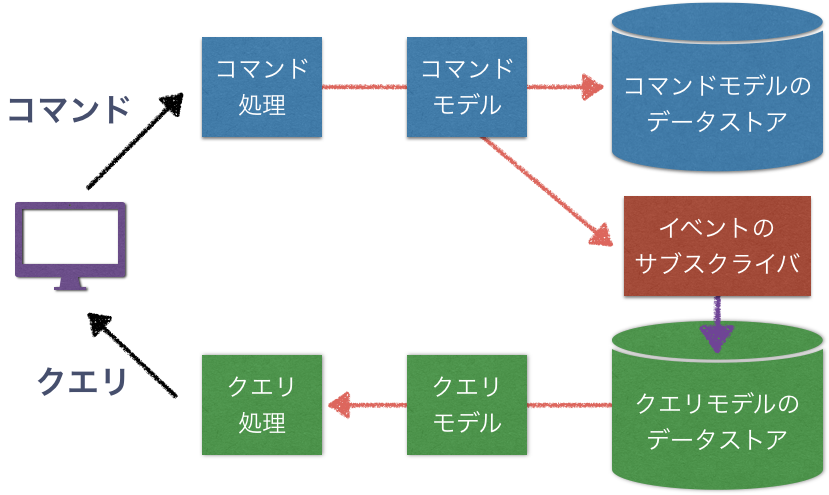
オブジェクトレベルで見ると、以下のように定義できる。
-
コマンド
メソッドがオブジェクトの状態を変更するのであれば、値を返却しない。Javaなどであれば、voidを返す。 -
クエリ
メソッドが値を返却するのであれば、オブジェクトの状態を変更してはいけない。Javaなどであれば、戻り値の型を定義する。
コマンド処理(コマンドハンドラ/コマンドプロセッサ)
発行されたコマンドを受け取るのが、コマンドハンドラ(コマンドプロセッサ)と呼ばれる。
いくつかの方式があり、メリット・デメリットを整理すると以下のようになる。
-
分類方式
同期処理で、アプリケーションサービスに複数のメソッドを作成する方式。
メリットとしては、シンプルで開発しやすい。 -
専用方式
同期処理で、単一メソッドを持つ単一のクラスを作成する方式。
メリットとしてはコマンドごとに責務が明確になる。 -
メッセージング方式
非同期処理で、専用方式で作られたコマンドハンドラに、コマンドをメッセージとして送信する方式。
メリットとしてはスケーラビリティが担保できる。しかし設計が複雑になるため、他の方式から検討した方がよい。
どの方式を採用するにしても、コマンドハンドラは、新しい集約のインスタンスを作成・取得し、コマンドを実行する。
コマンドハンドラの処理が完了すると、集約のインスタンスが更新され、コマンドモデルがドメインイベントを発行する。
コマンドモデル(ライトモデル)
コマンドモデルのメソッドが実行されると、ドメインイベントを発行する。
コマンドモデルのデータストア
コマンドモデルの更新結果を保存する。
イベントのサブスクライバによるクエリモデルの更新
コマンドモデルが発行する全てのドメインイベントを受信する。そして、受け取ったドメインイベントに応じてクエリモデルを更新する。
クエリ処理(クエリプロセッサ)
データベースの結果セットをそのまま利用するか、JSONやXMLでシリアライズしたものやDTOを組み立てるという方法がある。
プロジェクトによって最適な選択が必要。
クエリモデル(リードモデル)
表示用や印刷用に非正規化したデータモデル。
クエリモデルのデータストア
表示用のデータを格納する。
データモデルがSQLデータベースであれば、クライアントのビューごとにテーブルを用意する。
可能な限り、UIの表示形式ごとに一つのテーブルを用意し、アプリケーションのユーザー権限を反映させたビューも用意する。
しかしながら、あくまで現実的な範囲にとどめる。
同期・非同期処理の採用基準
同期・非同期処理の採用基準は機能要件によって異なってくる。
