概要
scikit-learn の決定木系のモデルを視覚化する方法についてのエントリーです。
最近良く使うので、備忘録&My チートシート代わりに書きます。
このエントリーでは、Windows版のPython3.5.2でサンプルコードを組んでいます。
環境の準備
決定木の視覚化にあたって必要なコンポーネントは以下の通りです。
- scikit-learn
- Graphviz
- pydotplus
Graphvizは、OSごとにインストール方法が異なります。
scikit-learn は、デフォルトで入っていることが多いのではないでしょうか。
一方 pydotplus は、pipでインストールする必要があるでしょう。
Graphviz のインストール(Windows7環境)
Graphviz は、Graph Visualization Software のことです。
DOT言語で記述された内容を画像にしてくれるライブラリです。
詳細はこちらを読んでください。
http://www.graphviz.org/Documentation.php
ダウンロードページは以下の通りです。
- Window版
http://www.graphviz.org/Download_windows.php
- RHEL,CentOS版
http://www.graphviz.org/Download_linux_rhel.php
- ubunts版
http://www.graphviz.org/Download_linux_ubuntu.php
- ソース版
http://www.graphviz.org/Download_source.php
Windows環境でインストールするので、以下のページからMSIファイルをダウンロードして実行します。
http://www.graphviz.org/Download_windows.php
ダウンロードしたMSIファイルを実行すると、まず以下の画面が表示されます。
「Next」をクリックして画面を進めます。
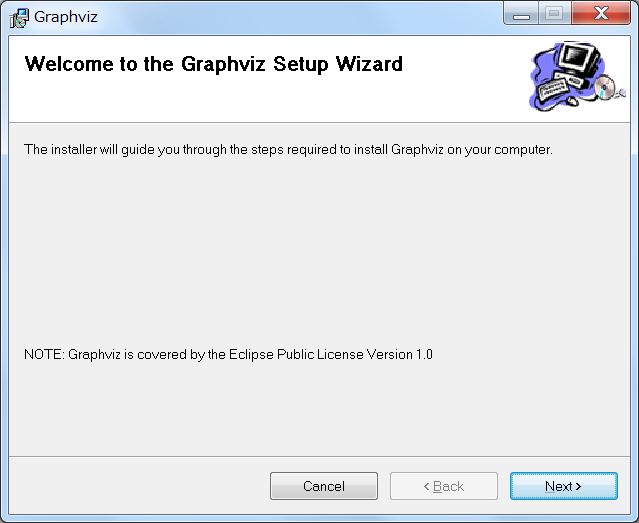
エントリー執筆時点(2017/09/03)のバージョンは2.38です。
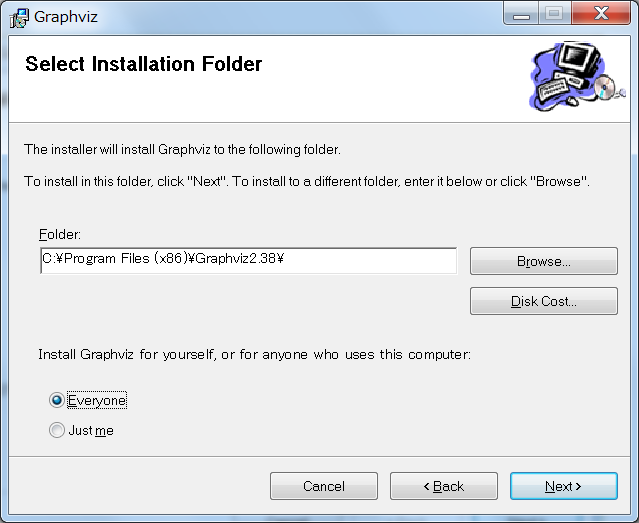
ここでは全てのユーザーが使えるように「Everyone」を選んだ状態で次に進みます。
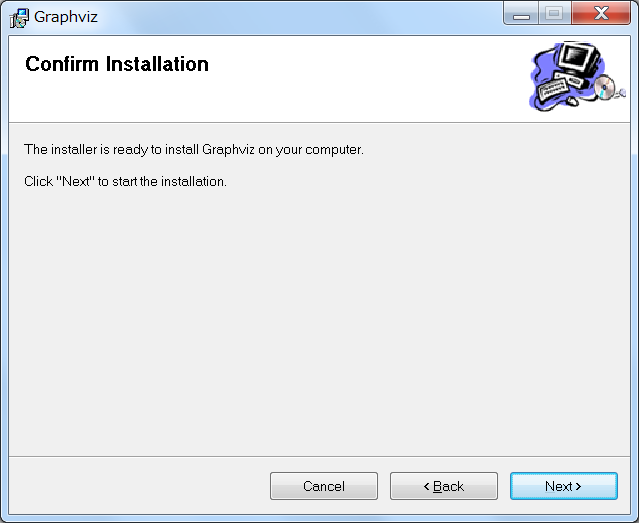
インストールの準備ができたことを知らせるメッセージです。
「Next」を押して進みます。
コンポーネントのインストールが進むにつれて、インジケーターのゲージが満ちていきます。
インジケータが完全に満たされたら「Next」をクリックします。

無事にGraphvizのインストールが完了しました。
「Close」をクリックして、ウィンドウを閉じます。
続いて Pydotplus のインストールに移ります。
pydotplus
先に述べたDOt言語を扱うためのpythonモジュールです。
今回はWindows環境なので、Anaconda Prompt で作業を進めます。

Anaconda Prompt起動したら、"pip install pydotplus"というコマンドを実行します。
(C:\Program Files\Anaconda3) C:\Users\usr********>pip install pydotplus
Collecting pydotplus
Downloading pydotplus-2.0.2.tar.gz (278kB)
100% |################################| 286kB 860kB/s
Requirement already satisfied: pyparsing>=2.0.1 in c:\program files\anaconda3\li
b\site-packages (from pydotplus)
Building wheels for collected packages: pydotplus
Running setup.py bdist_wheel for pydotplus ... done
Stored in directory: C:\Users\usr********\AppData\Local\pip\Cache\wheels\43\31\
48\e1d60511537b50a8ec28b130566d2fbbe4ac302b0def4baa48
