はじめに
2018年4月から2019年2月までの10ヶ月の活動記録をまとめてみました。
基礎編はプログラミング初学者の私がPythonとKerasを勉強した過程、
実践編は医療機関で医用画像認識のお仕事をいただいたときに読んだ主要な論文です。
番外編にやってよかった勉強会について書いてみました。
ここで取り組んだいくつかの論文(共著)が医学学会でアクセプトされたのはとてもありがたいことでした。
まずはじめに、2018年4月の私と、2019年2月の私の比較です。
2018年4月
- あーPythonね。ヘビ飼ってんの?
- パソコン詳しいひとがいじってる黒い画面でてきた!こわい!
- ロロロジスティックカイキ?????
2019年2月
- PythonもUbuntuも少しはいじれるようになった
- 画像分類とか物体検出とかセグメンテーションにちょっと強くなった
- 自然と論文を読むようになった
- (色んなお医者さんと仲良くなった)
色々できることは増えましたが、初学者が脱初学をしたぐらいのレベル感なので、ディープラーニングの細かい理論はまだまだよくわかっていないですし、最新の物体検出モデルを一から実装しろと言われてもしんどいので、このあたりができる方達は本当にリスペクトです。それでもスーパーマンたちが考えたり、実装してくれたものを現場に持ち込み、おおむね前処理芸人と化しながら、学習・推論・良い感じの可視化を通して、周囲の誰かに貢献するのも重要な役割だとわかりました。
基本編
ProgateでPythonをやる
こちらを何周かしたことでPythonの最低限の書き方を身につけられました。やっている時はこれだけで大丈夫なのかな...と思いながら、後々大丈夫ではなかったと気づくのですが、何よりわかりやすくて基本を押さえるには十分でした。
ゼロから作るディープラーニングを読む
勉強を始めるためにとりあえず本屋に行ったとき「この本めっちゃ売れてるで」的な帯が書いてあったのと、知り合いが「いいから黙ってオライリー」と言っていたので最初にこれを読みました。Pythonのインストールからニューラルネットの基本、そしてその先までまさにゼロから書いてあるので初学者の私にはうってつけでしたが、なんだかんだこちらだけではまったくイメージが湧かず、結局1読んだら10ググるみたいな状況でした。
Kerasに触れる
- 全結合でMNIST
- CNNでMNIST
- CNNでCIFAR10
- CNNで適当に集めた画像を分類してみる
ここでの試行錯誤が最もハードで最も学びが多かったです。初学者にはKerasがわかりやすいということで取り組んでみたものの、そもそも土台となるPythonをわかっていないので、吐かれるエラーがPython的なエラーなのかKeras的なエラーなのかさえ理解できず、半泣きでGoogle先生に縋っていました。そんなときは知り合いのエンジニアの「エラーの数だけ強くなる」という言葉を思い出すことで「はいエラー、ありがとうございます!」と自己啓発をしていました。正直これらをやってもPythonはおろか、Kerasの知識も圧倒的不足状態でしたが、以降の実践編で基本編以上に苦戦するなかでこれらの不足を埋めていくことができたと感じます。
実践編
SSD: Single Shot MultiBox Detector
