以前こちらの記事を書いた際に、シングルノードでの分散チューニングしかできていませんでした。
from pyspark.ml.deepspeed.deepspeed_distributor import DeepspeedTorchDistributor
dist = DeepspeedTorchDistributor(
numGpus=NUM_GPUS_PER_WORKER,
#nnodes=NUM_WORKERS,
#localMode=False, # ワーカーにトレーニングを分散
localMode=True, # ドライバーノードでトレーニング
deepspeedConfig=deepspeed_config
)
マルチノードクラスターでは、以下のような設定になります。
from pyspark.ml.deepspeed.deepspeed_distributor import DeepspeedTorchDistributor
dist = DeepspeedTorchDistributor(
numGpus=NUM_GPUS_PER_WORKER,
nnodes=NUM_WORKERS,
localMode=False, # ワーカーにトレーニングを分散
deepspeedConfig=deepspeed_config
)
前回トライしていた際には、マルチノードにするとチューニング途中でncclのエラーに遭遇していました。それから、いろいろ試行錯誤していたところ動いたのでこちらにまとめます。Databricksランタイムのバージョンと同梱されているdeepspeedのバージョンの問題だったようです。DBR 14.1で動作確認しています。
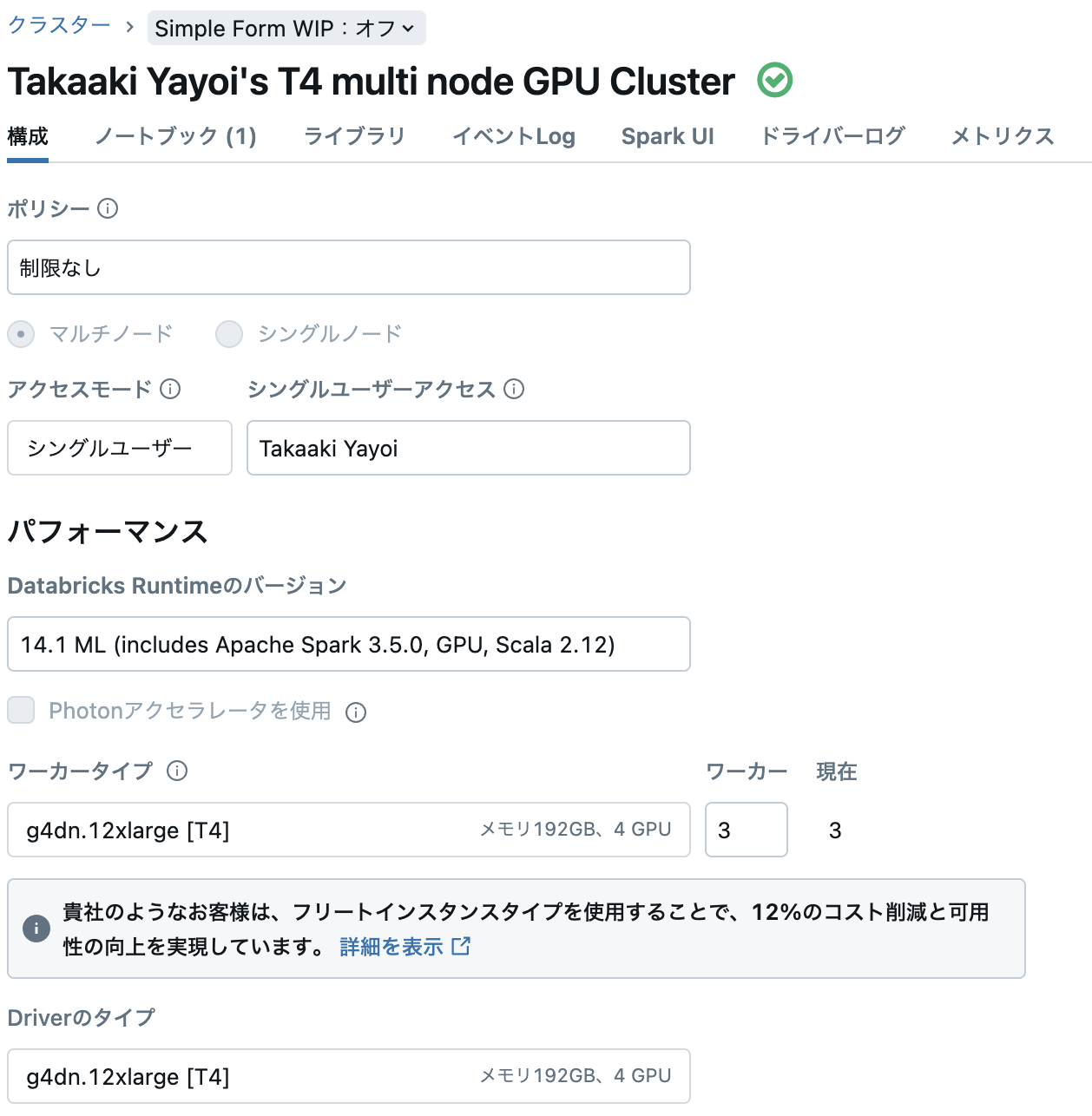
クラスターのスペック
- マルチノード: 3ワーカー
- ランタイム: ML 14.1 GPU
- インスタンスタイプ: g4dn.12xlarge [T4]
DeepSpeedディストリビューターによるLlama 2 7B Chatのファインチューニング
このノートブックでは、Apache SparkのDeepspeedTorchDistributorとHugging Faceのtransformersライブラリを用いて、Llama-2-7b-chat-hf modelのファインチューニングの例を提供します。
要件
このノートブックでは、以下を必要とします:
- GPU、マルチノードクラスター。現時点では、DeepSpeedはCPUでの実行をサポートしていません。
- Databricks Runtime 14.0 ML以降
- g4dn.12xlarge (4x T4) on AWS
必要なパッケージのインストール
MLR 14.0で実行する際、クラスターにdeepspeedをインストールする必要があります。
ここではMLR 14.1を使っていますが、deepspeedは0.10.0が同梱されており、これで動作を確認できました。
ncclのバージョンも確認しておきます。
import torch
print(torch.cuda.nccl.version())
(2, 14, 3)
(オプション) DeepSpeed設定の定義
こちらは前回と変わってません。
ディストリビューターにDeepSpeedの設定を指定する選択をすることもできます。指定しない場合、デフォルト設定が適用されます。
Pythonのディクショナリーあるいは、jsonの設定を含むファイルのパスを表現する文字列で設定を引き渡すことができます。
deepspeed_config = {
"fp16": {
"enabled": True
},
"bf16": {
"enabled": False
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"overlap_comm": True,
"contiguous_gradients": True,
"sub_group_size": 5e7,
"reduce_bucket_size": "auto",
