ここ数年のMLflowの進化が激しすぎて、おっさんついていくの大変です。
Models From Codeや今回のChatModelのようにLLMやエージェントをMLflowで管理できるようにするための新機能が目白押しです。
ChatModelに関しては、先人がすでに色々試されています。
この辺り、私は全然追えていなかったので、今更ではありますがチュートリアルを翻訳しました。
で、上のチュートリアルを動かそうとして詰まっていたのですが、ようやく動きました。
チュートリアルでは、MLflowフレーバーを持たないOllamaを使っているので、そちらを動かすところからです。
上の @isanakamishiro2 さんがOllamaもすでに動かされていたので、参考にさせていただきます。毎度ありがとうございます。
シェルで以下を実行するだけでOllamaが起動します。
%sh
curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
>>> Downloading Linux amd64 bundle
######################################################################## 100.0%
>>> Creating ollama user...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
WARNING: Unable to detect NVIDIA/AMD GPU. Install lspci or lshw to automatically detect and install GPU dependencies.
ライブラリをインストール、MLflowは最新にします。
%pip install ollama
%pip install -U mlflow
dbutils.library.restartPython()
llama3.2:1bをダウンロードします。
import ollama
ollama.pull('llama3.2:1b')
ProgressResponse(status='success', completed=None, total=None, digest=None)
動作確認します。optionsがあるとエラーになるのでコメントアウトしています。
import ollama
from ollama import Options
from rich import print
response = ollama.chat(
model="llama3.2:1b",
messages=[
{
"role": "user",
"content": "What is MLflow Tracking?",
}
],
#options=Options({"num_predict": 25}),
)
print(response)
ChatResponse(
model='llama3.2:1b',
created_at='2025-02-15T22:53:35.014169842Z',
done=True,
done_reason='stop',
total_duration=7032509619,
load_duration=3203765726,
prompt_eval_count=31,
prompt_eval_duration=418000000,
eval_count=367,
eval_duration=3409000000,
message=Message(
role='assistant',
content="MLflow Tracking (MFT) is an open-source platform for managing and tracking machine learning
experiments, including training data, model evaluation, hyperparameter tuning, and model deployment. It's a part of
the larger MLflow ecosystem, which provides a comprehensive framework for reproducibility, collaboration, and
automation in machine learning.\n\nWith MFT, you can track various aspects of your machine learning workflow, such
as:\n\n1. **Experiment metadata**: Store information about the experiment, including its name, description,
authors, and tags.\n2. **Run metadata**: Track details about each run, like input data, computational resources,
