初版:2020/3/10
著者:高重 聡一, 伊藤 雅博, 株式会社 日立製作所
はじめに
この投稿では、機械学習モデルを組み込んだシステム設計を行う際の、データ前処理の設計ノウハウとデータ前処理の性能検証結果について紹介します。
第2回目は、Pythonを用いたデータ前処理における性能向上ノウハウと検証結果について紹介します。
投稿一覧:
- 機械学習を利用するシステムのデータ前処理について
- 機械学習向けデータ前処理の性能検証(数値データ編)(その1)(本投稿)
- 機械学習向けデータ前処理の性能検証(数値データ編)(その2)
性能検証で参照したベンチマーク(BigBench)について
設計ノウハウや性能検証結果の紹介の前に、検証でリファレンスとして参照したベンチマークについて紹介します。今回は、ビッグデータ分析用のベンチマークプログラムの1つであるBigBenchを使用しました。BigBenchは、オンラインのe-コマースサイトにおけるアクセスユーザなどのデータを分析するシステムを模擬したベンチマークプログラムで、RDB上のデータやWebログなどの構造化もしくは半構造化されたデータを対象とした、30個の業務シナリオとベンチマークプログラムが定義されています。図 1にBigBenchのデータ構造を示します。
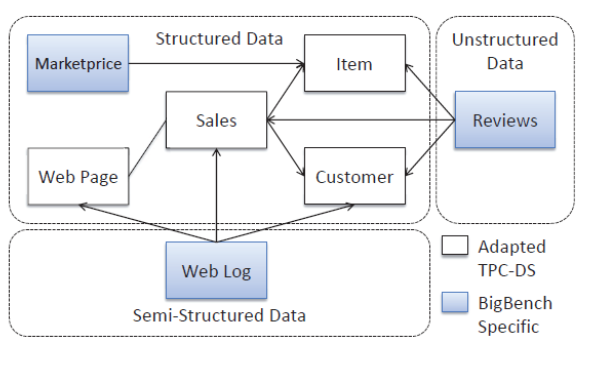
図 1 BigBenchのデータ構造
今回は、BigBenchの30個の業務シナリオの中で、最も処理が複雑で、なおかつデータ前処理の典型例ともいえる業務シナリオ#5を検証対象として参照し、独自にpythonで初期コードを実装しました。業務シナリオ#5は次のようなものです。
オンラインストアのユーザのWebアクセス履歴から、該当ユーザが興味を持つ製品のカテゴリを推定するロジスティック回帰モデルを作成する。
業務シナリオ#5の処理の概要を図 2に示します。
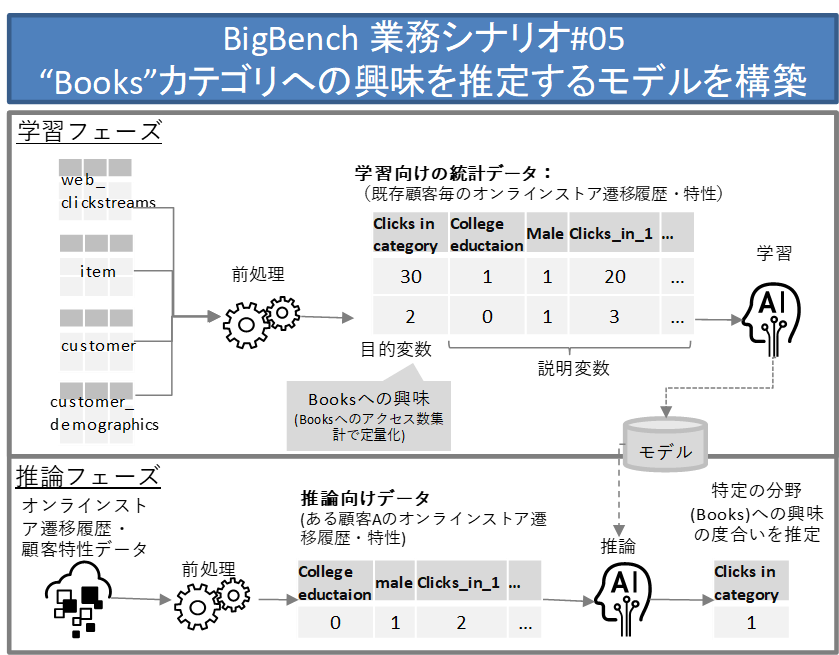
図 2 BigBench業務シナリオ#5の処理の概要
このシナリオは学習フェーズと推論フェーズに分かれています。
学習フェーズでは、Web上のオンラインストアへのアクセス履歴(web_clickstreams)や、製品情報のデータベース(item)、ユーザ(顧客)情報のデータベース(customer, customer_demographics)などの関連情報から、ユーザ(顧客)ごとのオンラインストアの遷移履歴や、ユーザの特性(学歴、性別など)を統計データとして整理します。この統計データをもとに、あるユーザが、特定のある分野(例えば”Books”)に興味があるかどうかを推定する回帰モデルを作成します。
推論フェーズでは、あるユーザについてアクセス履歴などを集計した統計データを作成し、それを学習フェーズで作成した回帰モデルに適用して、そのユーザが”Books”分野にどの程度興味を持つかを推定します。
ここで、業務シナリオ#5の中を参照して、今回の検証向けに実装したデータ前処理の流れを図 3に示します。