Successfully built pydotplus
Installing collected packages: pydotplus
Successfully installed pydotplus-2.0.2
成功すると上記のような出力がされます。
エラーが発生して中断されなければ、pydotplus のインストール作業は以上で完了となります。
環境変数の設定
次に、pydotplus に Graphviz のインストールパスを認識させるべく、環境変数を編集します。
まず、graphvizがインストールされた場所にある "bin" ディレクトリの位置を確認します。
スタートメニューのリストにある「gvedit.exe」のプロパティを見ると確認できます。

このパス("C:\Program Files (x86)\Graphviz2.38/bin")を、環境変数pathに追加します。

path を変更したら、PythonのIDE(PyCharmなど)を再起動しておきます。
決定木系モデルの視覚化のサンプルコード
おなじみの irisデータセットを使って RandomForestモデルを作り、そのモデルの中から決定木モデルを一つ取り出して視覚化(=png画像で出力)してみました。
そのサンプルコードは以下の通りです。
内部処理を把握するためのデバッグ用print文をそのまま残してあります。
u"""
決定木系モデルを視覚化する。
Graphviz を用いて、決定木のモデルを視覚化する。
決定木だけでなく、ランダムフォレストなど木構造のモデルに適用できる。
"""
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.cross_validation import train_test_split
from sklearn.model_selection import cross_val_score
# モデルの木構造の視覚化に必要なパッケージ
from sklearn import tree
import pydotplus as pdp
import pandas as pd
import numpy as np
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
print(df.head(5))
print(iris.target)
print(iris.target_names)
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
print(df.head(5))
# 学習データとテストデータを分ける
features = df.columns[:4]
label = df["species"]
print(features)
print(label)
print(df[features].head(5))
df_train, df_test, label_train, label_test = train_test_split(df[features], label)
clf = RandomForestClassifier(n_estimators=150)
clf.fit(df_train, label_train)
print("========================================================")
print("予測の精度")
print(clf.score(df_test, label_test))
# 試しに木の一つを視覚化する
estimators = clf.estimators_
file_name = "./tree_visualization.png"
dot_data = tree.export_graphviz(estimators[0], # 決定木オブジェクトを一つ指定する
out_file=None, # ファイルは介さずにGraphvizにdot言語データを渡すのでNone
filled=True, # Trueにすると、分岐の際にどちらのノードに多く分類されたのか色で示してくれる
rounded=True, # Trueにすると、ノードの角を丸く描画する。
feature_names=features, # これを指定しないとチャート上で特徴量の名前が表示されない
class_names=iris.target_names, # これを指定しないとチャート上で分類名が表示されない
special_characters=True # 特殊文字を扱えるようにする
