Lakehouse Powers NLP in Insurance | Databricks Blogの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Insurance LLM Solution Acceleratorのダウンロード
イントロダクション
現在の経済的、社会的状況は、顧客の期待値や嗜好を再定義しました。社会はよりデジタルになることを強いられており、これは保険会社のカスタマーサービスにも到達しています。
しかし、データドリブンのマインドセットでこの問題にアプローチする際に、大きな課題に直面することになります。歴史的に見て、未来を理解し、予測するために、企業が分析を実現するための主要な材料は構造化データでした。自然言語処理(NLP)を活用することで、企業は通話の音声やチャットメッセージのフリーテキストのように、顧客によって生成される様々な非構造化データを分析することができます。
自然言語処理(NLP)とは、コンピューターが人間の言語を理解、解釈、生成できるようにする一連のテクノロジーを指します。保険業界においては、特にカスタマーサービス、クレーム(申請)処理、補償において、大量の記述あるいは発話された言語の理解、処理を必要とするタスクの自動化にNLPを活用することができます。
現在では、顧客は製品のカスタマイゼーションや価値に関して様々な期待値を持っています。彼らは、年に一度更新されるようなものよりも、日常的な生活に組み込まれている保険を好みます。今ではシームレスな顧客体験が望まれており、TalkDeskによると、顧客の58%はカスタマーサービスに対する期待値は一年前よりも高くなっていると述べています。Bain & Companyのレポートによれば、14カ国の28,765人の利用者の59%は、保険会社に健康的な生活に対する褒賞を欲しいと言っています。
保険提供者の観点では、顧客の需要について行くことは大変なことです。Forresterは、サポートチームの53%においてパンデミックの開始以来、サポート問い合わせの増加を目撃しています。保険コンタクトセンターへのプレッシャーを削減するために、デジタルかつセルフサービス体験の提供が多くの場所で行われるようになっています。
保険会社は、クレームの状態のチェック、クレームの報告、保険のカバー範囲の理解のような一般的な保険のトピックに関する顧客問い合わせに対応するために、長年チャットボットやIVRを活用してきています。しかし、あまりに大きい複雑性やオーバーヘッドでカスタマーサービスのエージェントを圧倒することなしに、IVRが優れたユーザー体験を提供するようにするのは大変なことです。Oliver Wymanによると、理想的とは言えない顧客体験につながるペインポイントの多くは以下のようなものであるとのことです:
- スクリーニング: カスタマーチャットボットは多くの場合、より複雑な顧客の要求に苦戦します。これらのチャットボットの理解能力は限定的であり、顧客の電話の背景にある理由を理解することが困難です。大規模言語モデル(LLM)は、この領域において従来の自然言語処理(NLP)と比較して優れた能力を示しました。
- ルーティング: チャットボットは顧客のリクエストの本質を完全に理解できないことがあるため、顧客のルーティングが限定的であり、顧客は人にルーティングされ、多くの場合、再度待たされることになります。
- 解決: カスタマーサービスのエージェントには、問い合わせをクイックに解決するための基本的なツールが欠けています。チャットボットは、顧客の要件を要約し、カバー範囲を検証するための保険ドキュメントを収集したり、エージェントに適切な解決策の一覧を提供することができないかもしれません。結果として、エージェントは顧客に電話の理由を繰り返すようにお願いすることになり、顧客のポリシーや適切な詳細情報を収集することでさらなる遅延をもたらし、言うまでもないことですがカスタマーサービス体験の劣化に繋がります。
保険会社は顧客体験を改善するために、チャットボットの理解能力やルーティング能力を高めるために、LLMのような最先端のテクノロジーを活用することを検討すべきです。顧客情報や適切なリソースにクイックにアクセスできる包括的なツールをエージェントに提供することで、解決プロセスの円滑化の助けとなります。
優れた顧客体験やケアを提供しつつも、自身のカスタマーサービスのスタッフをスケール、トレーニングする際の課題に対応するためのベストな戦略の定義はうんざりするものかもしれません。このコインの両面のバランスを適切に取るにはどうしたらいいのでしょうか?そして、さらに重要なことですが、どこからスタートしたらいいのでしょうか?