"reduce_scatter": True,
"stage3_max_live_parameters" : 1e9,
"stage3_max_reuse_distance" : 1e9,
"stage3_prefetch_bucket_size" : 5e8,
"stage3_param_persistence_threshold" : 1e6,
"stage3_gather_16bit_weights_on_model_save": True,
"offload_optimizer": {
"device": "cpu",
"pin_memory": True
}
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": False
}
DeepSpeedディストリビューターの作成
ディストリビューターを作成する際、使用するノードの数、ノードあたりのGPUの数を指定することができます。
import torch
NUM_WORKERS = int(spark.conf.get("spark.databricks.clusterUsageTags.clusterWorkers", "1"))
def get_gpus_per_worker(_):
import torch
return torch.cuda.device_count()
NUM_GPUS_PER_WORKER = sc.parallelize(range(4), 4).map(get_gpus_per_worker).collect()[0]
print("NUM_WORKERS:", NUM_WORKERS)
print("NUM_GPUS_PER_WORKER:", NUM_GPUS_PER_WORKER)
NUM_WORKERS: 3
NUM_GPUS_PER_WORKER: 1
ワーカーノードでチューニングするように設定します。
from pyspark.ml.deepspeed.deepspeed_distributor import DeepspeedTorchDistributor
dist = DeepspeedTorchDistributor(
numGpus=NUM_GPUS_PER_WORKER,
nnodes=NUM_WORKERS,
localMode=False, # ワーカーにトレーニングを分散
#localMode=True, # ドライバーノードでトレーニング
deepspeedConfig=deepspeed_config
)
トレーニング関数の定義
こちらは前回と変わってません。
このサンプルでは、Llama2をファインチューニングするためにHuggingFaceのtransformersパッケージを使います。
from datasets import Dataset, load_dataset
import os
from transformers import AutoTokenizer
TOKENIZER_PATH = '/Volumes/users/takaaki_yayoi/llama2_models/Llama-2-7b-chat-hf'
MODEL_PATH = '/Volumes/users/takaaki_yayoi/llama2_models/Llama-2-7b-chat-hf'
#TOKENIZER_PATH = '/dbfs/llama2_models/Llama-2-7b-chat-hf'
#TOKENIZER_PATH = "meta-llama/Llama-2-7b-chat-hf"
#MODEL_PATH = "meta-llama/Llama-2-7b-chat-hf"
DEFAULT_TRAINING_DATASET = "databricks/databricks-dolly-15k"
INTRO_BLURB = "Below is an instruction that describes a task. Write a response that appropriately completes the request."
