初版:2020/3/3
著者:高重 聡一, 伊藤 雅博, 株式会社 日立製作所
はじめに
この投稿では、機械学習モデルを組み込んだシステム設計を行う際の、データ前処理の設計ノウハウと数値データ前処理の性能検証結果について紹介します。
第1回目は、機械学習システムのデータ前処理とその設計の概要について紹介します。
投稿一覧:
- 機械学習を利用するシステムのデータ前処理について (本投稿)
- 機械学習向けデータ前処理の性能検証(数値データ編)(その1)
- 機械学習向けデータ前処理の性能検証(数値データ編)(その2)
AI案件の概要と流れ
機械学習をはじめとするAI技術を活用したデータ分析が注目を集めており、AIを活用した案件が増加しています。AI案件ではお客様のデータを分析することで、何らかの知見を得たり、予測を自動化したりするための機械学習モデルを作成します。
AI案件は多くの場合、1)データ分析の専門家であるデータサイエンティストが中心となってPoC(Proof of Concept)を行い、データ分析や機械学習モデルの有用性を確認、2)その成果をもとにシステムエンジニア(以下、SE)が本番システム化する、という2段階で実施されます。データサイエンティストによるPoCの成果物は、お客様に提出する報告書のほかにPythonなどの言語で記述されたソースコードがあり、これを元にSEが設計を行いシステム化します。
システム化における課題
PoCの成果物を元にしたシステム化の課題の一つに、本番環境におけるデータ量の増加があります。PoCはあくまで検証であるため、顧客から預かるデータ量は少量であることが多く、大量のデータがある場合でも素早く検証を行うためにデータをサンプリングして使用することが多いです。このように、PoCでは1台のデスクトップマシン上で処理できる程度の、少量のデータを使用するのが一般的です。一方、機械学習システムはデータをもとに学習を行うため、データ量が多いほど予測精度が高まるという特性があります。そのため本番システム化の際には、予測精度を高めるために大量のデータを使用することが多く、機械学習システムには高いデータ処理性能が求められます。
また、機械学習のモデルをデータサイエンティストが扱うのに対して、データ前処理はSEをはじめとするエンジニアが中心に設計を進めることが一般的です。データ前処理は機械学習のモデルと密接に関連した技術ですが、そこでは基盤設計やサイジング、失敗時の障害処理、などSEとしての知識も求められます。
その際、SE側で前処理をコストと時間をかけて一から再設計、再実装することは効率的ではありません。そこで、データサイエンティストがPythonなどで開発したプロトタイプを活用してシステム化を進めるアプローチが有効となります。しかし、このような設計のノウハウに関する公開情報は現在それほど多くありません。
本投稿では、PoCの段階を終え、機械学習モデルを組み込んだシステム設計を行うSEを対象として、性能検証の結果から得られた知見をもとに、データ前処理の設計手順とポイントを紹介します。
機械学習システムにおけるデータ前処理の概要
機械学習システムにおけるデータ前処理
機械学習を用いるシステムでは、主に学習、推論、再学習の3つのフェーズにおいてデータ前処理を実行することが考えられます。図1にその概要を示します。

図 1 機械学習活用システムの全体像
-
学習時のデータ前処理
様々な形式で格納されたデータセットから、あるモデルを学習するために適したデータの構造に変換したり、精度などを高められるようにデータの正規化や集計を行ったりする処理を行います。学習時の前処理では全データを一括で処理するケースが多く、推論時に比較して処理量が非常に多い傾向にあります。
-
推論時のデータ前処理
推論では、モデルを利用して、実際の運用の現場から収集したデータに対して分類や傾向の予測を実行します。推論では数秒単位などのレイテンシの要件が課される場合もあり、この場合は前処理に対してもレイテンシの要件が課されることになります。
推論時のデータ前処理は、学習時と同じ特徴量を持つように変換を行う処理となりますが、推論対象のデータのみに対して実施され、また、処理が簡略化される場合もあります。一方で、モデルの利用ごとに処理を実行する必要があるため、本番稼働するシステムで継続的に呼び出される頻度が高くなります。 -
再学習時のデータ前処理
運用現場の実データによって、学習に転用できるデータが蓄積された場合、それを利用してモデルを更新する運用を行う場合があります。そのような場合には学習時のデータ前処理と同様の処理を行うことになります。
データ前処理の設計における課題と解決方針