カスタマーサービスにNLPを適用することによる潜在的な成果
全体的なデジタルトランスフォーメーション戦略への投資は、保険会社がシームレスに自分たちのオペレーションをスケールしつつも、予算や人材をオペレーショナルなプロセスから実際の製品、価値創生にシフトする助けとなります。カスタマーサービスの文脈では、そのような戦略を立案する際に鍵となる検討事項の一つは、コールデフレクション(問い合わせの別チャネルへの転送)です。一般的な顧客のペインポイントを理解し、セルフサービス
チャネルでそれらを支援することで、保険会社は、より簡単にスケールしつつも、より迅速でより適切な顧客体験を提供することができます。
保険ドメインのカスタマーサービスにデジタルトランスフォーメーションを適用するには、顧客がなぜ連絡をとってきているのかを理解する必要があります。例えば、我々は以下のようなことを知りたいと考えるかもしれません:
- 顧客の電話の理由のトップ10は?
- 何人の顧客が自動車の保険の支援で電話しているのか、あるいは生命保険や健康保険のような別のタイプの製品についてか?
- 月毎、あるいは年ごとにこれらの分布はどのように変化しているのか?
これらの洞察によって、カスタマーサービスやマーケティングや使いやすさのような他の領域に対する適切な戦略を立案することができるようになります。さらに、同じお客様から数多くのコンタクトが繰り返し発生するような、潜在的に問題となっている製品やトピックがどれであるのかを分析することができます。最後に、我々のカスタマーサービスチームがお客様の対応をするために、適切に準備ができているのかどうかを調査する必要があります。
この種の分析の実行には、企業は生のテキストを適切に解釈された文(分類されたテキスト)に変換し、構造化されたデータに頼る必要があります。自然言語処理の文脈では、BERT、GPT、ChatGPTのようなtransformerモデルによって、これまでに予想もできなかった規模でこのタイプのデータから、価値のある構造化された洞察を抽出することが可能となりました。これらのモデルによって、特定の顧客の意図に基づいて顧客の発言を容易に分類し、顧客の感情を計測できるようになります。
実装の課題とモチベーション
企業が顧客を理解すると、データとAI成熟度曲線の右側に移動することができます。自然言語処理(NLP)とTransformerモデルによって、エンゲージメントのためのチャットボットの活用や、過去の履歴に基づいて顧客の意図や次のやり取りの予測のようなパーソナライゼーションなど顧客体験の自動化を支援することができます。NLPやTransformerのポテンシャルに関わらず、多くの企業における導入の全体像は、まだ多くの未到達の機会があることを示しています。McKinseyによると、2022年末時点では企業の11%のみが、自身のAI製品の一部にTransformerモデルを導入する計画があるとのことです。