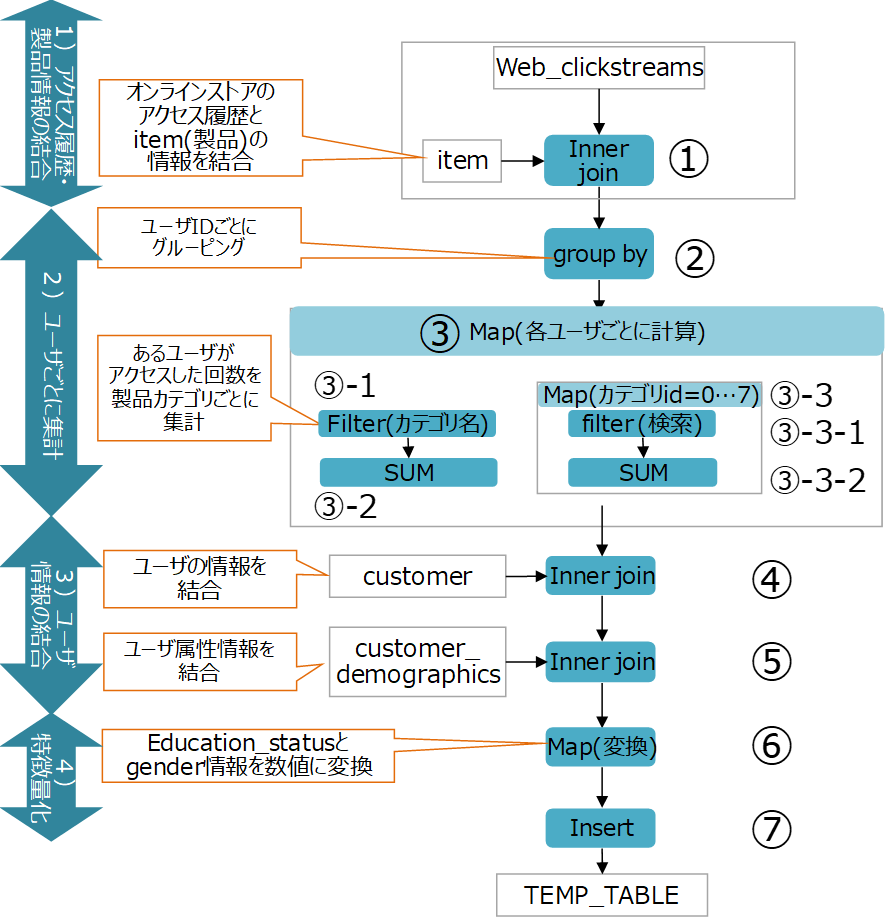
図 3 BigBench業務シナリオ#5の前処理アルゴリズム概要(学習フェーズ)
この前処理は以下の4つのフェーズで構成されています。
1) 【アクセス履歴と製品情報の結合】
Webアクセス履歴を製品DBと関連付けてカテゴリごとに分類できるようにします(図 3の①)。
2) 【ユーザごとに集計】
アクセスしたユーザごとに各カテゴリの製品を何回クリックしたかをテーブル上に集計します(図 3の②③)。
3) 【ユーザ情報の結合】
アクセスしたユーザの属性情報と、ユーザごとの集計情報を関連付けて、ユーザの属性による分類ができるようにします(図 3の④⑤)。
4) 【特徴量化】
機械学習で利用できるように、テキスト情報などを数値列に変換します(図 3の⑥⑦)。
BigBench業務シナリオ#5のPythonでのコーディング例
BigBenchの業務シナリオ#5について、Pythonでデータ前処理を実装した例を図 4に示します。今回はこのコードをもとに、処理の改善を検討していきます。
import pandas as pd
import numpy as np
# データ読み込み
web_clickstreams = pd.read_csv("web_clickstreams.csv")
item = pd.read_csv("item.csv");
customer = pd.read_csv("customer.csv")
customer_demographics = pd.read_csv("customer_demographics.csv")
# 処理①:アクセス履歴と商品情報の結合
data = web_clickstreams.loc[web_clickstreams['web_clickstreams.wcs_user_sk'].notnull(), :]
data = pd.merge(data, item, how='inner', left_on=['wcs_item_sk'], right_on=['i_item_sk'])
# 処理②:ユーザID単位でデータを分割
data = data.groupby('wcs_user_sk')
# 処理③: ユーザごとに集計
i_category_index = "Books"
types = ['wcs_user_sk', 'clicks_in_category']+['clicks_in_%d'%i for i in range(1, 8)]
def summarize_per_user(data_mr):
wcs_user_sk_index = data_mr.name
# ③-1,③-2 ある指定した製品カテゴリ(Books)へのアクセス数を集計する
clicks_in_category = len(data_mr[data_mr['i_category'] == i_category_index])
