はじめに
早速ですが、この記事は以下の様な流れになっております。
- 当記事の概要
- 分析の設計
- データの準備
- 予測モデル構築
- 可視化・考察
- 【後編】元自衛隊のエンジニア1年目がPythonで感情予測をした話 25.5%→33.6%
全体を通して、そもそも何をしようとしているのか?
本記事ではTwitterのデータを利用して、ツイートのデータを感情分析しています。
感情分析の高精度なモデルが出来れば、ツイートに限らず様々な文章の感情を定量的に判定できるようになると考えます。
全体を通して、精度が高くなるようにデータの前処理やモデルの性能向上を実施しています。
(この感情分析で何をどう分類したいのか? 具体例は当記事のこちらで挙げております)
結果を先に申し上げると、ベースラインとして 24.0% の精度だった感情予測モデルを 33.6% に引き上げました。
私は機械学習初心者であるため、試行錯誤の過程も残しておきたいと考えております。
1. 当記事の概要
1.1 自己紹介
私は陸上自衛隊の最前線で12年働いていました。
その中で災害現場やレンジャーなどを経験しています。
任務の中で、人の感情に強く興味を持つようになりました。
2022年、データ分析やエンジニアリングへの強い興味により、当テーマへ取り組みました。
普段はPythonやVBAを書いています。
1.2 目的
感情分析をしようと思ったきっかけは、「コールセンターの業務改善」に着目したことです。
コールセンターが受電するクレームを文章化して「感情分析」できたら面白いのではないかと思いました。
クレームの文章化は音声のテキスト化や個人情報が障害となり、データ準備は困難です。
ですが、まずは足掛かりとして余暇の時間を使いデータ準備と予測モデルの構築をしてみようと思います。
もう一つの目的があり、それは私自身のスキルアップです。
目的についてQ&A
| Q. | A. |
|---|---|
| 結局やりたいことは? | [文章] を与えると [この文章の感情は●●です] と高精度で返してくれるような仕組みの作成(●●に入るのはhapiness sadnessなど13クラス) |
| どのようなデータを使うの? | [文章] [文章の感情] という2列のデータセット |
| 具体的に何をやるの? | 機械学習モデル:ランダムフォレストなどによる分類器作成 |
1.3 環境
- Google Colaboratory
- Python 3.8
- ChatGPT ver.Feb 13
1.4 進め方
- 分析の設計
- データの収集
- データの整形(1回目:最小限)
- モデルの構築(ランダムフォレスト)
- 可視化・考察(1回目)
以下【後編】 - データの整形(2回目)
- 可視化・考察(2回目)
- データの整形(3回目)
- 可視化・考察(3回目)
- 目的変数修正
- 可視化・考察(4回目)
- 結論・今後の展望
2. 分析の設計
2.1 どんなデータを扱うか
| テキスト例 | 正解ラベル例 |
|---|---|
| 例:夫の収入が増えて暮らしが改善! |
喜び |
| 例:私は長い間、病気で働けてません |
悲しみ |
| 例:今は仕事から充実感を得ています |
楽しみ |
こんな感じのデータを探して、ランダムフォレストによる教師あり学習/分類を行います。
ランダムフォレストを選んだ理由は初心者が扱いやすく、精度が出やすいからです。
ゆくゆくはLSTMやBERT、transformerなど他の手法も実装してみたいです。
補足:どのように正解ラベルは付けられているのか?
実際に見つけたデータは、以下の様な40,000行のデータです。
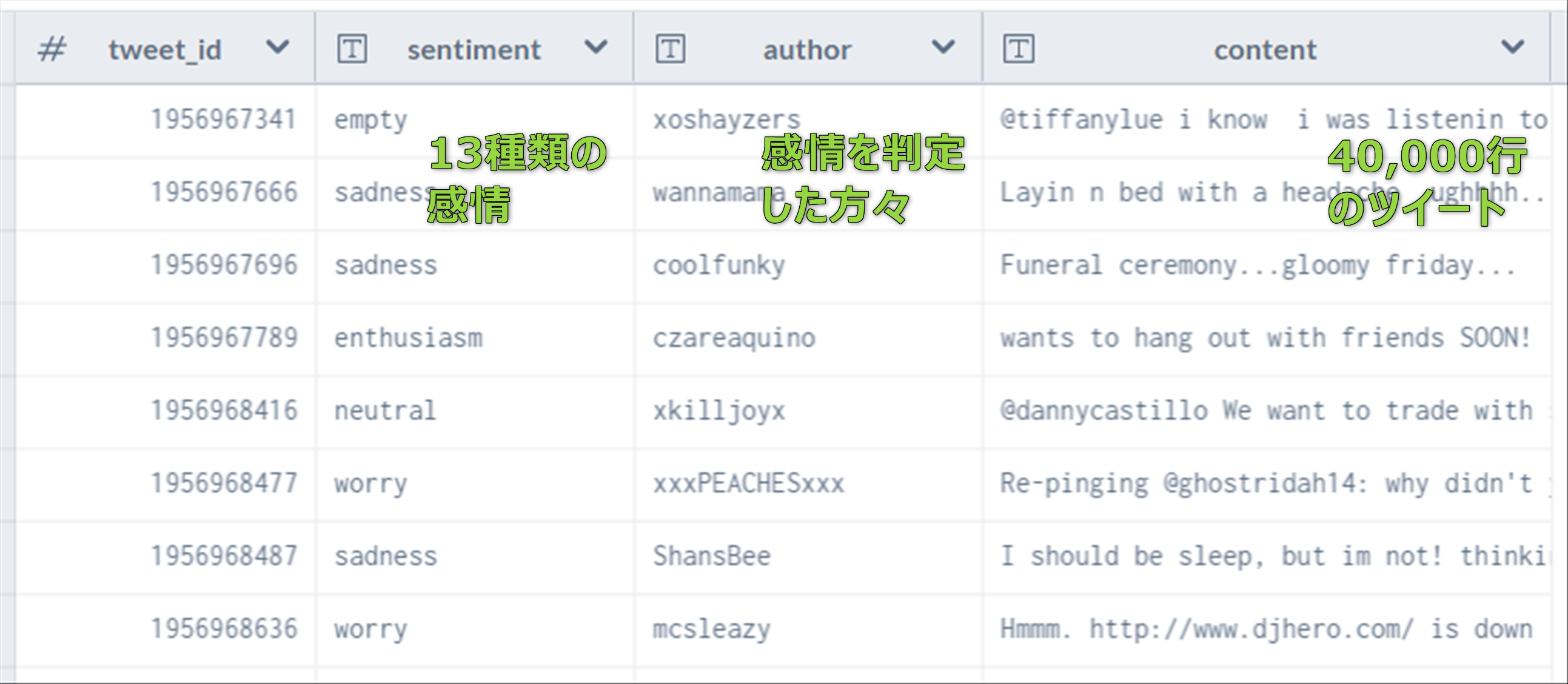
- 複数人の手によって、手動で付けられています。
→ データ製作者本人による正解ラベル付けのご説明【Kaggle】
