こちらのイベントで説明した内容です。

自己紹介

弥生 隆明と言います。4年前にDatabricksにジョインしました。
Spark本の宣伝と会社紹介
今月、Spark本を出しました!DatabricksはSparkのクリエーターが創業した会社です。


今日お話ししたいこと
もちろん、DBRXをご説明しますが、それだけではありません。DBRX含む生成AIに対するDatabricksのスタンスについてもお話しさせてください。
その前に、「Dolly」を覚えていますか?

- こちらのイベントでも紹介させていただきましたが、去年の4月にバージョン2.0を公開しましたEleutherAIのpythiaモデルファミリーをベースとした12Bのパラメーターを持つ言語モデルです
- これは以下の我々の理念のもと取り組んだものです
- お客様自身がモデルを所有し、自分のデータを活用してアプリケーションを構築できるようにすべきです
- 今日の他の方の発表でも触れられていた、バイアスや説明可能性に関する重要な問題やAIの安全は、数社の大企業ではなく多様なステークホルダーのコミュニティによって取り組まれるべきです
これらの理念を変えることなしに、我々は新たなオープンLLMを開発・公開しました
DBRXのご紹介
DBRXはDatabricksによるオープンソースLLMです。
-
DBRX Base 事前トレーニング済みモデル
- スマートなオートコンプリートのように動作 - 何を言ったとしても続きを生成します。
- ご自身のデータでファインチューニングする際に有用です。
-
DBRX Instruct ファインチューニングモデル
- 質問回答や指示追従を行うように設計されています。
- ドメイン固有のデータに対する追加トレーニング、指示追従のためのファインチューニングを行うことでDBRXをベースとして構築されています。
実機デモ
詳細に入る前にデモをさせてください。こちらはDatabricksで提供されているAI Playgroundというものでして、複数のLLMに対して同じプロンプトを投入して挙動を比較することができます。Llama 2と比較してみます。
見てわかりますように非常に高速です。この理由は後で触れます。
ベンチマーク
DBRXは言語理解(MMLU)、プログラミング(HumanEval)、数学(GSM8K)において、(発表時点で)有名なオープンソースモデルを上回っています。
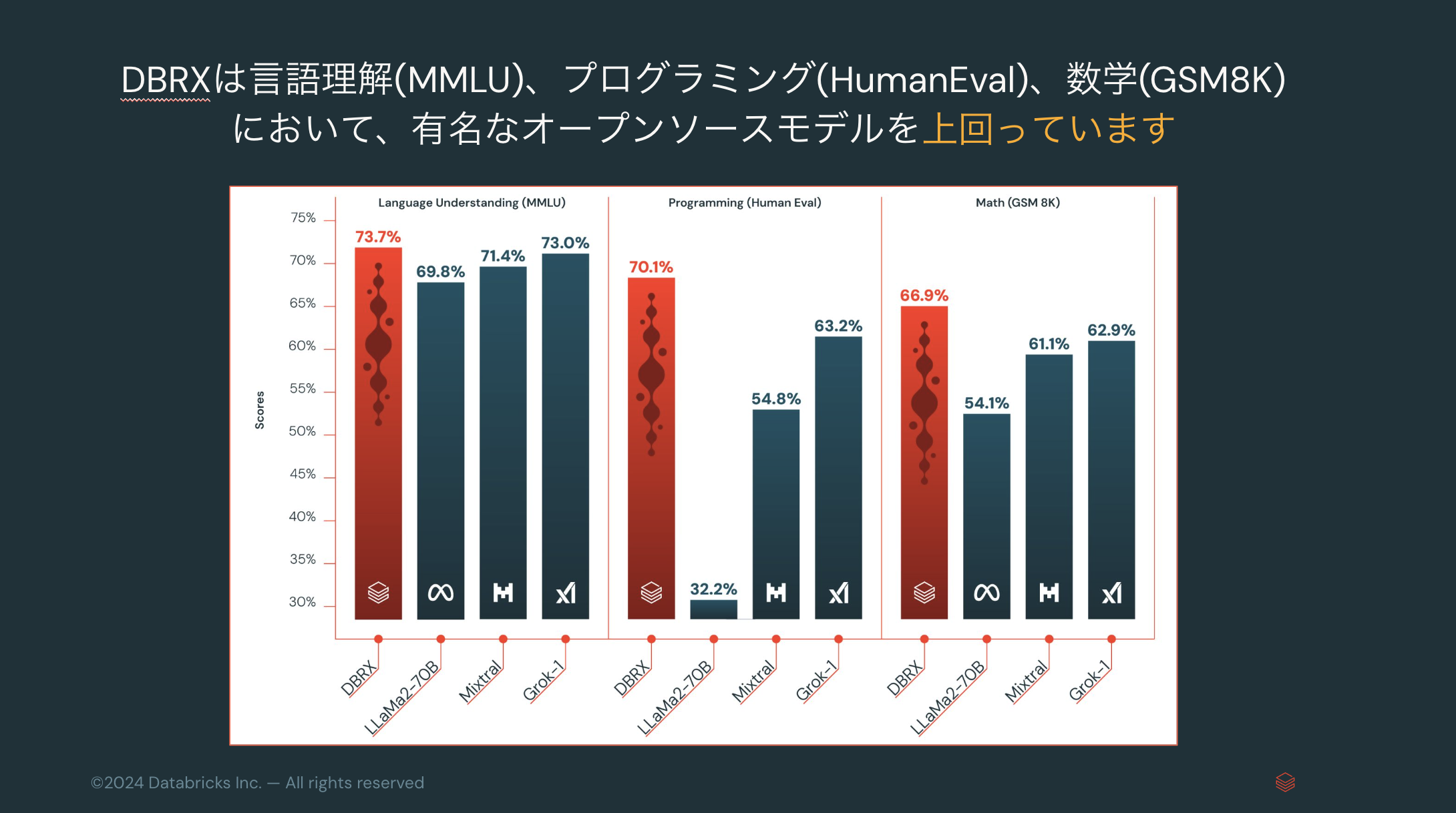
ベンチマークの詳細はこちらをご覧ください。
DBRXアーキテクチャ
- DBRXは次トークン予測を用いてトレーニングされたデコーダーオンリーのトランスフォーマーベースの大規模言語モデル(LLM)です。
