Get started with Databricks as a data scientist | Databricks on AWS [2022/1/22時点]の翻訳です。
Databricksクイックスタートガイドのコンテンツです。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
このチュートリアルでは、Databricks Data Science & Engineeringワークスペースをご案内します。クラスターとノートブックを作成し、テーブルに対してクエリーを実行し、クエリーの結果を表示します。
ティップス
本書を補完する目的で、DatabricksのData Science & Engineeringランディングページから利用できる5分のハンズオンを提供するクイックスタートチュートリアルノートブックもチェックしてください。Databricksにログインし、クイックスタートチュートリアルをクリックして下さい。チュートリアルが見つからない場合、サイドバーのペルソナスイッチャーからData Science & Engineeringを選択してください。
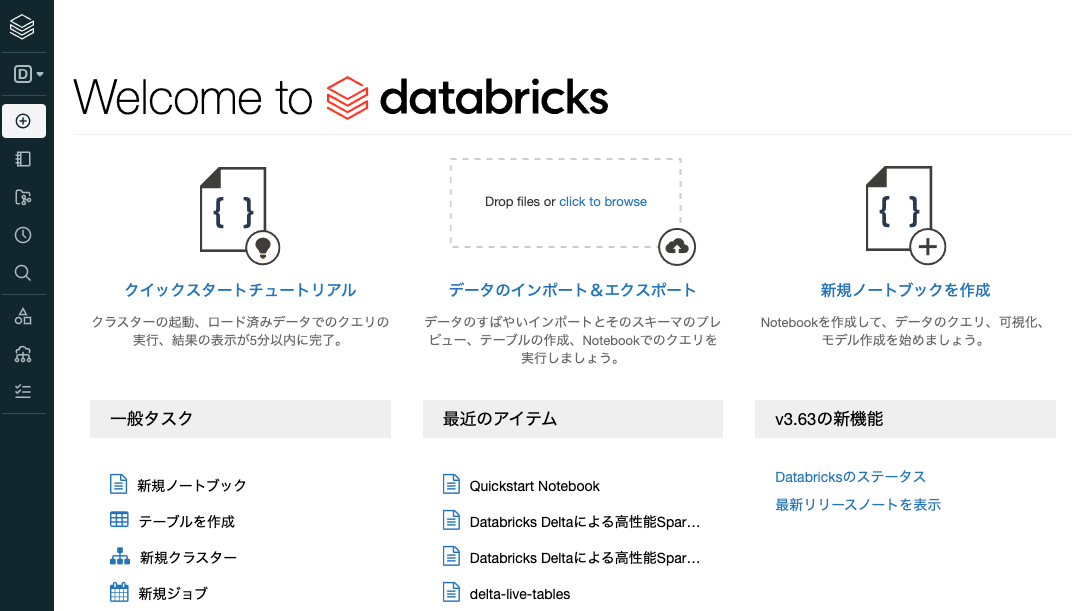
ノートブックの日本語訳です。
要件
Databricksにログインすると、Data Science & Engineeringワークスペースに移動します。Databricksフリートライアルへのサインアップを参照ください。
ステップ1: DatabricksのData Science & Engineering UIに慣れる
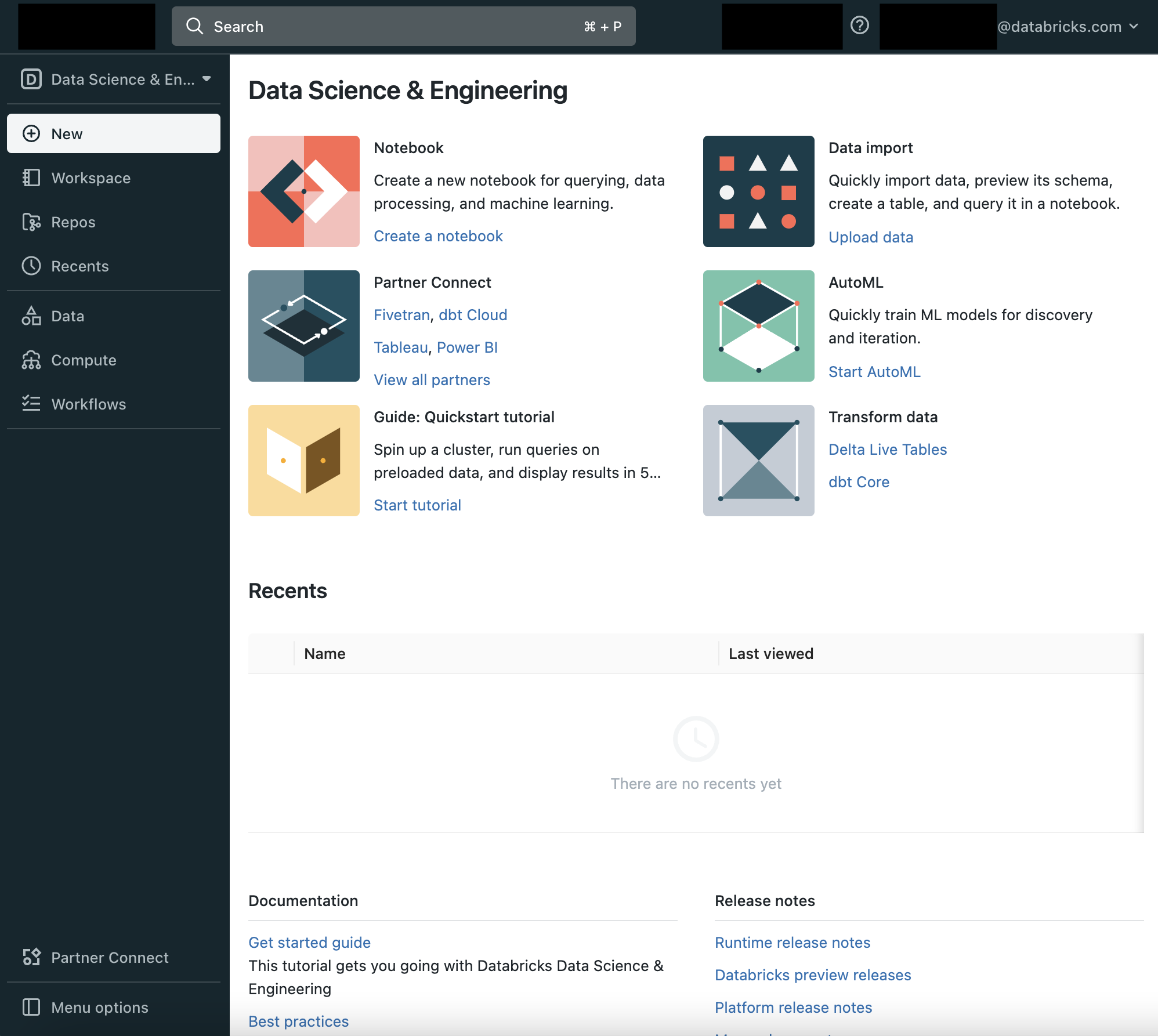
画面左のサイドバーとランディングページのCommon Tasksリストから、DatabricksのData Science & Engineeringの主要エンティティ: ワークスペース、クラスター、テーブル、ノートブック、ジョブ、ライブラリにアクセスすることができます。ワークスペースはノートブック、ライブラリ、インポートしたデータのようなDatabricksアセットを格納する特殊なルートフォルダーです。
サイドバーの利用
左のサイドバーからDatabricksの全てのアセットにアクセスできます。サイドバーのコンテンツは選択するペルソナ(Data Science & Engineering、Machine Learning、SQL)によって決まります。
-
デフォルトではサイドバーは畳み込まれた状態で表示され、アイコンのみが表示されます。サイドバー上にカーソルを移動すると全体を表示することができます。
-
ペルソナを変更するには、Databricksロゴ
 の直下にあるアイコンからペルソナを選択します。
の直下にあるアイコンからペルソナを選択します。

-
次回ログイン時に表示されるペルソナを固定するには、ペルソナの隣にあるをクリックします。再度クリックするとピンを削除することができます。
-
