弊社ではオンプレ環境でのアプリ開発を行っています。
「なぜこのクラウド全盛期にオンプレ??」と思うかもしれませんが、その理由についてはこちらで当時のCTOが説明してくれています。
ただ全サービスがオンプレとは限らず、例外もありまして、自分が参画しているプロジェクトではAWS環境でのアプリ開発を行っています。
DBは Amazon Aurora MySQL を利用しているのですが、ふと「Auroraって何?」と思ったので、勉強がてら記事にまとめてみました。
1. そもそもRDSとは? Auroraは何が違うのか?
まず最初に、 Amazon RDS (Relational Database Service) について軽く触れておきます。
RDSは、AWSが提供するマネージドなリレーショナルデータベースサービスです。OSやDBエンジンのインストール、パッチ適用、バックアップなどをAWSが肩代わりしてくれるって感じです。
通常、RDSでMySQLを選択すると、OSやDBの管理はAWSにお任せできますが、裏側のハードウェア構成(アーキテクチャ) は、EC2(仮想サーバー)にEBS(ブロックストレージ)が紐づく、一般的な構成と基本的には同じです。
しかし、Amazon Aurora はアーキテクチャが根本から異なります。
以下表がこの記事の結論になりますが、アーキテクチャの違いによって、レプリケーション方法も異なり、それによりレプリカ追加時の負荷、耐障害性にもいい影響をもたらしています。
| 特徴 | Amazon RDS (MySQL) | Amazon Aurora (MySQL) |
|---|---|---|
| アーキテクチャ | インスタンス(計算資源)とストレージが密結合 (EBS) | インスタンス(計算資源)とストレージの完全分離 |
| レプリケーション | マルチAZはストレージ同期 リードレプリカはBinlog転送 |
共有分散ストレージ + REDOログ転送 |
| レプリカ追加時の負荷 | マスターからデータをコピーするため負荷増 | ストレージを共有するため負荷ほぼゼロ |
| 耐障害性 | マルチAZ構成でスタンバイ機へ同期 | ディスク障害は自動修復、インスタンス障害はリーダーが昇格 |
最大の違いは 「Compute(計算資源)とStorage(保存領域)の完全な分離」 です。
2. Auroraの思想:「The Log is the Database」
Auroraの特徴としてよく挙げられるのが、「データを3つのAZ(アベイラビリティゾーン)に各2つずつ、合計6つのコピーとして保存する」 という点です。
ここで疑問が湧きます。 一般的な構成では1つのディスクに書き込むのに対し、Auroraはネットワーク越しに6箇所へ書き込みを行います。 「1箇所に書くよりも、6箇所へばら撒くAuroraの方が、処理が重くて遅くなるのでは?」
しかしAWS公式サイトによると、Auroraは 「標準的なMySQLの最大5倍のスループット」 を実現すると謳われています。 なぜコピー数が多いのに速いのか。 そのヒントは、Auroraのアーキテクチャについて解説された論文(後述の参考資料1)にある 「The Log is the Database(ログこそがデータベースである)」 という概念にありそうです。
2-1. 一般的なMySQL(InnoDB)の書き込み
比較のために、まずは一般的なMySQL(InnoDBエンジン)がデータを1行更新する際の挙動を見てみます。
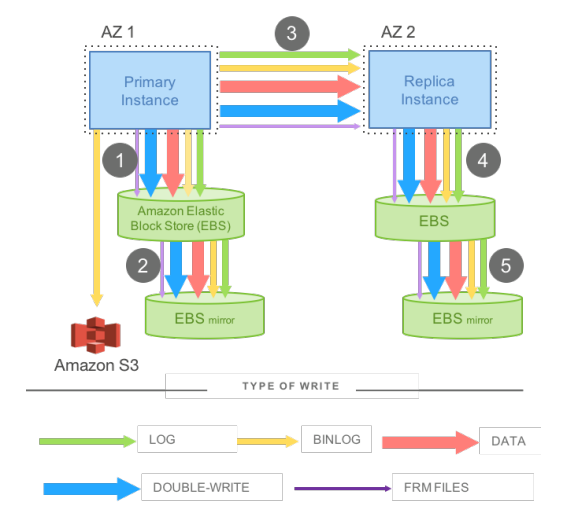
図:従来のミラーリングされたMySQLにおけるネットワークI/O
出典: Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases, Figure 2
データの整合性(ACID)を守るため、裏側では複数の種類のデータを書き込んでいます(画像下部の凡例参照)。
・緑の矢印:ReDoログ
・黄の矢印:バイナリログ
・赤の矢印:変更データ
・青の矢印:二重書き込みデータ
・紫の矢印:メタデータ
さらに、これらをレプリカにも転送して(画像の③)、同じ書き込み処理を繰り返します。
つまり、1行のデータを守るために、データ本体+αをネットワーク越しに何度も送受信している、ということです。
2-2. Auroraはログだけ送る
対して、Auroraの挙動は以下の図の通り。
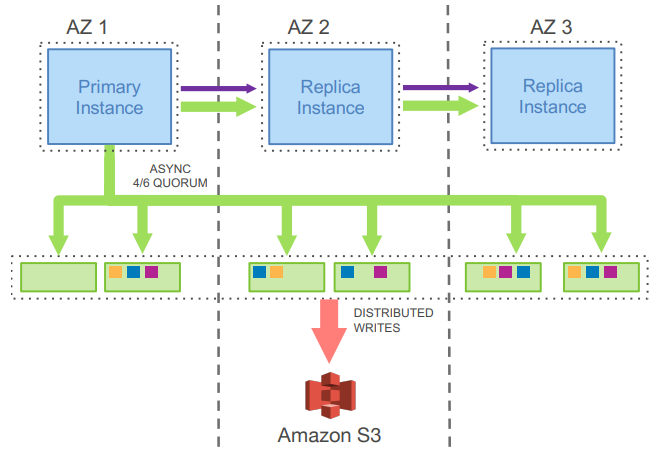
図:Amazon AuroraにおけるネットワークI/O