# ③-3 ‘i_category_id’==1…7について、それぞれ計算
# ③-3-1, ③-3-2 ‘i_category_id’==iのアクセスログの数を集計
return pd.Series([wcs_user_sk_index, i_category_index] + \
[len(data_mr[data_mr['i_category_id']==i]) for i in range(1, 8)], \
index = types)
data = data.apply(summarize_per_user)
# 処理④:ユーザ情報と結合
data = pd.merge(data, customer, how='inner', left_on=['wcs_user_sk'], right_on=['c_customer_sk'])
# 処理⑤:ユーザ属性情報と結合
data = pd.merge(data, customer_demographics, how='inner', \
left_on=['c_current_cdemo_sk'], right_on=['cd_demo_sk'])
# 処理⑥:特徴量化
data['college_education'] = data['cd_education_status'].apply( \
lambda x: 1 if x == 'Advanced Degree' or x == 'College' or \
x == '4 yr Degree' or x == '2 yr Degree' else 0)
data['male'] = data['cd_gender'].apply(lambda x: 1 if x == 'M' else 0)
# 処理⑦: 必要な情報を抽出して代入
result = pd.DataFrame(data[['clicks_in_category', 'college_education', 'male', \
'clicks_in_1', 'clicks_in_2', 'clicks_in_3', \
'clicks_in_4', 'clicks_in_5', 'clicks_in_6', 'clicks_in_7']])
# 結果を保存
result.to_csv('result-apply.csv')
図 4 BigBench業務シナリオ#5のコード例
Pythonでのデータ前処理設計ノウハウ: ロジックの最適化
まず手始めに、純粋なpythonの範囲内でできる改善から始めます。
Pythonのコーディングにおいては、性能向上のためのノウハウとしてロジックの最適化が重要になります。今回の対象業務のコードに対して大きな効果が見込めるロジック最適化として、以下の2点を検討、適用しました。
ループのpandas関数利用
forループなどで繰り返し処理を実行すると、Pythonの制約により、単一のCPUでのみ処理が実行されます。これを、apply, mapなどのpandas関数に書き直すことによって、内部的にマルチスレッドで並列実行され、高速化される可能性があります。
