はじめに
普段は自然言語処理の研究として,金融テキストを対象にした研究をしています.
研究で扱ってる内容は,共同研究の内容であるため外部に公表できなかったり,公表できるものは学会発表したり,論文投稿したりでまとめるため,記事にし直すことがなかったので,新たに記事にできるようなことをやり始めることにしました.
この記事では,アニメ「けものフレンズ」のサーバルのセリフをマルコフ連鎖で自動生成する方法を紹介します.

(著作権とかよくわからないから,安定のイラスト屋)
記事の流れとしては,
- データの取得
- N階マルコフ連鎖について
- 実装
- 考察
- まとめ
となります.
けものフレンズのテキストデータの取得
セリフのデータは,akahukuさんのGitHub上にあるものを使わせていただきました.
本当こういうデータには,感謝しかないです.
このテキストデータは,どのキャラクターが話しているかのlabelが付与してあるので,サーバルのセリフだけを取り出すことができました.
もともとこのデータを探してたのは,セリフ自動生成ではなく,pytorch による文章分類の実装を勉強したくて,分類に使えそうなデータを探していたときでした(セリフ分類の記事はまた別の機会に書く予定です).
ちなみにサーバルのセリフ自動生成にした理由は単純にセリフが一番多かったからです(長いセリフと短いセリフ合わせて812).
本当は,ツチノコや博士で作りたかったのですが,残念ながらデータ数が圧倒的に不足してました.
本当は,細かいデータの加工とか書くべきだと思うのですが,記事が無駄に長くなってしまうので省略しますが,文字をすべて全角でそろえた以外に特殊な処理は行っていないです.
収集したデータから,下記に示すようなデータを抽出しました.
博士 ではお前達、これを見つけてくるのです。
博士 陸地を走る時に必要なのです。頭を使うのです。
博士 似たようなバスは、いくつか島で目撃されているのです。まずはそれを探すのです。
博士 しょうがないですね。遊園地にバス的なものがあるのです。
博士 お前らにはそうですね、これぐらいがいいのです。
:
サーバル やっぱり、もうちょっと付いていこうかなって。
サーバル お友達になろうよ!
サーバル うわぁ!ボス!?
サーバル しゃべったー!?
N階マルコフ連鎖について
マルコフ連鎖と実装に関しては,@k-jimonさんの[Python]N階マルコフ連鎖で文章生成という記事がとても参考になりました.
正直,この記事で0から書く必要性を感じないほどです.
マルコフ連鎖による文章生成に関して,直感的にわかりやすい説明が,「マルコフ連鎖による文章生成」に書かれています.
一応,リンク先の記事がなくなってもいいように,この記事でも簡単に紹介します.
マルコフ連鎖
とりあえずWikipediaより.
マルコフ連鎖(マルコフれんさ、英: Markov chain)とは、確率過程の一種であるマルコフ過程のうち、とりうる状態が離散的(有限または可算)なもの(離散状態マルコフ過程)をいう。また特に、時間が離散的なもの(時刻は添え字で表される)を指すことが多い(他に連続時間マルコフ過程というものもあり、これは時刻が連続である)。マルコフ連鎖は、未来の挙動が現在の値だけで決定され、過去の挙動と無関係である(マルコフ性)。各時刻において起こる状態変化(遷移または推移)に関して、マルコフ連鎖は遷移確率が過去の状態によらず、現在の状態のみによる系列である。特に重要な確率過程として、様々な分野に応用される。
簡単に言い直せば,現状態を加味して,次の状態になる確率が決まり,過去の結果は確率に影響を与えないみたいなことが書いてあります.
天気でいうと今日が晴れていれば,明日も晴れの可能性が高いし,今日が雨ならば,明日は曇りや雨の確率が高いみたいな感じです.
マルコフ性の仮定により,今日の天気も晴れであれば,昨日の天気が晴れだろうと,雨だろうと影響を与えないのが,マルコフ連鎖です.
文章生成においては,例として以下の3文を考えます.
「サーバルは狩りごっこが好き」
「カバンは考えるのが得意」
「博士は料理が苦手」
今回は詳しく扱わないので,詳細な説明は省きますが,文章を単語単位に分割することができるため,以下のような図ができます.