同期処理であれば、同一DB内にクエリモデルとコマンドモデルのデータストアを用意し、同一トランザクションの中で両方のモデルを更新できる。
こうすることで一貫線が完全に保たれるが、処理時間がかかる。
非同期処理であれば、レスポンスがすぐに返せるが、一貫性が保たれず「結果整合性」への対応が必要になる。
クエリモデルでの結果整合性の扱い
「結果整合性」とは「結果として一貫性が保たれていればよい」という考え方。
非同期であれば、結果整合性は保たれるがクエリモデルが更新されるまでに時間を要するため、UI側で対応が必要になる。
対応方法としては、入力パラメーターを利用して、擬似的に表示したり、データの最終更新日時を表示しておくといった方法がある。
サーバーからプッシュする技術(CometやWeb Socketなど)やオブザーバーパターン、後述するデータファブリックを使うという方法もある。
場合によっては、ユーザーに対してリクエストの受理と多少時間を要することを通知するだけでよい場合もある。
イベント駆動アーキテクチャ(EDA)
イベント駆動アーキテクチャ(EDA:Event Driven Architecture)とは、イベントを待機し、発生したイベントに応じた処理を行うアーキテクチャ。
複数のドメイン間で連携する分散処理が行える。
複数のヘキサゴナルアーキテクチャでのイベント駆動アーキテクチャは以下のようになる。
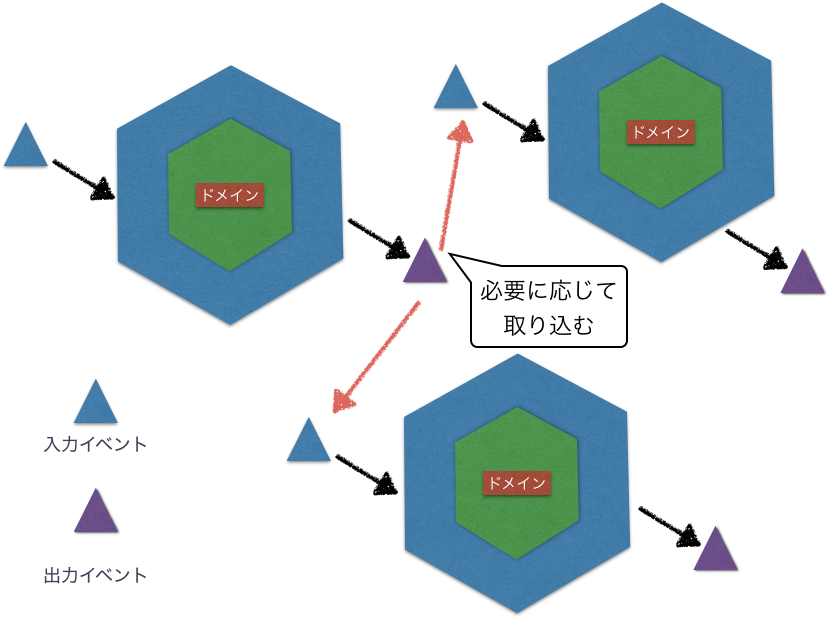
発行されたドメインイベントは、受信側の境界づけられたコンテキスト内で必要であれば使用され、不必要であれば無視する。
こうして、あるシステムが発行したドメインイベントを他のシステムのサブスクライバが受け取ることができる。
電話番号一覧から条件に一致する件数を出力するサンプル
実践DDD本で登場するパイプとフィルターパイプラインのサンプルとして、コマンドラインの例が記載されている。
サンプルとして、電話番号一覧から市外局番303に一致する件数を取得している。
Linuxコマンドラインで表すと以下のようになる。
cat phone_numbers.txt | grep 303 | wc -l
以降では、この処理を「パイプ&フィルターパイプライン」で紹介し、さらに並列パターンとして「長期プロセス(サーガ)パイプライン」で紹介している。
パイプ&フィルターパイプライン
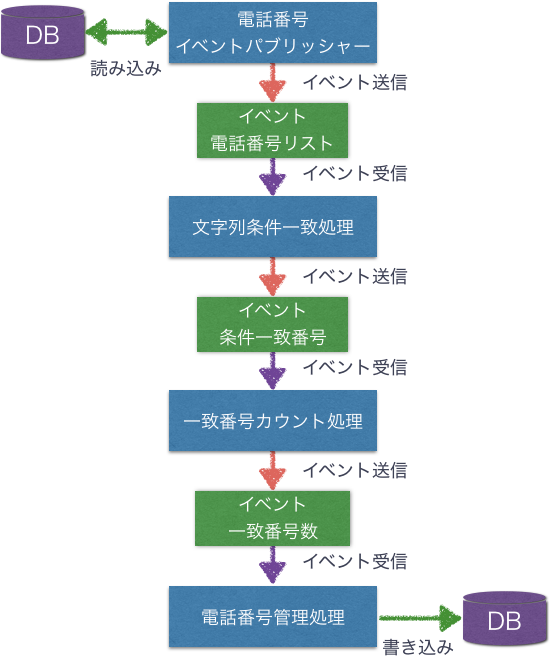
上図では、イベントを送信し、フィルターが処理を行うことでパイプラインを形成している。
「パイプ」はメッセージチャネルのことで、次に送るイベントを意味し、「フィルター」は受け取ったイベントに応じて処理するもの。これらの組み合わせでパイプラインを構築する。