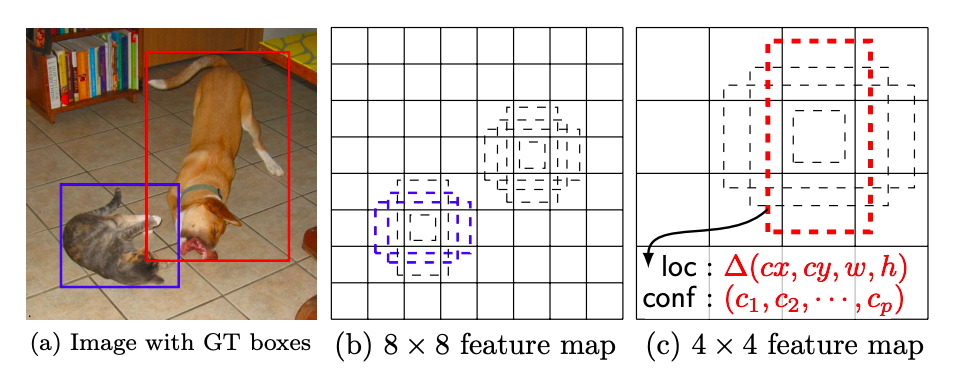
(画像は下記論文より)
https://arxiv.org/abs/1512.02325
https://github.com/rykov8/ssd_keras
続いて取り組んだのが物体検出で、画像を入力するとどこに(物体を囲う矩形の座標)何があるか(その矩形内にある物体のクラス)を出力してくれるやつです。物体検出のアルゴリズムには1 stage approach と 2 stage approach の2つがあり、簡単にいうと1stageは推論が速いが精度が低い、2stageは推論が遅いが精度が高いという特徴があります。SSDは1 stage approach の1つです。
私は上記のKeras実装のリポジトリを活用しました。
ここでPythonのxml, os, opencvモジュールを知り、さらにnumpy, matplotlibの理解を深められたと思うので、とりあえず走りながら知識を獲得していく勉強スタイルの効率の良さを実感しました。具体的な処理についてですが、GeforceGTX1080Tiで25FPSほどの速さなので、違和感なくリアルタイムで推論を行うことができます。しかしbatch size が大きいと推論が遅くなるので、batch sizeは1か2にするのが条件です。そして注意点としてこのリポジトリはKeras1系で実装されているので、Keras2系で動かすにはいくつか修正する箇所があり、下記を参考にしました。
https://github.com/keras-team/keras/wiki/Keras-2.0-release-notes
Focal Loss for Dense Object Detection
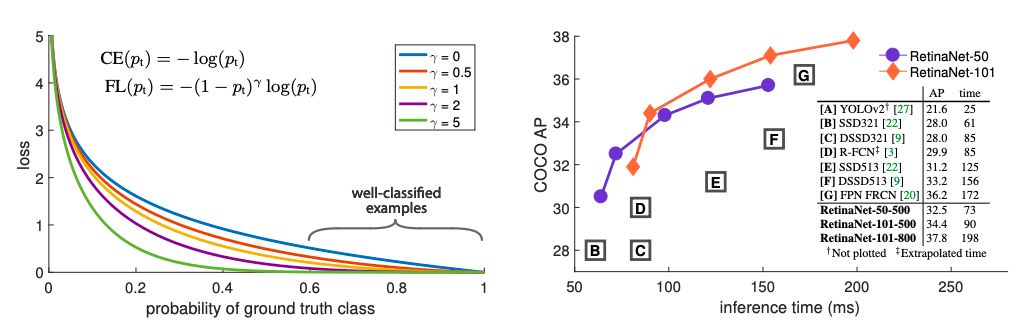
(画像は下記論文より)
https://arxiv.org/abs/1708.02002
https://github.com/fizyr/keras-retinanet
こちらも物体検出で、論文の核はFocal lossという損失関数です。
1 stage approachの精度が低い原因がeasy negative(物体が全く写っていない背景のみの領域)の膨大さであることを突き止め、既存のクロスエントロピーに簡単な重みをつけることで精度を改善したという感動的な論文です。ちなみに2 stage approachは最初のステップで物体が存在する領域の候補を抽出することでeasy negativeを削減しています。論文では同時にRetinaNetという物体検出モデルが提案されており、RetinaNetは上記のKeras実装のリポジトリを活用しました。12FPSほどの処理になりますが、とにかく精度が高いです。
U-Net: Convolutional Networks for Biomedical Image Segmentation
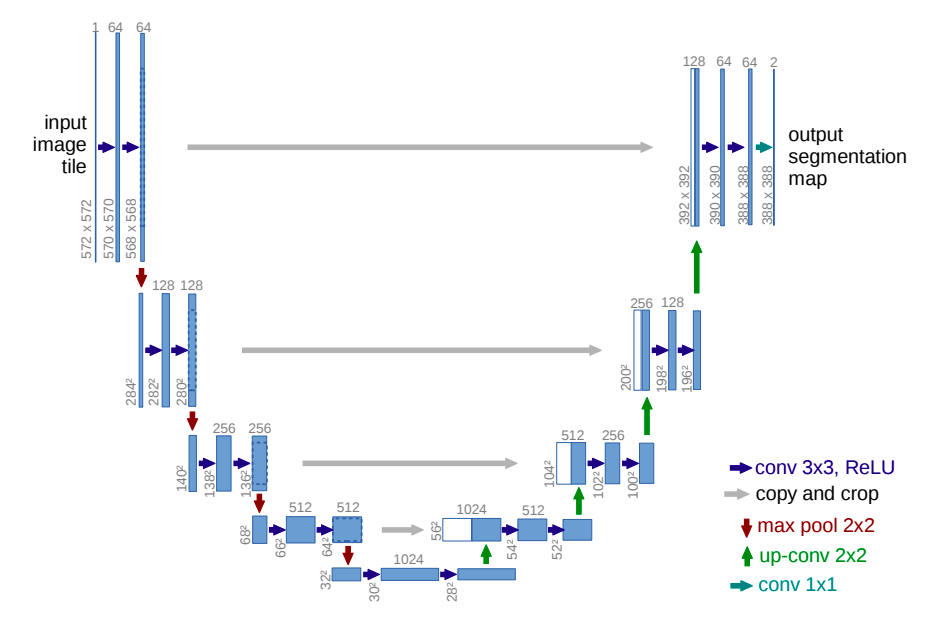
(画像は下記論文より)
https://arxiv.org/abs/1505.04597
https://github.com/zhixuhao/unet