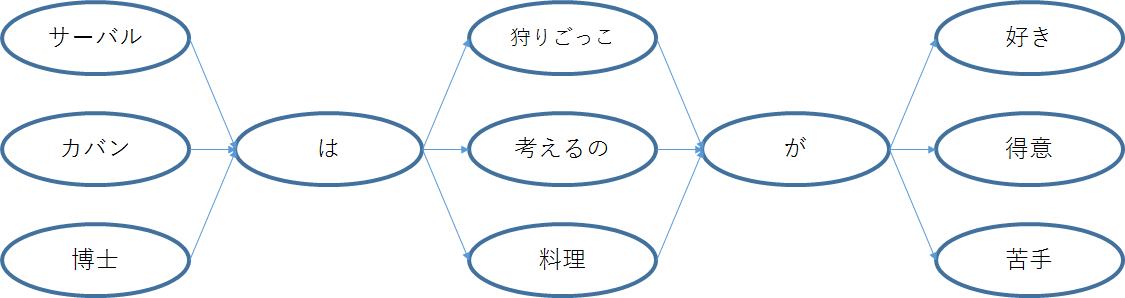
これが状態遷移を表した図であり,左から右に遷移していくことで文章を作ることができます.
例えば,以下のように遷移することで,
「カバンは狩りごっこが苦手」
といった文章を作成することができます.
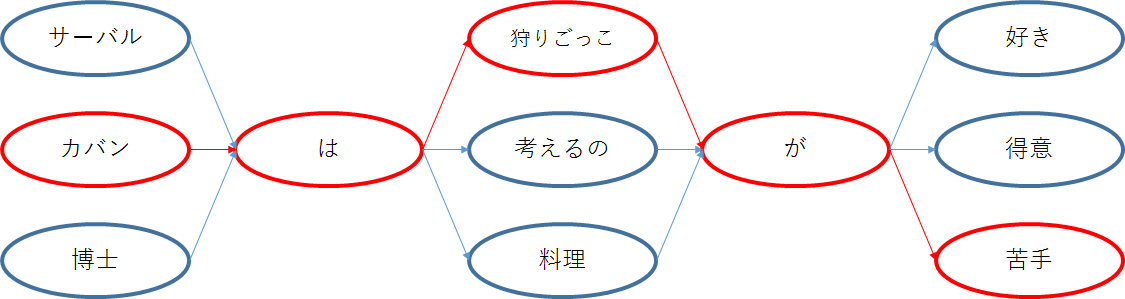
このように,学習のためのデータに出現する単語がどのように出現するかを蓄積させていくことで,様々な文章を生成することができるようになります.
N階マルコフ連鎖
N階マルコフ連鎖は,N-1前の状態から現在の状態までのNの状態を加味して,次の状態を予測します.
N=1のとき,通常のマルコフ連鎖と同様になります.
先ほどの天気の例では,やはり可能であるなら,前日の天気も加味した方が明日の予測はいい結果になることは直感的にもわかると思います.
晴れ,晴れと続けば,明日は晴れる可能性が高いですし,雨,晴れとなれば,晴れ,晴れよりは,明日が晴れる確率が下がるといった感じです.
文章生成は,やはり少し前に何が出現したかを加味した方が,生成された文章がそれっぽくなります.
例えば,先ほどの文の他に以下の
「カレーは二日目がおいしい」
のような文章がありN=1の場合には,
「カレーは狩りごっこが得意」
みたいな文章が生成されてしまいます.
ただし,Nを大きくすればするほど新しい文章の生成が難しくなります.
もっと大量のデータがあればいいのですが...
実装
お待ちかねの実装です.
ただ,今回のN階マルコフ連鎖においては,単語単位ではなく,文字単位でモデルを作成します.
今回のデータがセリフデータであることで話言葉であること,作品の特徴から,ひらがなやカタカナが多いこと,固有表現(ジャパリパークなど)が多いことなどから,MeCab などで形態素解析しにくいことやデータ数が少ないことを考慮し,文字単位での文章生成を行いました.
例えば先ほどの
「博士は料理が苦手」
は
「博」,「士」,「は」,「料」,「理」,「が」,「苦」,「手」
のように分けて状態遷移モデルを作成します.
