Databricksでは前からREST API経由で機械学習モデルを呼び出すことができるエンドポイントをサポートしていましたが、最近ではタイトルにあるサーバレスリアルタイム推論エンドポイント(serverless real time inference endpoint)をサポートする様になりました(パブリックプレビュー中です)。
サーバレスリアルタイム推論エンドポイントは、プロダクション用途を意図しており、秒間3000クエリー(QPS)までをサポートすることができます。サーバレスリアルタイム推論エンドポイントは、自動でスケールアップ・ダウンするので、エンドポイントはスコアリングのリクエストのボリュームに応じて自動で調整することを意味します。リクエストがない際にはノード数を0にまでスケールダウンすることも可能です。
サーバレスリアルタイム推論エンドポイントの起動
ここでは、ワイン品質予測モデルをエンドポイントにデプロイします。
-
サービングタブをクリックします。
-
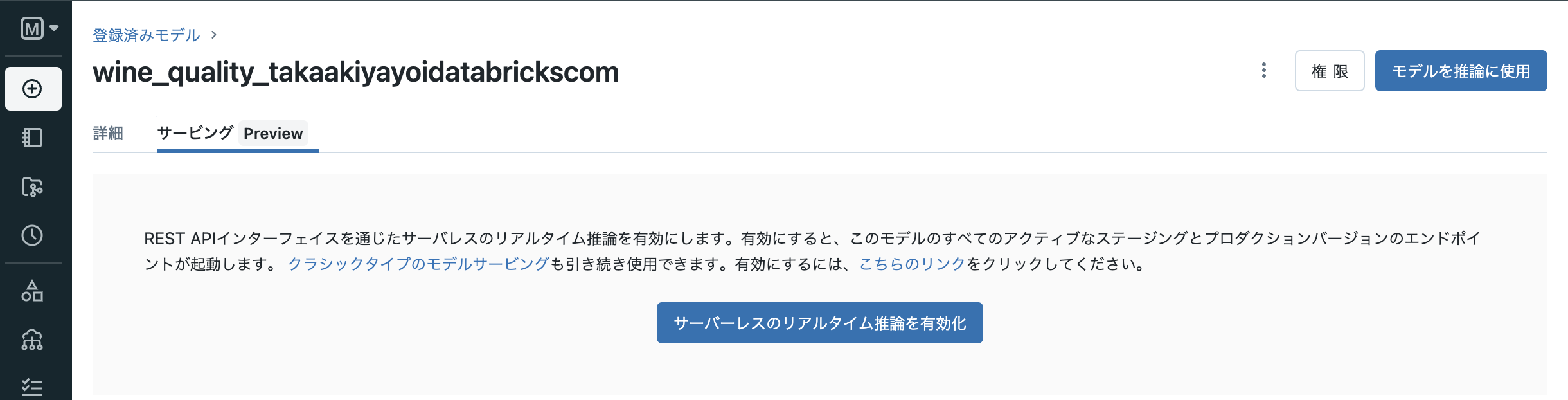
有効化ボタンをクリックします。従来のエンドポイントを使うには
クラシックタイプのモデルサービングも引き続き使用できます。有効にするには、こちらのリンクをクリックしてください。のリンクをクリックします。
-
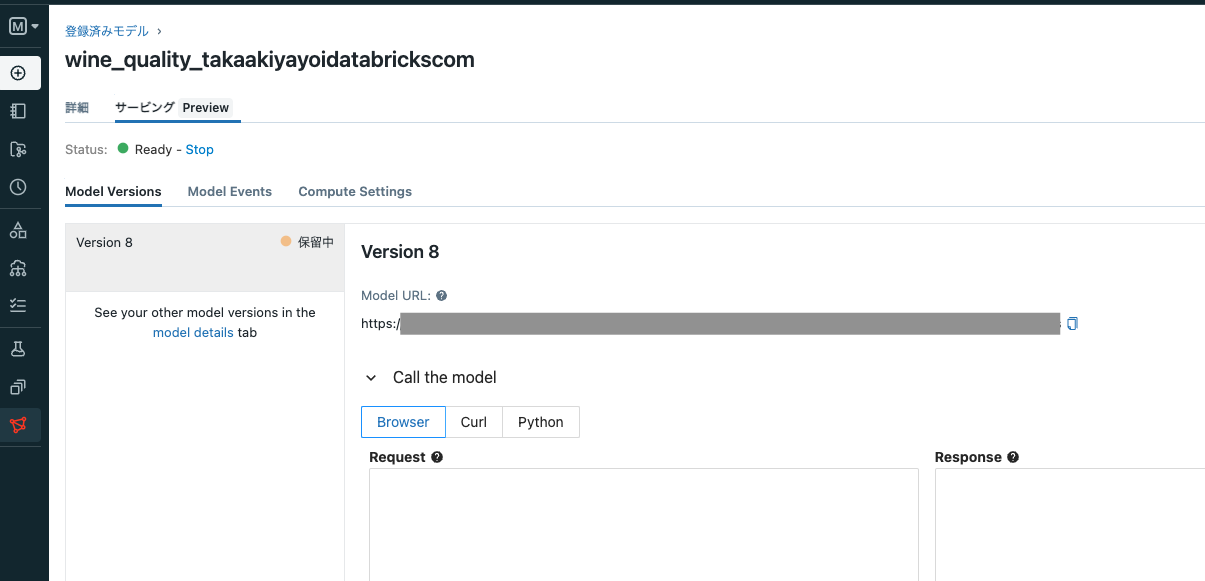
少し待つとエンドポイントが起動し、モデルのデプロイがスタートします。
-
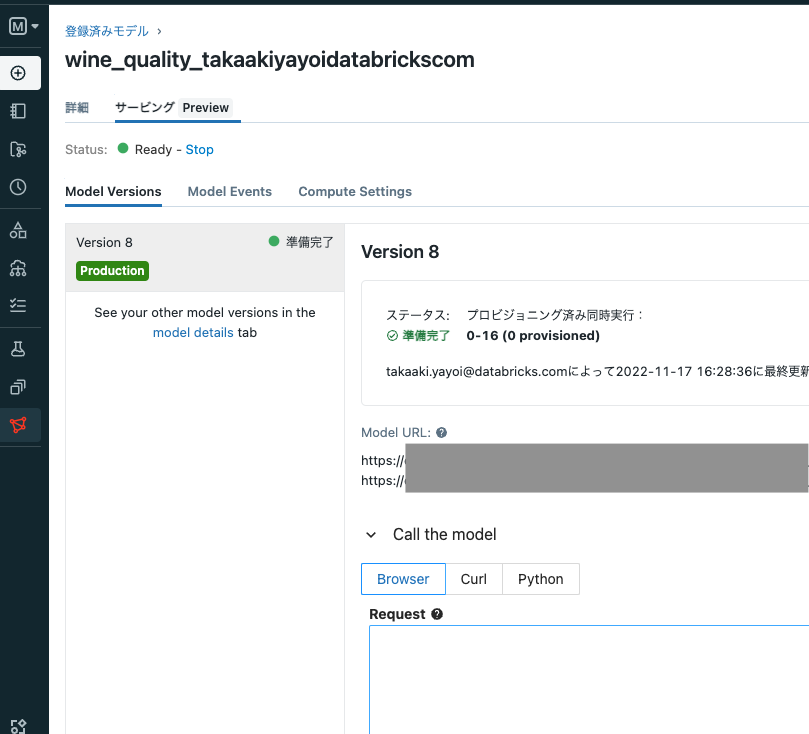
モデルが準備完了となれば、エンドポイントからモデルを呼び出すことができます。