2.2 どのぐらいの精度まで求めるか
| テキスト例 | 正解ラベル例 | 予測例 | 正誤 |
|---|---|---|---|
| 例:夫の収入が増えて暮らしが改善! |
喜び | 喜び | ○ |
| 例:私は長い間、病気で働けてません |
悲しみ | 悲しみ | ○ |
| 例:今は仕事から充実感を得ています |
楽しみ | 喜び | × |
精度:目標は正解率30%
- もし、有料サービスとして提供するなら90%以上のイメージ
- Kaggleメダリストの方がtransformerモデルを使用し、同題材で31.6%
- いきなりサービス化ではなく自分の時間を使った実験なので、目標は30%
- 上の表の|楽しみ|喜び|×|のように判断が難しいケースが多数存在
3. データの準備
3.1 データ収集
理想は 「日本の」「コールセンターのお客様の文言」 です。
しかし、あの手でこの手で捜索したものの都合よく見つかるはずもなく、断念しました。
【探し方】
| No. | 方法 | あの手この手 | 備考 |
|---|---|---|---|
| 1 | 検索 | Google Data Search | ラベル付データなし |
| 2 | 検索 | ラベル付きデータなし | |
| 3 | 検索 | Kaggle | ラベル付きデータあり(英語) |
| 4 | スクレイピング | 様々なページをクローリング | ラベリング困難 |
| 5 | 自作 | ChatGPT | 1分で50件程度が限界 |
| 6 | 検索 | 行政のHP | ラベル付きデータなし |
| 7 | ありものを使う | GCP | APIはあるがデータ提供見当たらず |
Kaggleにあった感情ラベル付きツイートデータが最も役立ちそうと考えました。
【理由】
- 13個の正解ラベルが付与されている
- 40,000行ある
- 英文なのがネックだが、翻訳をうまく使えば克服できそう
3.2 データ俯瞰
目的
- データ自体がKaggleのオープンデータであり、内容を把握できていないため
- データ分析やモデル構築の方針を決めるため
手段
- 全データを出力して、どういう情報があるのか確認する
まずは、KaggleからDLしたcsvファイルをpandasで読み込んでみます。
import pandas as pd
Tweet = pd.read_csv('/content/drive/MyDrive/Data for Colab Notebooks/tweet_emotions_tweets_and_sentiments.csv', encoding='cp932'
Tweet
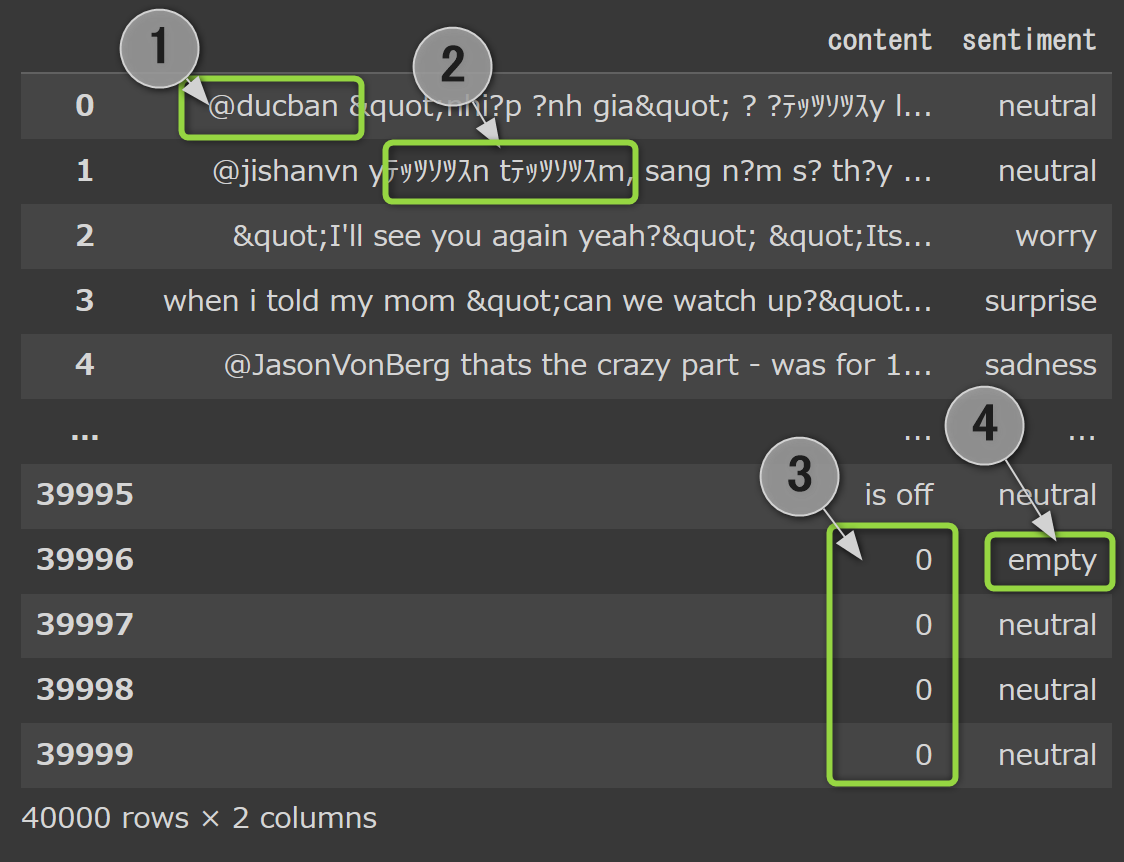
【ざっと見てわかること】
① @マークから始まる名前のようなものがある
② ところどころ文字化けしている
③ "0"の行が存在する
④ sentiment(感情)にemptyなど日常的には使用しない、分かりにくい感情ラベルが存在する
④ → ① → ② → ③ の順に対処していきます。
④ 日常的には使用しない、分かりにくい感情ラベルについて
ざっくりとした和訳はChatGPTが使いやすいので、翻訳してみました
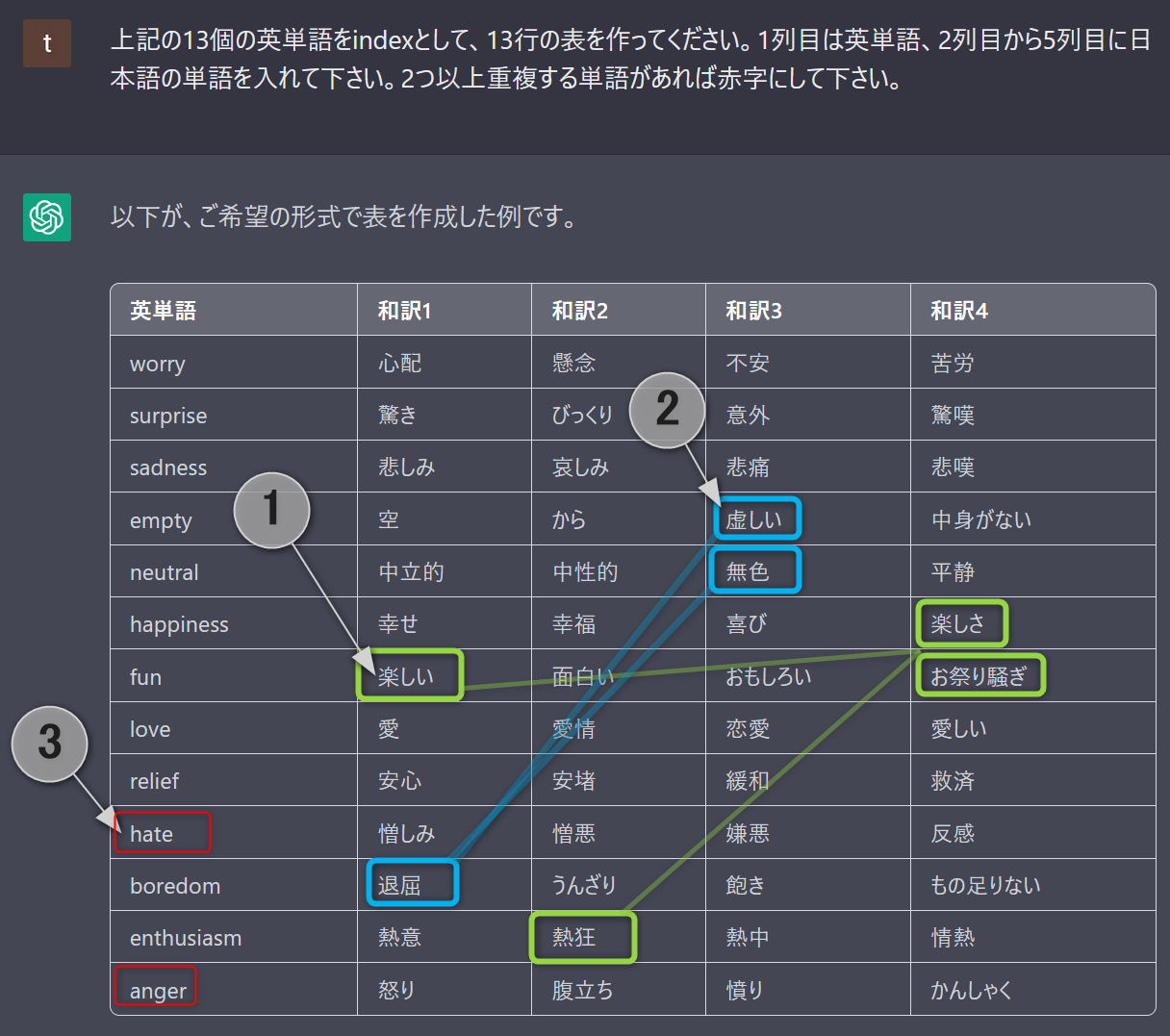
【洞察】
| No. | 気づいたこと | 予期されること | 対策 |
|---|---|---|---|
| ① | fun, happiness, enthusiasm には意味が近い和訳がある | 混同すると予測精度に悪影響 | グルーピングを検討 |
| ② | empty, neutral, boredom には意味が近い和訳がある | 〃 | 〃 |
| ③ | hate, anger は「怒り・憎しみ」と意味が近い | 〃 | 〃 |