- DBRXはDatabricksにおいて完全にゼロから構築されました。
- DBRXは公開オンラインデータソースを用いて事前トレーニングされました。
- DBRXのトレーニングには顧客データは使用されていません。注意深く選別された12Tのトークンでトレーニングしており、最大コンテキスト長は32kトークンです。
- 我々は事前トレーニングにおいて、モデルの品質が劇的に改善されることを発見した方法で、データミックスを変更するcurriculum learningを用いています。
- このモデルは3072枚のNVIDIA H100を用いて事前トレーニングされました。事前
トレーニング、事後トレーニング、評価、レッドチーム、改善を含め、約3ヶ月を要しました。 -
Fine-grained sparse mixture-of-experts (MoE) モデルアーキテクチャ
- MoEの特徴である”sparse”と対比して、標準的な非MoEモデルは時に”dense”モデルと呼ばれます。
-
132Bのパラメーターおよび最大32Kトークンをサポート
このモデルの合計パラメーター数は132Bですが、モデルのトレーニング、ファインチューニング、推論の実施の際には、どのような入力が与えられたとしても36Bのみが使用されます。これが先ほどのデモでお見せしたように、レスポンスが高速な理由です。 - Dropless実装
- このモデルは企業環境において企業によって利用されることを想定して設計されています。
- MixtralやGrokのような他のオープンMoEモデルと比較して、DBRXはきめ細かいです - より小規模な大量のエキスパートを使用します。
- ネットワークの各レイヤーは16の”エキスパート”に分割されます。
- それぞれの入力に対して、ネットワークは動的に4つのエキスパートを選択して利用します。すなわち、このネットワークは16のエキスパートのうち4つのエキスパートを利用します。
- DBRXではrotary position encodings (RoPE)、gated linear units (GLU)、grouped query attention (GQA)を使用しています。
-
tiktokenリポジトリで提供されているGPT-4 tokenizerを使用しています。
- 徹底的な評価と大規模な実験をベースとしてこの選択を行いました。
DBRXの構築方法
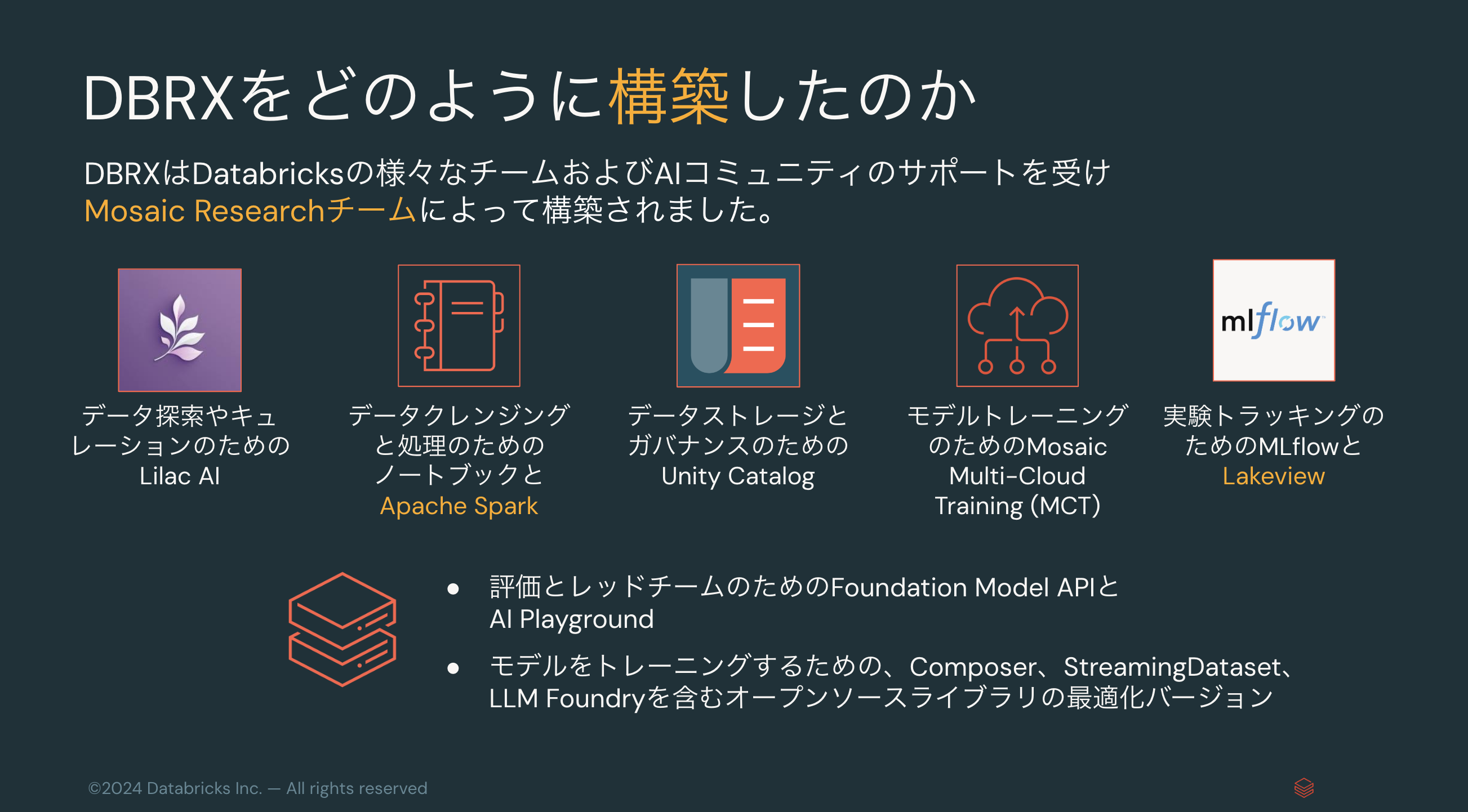
DBRXはDatabricks上で構築されました。これは、皆様自身でも自分のデータを用いてDBRX相当のLLMを構築できるということを意味します。また、以下のオープンソースライブラリを活用しています。