データサイエンティストによるPoCは少量のデータで実施することが多いため、PoC時にはPythonで前処理が実装されることが多くなっています。一方、システム化の際にPythonで前処理を実装しようとすると以下の表 1に示すような課題が発生します。なお表 1にはその課題の解決策案も合わせて示しています。
表 1 データ前処理システムの課題と解決策
| # | 課題 | 解決策案 |
|---|---|---|
| ① | 対象とするデータ量が膨大であるため、前処理に非常に時間がかかる | ビッグデータ処理基盤活用 データ量が大きい場合にはPythonなどで書かれた前処理をSparkなどの処理基盤で並列分散実行できるように設計・実装 |
| ② | ①でビッグデータ処理基盤を活用した場合、前処理の再実装が必要となり工数がかかる | PoC段階からのシステム化を見据えた前処理実装 Spark化する際に大きな変更なしで動作するようなPythonの処理実装方式をPoC時に採用して実装する。 |
機械学習を活用するシステムの設計プロセス
機械学習を活用するシステムは、図 2に示すような流れで設計します。本投稿のはじめに述べたように、機械学習の有用性を確認するPoCを実施し、そこで有用性が確認できたロジックをシステム化するのが一般的です。
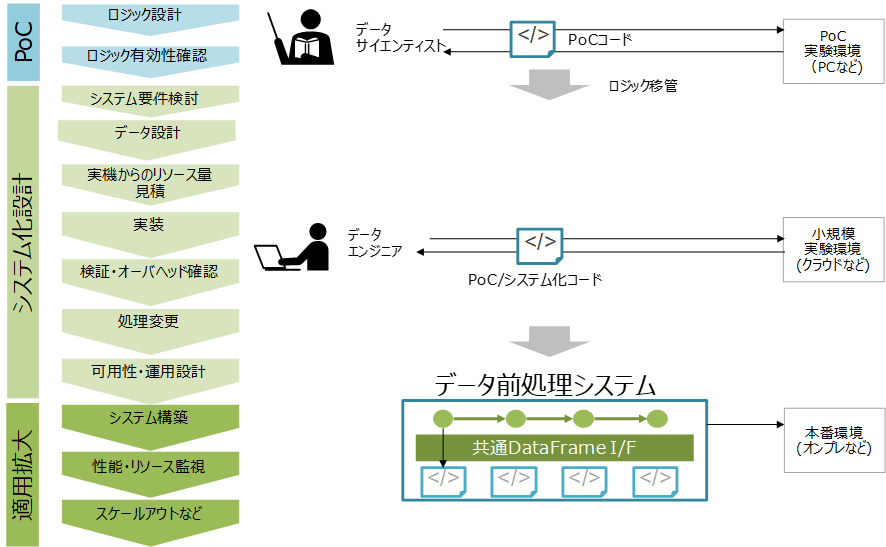
図 2 機械学習を活用するシステムの設計プロセス概要
機械学習を活用するシステムには、図 1に示したように大きく学習システムと推論システムがありますが、以降、今回は学習システムについて取り扱っていきます。なお、一般的に推論システムは学習システムと比較して
- 1回の推論で用いるデータ量は小さい
- 1回の推論の実行時間(レイテンシ)に関する制約が大きい
という傾向にあります。
学習時の前処理設計
学習システムのデータ前処理を設計・実装する場合の、設計項目は表 2の通りです。ここでは、機械学習に特徴的な部分のみ示しています。
表 2 学習システムの設計項目一覧
| # | 設計項目 | 内容詳細 |
|---|---|---|
| 1 | システム要件の検討 |
|
| 2 | データ設計 |
|
| 3 | 実機によるリソース見積 |
|
| 4 | 実装 |
|
| 5 | 可用性設計 |
|
| 6 | 運用設計 |
|
リソース見積もり
学習システムにおいて、もっとも重要な観点は、対象とするデータを用いたモデル開発が、システム要件で求められる期間内に完了できるか、ということです。PoCのフェーズでは、対象とするデータは一部の期間、(機器や帳票などの)一部の対象に絞って取り扱うことが多いですが、その後のシステム化では全期間や全種類のデータを取り扱うことにより、データ量が膨大になることがあります。前処理についても、大きなデータに対して許容できる処理時間内で処理を終えることが可能なように、システム化設計において必要なリソース(CPU数、メモリ量)を見積もることが重要となります。
前処理に必要なリソースを求める場合、まずは前処理内の各処理について、小規模のデータセットを用いて入出力データサイズと処理時間を確認します。また、第2回以降で述べる、処理ロジックの最適化での効果が期待できる処理(繰り返し回数の多い処理)についても確認しておきます。
リソースのうちCPU数については、小規模データセット使用時の入力データサイズと処理時間をもとに、本番システムでの入力データサイズから本番システムの処理時間を見積もります(このとき、処理時間はデータサイズに比例するものとします)。この時間を、システム要件で定められた処理時間で割ることにより、必要なCPUのおおよその数を見積もることができます。
メモリ量については小規模データセット使用時の各処理の入力データサイズをもとに、本番システムでの各処理のデータサイズを見積もり、その合計サイズで概算します。
データ処理基盤の選択
本番前処理システムのデータの前処理を実行する基盤として、Pythonで書かれたPoCコードをそのままPythonとして実行する環境を構築するか、Sparkなどの分散処理基盤で実行すべきか、を判断することが必要です。
基本的には、必要リソースの見積もりの結果、メモリが不足しそうな場合はSparkを、メモリ量が問題ない場合にはそのままPythonで前処理する方針となります。
おわりに
本投稿では、機械学習を利用するシステムのデータ前処理とその設計の概要について紹介しました。次回は、Pythonを使用した数値データ前処理の性能向上ノウハウ、また、実機での性能検証結果について紹介します。