重複したループの簡略化
同じデータ範囲に対して場合分けで処理を行う場合、filterのようなデータの絞り込み処理を、異なる条件式で何回も実行していることがあります。このようなコードでは、同じデータ範囲に対して何度もデータの条件比較を行うため、実行効率が悪くなります。このような処理は1度のループで済ませるように書き換えることで高速化できます。
BigBenchの業務シナリオ#5におけるロジック最適化の例
-
ループのpandas関数利用
今回の例では図 4のコードの時点でpandasの関数を利用しています。
-
重複したループの簡略化
下記の図 5上側の最適化前のコードには、図 3中の「③-3 mapループ(0…7の繰り返し)」が書かれています。これを見ると、data_mrという配列の要素の’i_category_id’の列を参照し、その値がそれぞれ1~7になる要素の個数を数えています。この実装では、同じ範囲のデータを7回重複して検索しています。この処理をgroupbyを用いて書き換えることで、検索回数を1回にすることができるようになります。
改善前#【最適化前】全要素検索を7回実行 return pd.Series([wcs_user_sk_index, i_category_index] + \ [len(data_mr[data_mr['i_category_id']==i]) for i in range(1, 8)],\ index=types)改善後#【最適化後】全要素検索を1回のみ実行 clicks_in = [0] * 8 for name, df in data_mr.groupby('i_category_id'): if name < len(clicks_in): clicks_in[name] = len(df) return pd.Series([wcs_user_sk_index, i_category_index] + clicks_in[1:], \ index = types);
図 5 ループでの検索処理を一回の検索に置き換えた例
ロジックの最適化の効果検証
ここでは、図 5のロジック最適化の効果を実際に性能測定してみます。
検証環境
今回の性能検証では、AWSを使用しておりそのスペックは以下の表 1の通りです。
表 1 検証環境のハードウェアスペック
| Pythonデータ前処理検証環境 | |
|---|---|
| インスタンス | AWS EC2 |
| OS | CentOS 7 64bit |
| CPU(コア数) | 32 |
| Memory(GB) | 256 |
| HDD(TB) | 5(1TB HDD×5台) |
また、検証で利用しているソフトウェアのバージョンは次の表 2の通りです。
表 2 検証環境のソフトウェアバージョン
| ソフトウェア | バージョン |
|---|---|
| Python | 3.7.3 |
| Pandas | 0.24.2 |
| Numpy | 1.16.4 |