and execution times.\n3. **Model performance**: Record metrics for model evaluation, training, and testing, such as
accuracy, precision, recall, and F1 score.\n4. **Hyperparameter tuning**: Store information about hyperparameters
optimized during the experiment, including their values and ranges.\n5. **Model deployment**: Track deployments to
different environments, like cloud services or on-premises infrastructure.\n\nMFT provides a standardized way of
sharing and referencing experiments across teams, organizations, and applications. It supports various data
formats, such as CSV, JSON, and TensorFlow checkpoints, making it easy to import and export experiment metadata
from other tools.\n\nSome key benefits of using MFT include:\n\n* **Reproducibility**: Easily reproduce experiments
by restoring the necessary information.\n* **Collaboration**: Share experiments with team members or stakeholders
through public repositories.\n* **Automation**: Automate tasks like data preparation, model serving, and monitoring
using MLflow's built-in APIs.\n* **Improved accountability**: Track changes to experiment metadata and
dependencies.\n\nWhile MFT is primarily designed for machine learning workflows, it can be used with any type of
experiment or research project that involves Python, TensorFlow, or other popular machine learning frameworks.",
images=None,
tool_calls=None
)
)
ChatModelを拡張したカスタムのSimpleOllamaModelを実装して、ollama_model.pyとして保存します。これをModels From CodeアプローチでMLflowにロギングします。あと、ここではオリジナルのコードからreturn ChatCompletionResponseの中身を変更しています。後で説明します。
%%writefile ollama_model.py
from mlflow.pyfunc import ChatModel
from mlflow.types.llm import ChatMessage, ChatCompletionResponse, ChatChoice
from mlflow.models import set_model
import ollama
class SimpleOllamaModel(ChatModel):
def __init__(self):
self.model_name = "llama3.2:1b"
self.client = None
def load_context(self, context):
self.client = ollama.Client()
def predict(self, context, messages, params=None):
# Ollama用のメッセージを準備
ollama_messages = [msg.to_dict() for msg in messages]
# Ollamaを呼び出す
response = self.client.chat(model=self.model_name, messages=ollama_messages)
# ChatCompletionResponseを準備して返す
return ChatCompletionResponse(