-
なお、上のCompute Settingでエンドポイントの計算リソースを設定することができます。ゼロにスケーリングをチェックすると、エンドポイントが使用されていない場合はノード数がゼロにまでスケールダウンします。
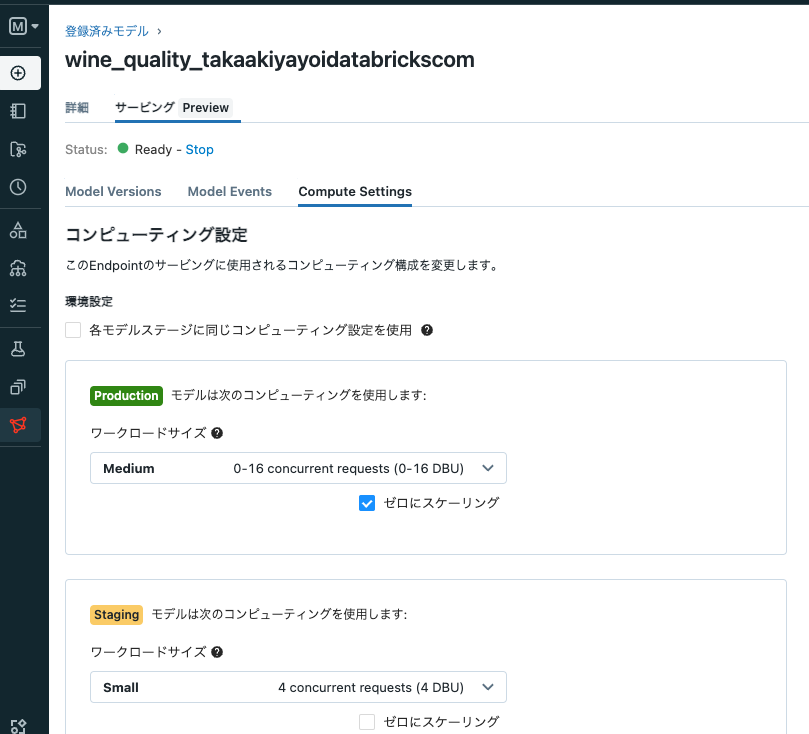
エンドポイントの呼び出し
以下の様な関数を準備してエンドポイントにアクセスできる様にします。ここで注意しなくてはならないのは、関数process_inputです。MLflow 2.0になってエンドポイントへのリクエストフォーマットが変更されています。旧来のMLflowを使う様に設定(Conda環境にMLflowのバージョンを指定)するか、フォーマットを変更する必要があります。この関数はMLflow 2.0にリクエストする際に必要なフォーマットにデータフレームを変換しています。
import os
import requests
import numpy as np
import pandas as pd
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def process_input(dataset):
if isinstance(dataset, pd.DataFrame):
return {"dataframe_split": dataset.to_dict(orient='split') }
elif isinstance(dataset, str):
return dataset
else:
return create_tf_serving_json(dataset)