性能を比較する処理方式
今回は以下の2つの処理方式で性能測定を実施しました。
-
Pythonによるシングルノード処理(図 5のロジック最適化なし)
図 4のコードをPython上で実行します。 -
Pythonによるシングルノード処理(図 5のロジック最適化あり)
図 4のコードに対して図 5の最適化を実施したコードを、Python上で実行します。
測定の対象とする処理内容
測定では、次の3つの処理に要した合計時間を計測します。
-
データソースからのデータのメモリ上への読み込み
データを処理するために、処理に必要なテーブル(web_clickstream, item, customer, customer-demographics)のすべてのデータをディスクからデータフレームに読み込みます。読み込むデータはテキストファイルで、ローカルディスクからの読み込みになります。
-
読み込んだデータに対する、データの結合、集計などの前処理
-
処理結果のデータストアへの書き込み
ローカルディスクにテキスト形式でデータを書き出します。
測定対象データ
本番システムで処理されるデータサイズを50GB程度(メモリ上に展開された場合の見積サイズ)と想定し、その1/100のデータサイズから本番想定のデータサイズの間のいくつかのデータサイズで測定し、処理時間がどのように変化をするかを確認しました。
各測定サイズに対して、処理対象となる入力データがメモリ上に展開された際のサイズと、もともとテキスト形式でHDD上に保存されている際のデータサイズを表 3に示します。以降、測定結果でのデータサイズはメモリ上のデータサイズの値を使用しています。
表 3 測定データのサイズ
| 本番データサイズに対する割合[%] | 1 | 5 | 10 | 25 | 50 | 75 | 100 | 200 | 300 |
|---|---|---|---|---|---|---|---|---|---|
| データ行数 - web_clickstreams | 6.7M | 39M | 83M | 226M | 481M | 749M | 1.09G | 2.18G | 3.39G |
| データ行数 - item | 18K | 40K | 56K | 89K | 126K | 154K | 178K | 252K | 309K |
| データ行数 - customer | 99K | 221K | 313K | 495K | 700K | 857K | 990K | 1.4M | 1,715 |
| データ行数 - customer_demographics | 1.9M | 1.9M | 1.9M | 1.9M | 1.9M | 1.9M | 1.9M | 1.9M | 1.9M |
| メモリ上のデータサイズ (GB) | 0.4 | 1.9 | 3.9 | 10.3 | 21.8 | 33.7 | 49.1 | 97.9 | 152.1 |
| HDD上のデータサイズ (GB) | 0.2 | 1.0 | 2.2 | 6.3 | 13.8 | 21.7 | 29.8 | 63.6 | 100.6 |