choices=[{"index": 0, "message": ChatMessage(role=response["message"]["role"], content=response["message"]["content"])}],
model=self.model_name,
)
set_model(SimpleOllamaModel())
オリジナルのコードは
# ChatCompletionResponseを準備して返す
return ChatCompletionResponse(
choices=[{"index": 0, "message": response["message"]}],
model=self.model_name,
)
となっています。
上のコードをロギングします。Databricksの場合、ノートブックエクスペリメントが使えるので、set_experimentはコメントアウトしています。あと、ChatModelでは自動でモデルのシグネチャが推定されるので、推定に必要な入力サンプルinput_exampleもコメントアウトしています。input_exampleがあるとTypeError: 'method' object is not subscriptableというエラーになりました。
import mlflow
#mlflow.set_experiment("chatmodel-quickstart")
code_path = "ollama_model.py"
with mlflow.start_run():
model_info = mlflow.pyfunc.log_model(
"ollama_model",
python_model=code_path,
#input_example=input,
)
そして、input_exampleをコメントアウトしても、オリジナルのコードでは、
ValueError: Expected `message` to be either an instance of `ChatMessage` or a dict matching the schema. Received `Message`
というエラーになりました。これで悩みましたが、結局のところChatModelの肝となる入出力のマッピングが間違っていたためでした。カスタムモデルのクラスの戻り値はChatCompletionResponseである必要がありますが、こちらから構造を紐解いていくとChatChoiseのリストが含まれており、ChatChoiceにはmessageというキーでChatMessageが格納されています。これはroleとcontentという、チャットモデルは一般的な構成となっています。しかし、オリジナルのコードはこの構成に準拠していなかったのでエラーとなっています。
MLflowの進化の過程でこうなったのかまでは追えていませんが、いずれにしても上記の修正が必要でした。今後はmlflow.typesを注視する必要があるのかなと思いました。
うまくロギングできると以下のように表示されます。

Predicting on input example to validate output(出力を検証するために入力サンプルで予測を実施)とあるように、出力を検証する過程で上記エラーメッセージが出ていたということです。
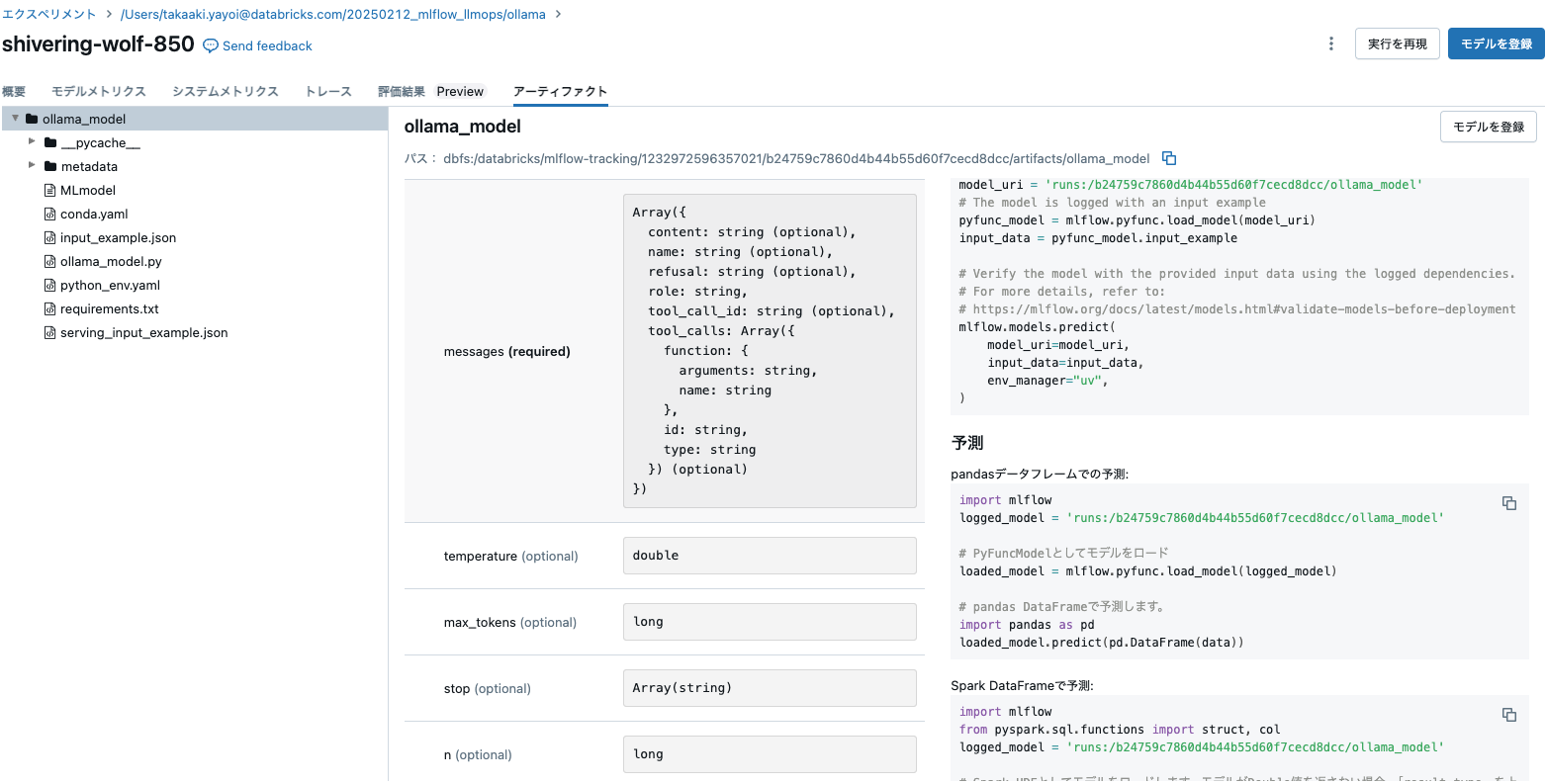
フレーバーはpyfuncとしてモデルが記録されます。
アーティファクトを確認すると、必須の入力message以外にtemperatureやmax_tokensのようにお馴染みのパラメーターもプリセットされています。
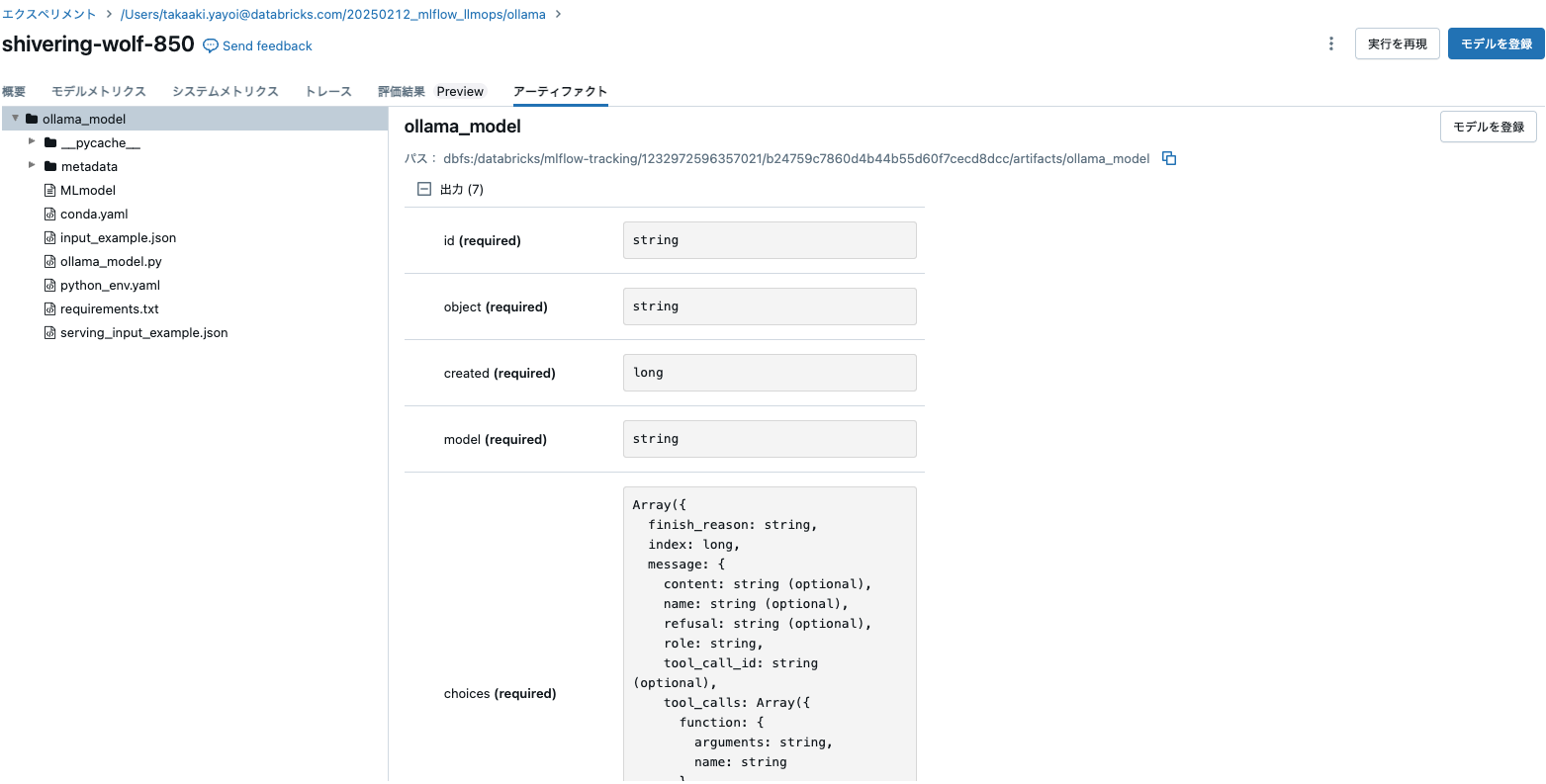
ロードして使ってみます。
loaded_model = mlflow.pyfunc.load_model(model_info.model_uri)
result = loaded_model.predict(
data={
"messages": [{"role": "user", "content": "What is MLflow?"}],
"max_tokens": 25,
}
)
print(result)
結果が得られていますが、トークン数は明らかに25よりも多くなっています。これは、この時点ではパラメーターがChatModelに引き渡されていないためです。そちらに関してはチュートリアルでカバーされています。
{
'choices': [
{
'message': {
'role': 'assistant',
'content': "MLflow (Machine Learning Flow) is an open-source software framework for managing and
tracking machine learning models, experiments, and deployments. It's designed to simplify the process of building,