| - | love, relief は「心温まる」という意味では近い | 〃 | 〃 |
| - | worry, sadness, boredom は「緩やかなストレス」という意味では近い | 〃 | 〃 |
| - | surprise は他に意味が近い感情がない | データが少ないと予測精度に悪影響 | 削除を検討 |
① @マークから始まる名前のようなものがある
② ところどころ文字化けしている
③ "0"の行が存在する
上記3点については、3.4 データ整形 の段階で処理します。
3.3 目的変数俯瞰
※前提として、当初は目的変数13個すべてを分析します。
目的
- 今回は目的変数が多様であるため、目的変数の情報を分析します。
- クラスラベルの種類の確認
- クラスラベルの偏りの確認
手段
- データセット内でどのように分布しているか、割合を以下のように可視化して考察します。
グラフ描画のコードは長いので畳みます
import matplotlib.pyplot as plt
# 単語の出現回数をカウント
words = ['worry', 'surprise', 'sadness', 'empty', 'neutral', 'happiness',
'fun', 'love', 'relief', 'hate', 'boredom', 'enthusiasm', 'anger']
word_counts = pd.DataFrame(index=words, columns=['count'])
for word in words:
word_counts.loc[word, 'count'] = Tweet.iloc[:, 1].str.count(word).sum()
# カウント数で多い順にソート
word_counts = word_counts.sort_values('count', ascending=False)
# グラフ作成
fig, ax = plt.subplots(figsize=(10, 6))
# 棒グラフ
colors = ['green', 'green', 'green', 'yellowgreen', 'yellowgreen', 'orange', 'orange', 'orange', 'deepskyblue', 'red', 'aqua', 'yellow', 'blue']
ax.bar(word_counts.index, word_counts['count'], color=colors)
ax.set_xticklabels(word_counts.index, rotation=45, ha='right', fontsize=16)
ax.set_title('Word Counts', fontsize=20)
ax.set_xlabel('Words', fontsize=18)
ax.set_ylabel('Count', fontsize=18)
for i, v in enumerate(word_counts['count']):
ax.text(i, v+5, str(v) + '\n' + str(round(v / word_counts['count'].sum() * 100, 2)) + '%', ha='center', fontsize=12)
plt.tight_layout()
plt.show()
【出力】まずは代表例として A, B, C をピックアップ
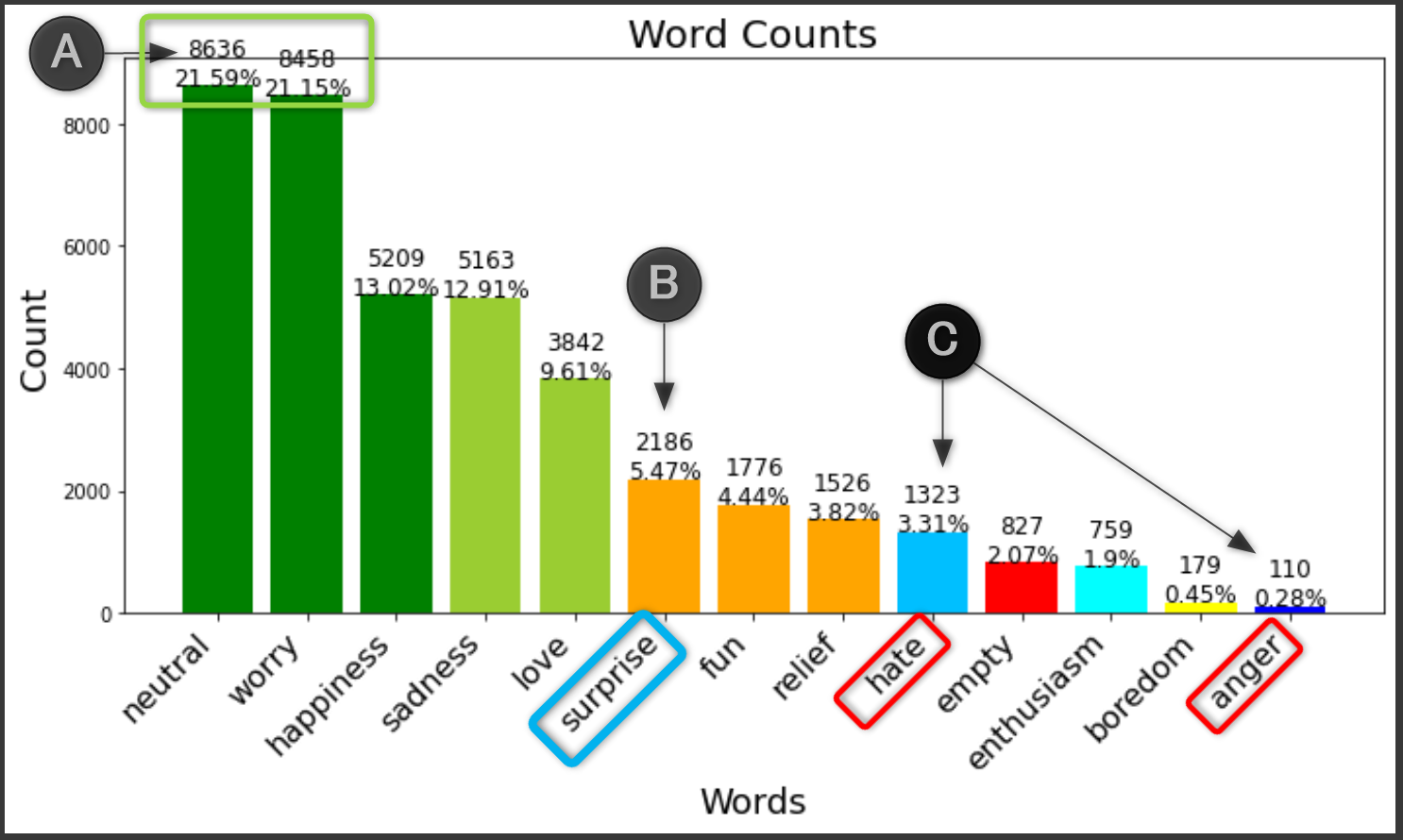
【洞察】
| No. | 気づいたこと | 予期されること | 対策 |
|---|---|---|---|
| A | 多い neutral worry と少ない boredom anger の間には50倍~80倍の差がある |
予測精度にムラが出る | 少ない目的変数はグルーピングを検討 |
