こちらで紹介されているノートブックをウォークスルーした内容です。こちらで紹介しているSpark NLPは無料で利用できます。日本語にも対応しています。
クラスターの作成
Spark NLPをクラスターにインストールする様に設定します。ここではDatabricksランタイム11.0MLを使用します。
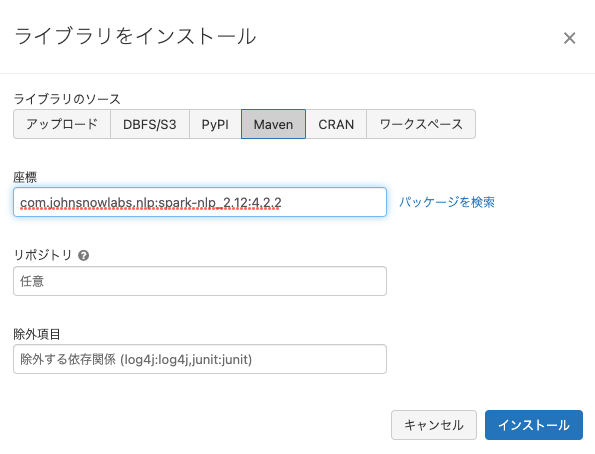
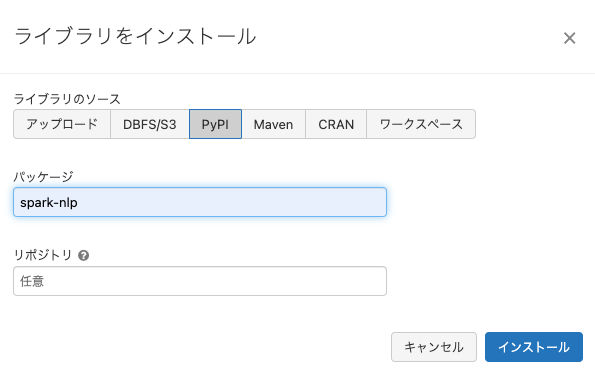
以下の様にPyPIとMavenからライブラリをインストールします。Mavenからインストールする際に指定するコーディネートはこちらで確認します。Spark NLP 4.2.2はDatabricksランタイム11.0MLをサポートしています。

そして、こちらにcom.johnsnowlabs.nlp:spark-nlp_2.12:4.2.2をインストールする様に指示があります。
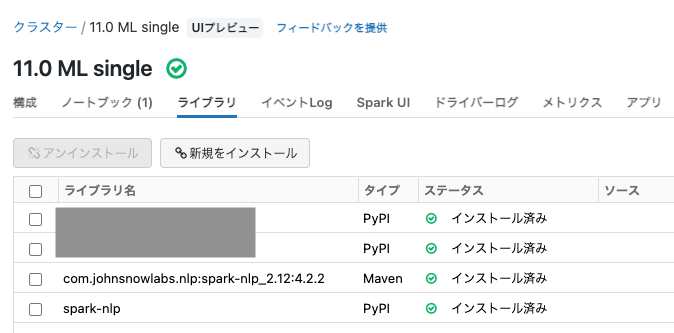
以下の様にクラスターが起動し、ライブラリがインストールされればクラスターの準備は完了です。
ノートブックの実行
ノートブックの翻訳版はこちらに置いてあります。
サンプルのトレーニング、評価データのロード
!wget -q https://raw.githubusercontent.com/JohnSnowLabs/spark-nlp/master/src/test/resources/conll2003/eng.train
!wget -q https://raw.githubusercontent.com/JohnSnowLabs/spark-nlp/master/src/test/resources/conll2003/eng.testa
Python
from sparknlp.training import CoNLL
training_data = CoNLL().readDataset(spark, 'file:/databricks/driver/eng.train')
test_data = CoNLL().readDataset(spark, 'file:/databricks/driver/eng.testa')
トレーニングデータにパイプラインをフィット
Python
import sparknlp
from sparknlp.base import *
from sparknlp.annotator import *
import mlflow
mlflow_run = mlflow.start_run()
max_epochs=1
lr=0.003
batch_size=32
random_seed=0
verbose=1
validation_split= 0.2
evaluation_log_extended= True
enable_output_logs= True
include_confidence= True
output_logs_path="dbfs:/ner_logs"
dbutils.fs.mkdirs(output_logs_path)
nerTagger = NerDLApproach()\
.setInputCols(["sentence", "token", "embeddings"])\
.setLabelColumn("label")\
.setOutputCol("ner")\
.setMaxEpochs(max_epochs)\
.setLr(lr)\
.setBatchSize(batch_size)\
.setRandomSeed(random_seed)\
.setVerbose(verbose)\
.setValidationSplit(validation_split)\
.setEvaluationLogExtended(evaluation_log_extended)\
.setEnableOutputLogs(enable_output_logs)\
.setIncludeConfidence(include_confidence)\
.setOutputLogsPath(output_logs_path)
# MLflowにモデルトレーニングパラメーターを記録
mlflow.log_params({
"max_epochs": max_epochs,
"lr": lr,
"batch_size": batch_size,
"random_seed": random_seed,
"verbose": verbose,
"validation_split": validation_split,
"evaluation_log_extended": evaluation_log_extended,
"enable_output_logs": enable_output_logs,
"include_confidence": include_confidence,
"output_logs_path": output_logs_path
})