サイドバーの一番下にあるMenu optionsで、サイドバーの表示モードを切り替えることができます。Auto(デフォルト)、Expand(展開)、Collapse(畳み込み)から選択できます。
-
機械学習に関連するページを開く際には、ペルソナは自動的にMachine Learningに切り替わります。
ヘルプの利用
ヘルプにアクセスするためには、右上のアイコン![]() をクリックします。
をクリックします。
ステップ2: クラスターを作成する
クラスターはDatabricksの計算リソースの集合体です。クラスターを作成するには:
-
サイドバーの
 Computeボタンをクリックします。
Computeボタンをクリックします。 -
クラスターページで、Create Clusterをクリックします。

-
クラスター作成ページで、クラスター名Quickstartを指定して、Databricksランタイムバージョンドロップダウンから**7.3 LTS (Scala 2.12, Spark 3.0.1)**を選択します。
-
Create Clusterをクリックします。
ステップ3: ノートブックを作成する
ノートブックはApache Sparkクラスターでの処理を実行するセルの集合体です。ワークスペースでノートブックを作成するには:
-
サイドバーで
 Workspaceボタンをクリックします。
Workspaceボタンをクリックします。 -
ワークスペースのフォルダーで
 をクリックし、Create > Notebookを選択します。
をクリックし、Create > Notebookを選択します。

-
ノートブック作成ダイアログで、名前を入力し、言語ドロップダウンではSQLを選択します。これによりノートブックのデフォルト言語を決定します。
-
Createをクリックします。先頭のセルが空白のノートブックが開きます。
ステップ4: テーブルを作成する
Databricksクラスターにインストールされた分散ファイルシステムDatabricks File System (DBFS)にマウントされたデータセットコレクションであるDatabricksデータセットのサンプルCSVファイルからテーブルを作成します。テーブルを作成するには2つの選択肢があります。
オプション1: CSVデータからSparkテーブルを作成する
標準的なパフォーマンスで十分で、すぐにテーブルを作りたいのであればこちらのオプションとなります。以下のスニペットをノートブックセルに貼り付けます。
DROP TABLE IF EXISTS diamonds;
CREATE TABLE diamonds USING CSV OPTIONS (path "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header "true")
オプション2: CSVデータをDelta Lake形式で書き込み、Deltaテーブルを作成する
Delta Lakeは、高速な読み込み、その他のメリットを提供する強力なトランザクショナルストレージレイヤーです。Delta LakeフォーマットはParquetファイルとトランザクションログから構成されます。将来的なパフォーマンスを見据えた場合に最適な選択肢となります。