| B |
surprise は他に近い感情がなく、平均の7.69%より少ない5.47% |
〃 | 削除を検討 |
| C |
hate anger は近い感情でかつ、足し合わせても surprise より少ない |
〃 | 削除か sadness とのグルーピングを検討 |
3.4 データの整形
目的
-
予測モデルの適切な学習や計算量低減を図り、精度を向上させるため
- 誤字脱字を含めた、誤ったデータを学習してしまうことの防止
- 計算時間の短縮
- 精度向上(意味のある単語に絞る、表記ゆれを無くす)
-
異なるデータセットにもモデルを適用できるようにして、データの汎用性を向上させるため
手段
- 大きく分けるとデータのクリーニングやデータの変換が挙げられる
まずは 3.2 で言及した以下の2点に対する処理を行います。
① @マークから始まる名前のようなものがある
② ところどころ文字化けしている
3.4.1 テキストのクリーニング
import re
# テキストのクリーニング(1.@から始まる語句を削除 2.アルファベット以外は文字化け含め削除)
def tweet_to_words(raw_tweet):
# a~zまで始まる単語だけを残し、空白ごとに区切ったリストを作成
letters_only = re.sub("[^a-zA-Z@]", " ",raw_tweet)
# @で始まる単語を削除
meaningful_words = [w for w in words if not re.match("^[@]", w)]
return( " ".join(meaningful_words))
# ツイート内容の列を全行処理
cleanTweet = Tweet['content'].apply(lambda x: tweet_to_words(x))
# テキストのクリーニング状況を確認
cleanTweet
【出力】
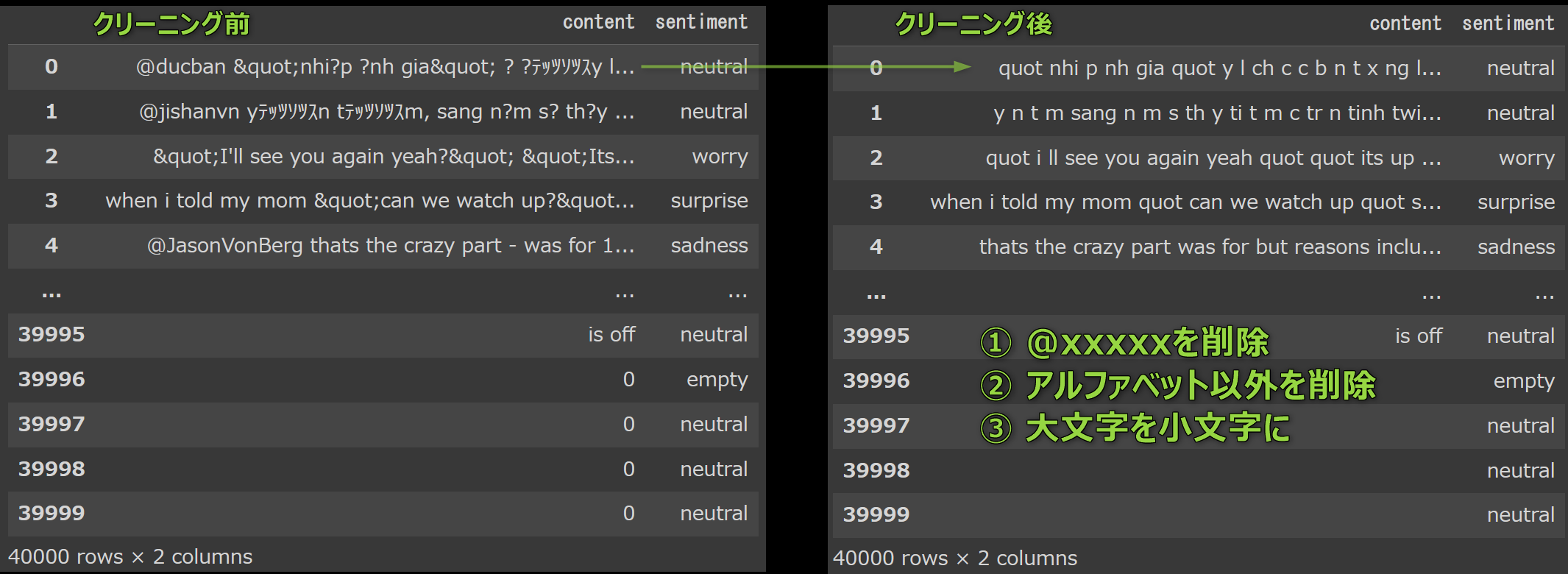
まだ"quot"という単語が目立つのが気になります。
しかし今はベースラインの予測精度を出す段階なので、このまま進めます。
後程、修正します。
3.4.2 単語のデータベースを作成
# 40,000行のツイートをすべて半角スペースで連結して、1つの文字列にする
all_text = ' '.join(cleanTweet)
# 上記の1つの文字列を半角スペースで分割して、たくさんの単語リストにする
many_words = all_text.split()
# 同じ単語も出現タイミングによって別々にカウントする
print("単語の総個数:"+str(len(many_words)))
【出力】単語の総個数:531,849
データベースにどんな単語が多いのかを確認します。
from collections import Counter
counts = Counter(many_words)
print("登場単語種類数:"+ str(len(counts))+"語")
# 単語ごとの出現回数を見たいので、データフレームに変換
counts_df = pd.DataFrame.from_dict(counts, orient='index', columns=['count'])
counts_df_sorted = counts_df.sort_values('count', ascending=False)
transposed_df = counts_df_sorted.transpose()
transposed_df.head(20)
【出力】下記を見るにi=「私」が一番多いですね。代名詞、前置詞と冠詞が目立ちます。下位は固有名詞が多そうです。
i to the a my you it and is in ... crazykids alexanders slurpeeee tibet inconclusive buckled jetsetter unattractive wellllllllllllll howdyyy
