背景
サイネージ端末がよく死ぬ
- 無線電波が弱い
- HDMIケーブルがスポスポ抜ける
- SDカードがヘタってる
壊れてなくてもヘタると読み書きが数十倍遅くなってくる。 - HDMIケーブルの品質が悪くて干渉に弱い
- モニターがヘボい
- 端末が壊れる
- モニターが壊れる
監視機能は?
本来できているはずだがまだ作っている最中。すんません。結構難しい。なんでかっていうと、
- 状態や履歴のレコード数がそこそこ多い
- 1レコードの構造も結構複雑
- できるかぎりニアリアルタイムが好ましい
- そもそも上で書いた障害対応などに時間を取られている
1日7時間かけて対応していたりする。
負荷見積もり例
将来見越して50,000台端末があるとして、それらが5分に1回状態と履歴を送信する場合。
- 平均で300レコード/秒超
コンテンツファイルダウンロード時など、イベント次第ではこの10倍以上くる。
普通にデータベース使うと、金かかるか負荷ですぐ行き詰まる。Bigなんとかとかsparkとかでもいいか、金の心配やGC/偏りチューニングが難しい。
それなりに金かければ難しくないかもしれないが、会社というものは往々にして渋いので、金も時間もかけずに頭だけ使って解決したい。
それでも死ぬ。サイネージは。毎日。
とりあえずイージー版をつくろう。
だったら、既に状態データはMQTT経由で送信しているので、それを活用すれば大抵の監視ができることに気づいた。
- DuckDB
- DuckLake on GCS
を使って、イージに超低価格データレイクを作ってみる。
DuckDBとは?
- SQLiteみたいなやつ
- ファイル: text,sqlite,csv,json,avro,parquet,excelなどの読み書き
- DB: PostgreSQLやMySQLなどにアクセス可
- ローカル/リモート問わずファイル/データベースの異種JOIN可
- 各種言語向けライブラリーあるし、cliもあって開発しやすい
DuckLakeとは?
- DuckDBを使った軽量データレイクハウス
- メタデータ: PostgreSQL,MySQL,SQLiteファイル,DuckLakeファイル
- 実データ: parquet(ローカルまたはクラウドストレージ)
- DuckDBのextensionとして利用する
- DuckDB cliから使える。
DuckLake/DuckDBの何がお手軽か?
- メタデータとしてファイルが使える
icebergなどで必要とされるカタログサーバーが不要。 - DuckDBはブラウザー上(wasm)でも動く
つまり、メタデータもデータもクラウドに置くと、
- データベースやカタログサーバーなどのインスタンス不要
- wasm頑張れば、ブラウザーだけあればバックエンドも不要
頑張れば、クエリーに関してはクラウドストレージのread料金だけで済むし、速いのでいいじゃないか。(収集/集約時のwrite料金は当然かかります)
構成
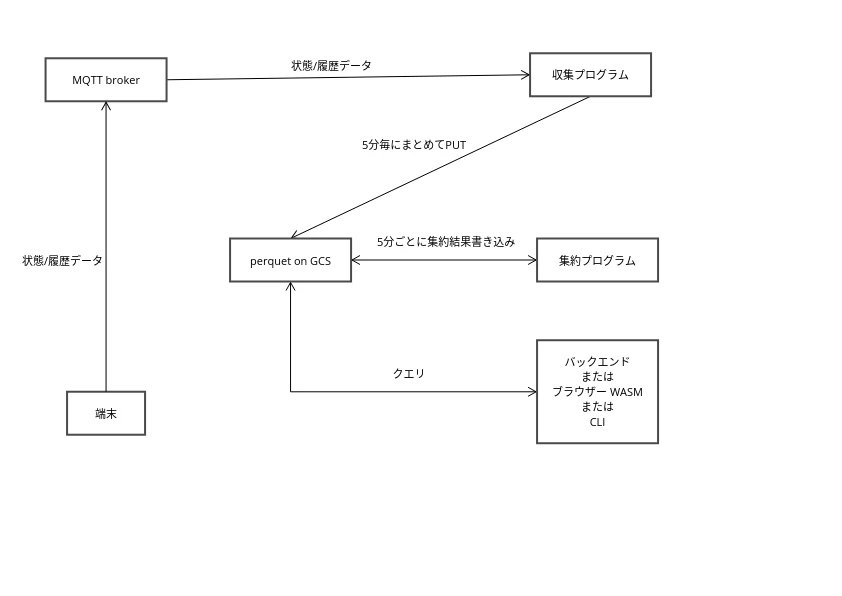
今回作ったもの
-
収集プログラム
MQTT broker経由でやってくる端末状態レコードを収集。DuckDBライブラリーを使い、GCSにparquetとしてhive partitioningを効かせて保存。
小さいparquetはまずいので、5分または100000レコードでバッファリングして書き込みしている。 -
集約プログラム
5分ごとに、DuckDBライブラリーを使って前回以降の新しいparquetファイルを読んで、GCS上の集約テーブル(parquet)に集約&MERGE INTO。
注意点
スタティックなDuckLakeをクラウドストレージで公開する手法は、Frozen DuckLakeと呼びますが、今回のは都度更新していく応用です。
-
メタデータがクラウドにあるままではREAD ONLYになる
集約前にメタデータダウンロード、集約後にメタデータアップロードすることで回避。もちろん実データそのものはクラウドに直接書き込む。 -
ローカルメタデータを使って、実データをリモートに書き込む形態だと、何かあったらデータが壊れるんじゃないか?
icebergと同様で、DuckLakeは意図しない限りデータファイルの削除も更新もしません。メタデータ内にはデータファイルへのポインターがあるので、たとえ実データをクラウドに書いている最中に障害起こっても、前のメタデータはそのままであり、前のファイルへのポインターのままなので大丈夫。 -
大丈夫なんだけど、クエリーしている最中にメタデータ変わったらエラーでることがあるので、設定でEtagチェック無効にするかセッションのリトライでカバーすること。
-
その他walファイル同期、expire、compaction設定などいろいろハマりポイントはある
-
DuckLakeは来月v1.0リリース予定
ちょっと変なバグに遭遇したので本当は1.0でやりたかった。
まとめ
- サイネージは毎日壊れる
- データレイクまでいかなくても、DuckDBは異種JOINなど便利に使えるし、v1.5からcliも便利になったので使ってみたら。
- 今回の都度集約/更新はめんどくさいが、スタティックなデータレイクを社内/社外に公開するのは簡単なので使ってみたら。
- 今回wasmのでもやろうと思ったけどフロントエンドよくわからない。ネット上にブラウザー上でクエリーやる例がいろいろあるので見て。
https://voluntas.github.io/duckdb-wasm-parquet/