Ollama Cloud モデルとは
Ollama's cloud models are a new kind of model in Ollama that can run without a powerful GPU. Instead, cloud models are automatically offloaded to Ollama's cloud service while offering the same capabilities as local models, making it possible to keep using your local tools while running larger models that wouldn't fit on a personal computer.
Ollamaといえば「ローカルでLLMを動かすツール」というイメージが強いですが、2025年末ごろからクラウドモデルという新しい仕組みが加わりました。
通常のOllamaモデルはローカルのGPUで推論を行うため、大きなモデルほど高スペックなマシンが必要です。クラウドモデルはその制約を取り除いたもので、モデルの実行はOllamaのクラウドインフラ(NVIDIAのGPUクラスタ)に自動でオフロードされます。ユーザー側からはローカルモデルと同じAPIやCLIで使えるため、既存のツール群やワークフローをそのまま活用できる点が特徴です。
対応モデルの一覧はモデルライブラリ(cloudフィルタ)で確認できます。
料金プランについて
プランは無料・Pro・Maxの3段階です。
| プラン | 月額 | 同時実行モデル数 | 用途感 |
|---|---|---|---|
| Free | $0 | 1 | 試用・評価、小規模なコーディング補助 |
| Pro | $20 | 3 | 日常的な開発作業、大規模モデルの利用 |
| Max | $100 | 10 | 継続的なエージェントタスク、複数エージェントの並列実行 |
Proは年払いにすると$200/年(月換算で約$16.7)になります。
使用量の考え方
ローカルモデルの実行は常に無制限です。クラウド利用分のみ制限があり、セッション制限(5時間ごとにリセット)と週次制限(7日ごとにリセット)の2軸で管理されます。
使用量はトークン数ではなくGPU利用時間ベースで計測されます。リクエストが短ければそれだけ消費量も少なく、プロンプトキャッシュが効く場合はさらに節約できます。ハードウェアやモデルアーキテクチャの効率が向上すれば、同じプランでより多く使えるようになる設計思想とのことです。詳細
セットアップ方法
まずOllamaをインストールします。
# macOS / Linux
$ curl -fsSL https://ollama.com/install.sh | sh
次に ollama.com のアカウントでサインインします。
$ ollama signin
あとはクラウドモデルをそのまま実行するだけです。
$ ollama run glm-5.1:cloud
pull と run は通常モデルと同じコマンドで動きます。APIでも同様で、localhost:11434 に対して普通にリクエストするだけです。
実際になんか作らせてみた
glm-5.1:cloud で試したら403が出た
# glm-5.1:cloud
Please run /login · API Error: 403 {"type":"error","error":{"type":"permission_error","message":"model is
experiencing high volume. while capacity is being added, a subscription is required for access:
https://ollama.com/upgrade (ref:
5ca53222-5dcd-47f5-92e4-f1e026352a3a)"},"request_id":"req_a33743a0ad38f6f475e35125"}
Freeプランだと glm-5.1:cloud のような需要の高いモデルは混雑時にサブスクリプションが要求されることがあるようです。glm-5.1はエージェントエンジニアリング向けの次世代フラッグシップモデルで、SWE-Bench Proでトップクラスの性能を発揮するだけあって人気が集中しているのかもしれません。
kimi-k2.5:cloud でエージェントチームを組ませてみた
Agent Teamsを試してみたくて kimi-k2.5:cloud で入門してみました。
$ ollama launch claude --model kimi-k2.5:cloud
> チームを作ってほしい
システムアーキテクチャ担当とテックリードの2人です

ollama launch コマンドとは
run がシンプルな対話実行であるのに対し、launch は外部アプリケーションを特定のモデルと組み合わせて起動するコマンドです。たとえば ollama launch claude --model glm-5.1:cloud は Claude Code(エージェントコーディング環境)のバックエンドとして glm-5.1:cloud を使う形で起動します。他にも Codex や OpenCode など、対応アプリが増えてきています。
スクリーンショットを見ると、system-architect と tech-lead の2エージェントで合計約72kトークンを消費。セッション使用率13.9%・週次使用率4.7%だったので、逆算するとセッション上限は約500k、週次上限は約1,500k相当ではないかと予想しています(使用量はGPU時間ベースのため、トークン数との対応は厳密ではありません。また公式は非公開)。
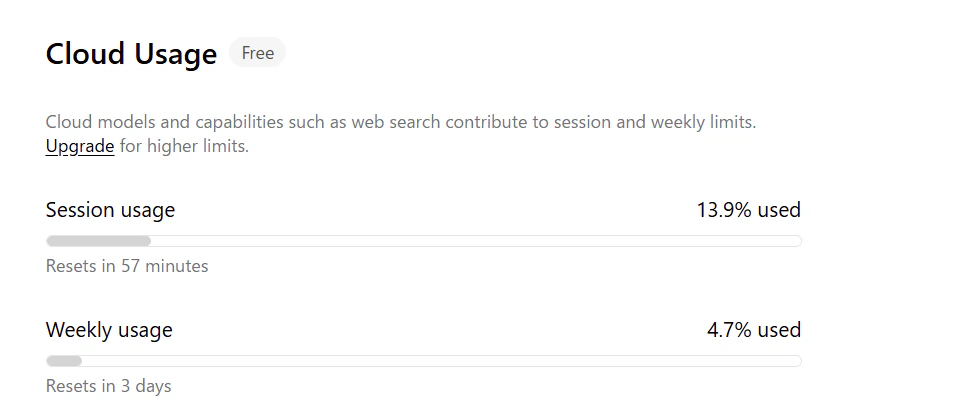
体感としては、ローカルで動かすよりもレスポンスが安定していて速い印象でした。GPU環境を用意しなくてもエージェントワークフローが試せるのは素直に便利です。
ただ、Agent Teamsで遊んでいたので本当に一瞬でレート制限に達してしまいました。cloudオンリーで何かする場合、いろいろ工夫が必要になるかもしれないですね。
Q & A
Q. optout(データ学習除外)設定はどうなっている?
公式によると、プロンプトや応答データがログ収集・学習に使われることはないとのことです。またOllamaがモデルホスティングのパートナーと契約する際も、ノーロギング・ノートレーニング・ゼロデータ保持ポリシーを要件としているそうです。ただしローカルモードで完全にクラウドを無効化したい場合は ollama の設定から Ollama Cloud 機能をオフにすることもできます(FAQ参照)。
Q. 制限はどれくらい?
セッション(5時間)と週次(7日)の2段階でリセットされる仕組みで、具体的な数値は公開されていません。使用状況はアカウントの設定ページで確認でき、上限の90%に達するとメールで通知が届きます。追加購入は近日対応予定とのことです。