count 24185 14387 12986 9844 8077 7790 7741 7468 5740 5443 ... 1 1 1 1 1 1 1 1 1 1
3.4.3 各単語の数値化、配列化
モデルに学習させるために、全ての単語を以下の様に ID番号化(数値化) します
# Counterオブジェクトの単語データベースを、降順のリスト型に変換
vocab = sorted(counts, key=counts.get, reverse=True)
# 単語ごとにIDを割当てた辞書を作成
vocab_to_int = {word: ii for ii, word in enumerate(vocab, 1)}
# リスト内包表記を使って各単語をIDに変換したリスト tweet_ints を作成
tweet_ints = []
for each in cleanTweet:
tweet_ints.append([vocab_to_int[word] for word in each.split()])
print(cleanTweet[4])
print("↓単語ごと数値化")
print(tweet_ints[4])
thats the crazy part was for but reasons include quot full schedule quot amp quot travelling with his daughter quot so not cool
↓単語ごと数値化
[323, 3, 519, 546, 27, 12, 21, 3410, 2645, 40, 446, 1599, 40, 71, 40, 5826, 24, 183, 883, 40, 19, 28, 204]
3.4.5 数値化した単語ごとに配列の長さを確認
# 各ツイートが持っている不揃いな状態の単語数を調査
tweet_len = Counter([len(x) for x in tweet_ints])
seq_len = max(tweet_len)
print("Zero-length reviews(単語数が0個のツイート数): {}".format(tweet_len[0]))
print("Maximum review length(一番単語数が多いツイート): {}".format(seq_len))
Zero-length reviews(単語数が0個のツイート数): 80
Maximum review length(単語数の最大値): 39
3.4.6 欠損値のある行(単語数0の行)を削除
# 単語数が0になっている行を飛ばした「index番号リスト」を作成
no_missing_idx = [idx for idx,tweet in enumerate(tweet_ints) if len(tweet) > 0]
clean_tweet_df = clean_tweet_df.iloc[no_missing_idx]
tweet_ints = [tweet for tweet in tweet_ints if len(tweet) > 0]
print("clean_tweet_df(欠損値削除後のデータフレーム):" + str(clean_tweet_df.shape))
【出力】40,000行のうち80行削除したため、39,920行になります。
clean_tweet_df(欠損値削除後のデータフレーム):(39920, 2)
3.4.7 配列の長さを揃える
# np.zeros:準備として39920*39の0だけが入った、np配列を作成
features = np.zeros((len(tweet_ints), seq_len), dtype=int)
