はじめに
QualiArts Advent Calendar 2020、23日目の記事です。
私はQualiArtsでサーバサイドエンジニアをやっていまして、去年はGorgoniaについての記事を書きました。
この記事の対象者
- 自然言語処理に興味のある方
- 人と話せるbotについて興味のある方
- GPT-3って聞いたことあるけど何なのかよく知らない方
2020年10月の衝撃
私は日々人工知能系のニュースに関してはよく見ているのですが、10月に衝撃的なニュースがありました。
それは、botがRedditで1週間誰にも気付かれず人間と会話していたことが判明したというものです。
しかも、botであることがバレた理由も、発言内容がきっかけではなく、「投稿頻度や文章を作成する速度が非常に速いユーザーがいることを疑問に思った」というものでした。
botの一部の発言はすでに削除されてしまっていますが、これだけの発言をして発言内容がおかしいと思われなかったことは本当にすごいと思います。おそらく、発現頻度が調整されていればもっと長い間、人間同士の会話にバレずに混ざっていることができていたでしょう。
人と自然に会話するAIを夢見ている自分にとっては、これはとても夢のある話で、とてもテンションが上がったのを覚えています。
この記事ではそのbotに使われていた技術であるGPT-3とその基礎となっているTransformerについて簡単に説明します。
GPT-3
GPT-3は、OpenAI(イーロン・マスクが設立した人工知能を研究する非営利団体)が開発した文章生成言語モデルで、2020年6月にベータ版がリリースされました。
GPT-3のGPTとは、Generative Pre-trained Transformerの略で、__Googleによる言語モデルである「Transformer」を言語生成タスクで事前学習するモデル__ということです。このTransformerについては次章で説明します。
3とついているだけあって、このGPT-3が出る前には、GPT-1、GPT-2が存在します。
GPT-2も結構大きなニュースになっており、「あまりにも高精度のテキストを簡単に自動生成できるため、悪用されると危険過ぎる」として、全てをすぐに公開せず、小規模なモデルから9ヶ月程度かけて段階的に公開していったという過去があります(こういうところもSF感があって好きです)。
GPT-2とGPT-3ではモデルに差はありません。では何が違うのかというと、パラメータ数です。GPT-2ではパラメータ数が15億だったのに対して、GPT-3ではパラメータ数がそのおよそ100倍の1,750億となっています。
GPT-3の学習に使っているトークン(単語または単語の一部)の量もすごいです。トータルで5000億弱のトークンを使用しており、その内訳としては一般的なWebクローリングで4100億、その他厳選されたWebから190億、本から670億、Wikiから30億となっております。個人的に、学習のトレーニングデータといえばWikipediaのイメージが強かったので、その割合が低いことに少し驚きました。
ただ、それだけ多くの学習をおこなっているので、かかっているコストもすごいです。トレーニングには460万ドルから1200万ドルの費用がかかるとのことです。個人では到底できないですね…
このGPT-3は現在マイクロソフトが独占ライセンスを取得していますが、我々もそのAPIを使用することはできます。ただ、すぐに使用できるわけではなく、こちらの JOIN THE WAITLIST から申請できます。
Transformer
この章では
- Transformerが出てくるまでの技術
- Transformerがそれまでの技術とどう違うのか
について簡単に説明します。
Transformer以前
Transformerが出てくる以前のメジャーな自然言語処理モデルは、LSTM(Long short-term memory:長・短期記憶)に代表されるゲート付きリカレントニューラルネットワーク(ゲート付きRNN)にアテンション機構を追加したものでした。このアテンション機構がTransformerを説明する上で重要なものです。
RNNと、ゲート、アテンション機構について簡単に説明します。
RNN
RNN(Recurrent neural network:回帰型ニューラルネットワーク)は簡単に言うと、__直前の結果を入力として次の結果を決定するニューラルネットワーク__となっています。
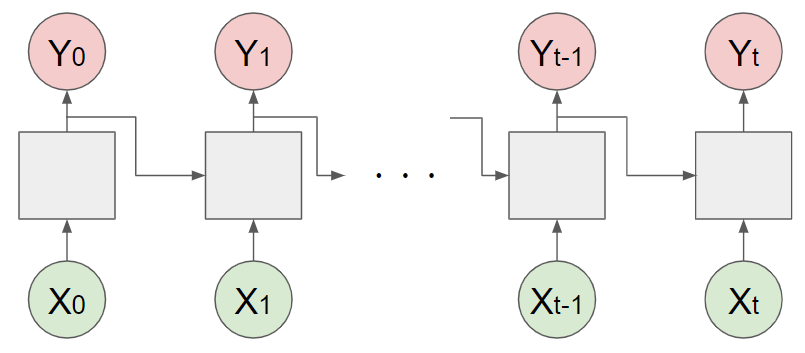
これにより、システムはある種の記憶を持つことができ、音声や文章といった時系列データをうまくあつかうことができるようになっています。
ゲート付きRNN
実はRNNには問題があります。それは、長期の依存関係を学習するのが苦手ということです。これは仕組み上、遠い過去の情報は、学習の途中で、意味のある情報が異常に弱まってしまう(勾配消失)、または異常に強まってしまう(勾配爆発)ということが発生しやすいことが原因となっています。
この問題への対処として考えられたのがゲートで、これは、次の計算に結果を渡す際、係数(0.0~1.0)をかけて渡す機構です(LSTMではこれに加えて記憶を失う、入力に係数をかけるなどをおこないます)。システムはこの係数も学習により獲得します。
アテンション機構
必要な情報だけに注意を向け、その情報から時系列変換を行う事により、より良い結果を得られると考えられます。
これは例えば、翻訳のタスクについて考えたとき、文章全体から単語一つ一つを選び出すのではなく、翻訳先の単語と対応関係にある翻訳元の単語がなにであるか選び出すということに注意を向け、翻訳を行うということに近いです。
そうするための仕組みがアテンション機構であり、具体的には、何に注目するべきか決めるため、__「入力の各単語の重要度を表す重みを計算」「重みと入力からコンテキストベクトルを計算」__をおこない、最終的には、この__コンテキストベクトルとLSTMの結果を用い出力を決定__します。
Transformer
2017年12月にGoogleの方が「Attention Is All You Need」という論文を発表し、その中でTransformerというネットワークアーキテクチャを提案しました。
Transformerの面白いところ、特徴的なところは、この論文のタイトルの通り、__これまでの回帰的な仕組みなどを排除し、先程説明したアテンション機構のみを残した__シンプルなアーキテクチャとなっているところです。
これにより、従来と比較して以下のような利点が出来ました。
- 並列化可能になった
- 学習に必要な時間が短くなった
- 品質がより良くなった
- 他のタスクにうまく一般化できるようになった
これまで基礎となっていた箇所がむしろ不要であったというのは本当に興味深い話ですね。
おわりに
なんとなくGPT-3とその基礎となった技術について理解した気持ちになれたでしょうか?
弊社では、グループ会社と協力して、それらの技術を応用して、スクリプターの業務を支援できないか挑戦しているところです。
その性能ゆえ、危険性も叫ばれている技術ではありますが、同時に今まで出来なかった支援ができるようになる技術でもあります。
この先どのようなものが出てくるか、みなさんがどのような応用をするのか、本当に楽しみでなりません。