| ※表中の行数のK, M, Gはそれぞれ千行、百万行、十億行の略称 |
性能測定結果
BigBenchの業務シナリオ#5に対して、2種類の処理(図 5のロジック最適化あり / なし)のそれぞれを、データサイズごとに実行して処理時間を測定した結果は図 6の通りとなりました。なお、処理できたのはデータサイズが約22GB(本番データサイズの50%)までで、それより大きいサイズのデータを処理しようとすると、メモリ不足で処理することができませんでした。ここで、入力データサイズが0.4GBの場合(図 6のグラフの一番左の点)はロジック最適化なしの場合の実行時間が412秒、ロジック最適化ありの場合が246秒で約40%短縮されました。また、入力データサイズが22GBの場合(図 6のグラフの一番右の点)はロジック最適化なしの場合の実行時間が5,039秒、ロジック最適化ありの場合が3,892秒で約23%の短縮にとどまりました。
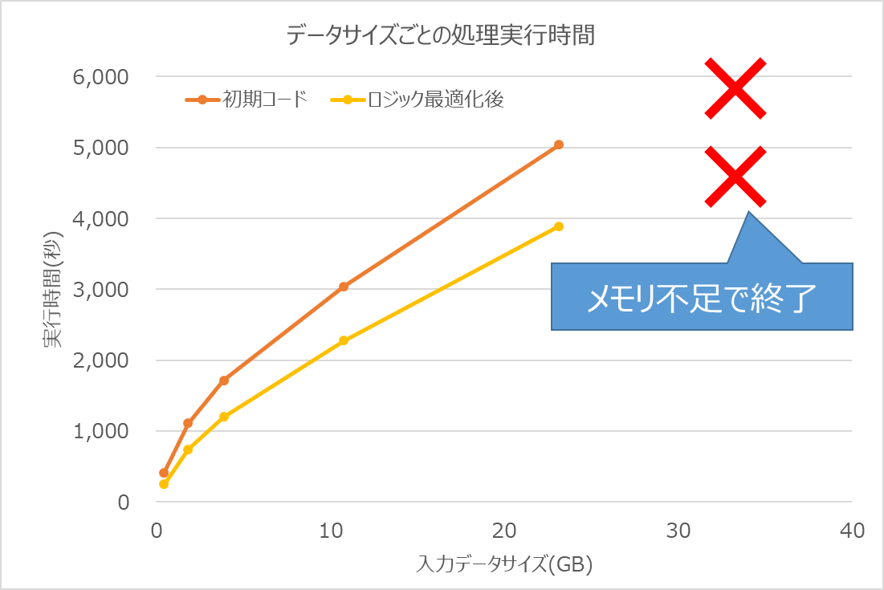
図 6 入力データサイズごとのデータ前処理時間測定結果
また、サイズ22GBのデータを処理した際のCPU, メモリ、ディスクI/O使用量の経過を図 7 に示します。今回検証マシンは32コアを備えていますが、Pythonは1コアしか利用できません。そのため、CPU利用率は常に1/32=3%程度となってています。一方で、メモリ上で22GB程度のサイズの入力データに対する処理に、200GB程度のメモリを消費している様子が分かります。これは、データ処理中、中間処理結果がメモリに保持されるため、そのサイズも合わせて消費されているためと考えられます。
I/Oは初期のデータ読み込み時のみ行われており、データ処理中はI/Oが発生せずに基本的にはオンメモリで処理されていることも確認できます。
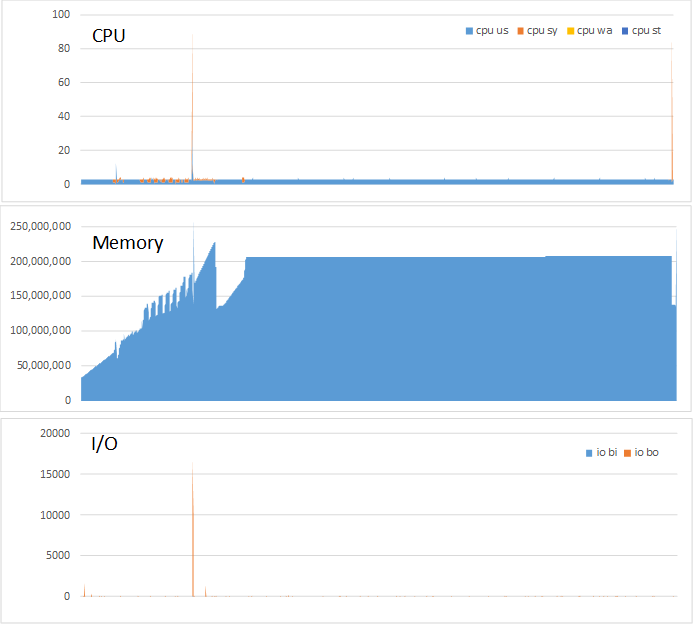
図 7 Python+Pandas環境でのCPU、メモリ、I/O使用量の時間的変化
ロジック最適化による効果と注意点
同じデータを繰り返し検索することを避けるロジック最適化により、40~23%の性能改善効果得られることが確認できました。このとき、データサイズが増えると性能改善効果が減少しましたが、これは改善効果がデータの特性(値の範囲や分布)に依存していて、データサイズが増加した際に、その特性が変化したためだと考えます。
そのため、PoCなどで本番とは異なるサイズの(小さいサイズのサブセットの)データで過度にロジックを最適化しても、本番規模のデータでは効果が変わってくる可能性があります。したがってロジック最適化は最後のチューニングで実施することを推奨します。
おわりに
本投稿では、Pythonを使用した数値データ前処理の性能向上ノウハウ、また、実機での性能検証結果について紹介しました。次回は、数値データ前処理に並列分散処理基盤であるSparkを用いた場合の性能検証結果について紹介します。