# iには0から順番に入っていく。rowにはtweet_ints(単語を数値に置き換えたもの)が入っていく
for i, row in enumerate(tweet_ints):
# iは行の指定に使われる。i番目のデータを操作する。
# -len(row):には単語数が入る。-で右から単語数個以降の要素に、右辺の要素を入れる
features[i, -len(row):] = np.array(row)[:seq_len]
print("numpy配列の形:"+ str(features.shape))
【出力】numpy配列の形:(39920, 39)
[[ 40 8922 191 2179 7020 40 407 489 1933 335 335 231 212 13 167 1461 489 40 56 20 8922 191 2179 40 335 212 1461 1 260 1933 1933 191 2179 260 139 212 11 293 1]
[ 407 212 13 20 3158 212 20 11 260 407 3159 13 20 335 939 212 8923 105 939 489 1 489 260 1461 260 1933 12986 2179 489 20 1550 20 335 1 335 335 1461 1933 4]
[ 0 0 0 0 0 40 1 87 69 6 112 134 40 40 70 35 2 6 40 40 1 8924 6 64 1 155 84 2 162 2 174 28 515 6 40 1598 3160 5825 412]
[ 0 0 0 83 1 492 5 161 40 33 51 221 35 40 107 274 40 182 40 171 126 1 60 107 240 1 1329 40 53 11 35 40 257 37 1 18 4 371 238]
中略
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 580 697]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 26 78]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 30933]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 929]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 89]]
0で埋めることで長さを揃え、処理しやすくします。
3.4.8 13種類の感情(目的変数)の数値化
# unique():データフレームの指定列の重複を削除
labels = clean_tweet_df["sentiment"].unique()
# 正解ラベルの数(13)をrange(0~12)で作成。"13"ではなく"13個の数値"なのがポイント
num = list(range(len(labels)))
まずは以下の2つの配列を作成
['neutral' 'worry' 'surprise' 'sadness' 'empty' 'happiness' 'fun' 'love' 'relief' 'hate' 'boredom' 'enthusiasm' 'anger']
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
# 次にmap()を行うためにあらかじめ辞書化
# worryと0を取り出して...という処理を12回繰り返す。少ない方のリストに合わされる
label_dic = dict(zip(labels,num))
print(label_dic)