def score_model(dataset):
#print(dataset)
url = 'https://<エンドポイントのURL>'
headers = {'Authorization': f'Bearer {os.environ.get("DATABRICKS_TOKEN")}'}
data_json = process_input(dataset)
print(data_json)
response = requests.request(method='POST', headers=headers, url=url, json=data_json)
if response.status_code != 200:
raise Exception(f'Request failed with status {response.status_code}, {response.text}')
return response.json()
-
https://<エンドポイントのURL>はお使いのモデルに割り振られるURLで置き換える必要があります。 -
os.environ["DATABRICKS_TOKEN"]には、以下の様なコードを用いてパーソナルアクセストークンを設定します。
import os
# 事前にCLIでシークレットにトークンを登録しておきます
token = dbutils.secrets.get("demo-token-takaaki.yayoi", "token")
os.environ["DATABRICKS_TOKEN"] = token
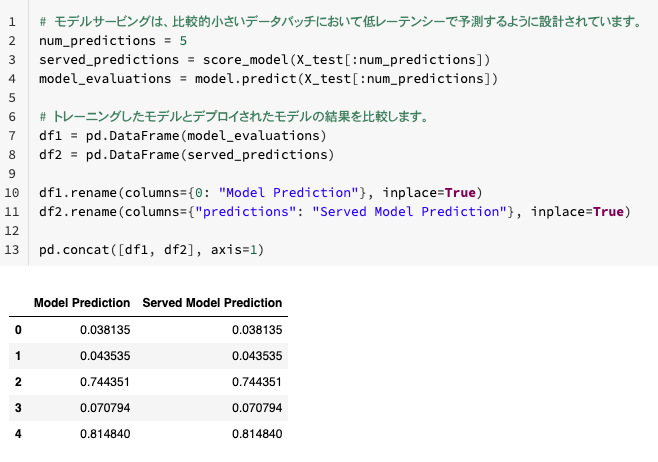