-
CSVデータをデータフレームに読み込み、Delta Lake形式で書き込みを行います。このコマンドでは、Pythonの言語マジックコマンドを使用し、ノートブックのデフォルト言語(SQL)以外の言語の処理を組み込みます。以下のコードスニペットをノートブックセルに貼り付けます。
Python
%python
diamonds = spark.read.csv("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header="true", inferSchema="true")
diamonds.write.format("delta").save("/mnt/delta/diamonds")
1. 格納場所にDeltaテーブルを作成します。以下のコードスニペットをノートブックセルに貼り付けます。
```sql:SQL
DROP TABLE IF EXISTS diamonds;
CREATE TABLE diamonds USING DELTA LOCATION '/mnt/delta/diamonds/'
SHIFT + ENTERを押してセルを実行します。ノートブックは自動的にステップ2で作成したクラスターにアタッチされ、セル内のコマンドが実行されます。
ステップ5: テーブルにクエリーを実行する
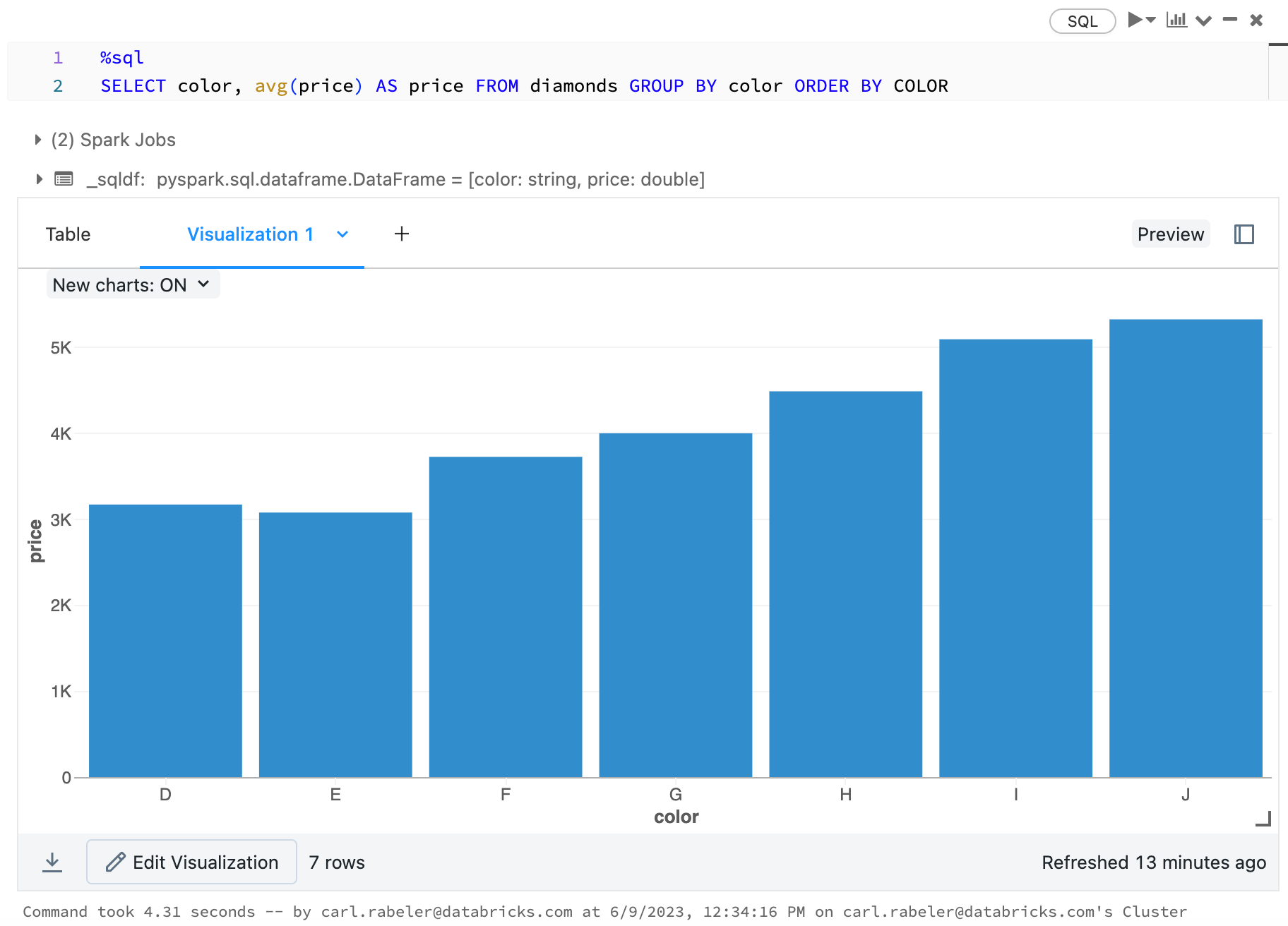
色ごとのダイヤモンドの平均価格を計算するSQL分を実行します。
-
セルの下にある
 をクリックして、ノートブックにセルを追加します。
をクリックして、ノートブックにセルを追加します。

-
以下のスニペットをセルに貼り付けます。
SQL
SELECT color, avg(price) AS price FROM diamonds GROUP BY color ORDER BY COLOR
**SHIFT + ENTER**を押してセルを実行します。ダイヤモンドの色と平均価格が表示されます。

# ステップ6: データを表示
色ごとの平均ダイヤモンド価格のグラフを表示します。
1. バーチャートアイコンをクリックします。
1. **Plot Options**をクリックします。
- **color**をKeysボックスにドラッグします。
- **price**をValuesボックスにドラッグします。
- Aggregationドロップダウンで**AVG**を選択します。

1. **Apply**をクリックしバーチャートを表示します。
# 次のステップ
DatabricksのData Science & Engineeringワークスペースの主要ツールを学ぶには以下をご覧下さい。
- [Introduction to Databricks](https://docs.databricks.com/getting-started/introduction/index.html)