INSTRUCTION_KEY = "### Instruction:"
INPUT_KEY = "Input:"
RESPONSE_KEY = "### Response:"
PROMPT_NO_INPUT_FORMAT = """{intro}
{instruction_key}
{instruction}
{response_key}""".format(
intro=INTRO_BLURB,
instruction_key=INSTRUCTION_KEY,
instruction="{instruction}",
response_key=RESPONSE_KEY,
)
PROMPT_WITH_INPUT_FORMAT = """{intro}
{instruction_key}
{instruction}
{input_key}
{input}
{response_key}""".format(
intro=INTRO_BLURB,
instruction_key=INSTRUCTION_KEY,
instruction="{instruction}",
input_key=INPUT_KEY,
input="{input}",
response_key=RESPONSE_KEY,
)
def load_training_dataset(
tokenizer,
path_or_dataset: str = DEFAULT_TRAINING_DATASET,
) -> Dataset:
print(f"Loading dataset from {path_or_dataset}")
dataset = load_dataset(path_or_dataset, cache_dir='/dbfs/llama2-deepspeed')["train"]
print(f"Found {dataset.num_rows} rows")
def _reformat_data(rec):
instruction = rec["instruction"]
response = rec["response"]
context = rec.get("context")
if context:
questions = PROMPT_WITH_INPUT_FORMAT.format(instruction=instruction, input=context)
else:
questions = PROMPT_NO_INPUT_FORMAT.format(instruction=instruction)
return {"text": f"{{ 'prompt': {questions}, 'response': {response} }}"}
dataset = dataset.map(_reformat_data)
def tokenize_function(allEntries):
return tokenizer(allEntries['text'], truncation=True, max_length=512,)
dataset = dataset.map(tokenize_function)
split_dataset = dataset.train_test_split(test_size=1000)
train_tokenized_dataset = split_dataset['train']
eval_tokenized_dataset = split_dataset['test']
return train_tokenized_dataset, eval_tokenized_dataset
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH)
tokenizer.pad_token = tokenizer.eos_token
train_dataset, eval_dataset = load_training_dataset(tokenizer)
以下のコマンドでは、Deepspeedが実行するトレーニング関数を定義しています。トレーニング関数は、実行のためにそれぞれのワーカーに送信され、モデルをロードし、トレーニング引数を設定するためにtransformersライブラリを使用し、トレーニングにはHFトレーナーを使います。
from functools import partial
import json
import logging
import os
import numpy as np
from pathlib import Path
import torch
import transformers
from transformers import (
AutoConfig,
AutoModelForCausalLM,
DataCollatorForLanguageModeling,
PreTrainedTokenizer,
Trainer,
TrainingArguments,
)
os.environ['HF_HOME'] = '/local_disk0/hf'
os.environ['TRANSFORMERS_CACHE'] = '/local_disk0/hf'
LOCAL_OUTPUT_DIR = "/Volumes/users/takaaki_yayoi/llama2_models/Llama-2-7b-chat-hf/output"
def load_model(pretrained_model_name_or_path: str) -> AutoModelForCausalLM:
print(f"Loading model for {pretrained_model_name_or_path}")