以下の様にデータを準備してエンドポイントを呼び出してスコアリングを行います。
# モデルサービングは、比較的小さいデータバッチにおいて低レーテンシーで予測するように設計されています。
num_predictions = 5
served_predictions = score_model(X_test[:num_predictions])
model_evaluations = model.predict(X_test[:num_predictions])
# トレーニングしたモデルとデプロイされたモデルの結果を比較します。
df1 = pd.DataFrame(model_evaluations)
df2 = pd.DataFrame(served_predictions)
df1.rename(columns={0: "Model Prediction"}, inplace=True)
df2.rename(columns={"predictions": "Served Model Prediction"}, inplace=True)
pd.concat([df1, df2], axis=1)
エンドポイントから結果が返されていることがわかります。
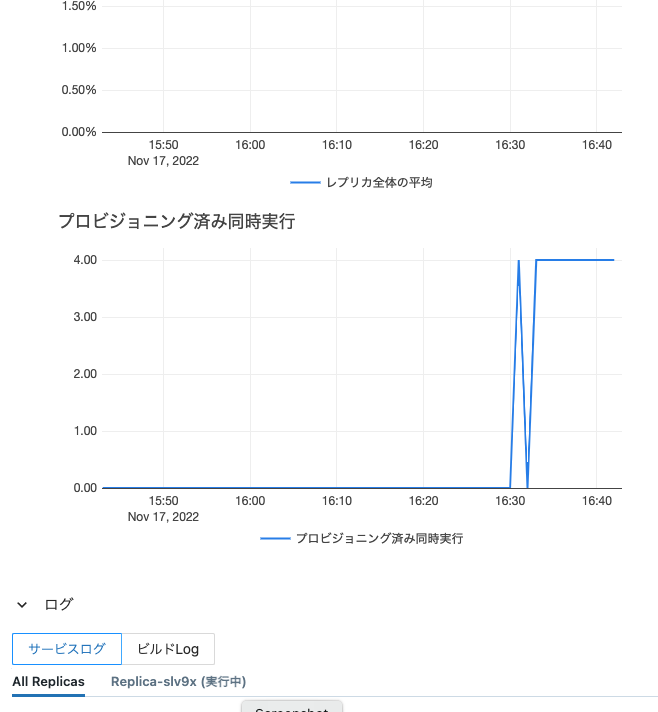
また、エンドポイントの画面にはモニタリングのためのメトリクスが表示されます。
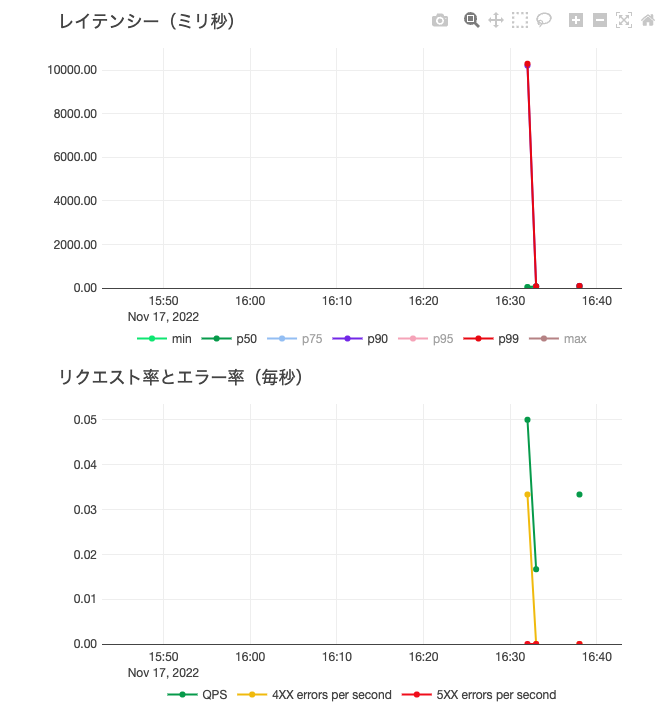
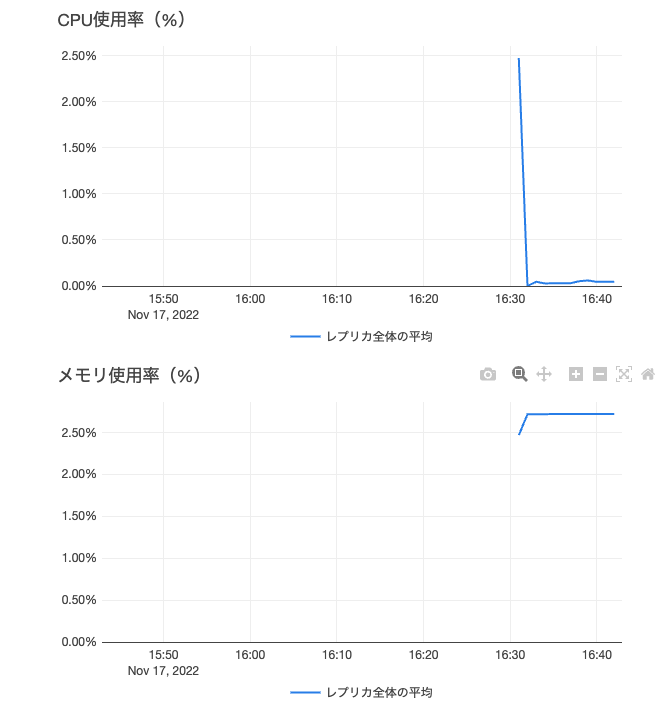
プロダクション用途でも活用できるサーバレスリアルタイム推論エンドポイント、ぜひ試してみてください!