出典: Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases, Figure 3
マスターインスタンスは、ストレージに対して 「Redoログ(変更差分)」だけ をネットワーク送信します。
受け取ったストレージ側は、ログを元にデータブロックを生成します。
これにより、「6箇所にログだけをばら撒く通信量」の方が、「従来のMySQLが1箇所にデータ本体ごと書き込む通信量」よりも少なくなるわけです。
2-3. 書き込みの同期:Quorum(クォーラム)モデル
先程の図にも記載されてましたが、6つのストレージノードへの書き込み(並列)に対して、 「Quorum」 の考え方が使われています。
- 書き込み成功条件: 6つのうち、4つ以上のストレージノードから「書き込み完了(ACK)」が返ってくれば成功とみなす。
全てのノードの完了を待つ必要がないため、仮に1つのAZで遅延が発生していても、他のAZが正常なら書き込み性能は落ちない、ということです。
3. リードレプリカの同期はどうなっている?
この「ログしか送らない」仕組みは、読み取り専用の「レプリカ(Reader)」との同期(レプリケーション)にもメリットがあります。
3-1. ストレージを共有している
従来のRDSでは、マスターもレプリカもそれぞれがストレージを持っていて、「データのコピー」が発生していました。
Auroraでは、マスターもレプリカも 「共有分散ストレージボリューム」 を見ています。データの実体は一つ(物理的には6つだけど論理的には一つ)なので、そもそもデータをコピーして渡す必要がありません。
3-2. メモリ(バッファプール)の同期
「ストレージを共有しているなら、同期ラグはゼロでは?」と思いますが、実際には10〜20ミリ秒程度のラグがあります。これは オンメモリのキャッシュ(バッファプール) の更新にかかる時間です。
- マスターが更新実行。
- マスターはストレージにログを送ると同時に、レプリカに対しても非同期でRedoログを送信。
- レプリカは受け取ったログを使って、自分のメモリ上にある古いキャッシュページを更新または破棄する。
従来のレプリケーション(SQLの再実行)とは異なり、単純なメモリ更新処理だけなので、CPU負荷も低く、遅延も抑えられる、ということです。
4. 障害耐久性とフェイルオーバー
この「共有ストレージ × Quorum」の構成は、障害発生時にも効果がありそうです。
4-1. ディスク障害・AZ障害
仮に1つのAZが丸ごとダウン(2つのコピーが消失)しても、残り4つのコピーがあるため、書き込み(Quorum 4/6)も読み込み(Quorum 3/6)も継続可能です。
ユーザーは何も操作する必要がなく、バックグラウンドで自動的にデータの修復が行われます。
4-2. インスタンス障害(フェイルオーバー)
マスターインスタンスがダウンした場合、Auroraは自動的にリードレプリカの1つを新しいマスターに昇格させます。その結果、
- データロストのリスクがない: 直前までの書き込みは共有ストレージ層(Quorum)で保証されています。
- 切り替え時間が短い: AWS公式ドキュメントによると、通常30秒以内とされています。
Failover times are typically 30 seconds. (引用: Amazon Aurora User Guide: Fault tolerance for an Aurora DB cluster)
従来のRDSでは、スタンバイ機への切り替え時にストレージのリカバリ処理(Crash Recovery)が走りますが、Auroraはストレージ側で常にログ適用が行われているため、インスタンス起動時のリカバリ処理がほぼ不要です。
5. まとめ
Auroraについて調べてみた結果、単に高機能なRDSというわけではなく、「クラウドに最適化されたログ指向の分散ストレージシステムの上に、MySQL互換のインターフェースを載せて使っている」 という理解に至りました。
- 同期方法: Redoログのみを転送し、物理ストレージを共有する。
- なぜ速いか: データ本体を送らないことで、通信量(I/O)を削減したため。
- 障害耐久: 3AZ・6コピーのQuorum構成により、AZ障害にも無停止で耐えられる。
参考資料
- Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases
- Amazon Aurora の特徴
- Amazon Aurora ストレージと信頼性