{'neutral': 0, 'worry': 1, 'surprise': 2, 'sadness': 3, 'empty': 4, 'happiness': 5, 'fun': 6, 'love': 7, 'relief': 8, 'hate': 9, 'boredom': 10, 'enthusiasm': 11, 'anger': 12}
目的変数を数値化する準備ができました。
3.4.9 数値化した目的変数を元データへ結合
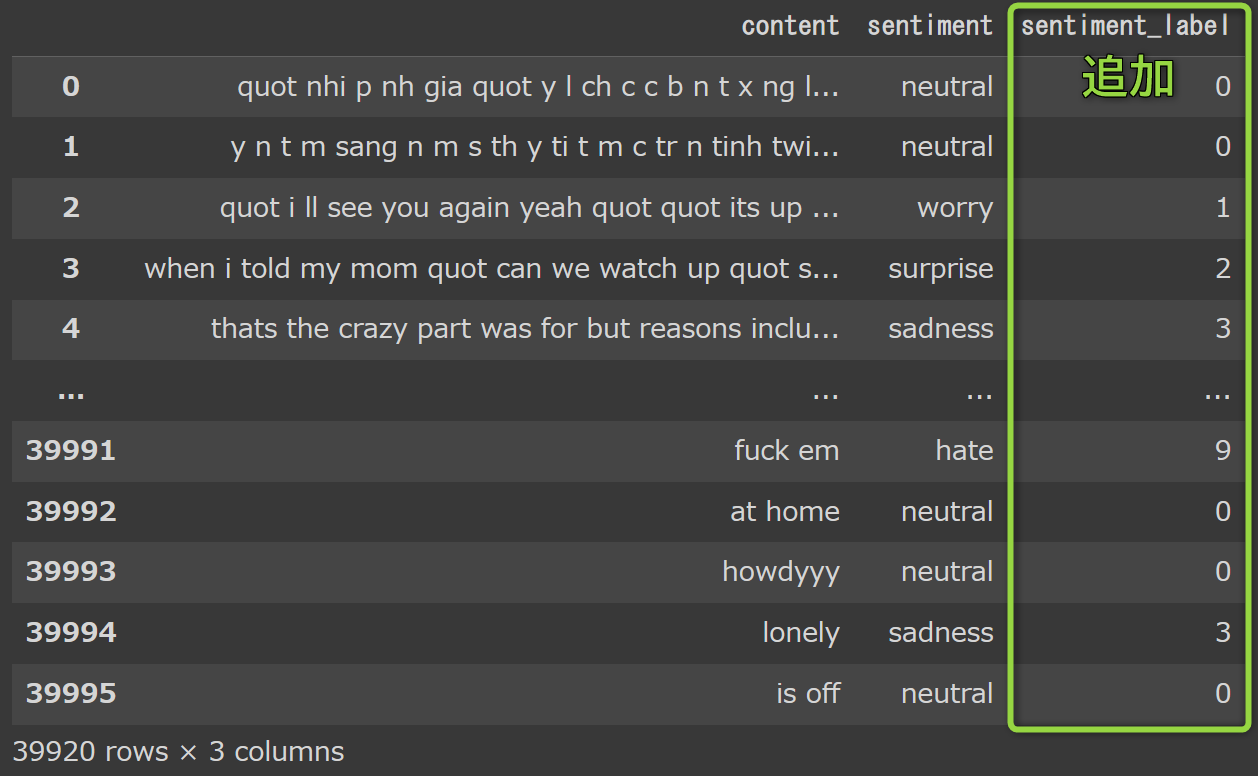
clean_tweet_df["sentiment_label"] = clean_tweet_df["sentiment"].map(label_dic)
clean_tweet_df
【出力】sentimentに対応したsentiment_labelをマッピングします
4. 予測モデル構築
4.1 学習データ(7割)とテストデータ(3割)の生成
from sklearn.model_selection import train_test_split
# 特徴量として、numpy配列化した単語群を説明変数 X とする
X = features
# 正解ラベルとして、dfの数値化した感情群を目的変数 y とする
y = clean_tweet_df.sentiment_label
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=42)
4.2 予測モデル構築
from sklearn.ensemble import RandomForestClassifier
model1 = RandomForestClassifier()
ベースラインを求めるため、ここではパラメータ調整は行いません。
4.3 モデルの学習
model1.fit(train_X, train_y)
4.4 正解率を算出
print("ランダムフォレスト: {}".format(model1.score(test_X, test_y)))
ランダムフォレスト: 0.23997995991983967
約24%とします。
4.5 パラメータ調整
コードは畳みます。 n_estimators の最適な値を、forループで探します。
# 決定木の数を検討:1~501を10刻みで試行(30分程度掛かるので注意)
n_estimators_list = [i for i in range(1, 501, 10)]
# 正解率を格納する空リストを作成
accuracy = []
# n_estimatorsを変えながらモデルを学習
for n_estimators in n_estimators_list:
model = RandomForestClassifier(n_estimators=n_estimators, random_state=42)
model.fit(train_X, train_y)
accuracy.append(model.score(test_X, test_y))
# accuracyが最大値になる時のn_estimatorsを取得
max_accuracy = max(accuracy)
optimal_n_estimators = n_estimators_list[accuracy.index(max_accuracy)]
print(f"The optimal n_estimators is {optimal_n_estimators} with the accuracy of {max_accuracy}")
# グラフの描画
plt.plot(n_estimators_list, accuracy)
plt.axvline(x=optimal_n_estimators, linestyle="--", color="gray")