考察でNの大きさによってどんな感じで変わるかも見ていきます.
(MeCabの導入とか書くのが面倒だったとかではありません)
環境
・Python3.7
前提知識
モデル作成のために,
["今","日"]→["は","も","、","が","は","が","は","、","は"]
みたいなデータ構造を作る必要がある.
これはN=2のときの例であり,「今」,「日」と文字が出現した場合に,次に何の文字が来るのかを,蓄積していく必要がある(文章生成のときは,この中からランダムに「文字」を選ぶため,重複しているものはそれだけ選ばれる可能性が高くなる).
データ数を削減するためのデータ構造の作り方もあるが,今回はシンプルにこういうデータ構造のものを作成していきます.
このデータは,key(上記の["今","日"])に対応するlist(["は",...])が存在する形になっているため,pythonのdictとlistを使います.
また,key作成には,deque を使います.
pythonの標準ライブラリであるcollectionsモジュールで使え,[Python]N階マルコフ連鎖で文章生成でも書かれていますが,今回の実装において重宝します.
listと何が違うのかを簡単に説明すると,最初に長さを指定しておけば,appendで追加したときに,指定した長さを超えていた場合,一番先頭にある値を押し出すことができます.
つまり,deque に["今","日"]が入っていて,「は」をappendで後ろに追加すると,["日","は"]になります(ほんとに便利).
こんな感じで実装できます.
from collections import deque
n_size = 2
queue = deque([], n_size)
ただし,keyにdeque はそのまま使えないので,tuple型に変換します.
key = tuple(queue)
前提知識はこれだけで大丈夫なはずです.
データの読み込み
抽出したデータは
名前 セリフ
と空白区切りにして"kemono_friends.txt"に保存してあるので一行ずつ読み込んで,改行を除去し空白で分割しています.
そして名前が"サーバル"のものをtext_listに追加してます.
text_list = []
with open("./data/kemono_friends.txt") as data:
for line in data:
char, text = line.rstrip('\n').split(" ")
if char == "サーバル":
text_list.append(text)
モデル作成
モデルを作成します.
"BOS"は文章の始まりを表すタグで,Beginning of sentenceの略で,"EOS"は文章の終わりを表すタグで,End of sentenceの略です.
n_sizeはN階マルコフ連鎖のNです.
from collections import deque
import pickle
n_size = 4
def mk_model(text_list):
model = {}
for text in text_list:
queue = deque([], n_size)
queue.append("[BOS]")
for i in range(0, len(text)):
key = tuple(queue)
if key not in model:
model[key] = []
model[key].append(text[i])
queue.append(text[i])
key = tuple(queue)
if key not in model:
model[key] = []
model[key].append("[EOS]")
return model
"""
ここにdata_load.pyをコピー
"""
セリフ自動生成
作成したモデルを用いて文章を自動生成するプログラムは先ほどのプログラムに以下のコードを追加します.
import random
def mk_serihu():
value_list = []
queue = deque([], n_size)
queue.append("[BOS]")
key = tuple(queue)
while(True):
key = tuple(queue)
value = random.choice(model[key])
if value == "[EOS]":
break
value_list.append(value)
queue.append(value)
return value_list
# とりあえず10個セリフを自動生成
for i in range(0, 10):
serihu = ''.join(mk_serihu())
print(serihu)
プログラムとしては,まず"BOS"がkeyになり,modelから文字をランダムに生成します.
あとはkeyが徐々に変わり,文字を次から次へと生成し,"EOS"が出たら生成を終了します.
出力はこんな感じです.
でも、あれくらい続けてるの?
初めてなんだー。やったね。
あっ。冷たっ。
バイバーイ。
うん。ね、ヒグマ。いくよ。
えっとね、アイドルって言って、踊ったり歌ったり、なんか始めるの?
待て待てー。
いやっ。
名前はさっき付けたの。なんのために。
なんだろう。
なかなかいい感じ!