model = transformers.AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path,
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
config = AutoConfig.from_pretrained(pretrained_model_name_or_path)
model_hidden_size = config.hidden_size
return model, model_hidden_size
from torch.distributed.elastic.multiprocessing.errors import record
@record
def fine_tune_llama2(
*,
local_rank: str = None,
input_model: str = MODEL_PATH,
local_output_dir: str = LOCAL_OUTPUT_DIR,
dbfs_output_dir: str = None,
epochs: int = 3,
per_device_train_batch_size: int = 10,
per_device_eval_batch_size: int = 10,
lr: float = 1e-5,
gradient_checkpointing: bool = True,
gradient_accumulation_steps: int = 8,
bf16: bool = False,
logging_steps: int = 10,
save_steps: int = 400,
max_steps: int = 200,
eval_steps: int = 50,
save_total_limit: int = 10,
warmup_steps: int = 20,
training_dataset: str = DEFAULT_TRAINING_DATASET,
):
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:128"
model, model_hidden_size = load_model(input_model)
deepspeed_config["hidden_size"] = model_hidden_size
deepspeed_config["zero_optimization"]["reduce_bucket_size"] = model_hidden_size*model_hidden_size
deepspeed_config["zero_optimization"]["stage3_prefetch_bucket_size"] = 0.9 * model_hidden_size * model_hidden_size
deepspeed_config["zero_optimization"]["stage3_param_persistence_threshold"] = 10 * model_hidden_size
fp16 = not bf16
training_args = TrainingArguments(
output_dir=local_output_dir,
per_device_train_batch_size=per_device_train_batch_size,
per_device_eval_batch_size=per_device_eval_batch_size,
gradient_checkpointing=gradient_checkpointing,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=lr,
num_train_epochs=epochs,
weight_decay=1,
do_eval=True,
evaluation_strategy="steps",
eval_steps=eval_steps,
fp16=fp16,
bf16=bf16,
deepspeed=deepspeed_config,
logging_strategy="steps",
logging_steps=logging_steps,
save_strategy="steps",
save_steps=save_steps,
max_steps=max_steps,
save_total_limit=save_total_limit,
local_rank=local_rank,
warmup_steps=warmup_steps,
report_to=[],
)
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=False
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
print("Training the model")
trainer.train()
print(f"Saving Model to {local_output_dir}")
trainer.save_model(output_dir=local_output_dir)
tokenizer.save_pretrained(local_output_dir)
if dbfs_output_dir:
print(f"Saving Model to {dbfs_output_dir}")
trainer.save_model(output_dir=dbfs_output_dir)
tokenizer.save_pretrained(dbfs_output_dir)
print("Training finished.")