ソリューション
保険会社のコールセンター分析のためのNLPとTransformerモデルの作成、メンテナンスに関する技術的なベストプラクティスと再利用可能な機能をセットにするように設計された新たなソリューションアクセラレータを発表できることを嬉しく思っています。このソリューションアクセラレータは、企業が機械学習ソリューションを開発、デプロイし始められるようにするための一連のアーティファクト(データ、ノートブック、コード、ビジュアライゼーション)となっています。以下のセクションでは、このソリューションアクセラレーターのそれぞれのコンポーネントを見ていきます。
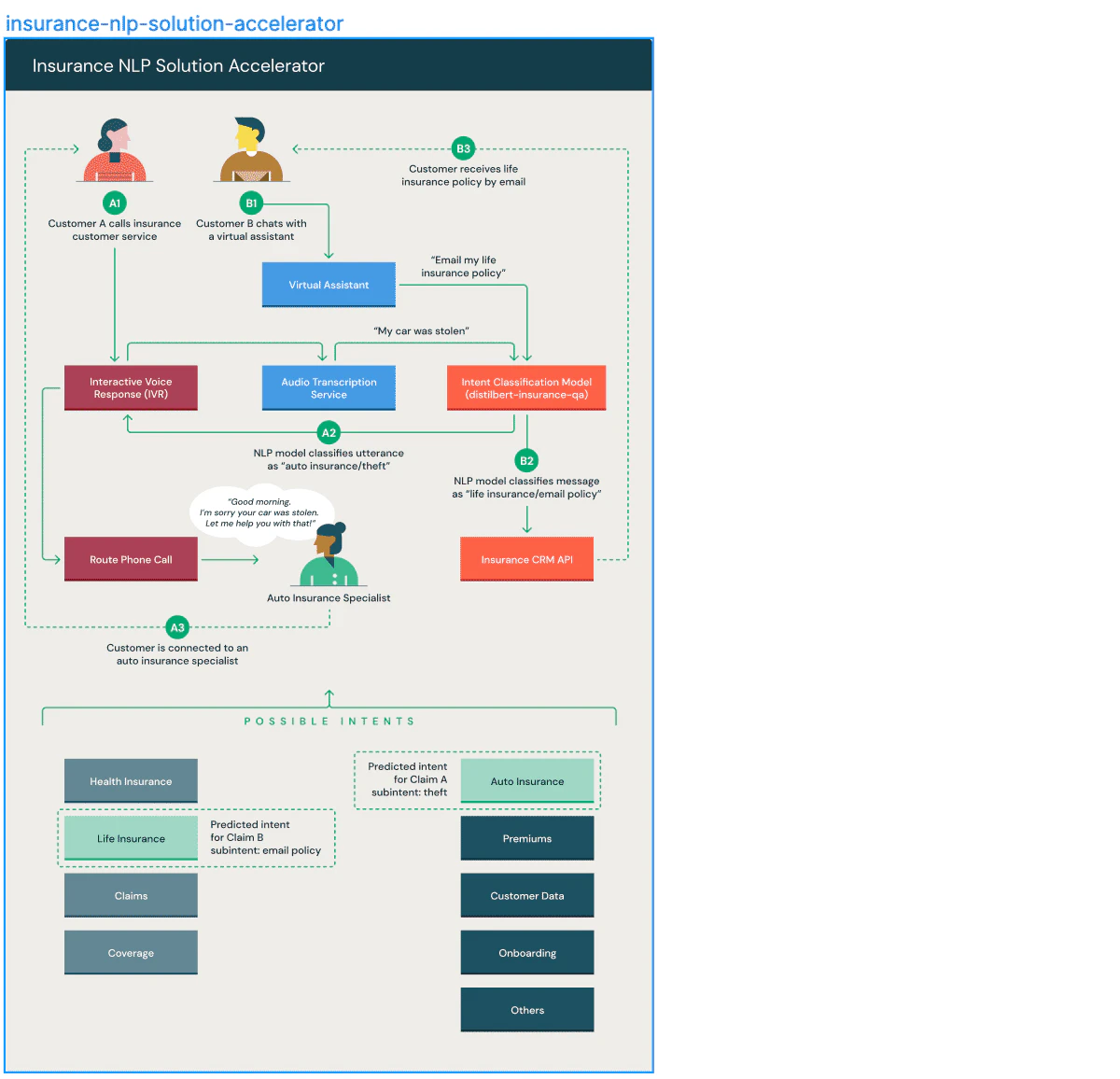
このソリューションアクセラレータの目的は2つあります:
- Interactive Voice Response (IVR)のストリームや顧客とサービスエージェント間の初期のやり取りから得られる大規模テキストデータに基づいて顧客の意図を検出
- 顧客からカスタマーサービスチャットボットへの最初の文をリアルタイムで分類
まとめ
まとめると、NLP、Transoformer、大規模言語モデル(LLM)の能力は進化し続けます。しかし、完璧なデータを所有している保険会社は存在しないと言うことに注意することが重要です。インフレーション、サプライチェーンの崩壊、損失トレンドの進展、災害における気象変更のインパクト、労働力の変化、補償ルールやカバー範囲外等の評価条件の更新のようなマクロ経済環境の最近の変化は、保険会社のビジネス構成を劇的に変化させました。このため、過去のデータでは未来のシナリオを効果的に汎化できない場合があいrます。
保険会社には二つの選択肢があります: オペレーショナルシステム(ポリシー、エクスポージャー、プレミアム。カバー範囲や申請内容など)から得られる自分たちの構造化データを補完するために、外部あるいはサードパーティのデータを取得することができます。あるいは、音声通話、画像、テキスト、動画を含む内部的な非構造化データで内部的な構造データを強化することができます。
サマリー
このソリューションアクセラレータによる我々のゴールは、顧客の非構造化データとNLP、Transformer、レイクハウスプラットフォームを活用することで、デジタル化の能力をどれだけ簡単に達成できるのかを示すことです。
Interactive Voice Response (IVR)のストリームやバーチャルエージェントから得られるテキスト情報に基づいて、顧客の意図を検知するための機械学習ソリューションを開発、デプロイし始めるには、Insurance NLP Solution Acceleratorをダウンロードしてください。