ちなみにmodelはデータ数が大きいと毎回生成するの大変なので,pickleでbinary fileとして保存するとすぐに呼び出せて便利です.
model.binaryfileとして保存して,それを呼び出すプログラムは以下のようになります.(とりあえずデータ加工とか飛ばして,自動生成を動かしてみたい方は,TwitterとかからDMもらえれば,model.binaryfileを渡します)
from collections import deque
import random
import pickle
n_size = 4
f = open("data/model.binaryfile",'rb')
model = pickle.load(f)
def mk_serihu():
value_list = []
queue = deque([], n_size)
queue.append("[BOS]")
key = tuple(queue)
while(True):
key = tuple(queue)
value = random.choice(model[key])
if value == "[EOS]":
break
value_list.append(value)
queue.append(value)
return value_list
# とりあえず10個セリフを自動生成
for i in range(0, 10):
serihu = ''.join(mk_serihu())
print(serihu)
考察
Nの値をいろいろ変えたところ,N=4くらいがそれっぽいセリフが作れました.
Nを大きくすると,どうしても学習データと同じものばかりになってしまうし,Nが小さいと文章が成り立たなくてなかなか難しい(汗).
N=4の場合の学習データにないよさげなやつをピックアップ.
ええと、ちょっと、やってみない?
ボスが何か言ってよ!
あれ、何かある?
ええっ。かばんちゃん器用だね。
冗談でしょかばんちゃん。
ほら、いこうか!
かばんちゃんはこんなになってたんじゃ?
えっ、なあにあれなに?どうやって持つのがいいのかなあ。
わたし達のことも忘れちゃうもんね。
63%ほど学習データにないセリフを生成できる!
次は,N=3の場合の学習データにないやつ.
どうしたの?かばんちゃんは?
わかった。何からやればいいの。
フレンズだったな…。
めちゃくなってるんだよ。楽しみだなー。
あっ!ダメ!それって取れるの?
みんなが心配なんだろう。
えっ、さっきのあの声、誰か食べられちゃったね。
80%が学習データにないセリフだけど,やっぱり不安定.
次は,N=2の場合の学習データにないやつ.
いいなーっ、もう騙されなに走り回って、大丈夫?
どこか。かばんな…たまた誰かでも、白いのかな。ね、溶岩?
それとも、たって呼べばいいの?
平気平気。フレンズの形してるの?
96%が学習データにないセリフだけど…
最後はN=5
昨日途中で寝ちゃったんだね。
砂がたくさんいるんだって。
え、ええっ。どういうことなの?ここは?
35%が学習データにないセリフ.
安定感あるけど,やっぱりもともとないセリフをもっと作ってほしいから,N=4がちょうどいいかな.
「かばんちゃん」みたいなセリフが長いから,そういう長めの単語の文字列来ると,意味不明なセリフ作りやすくなるから,やっぱりマルコフ連鎖だけでは厳しいね(汗)
まとめ
とりあえず,簡単に作れるモデルだけど文章生成は難しい.
固有表現抽出でキャラや場所の文字列登録したり,word2vecで類似単語に置換したり,簡単にできることはまだまだたくさんあります.
また,最近の文章生成は深層学習使ってたりするのがいろいろとあるので,試していけたらと思います.
個人的には,セリフ自動生成器を使って学習データを大量に作り,適当なセリフを入力すると指定したキャラクターっぽいセリフに変換して出力できるようなモデルを作りたいと思ってます.
あとは,やっぱり一方的なセリフよりは短い対話できるモデルを組みたいですね.
けものフレンズはいいデータがあったけど,本当は@RemChabotで使っているなろうAPIで取得した小説のテキストデータ使って,レムと対話できるようにしたいと思っています.
小説のデータは,セリフに対してのラベルがないのでデータ作るところで止まっています(汗)
誰かデータ作ってほしい.
自然言語処理はとにかく,学習データ作りが大変なので,協力してくれる人いたら連絡お待ちしています.
記事を書くのになれておらず,読みにくかったり至らない点も多かったと思いますが,最後まで読んでいただきありがとうございました.
少しでも「参考になった」,「続きが読みたい」と思ってくれた方は,いいねしてもらえると嬉しいです.(モチベになるので).
参考サイト一覧
TVアニメ けものフレンズの台詞を書き起こしてみました
Wikipedia
[Python]N階マルコフ連鎖で文章生成
「マルコフ連鎖による文章生成」