ディストリビューターの実行
上で設定を変えているので、マルチノードでのチューニングが実行されます。
dist.run(fine_tune_llama2, epochs=1, max_steps=1)
Started distributed training with 3 executor processes
2024-08-07 08:15:11.025092: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2024-08-07 08:15:11.028496: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2024-08-07 08:15:11.033235: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2024-08-07 08:15:11.071724: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-08-07 08:15:11.075192: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-08-07 08:15:11.079450: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
[2024-08-07 08:15:20,330] [INFO] [real_accelerator.py:133:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-08-07 08:15:20,327] [INFO] [real_accelerator.py:133:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2024-08-07 08:15:20,400] [INFO] [real_accelerator.py:133:get_accelerator] Setting ds_accelerator to cuda (auto detect)
Loading model for /Volumes/users/takaaki_yayoi/llama2_models/Llama-2-7b-chat-hf
Loading model for /Volumes/users/takaaki_yayoi/llama2_models/Llama-2-7b-chat-hf
Loading model for /Volumes/users/takaaki_yayoi/llama2_models/Llama-2-7b-chat-hf
Loading checkpoint shards: 100%|██████████| 2/2 [01:53<00:00, 56.70s/it]
[2024-08-07 08:18:21,993] [WARNING] [comm.py:152:init_deepspeed_backend] NCCL backend in DeepSpeed not yet implemented
[2024-08-07 08:18:21,993] [INFO] [comm.py:616:init_distributed] cdb=None
Loading checkpoint shards: 100%|██████████| 2/2 [01:54<00:00, 57.10s/it]
Loading checkpoint shards: 100%|██████████| 2/2 [01:54<00:00, 57.08s/it]
[2024-08-07 08:18:22,196] [WARNING] [comm.py:152:init_deepspeed_backend] NCCL backend in DeepSpeed not yet implemented
[2024-08-07 08:18:22,197] [INFO] [comm.py:616:init_distributed] cdb=None
[2024-08-07 08:18:22,210] [WARNING] [comm.py:152:init_deepspeed_backend] NCCL backend in DeepSpeed not yet implemented
[2024-08-07 08:18:22,210] [INFO] [comm.py:616:init_distributed] cdb=None
[2024-08-07 08:18:22,210] [INFO] [comm.py:643:init_distributed] Initializing TorchBackend in DeepSpeed with backend nccl
Training the model
Training the model
Training the model
Using /root/.cache/torch_extensions/py310_cu118 as PyTorch extensions root...
Creating extension directory /root/.cache/torch_extensions/py310_cu118/cpu_adam...
Using /root/.cache/torch_extensions/py310_cu118 as PyTorch extensions root...
Creating extension directory /root/.cache/torch_extensions/py310_cu118/cpu_adam...
Using /root/.cache/torch_extensions/py310_cu118 as PyTorch extensions root...
Creating extension directory /root/.cache/torch_extensions/py310_cu118/cpu_adam...
Detected CUDA files, patching ldflags
Emitting ninja build file /root/.cache/torch_extensions/py310_cu118/cpu_adam/build.ninja...
Building extension module cpu_adam...
Detected CUDA files, patching ldflags
Emitting ninja build file /root/.cache/torch_extensions/py310_cu118/cpu_adam/build.ninja...
Building extension module cpu_adam...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
Detected CUDA files, patching ldflags
Emitting ninja build file /root/.cache/torch_extensions/py310_cu118/cpu_adam/build.ninja...
Building extension module cpu_adam...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/3] /usr/local/cuda/bin/nvcc -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/databricks/python/lib/python3.10/site-packages/deepspeed/ops/csrc/includes -I/usr/local/cuda/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include/torch/csrc/api/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include/TH -isystem /databricks/python/lib/python3.10/site-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.10 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_75,code=compute_75 -gencode=arch=compute_75,code=sm_75 --compiler-options '-fPIC' -O3 --use_fast_math -std=c++17 -U__CUDA_NO_HALF_OPERATORS__ -U__CUDA_NO_HALF_CONVERSIONS__ -U__CUDA_NO_HALF2_OPERATORS__ -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_75,code=compute_75 -c /databricks/python/lib/python3.10/site-packages/deepspeed/ops/csrc/common/custom_cuda_kernel.cu -o custom_cuda_kernel.cuda.o