物体検出と同時に取り組んだのが、セマンティックセグメンテーション(以下セグメンテーション)です。画像を入力すると、各ピクセルが何のクラスに属するか分類して、塗り絵のようなマスク画像を出力します。Deeplabv3など他のアルゴリズムもありますが、U-NetもSSDと同じく30FPS前後の速さなので、リアルタイム性を重視したときにU-Netがベストでした。セグメンテーションは物体検出と違い、インスタンスの区別ができません。例えばりんごが2つ重なり合いながら写っていると、物体検出ではりんごを2つ検出できますが、セグメンテーションはりんごの領域をすべて塗りつぶすので、出力のマスク画像だけではりんごが2つあるという情報は得られません。これを解決したMask-RCNN(インスタンスセグメンテーションが可能)というアルゴリズムもありますが、もちろん処理に時間がかかります。
まとめ
これらを用いて、内視鏡の動画や画像からポリープを検出したり、細胞の病理画像が陽性か陰性かの分類をしたり、他にも手術動画に対して画像認識をしたりしていました。前者の2つは論文として医学系の学会であるDDW(Digestive Disease Week 2019)にそれぞれポスターとオーラルで採択され、共著者として掲載していただきました。(学生の頃は学会に行ったこともないので、ポスターとかオーラルってなんなん?っていう状況でした...)
番外編(勉強会)
仕事のメンバー(当時は3人)と行っていた勉強会が非常に有益なものだったので共有します。
毎週日曜の朝7時からスカイプで1時間
日曜の朝7時から予定があることは少ないだろうということでこの時間になりましたが、土曜に飲みすぎたときを除いて、このスタイルは最適だったと思います。
毎週2人が発表担当(1人が実装、1人が論文)
実装は簡単なものでもいいというのが私がこの勉強会に参加し続けられた理由だったとも思います。ここではデータオーグメンテーションやgrad-camや半教師あり学習、Kerasの挙動等(他にもたくさん)を学びました。論文もルールは決まっておらず、気になったものや必要なものを読み、簡単にまとめて共有するというものです。
自分を除く2人は優秀な大学院生だったのでついていくだけでも必死(おそらくついていけてなかった)でしたが、こうして誰かに発表する場が設定されているだけで、何か役に立つ検証をしようというモチベーションにもつながりますし、なにより時間があればモジュールのドキュメントを確認したり、論文を漁ったりする癖がつきました。何より自分のつたない実装や論文共有でもマウントを取らず、褒めてくれ、こうしたらもっとよくなるかもと提案してくれた2人に感謝です。
おわりに
発展が著しい分野や業界のスピード感を体感したいというのが、深層学習の勉強をはじめたひとつの理由でもあったので、自分が使っているアルゴリズムを超えてSOTAとなった論文を読んでいる間に、さらにそれを超える論文が発表されるような感覚はとても刺激的でした。
同時に自分のキャリアをどう築いていくかについても随分考えさせられましたが、ここで培ったキャッチアップ能力は今後もどこかで活かせそうだなという感想で締めさせていただきます。
最後までご覧いただき、ありがとうございました。