# トレーニングデータ、評価用データはすでにトークナイズされているので、エンべディングモデルを直接適用し、
# エンベンディングに固有エンティティ識別器をフィットします
glove_embeddings = WordEmbeddingsModel.pretrained('glove_100d')\
.setInputCols(["document", "token"])\
.setOutputCol("embeddings")
ner_pipeline = Pipeline(stages=[
glove_embeddings,
nerTagger
])
ner_model = ner_pipeline.fit(training_data)
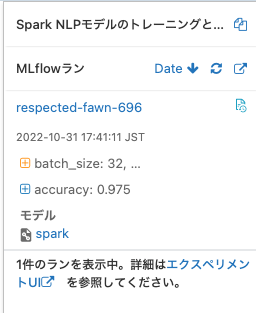
MLflowにモデルが記録されます。
テストデータによる評価
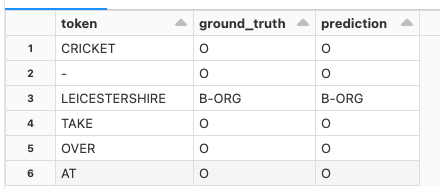
トークン、正解データ、予測
Python
import pyspark.sql.functions as F
display(predictions.select(F.col('token.result').alias("tokens"),
F.col('label.result').alias("ground_truth"),
F.col('ner.result').alias("predictions")).limit(3))

Python
# 評価のために行あたり1トークンになる様にデータを再フォーマット
predictions_pandas = predictions.select(F.explode(F.arrays_zip(predictions.token.result,
predictions.label.result,
predictions.ner.result)).alias("cols")) \
.select(F.expr("cols['0']").alias("token"),
F.expr("cols['1']").alias("ground_truth"),
F.expr("cols['2']").alias("prediction")).toPandas()
最初の20トークンとラベル
Python
display(predictions_pandas.head(20))
Python
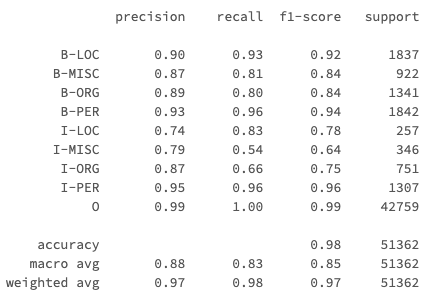
from sklearn.metrics import classification_report
# 分類レポートの生成
report = classification_report(predictions_pandas['ground_truth'], predictions_pandas['prediction'], output_dict=True)
# 直接MLflowに精度を記録
mlflow.log_metric("accuracy", report["accuracy"])
# MLflowにアーティファクトとしてトークンタイプごとの完全な分類を記録
mlflow.log_dict(report, "classification_report.yaml")
# ノートブックで参照するためにレポートを出力
print (classification_report(predictions_pandas['ground_truth'], predictions_pandas['prediction']))
テキストの予測パイプラインの構築および記録
Python
document = DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")
sentence = SentenceDetector()\
.setInputCols(['document'])\
.setOutputCol('sentence')
token = Tokenizer()\
.setInputCols(['sentence'])\
.setOutputCol('token')
# パイプラインからモデルを取得
loaded_ner_model = ner_model.stages[1]
converter = NerConverter()\
.setInputCols(["document", "token", "ner"])\
.setOutputCol("ner_span")
ner_prediction_pipeline = Pipeline(
stages = [
document,
sentence,
token,
glove_embeddings,
loaded_ner_model,
converter])
Python
# 空のデータフレームにフィットさせることで、モデルを再トレーニングすることなしにパイプラインモデルを構築することができます
empty_data = spark.createDataFrame([['']]).toDF("text")
prediction_model = ner_prediction_pipeline.fit(empty_data)
