こちらの続きです。
元々はこちらを実現したかったのでした。カメラモジュールがあるので、それをマルチモーダルモデルの入力にしたらどうだろうと、よくある発想かもしれませんが実装したら面白かったです。
ベースにしたのはこちらです。
元記事は、テキストのプロンプトと画像のURLを受け取る実装になっていましたが、Raspberry Piの画像を直接受け取る形に変更します。
カメラモジュールの操作に関してはこちらが非常に助けになりました。ありがとうございます。
Databricks側の実装
モデル入力のインタフェースを変更します。画像をBase64エンコードを受け取るようにします。こちらを参考にさせてもらいました。
import mlflow
import pandas as pd
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
from PIL import Image
import requests
import io
import base64
class Model(mlflow.pyfunc.PythonModel):
def __init__(self):
self.processor = LlavaNextProcessor.from_pretrained(model_id)
self.model = LlavaNextForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
cache_dir="/Volumes/users/takaaki_yayoi/llava_test")
self.model.to("cuda:0")
def predict(self, context, model_input):
processor = self.processor
model = self.model
results = []
for mi in model_input:
im_b64 = mi[0]
prompt = mi[1]
# convert it into bytes
img_bytes = base64.b64decode(im_b64.encode('utf-8'))
# convert bytes data to PIL Image object
image = Image.open(io.BytesIO(img_bytes))
# Prepare inputs
inputs = processor(prompt, image, return_tensors='pt').to(0, torch.float16)
# Generate and store response
output = model.generate(**inputs, max_new_tokens=150, do_sample=False)
result = (processor.decode(output[0], skip_special_tokens=True))
results.append(result)
return results
# 関数をモデルとして保存
with mlflow.start_run():
mlflow.pyfunc.log_model(
"model",
python_model=Model(),
pip_requirements=['transformers==4.39.0', 'mlflow==2.11.3', 'tensorflow', 'torch', 'Image', 'requests'],
signature=signature
)
run_id = mlflow.active_run().info.run_id
これでGPUサービングエンドポイントにデプロイします。前回同様にURLとパーソナルアクセストークンを準備しておきます。
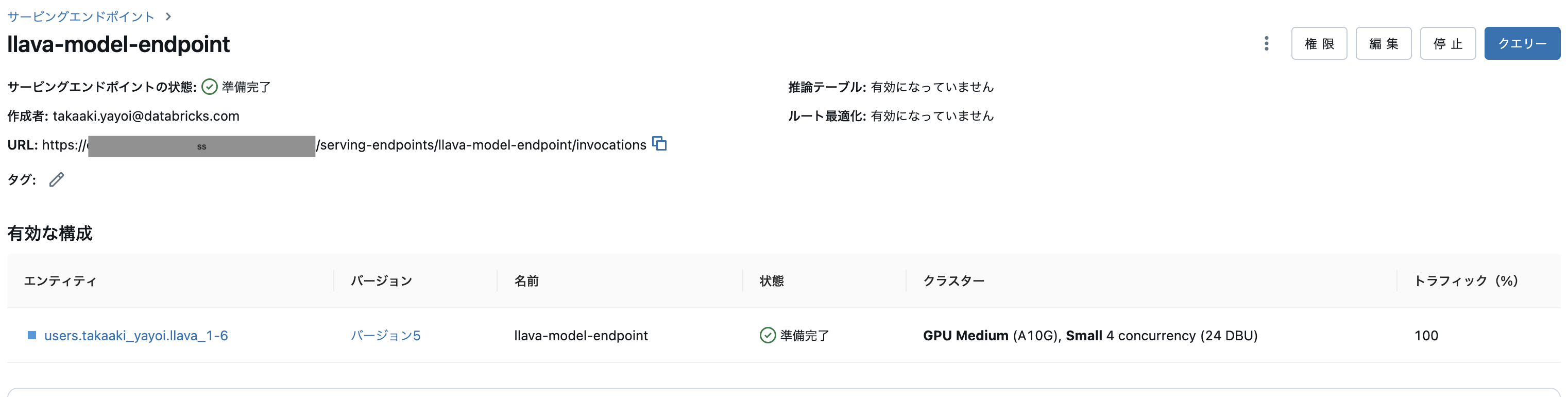
Raspberry Pi側の実装
前回のものを拡張して、カメラの画像をモデルサービングエンドポイントに送信するようにします。あと、こちらを参考にpicamera2を使えるように仮想環境を作り直しました。
python -m venv --system-site-packages env
source env/bin/activate
/home/yayoi/Documents/env/bin/pip install openai requests scipy pyopenjtalk
コードの実態はこちら。2.4Hzの通信をしているので、画像をそのまま送信するとそれがボトルネックになってしまっていたので、画像サイズを小さくしています。
multimodal.py
import os
# 音声発話向けライブラリ
import pyopenjtalk
from scipy.io import wavfile
import numpy as np
import subprocess
# カメラ向けライブラリ
from picamera2 import Picamera2
import requests
import json
import re
import base64
from io import BytesIO
from PIL import Image
# レスポンスの読み上げを格納する音声ファイル
wave_file = "/home/yayoi/Documents/dbx/talk.wav"
# テキストを発話
def synthesize_voice(text):
x, sr = pyopenjtalk.tts(text)
wavfile.write(wave_file, sr, x.astype(np.int16))
cmd = f'/usr/bin/aplay {wave_file}'
process = (subprocess.Popen(cmd, stdout=subprocess.PIPE,
shell=True).communicate()[0]).decode('utf-8')
# PIL ImageをBase64に変換
def pil_to_base64(img, format="jpeg"):
buffer = BytesIO()
img.save(buffer, format)
img_str = base64.b64encode(buffer.getvalue()).decode("ascii")
return img_str
# How to get your Databricks token: https://docs.databricks.com/en/dev-tools/auth/pat.html
DATABRICKS_TOKEN = os.environ.get('DATABRICKS_TOKEN')
# Alternatively in a Databricks notebook you can use this:
# DATABRICKS_TOKEN = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
print("##### camera initialize.")
# 画像保存先
img_file = "/home/yayoi/Documents/capture.jpg"
# 撮影
camera = Picamera2()
config_capture = camera.create_still_configuration()
camera.configure(config_capture)
camera.start()
image = camera.capture_image()
image = image.resize((160, 128)) # サイズ変更
im_b64 = pil_to_base64(image) # Base64エンコード
print("##### photo captured.")
prompt = '[INST] <image>\n画像を簡潔に説明してください[/INST]'
# 画像を保存
image.save(img_file, 'JPEG')
data = {
"inputs": [(im_b64, prompt)]
}
#print(data)
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {DATABRICKS_TOKEN}"}
print("##### sending request.")
response = requests.post(
url="<エンドポイントのURL>", json=data, headers=headers
)
#response = json.dumps(response.json(), ensure_ascii=False)
response_list = response.json()["predictions"]
response_text = re.sub(r"\[?.*\]", "", response_list[0])
print(response_text)
synthesize_voice(response_text)
動作確認
動かします。
/home/yayoi/Documents/env/bin/python /home/yayoi/Documents/multimodal.py
キャプチャされた画像はこちらです。

やっぱり、色々なインタフェースと組み合わせるとさらに興味深いものになりますね。