)
graph = pdp.graph_from_dot_data(dot_data)
graph.write_png(file_name)
それでは各部を見ていきます。
iris データセットを読み込んで、学習データを用意しているのは以下の部分です。
特徴量の名前ば iris.feature_names にセットされています。
目的変数(=アヤメの種類)は、iris.target にセットされています。
ただし、iris.targetは数字であり、人が読むのには不親切な状態です。
そこで iris.target_names にある種類名の表記を使い、人間が読める(=human-redable)な目的変数をdf['species'] にセットしています。
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
print(df.head(5))
print(iris.target)
print(iris.target_names)
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
print(df.head(5))
続いて、RandomForestモデルを作る部分のコードです。
学習データを格納した df は、目的変数も含んでいます。
特徴量の部分と目的変数を分けて、モデルにインプットする必要があります。
なので、特徴量部分は features に、目的変数は label にセットします。
そして、train_test_split でモデル学習用とテスト用のデータに分割します。
clf には、RandomForestオブジェクトがセットされます。使用する決定木の数は150個としています。(引数:n_estimator=150)
あとは 学習用データを指定して、fit()メソッドでモデルに学習させます。
features = df.columns[:4]
label = df["species"]
print(features)
print(label)
print(df[features].head(5))
df_train, df_test, label_train, label_test = train_test_split(df[features], label)
clf = RandomForestClassifier(n_estimators=150)
clf.fit(df_train, label_train)
そしていよいよ視覚化です。
RandomForestオブジェクトは estimators_ というプロパティを持っています。
estimators_ は、決定木オブジェクトのリストです。
ここではサンプルとして一番目の決定木オブジェクト(estimators[0])を視覚化します。
png画像ファイル "tree_visualization.png" として出力します。
tree.export_graphviz() が視覚化処理をしています。
引数の説明はコードのコメント中に記述しました。
引数をちゃんと指定しないと、特徴量名、分類名ともに表示されないので注意が必要です。
# 試しに木の一つを視覚化する
estimators = clf.estimators_
file_name = "./tree_visualization.png"
dot_data = tree.export_graphviz(estimators[0], # 決定木オブジェクトを一つ指定する
out_file=None, # ファイルは介さずにGraphvizにdot言語データを渡すのでNone
filled=True, # Trueにすると、分岐の際にどちらのノードに多く分類されたのか色で示してくれる
rounded=True, # Trueにすると、ノードの角を丸く描画する。
feature_names=features, # これを指定しないとチャート上で特徴量の名前が表示されない
class_names=iris.target_names, # これを指定しないとチャート上で分類名が表示されない
special_characters=True # 特殊文字を扱えるようにする
)
graph = pdp.graph_from_dot_data(dot_data)
graph.write_png(file_name)
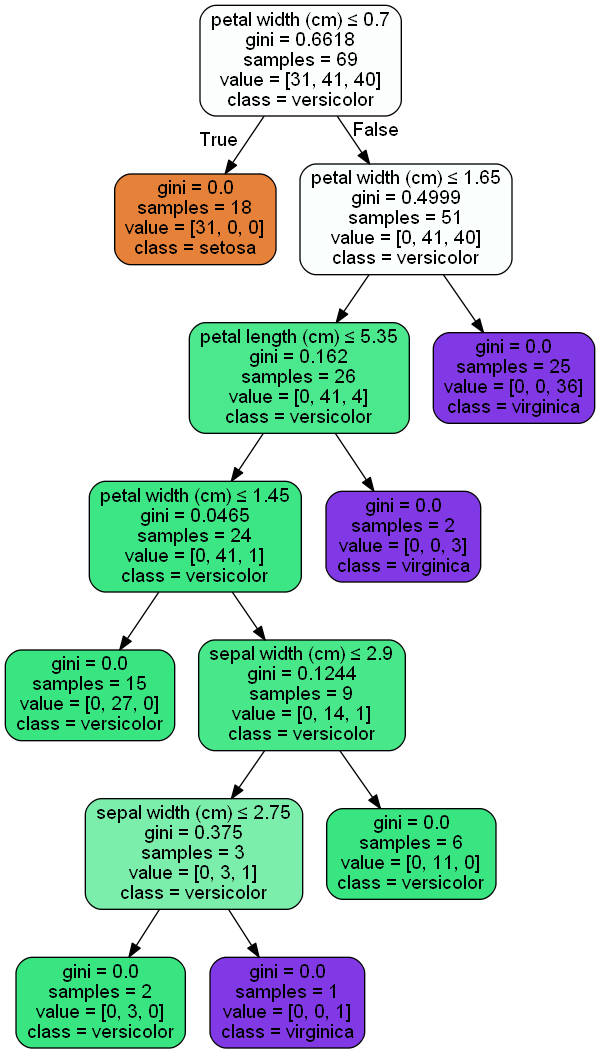
すると以下のように決定木が視覚化されたものが、png画像として得られます。