Python
# Databricksランタイム11.2や11.2MLでは、モデルロギングはDatabricks MLflowユーティリティを用いて記録されます。
# Databrikcsランタイム11.2のDBFS向けDatabricks MLflowユーティリティは、
# Spark NLPがモデルのシリアライズ化に使用するすべてのファイルシステムコールをサポートしていません。
# 以下のコマンドではMLflowユーティリティの使用を無効化し、標準のDBFSサポートを使用する様にしています。
import os
if os.environ["DATABRICKS_RUNTIME_VERSION"].startswith('11.'):
os.environ["DISABLE_MLFLOWDBFS"] = "True"
Python
## モデルをMLflowに記録し、モデルURIへのリファレンスを構築します
model_name = "NerPipelineModel"
mlflow.spark.log_model(prediction_model, model_name)
mlflow.end_run()
mlflow_model_uri = "runs:/{}/{}".format(mlflow_run.info.run_id, model_name)
display(mlflow_model_uri)

モデルをテキストに適用
Python
# サンプルテキストの作成
text = "From the corner of the divan of Persian saddle-bags on which he was lying, smoking, as was his custom, innumerable cigarettes, Lord Henry Wotton could just catch the gleam of the honey-sweet and honey-coloured blossoms of a laburnum, whose tremulous branches seemed hardly able to bear the burden of a beauty so flamelike as theirs; and now and then the fantastic shadows of birds in flight flitted across the long tussore-silk curtains that were stretched in front of the huge window, producing a kind of momentary Japanese effect, and making him think of those pallid, jade-faced painters of Tokyo who, through the medium of an art that is necessarily immobile, seek to convey the sense of swiftness and motion. The sullen murmur of the bees shouldering their way through the long unmown grass, or circling with monotonous insistence round the dusty gilt horns of the straggling woodbine, seemed to make the stillness more oppressive. The dim roar of London was like the bourdon note of a distant organ."
sample_data = spark.createDataFrame([[text]]).toDF("text")
# モデルをロードして適用
mlflow_model = mlflow.spark.load_model(mlflow_model_uri)
predictions = mlflow_model.transform(sample_data)
生の予測結果
Python
display(predictions)

抽出されたエンティティ
Python
display(predictions.select(F.explode(F.arrays_zip(predictions.ner_span.result,predictions.ner_span.metadata)).alias("entities"))
.select(F.expr("entities['0']").alias("chunk"),
F.expr("entities['1'].entity").alias("entity")))
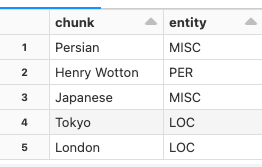
TokyoやLondonがLOC(位置)として抽出されていることがわかります。