training, deploying, and managing machine learning models in various environments, including data science teams,
research institutions, and enterprises.\n\nWith MLflow, you can:\n\n1. **Track model performance**: Monitor metrics
such as accuracy, precision, recall, F1-score, and others to evaluate the effectiveness of your models.\n2.
**Manage experiments**: Run multiple iterations of an experiment, with parameters like hyperparameter tuning or
data augmentation, and track their results.\n3. **Deploy models**: Integrate MLflow with various cloud providers
(e.g., AWS SageMaker, Google Cloud AI Platform) or on-premises environments to deploy your models in
production.\n4. **Integrate with data science workflows**: Easily integrate MLflow into existing data science
pipelines using popular tools like Jupyter Notebooks, Airflow, and GitLab CI/CD.\n\nMLflow provides several key
features:\n\n1. **Model serving**: Deploy trained models as a cloud-based service or on-premises
infrastructure.\n2. **Data pipeline integration**: Integrate MLflow with popular data processing tools (e.g.,
Apache Beam, Dask) to automate data preparation and transformation.\n3. **Hyperparameter tuning**: Use libraries
like GridSearchCV, RandomizedSearchCV, and Bayesian Optimization for hyperparameter tuning.\n4. **Model
versioning**: Track changes to model versions, allowing you to roll back to previous versions if needed.\n\nBy
using MLflow, developers can:\n\n* Reduce the risk of overfitting or underfitting by monitoring performance and
experiment results\n* Improve model efficiency by automating data processing and deployment\n* Enhance
collaboration among team members with a shared understanding of the model's history and changes\n\nOverall, MLflow
is an essential tool for any machine learning project that requires tracking, managing, and deploying models across
multiple environments."
},
'index': 0,
'finish_reason': 'stop'
}
],
'model': 'llama3.2:1b',
'object': 'chat.completion',
'created': 1739663591
}
フレーバーがないモデルであれば、PyFuncでやればいいところを、ユースケースとして増加の一途を辿る生成AIチャットbotやエージェント向けにプリセットされたインタフェースを提供するのがChatModelだと理解しました。
ただ、入出力のマッピングには慣れが必要だと感じましたし、こちらで説明されているように後継のChatAgentも出てくるということで、この激しい変化を所与のものとして、このビッグウェーブを乗り越えていく必要があるのだなとしみじみ感じた週末でした。