Databricksが提供するApache Spark、Unity Catalog、MLflow、Lakeviewなども活用しています。
どうやってDBRXを試す?
- Hugging Face Databricks Space
- Databricks AI PlaygroundやFoundation Model API
- DBRX GitHub
生成AIに対するDatabricksのスタンス - モデルニュートラル
DBRXのサマリー
- DBRXはオープンソースLLMの新記録を樹立し、プロプライエタリ(クローズドソース)LLMと同等、比類するものとなっています。
- 合計132Bのパラメーターを持つFine-grained sparse mixture-of-experts (MoE) モデルアーキテクチャ
- Mosaic Research、Databricks、AIコミュニティのテクノロジーによって構築されました。
- DBRXはMoEアーキテクチャ、優れたデータ、GPT-4 tokenizer によって優れたトレーニング効率性を有しています。
- DBRXは、SQLのようなアプリケーションのように我々のGenAI-powered製品にすでに組み込まれています。早期のロールアウトではGPT-3.5を上回っており、GPT-4に迫るものとなっています。
- また、RAGタスクにおいてもオープンモデルやGPT-3.5を上回るモデルとなっています。
モデルニュートラルが大切です
- しかし、DBRXも数多くのLLMの一つに過ぎません。
- DBRX発表後も、Meta Llama 3やSnowflake Arcticなど優れたLLMが発表され
続けていますし、今後もこの流れは継続していきます。- DatabricksではMeta Llama 3をサポートしており、直接利用できるようになっています。
- Meta Llama 3、DBRX、Azure OpenAIなどのLLMはお客様の要件に基づいて適切に選択することが重要です。
- Databricksはモデルニュートラルが重要であると考えており、Databricksが様々なモデルの開発、運用、監視のためのプラットフォームであり続けます。
- DBRXのような高品質なLLMがDatabricksプラットフォームで構築できるということをお伝えしたかったのです。
- DollyやDBRXなどを通じて、昨年から続いているLLM普及の一助になりたいと考えています。
懇親会
LLMの今後についての話になったので、こちらのCompound AI Systemについて触れさせていただきました。