- [Navigate the workspace](https://docs.databricks.com/workspace/index.html)
- [Databricksのノートブック](https://qiita.com/taka_yayoi/items/24a897cf40bba6d9e305)、[Databricksにおけるデータの可視化](https://qiita.com/taka_yayoi/items/36a307e79e9433121c38)
- [DatabricksにおけるPythonライブラリ管理](https://qiita.com/taka_yayoi/items/d3a46efdc1ad01a581d0)
- [Clusters](https://docs.databricks.com/clusters/index.html)、[Databricksにおけるジョブ管理](https://qiita.com/taka_yayoi/items/b3275a1983c51a8bbe1a)
- [Databricksにおけるデータのインポート、読み込み、変更](https://qiita.com/taka_yayoi/items/4fa98b343a91b8eaa480)
- [Databricksにおけるデータベースおよびテーブル](https://qiita.com/taka_yayoi/items/e7f6982dfbee7fc84894)
- [Developer tools and guidance](https://docs.databricks.com/dev-tools/index.html)
- [Databricks integrations](https://docs.databricks.com/integrations/index.html)
以下のクイックスタートもご覧ください。
- [データエンジニアとしてDatabricksを使い始める](https://qiita.com/taka_yayoi/items/a18adea4959b885783c6)
- [Get started with Databricks as a data analyst](https://docs.databricks.com/getting-started/sql-quick-start.html)
- [Get started with Databricks as a machine learning engineer](https://docs.databricks.com/getting-started/ml-quick-start.html)
- [Get started as a Databricks administrator](https://docs.databricks.com/getting-started/admin-get-started.html)
### Databricks 無料トライアル
[Databricks 無料トライアル](https://databricks.com/jp/try-databricks)