plt.title("accuracy by n_estimators increasement")
plt.xlabel("n_estimators")
plt.ylabel("accuracy")
plt.show()
→ 最適な値は 331でした
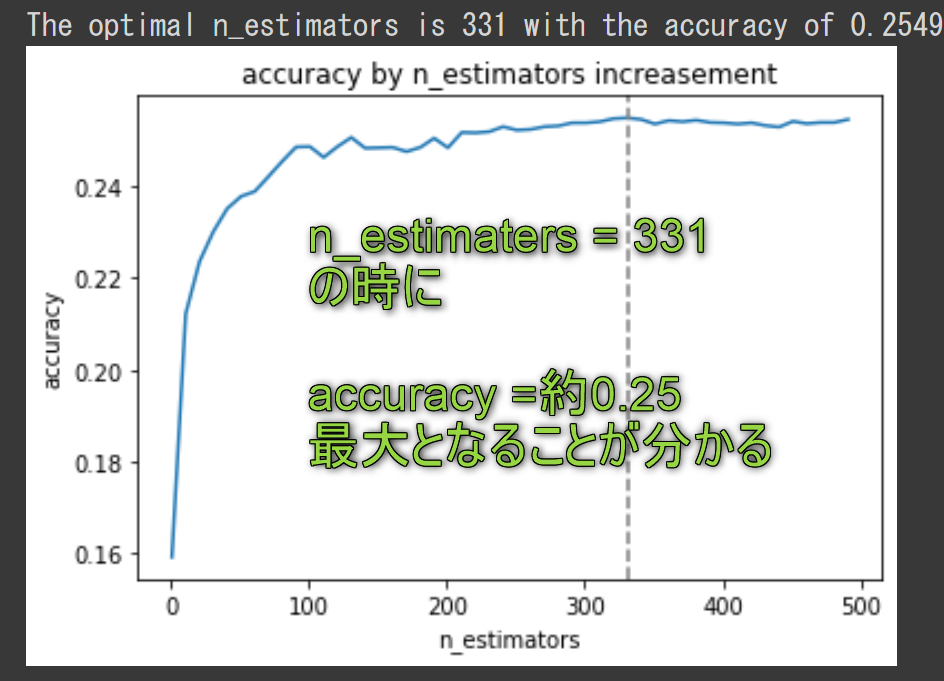
ランダムフォレスト: 0.25492184635543810
model1 = RandomForestClassifier(n_estimators=331)
model1.fit(train_X, train_y)
print("ランダムフォレスト: {}".format(model1.score(test_X, test_y)))
→約25.5%とします
5. 可視化・考察
5.1 考察
| 分析者 | 今回使用した予測モデル | パラメータ調整 | 正解率 | コメント |
|---|---|---|---|---|
| 私 | 決定木 | デフォルト | 16.5% | 参考用 |
| 私 | ランダムフォレスト | デフォルト(n_estimaters=100) | 24.0% | 最小限の前処理 |
| 私 | ランダムフォレスト | n_estimaters=331 | 25.5% | 上記+パラメータ調整 |
| Kaggleメダリスト | transformer | リンク先参照 | 31.6% |
【精度向上について】
- Kaggleメダリストの方の精度が31.6%にとどまったのは、類似する目的変数が判別しにくかった影響だと考えられます。
- 類似する目的変数をまとめることが出来れば、30%は超えられそうです
5.2 正解率25.5%の内訳を混同行列にて可視化
from sklearn.metrics import confusion_matrix, f1_score, precision_score, recall_score
y_true = test_y #正解のラベル
y_pred = model1.predict(test_X) #ランダムフォレストの予測値(混同行列用)
conf_matrix = confusion_matrix(y_true,y_pred)
print("テストデータ総個数: {}".format(np.sum(conf_matrix)))
【出力】テストデータ総個数: 11976
上記の conf_matrix(混同行列)をヒートマップ風にしてみます。
左の項目が正解値 上部の軸が予測値 です。
worryと予測してしまう誤答が目立ちます(濃い緑)
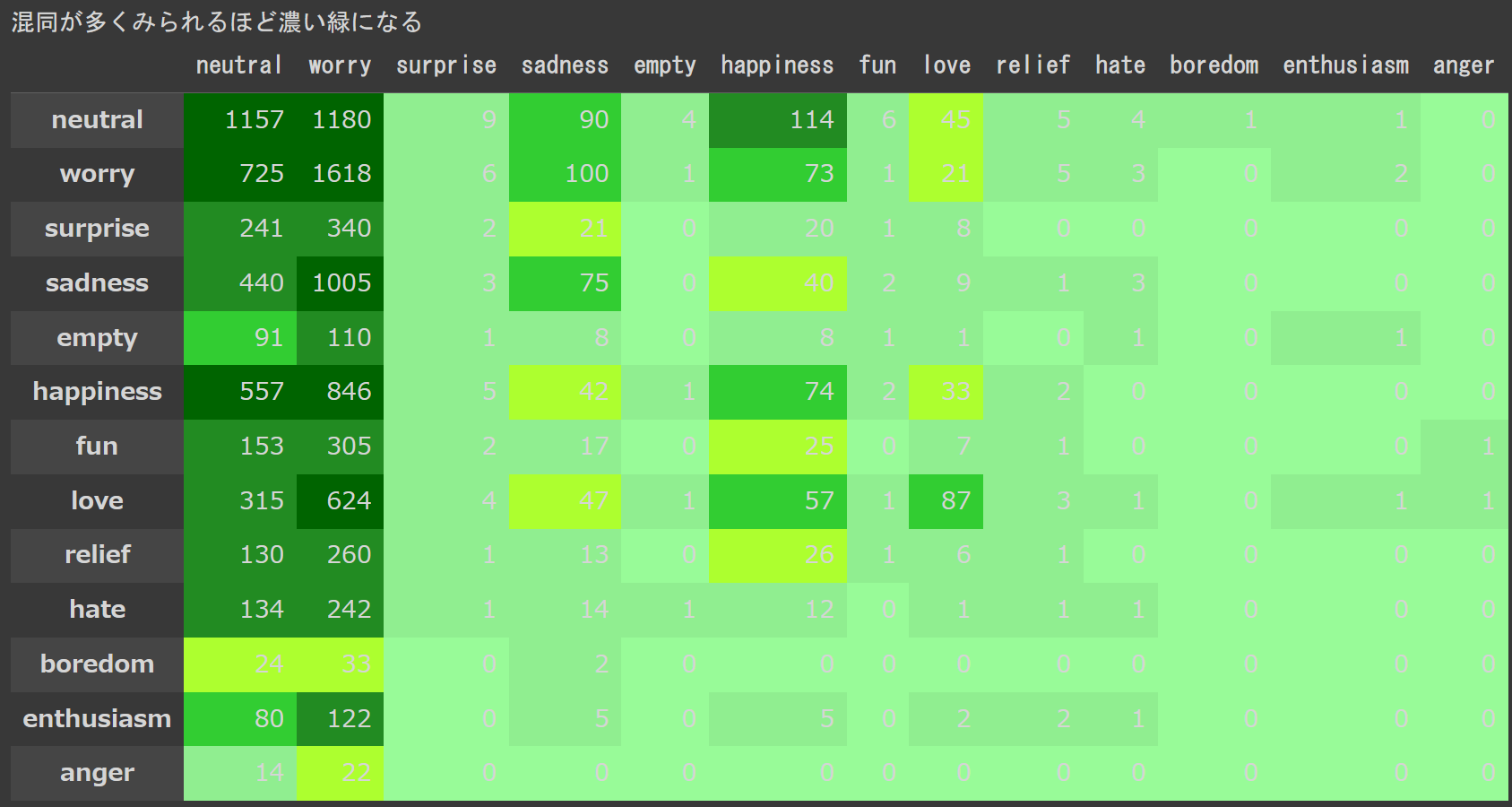
↓ 混同行列に、合計と正解割合を追加しました。画像下部に影響度が大きそうな洞察を3つ挙げました。
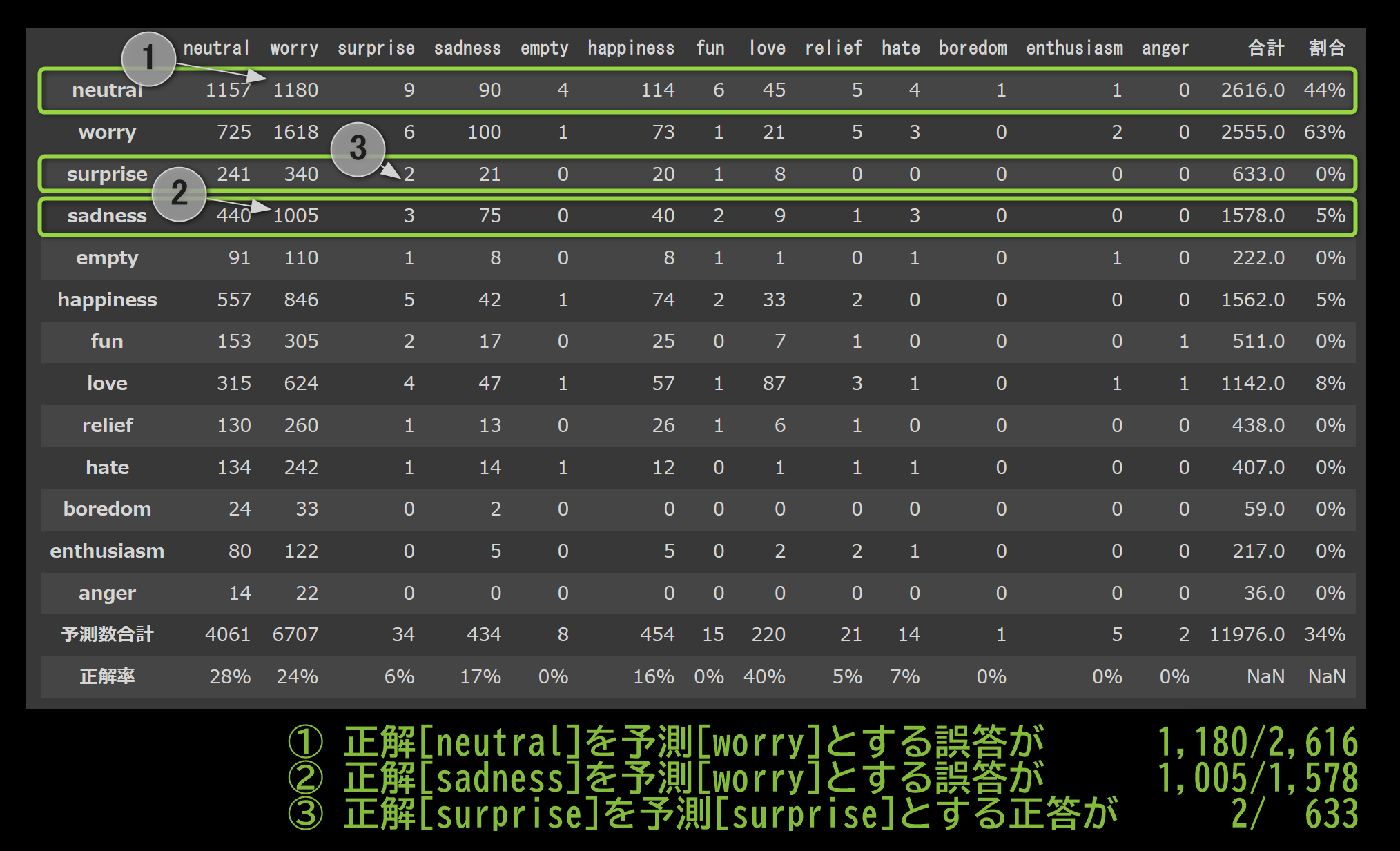
やはりworryと予測してしまう誤答が目立ちます。
まとめ
長くなってしまうので【後編】へ続きます。
目標の精度 30%に対して、現在25.5%です。
- データ前処理
- 目的変数削減
- 今後の展望、他のモデルと比較
の順に実施していきます。
| No. | 未解決の課題 | 今後やること | 使えそうな手段 |
|---|---|---|---|
| 1 | "quot"の多発が気になるので対処 | 追加の文字化け対策 | 文字コードに留意 |
| 2 | ストップワード未使用 | 不要語の削除 | nltk, ワードリスト自力作成 |
| 3 | 語幹の抽出をしていない | 形態素解析 | nltk, Polyglot |
| 4 | 感情ごとの正答率差が激しい | 目的変数削減 | wordcloud,相関行列 |
| 5 | 決定木以外との比較がない | 他のモデルと比較 | LightGBM, LSTM, BERT, transformer |