パイプ&フィルターパイプラインは柔軟性が高く、新たなフィルターやイベントを追加しやすい。
DDDに置き換えると、最初のステップで境界づけられたコンテキストの集約の結果を元にドメインイベントを発行し、以降のステップでドメインイベントを受け取った境界づけられたコンテキストが、さらなるイベントの発行や集約の作成、更新をするといったことが考えられる。
長期プロセス(サーガ)パイプライン
イベント駆動で分散処理を並列に処理したい場合に、長期プロセス(サーガ)を利用する。
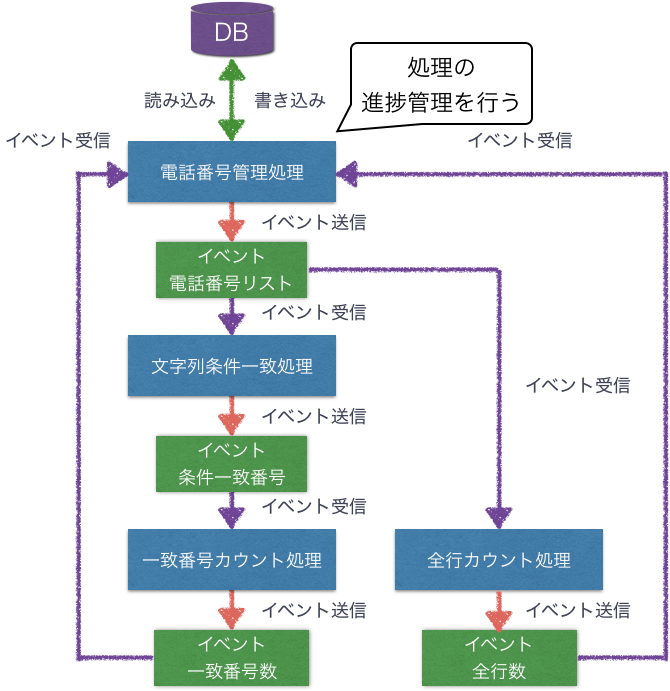
上図では、あるイベントから複数の処理を開始し、それらが完了するまで追跡するパイプラインを形成している。
長期プロセスは、レガシーシステムとの統合でレイテンシが気になる場合や分散処理や並列処理を扱うには有効。
採用するに当たっては、インフラストラクチャやアプリケーション障害の復旧、イベントのメッセージ管理などを考慮する必要がある。また、正常系だけでなく、失敗を想定したワークフローを組み込む必要があり、難易度が高い。
イベントソーシング
「イベントソーシング」は、オブジェクトが発生した変更を追跡・管理するというパターン。
Gitのような起こった全ての変更を追跡リビジョン管理システムに似ている。
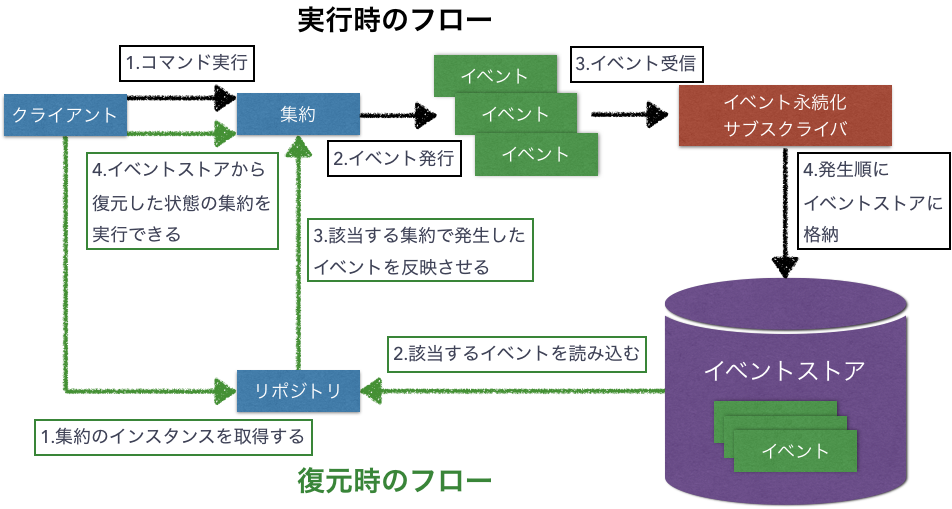
イベントソーシングは、上図のように発生した全てのイベントをイベントストアに格納する。
記録された最初のイベントからオブジェクトを復元し、過去の操作を完全に再現できる。
状態変更の履歴を追えるというメリットはあるものの、技術的・業務的に少なからず影響があるので、ビジネス的メリットを考慮した方がよい。
データファブリック(グリッドベース分散コンピューティング)
以下のような特徴を持ったもので、製品としてPivotalのGemFireやOracleのCoherenceが該当し、OSSとして、Apache GeodeやApache Igniteなどが存在する。
特徴として以下のようなものを備える。
- ドメインオブジェクトを永続化してキャッシュに格納
- マルチノードキャッシュとレプリケーションによる耐障害性の担保
- イベント駆動形式における送達保証のサポート
- キャッシュ変更通知
- 長期プロセスを伴うような分散並列処理
さいごに
改めて、どのアーキテクチャを採用するにしても、品質や機能要件に応じて適切なアーキテクチャを選択することが望ましい。
昨今ではオニオンアーキテクチャやクリーンアーキテクチャが登場しており、より具体化されているため、それらも踏まえた議論が必要だと考える。