[1/3] /usr/local/cuda/bin/nvcc -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/databricks/python/lib/python3.10/site-packages/deepspeed/ops/csrc/includes -I/usr/local/cuda/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include/torch/csrc/api/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include/TH -isystem /databricks/python/lib/python3.10/site-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.10 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_75,code=compute_75 -gencode=arch=compute_75,code=sm_75 --compiler-options '-fPIC' -O3 --use_fast_math -std=c++17 -U__CUDA_NO_HALF_OPERATORS__ -U__CUDA_NO_HALF_CONVERSIONS__ -U__CUDA_NO_HALF2_OPERATORS__ -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_75,code=compute_75 -c /databricks/python/lib/python3.10/site-packages/deepspeed/ops/csrc/common/custom_cuda_kernel.cu -o custom_cuda_kernel.cuda.o
[1/3] /usr/local/cuda/bin/nvcc -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/databricks/python/lib/python3.10/site-packages/deepspeed/ops/csrc/includes -I/usr/local/cuda/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include/torch/csrc/api/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include/TH -isystem /databricks/python/lib/python3.10/site-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.10 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_75,code=compute_75 -gencode=arch=compute_75,code=sm_75 --compiler-options '-fPIC' -O3 --use_fast_math -std=c++17 -U__CUDA_NO_HALF_OPERATORS__ -U__CUDA_NO_HALF_CONVERSIONS__ -U__CUDA_NO_HALF2_OPERATORS__ -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_75,code=compute_75 -c /databricks/python/lib/python3.10/site-packages/deepspeed/ops/csrc/common/custom_cuda_kernel.cu -o custom_cuda_kernel.cuda.o
[2/3] c++ -MMD -MF cpu_adam.o.d -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/databricks/python/lib/python3.10/site-packages/deepspeed/ops/csrc/includes -I/usr/local/cuda/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include/torch/csrc/api/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include/TH -isystem /databricks/python/lib/python3.10/site-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.10 -D_GLIBCXX_USE_CXX11_ABI=0 -fPIC -std=c++17 -O3 -std=c++17 -g -Wno-reorder -L/usr/local/cuda/lib64 -lcudart -lcublas -g -march=native -fopenmp -D__AVX512__ -D__ENABLE_CUDA__ -c /databricks/python/lib/python3.10/site-packages/deepspeed/ops/csrc/adam/cpu_adam.cpp -o cpu_adam.o
[2/3] c++ -MMD -MF cpu_adam.o.d -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/databricks/python/lib/python3.10/site-packages/deepspeed/ops/csrc/includes -I/usr/local/cuda/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include/torch/csrc/api/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include/TH -isystem /databricks/python/lib/python3.10/site-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.10 -D_GLIBCXX_USE_CXX11_ABI=0 -fPIC -std=c++17 -O3 -std=c++17 -g -Wno-reorder -L/usr/local/cuda/lib64 -lcudart -lcublas -g -march=native -fopenmp -D__AVX512__ -D__ENABLE_CUDA__ -c /databricks/python/lib/python3.10/site-packages/deepspeed/ops/csrc/adam/cpu_adam.cpp -o cpu_adam.o
[2/3] c++ -MMD -MF cpu_adam.o.d -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/databricks/python/lib/python3.10/site-packages/deepspeed/ops/csrc/includes -I/usr/local/cuda/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include/torch/csrc/api/include -isystem /databricks/python/lib/python3.10/site-packages/torch/include/TH -isystem /databricks/python/lib/python3.10/site-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.10 -D_GLIBCXX_USE_CXX11_ABI=0 -fPIC -std=c++17 -O3 -std=c++17 -g -Wno-reorder -L/usr/local/cuda/lib64 -lcudart -lcublas -g -march=native -fopenmp -D__AVX512__ -D__ENABLE_CUDA__ -c /databricks/python/lib/python3.10/site-packages/deepspeed/ops/csrc/adam/cpu_adam.cpp -o cpu_adam.o
[3/3] c++ cpu_adam.o custom_cuda_kernel.cuda.o -shared -lcurand -L/databricks/python/lib/python3.10/site-packages/torch/lib -lc10 -lc10_cuda -ltorch_cpu -ltorch_cuda -ltorch -ltorch_python -L/usr/local/cuda/lib64 -lcudart -o cpu_adam.so
Loading extension module cpu_adam...
Time to load cpu_adam op: 31.403549671173096 seconds
[3/3] c++ cpu_adam.o custom_cuda_kernel.cuda.o -shared -lcurand -L/databricks/python/lib/python3.10/site-packages/torch/lib -lc10 -lc10_cuda -ltorch_cpu -ltorch_cuda -ltorch -ltorch_python -L/usr/local/cuda/lib64 -lcudart -o cpu_adam.so
Loading extension module cpu_adam...
Time to load cpu_adam op: 31.35505962371826 seconds
[3/3] c++ cpu_adam.o custom_cuda_kernel.cuda.o -shared -lcurand -L/databricks/python/lib/python3.10/site-packages/torch/lib -lc10 -lc10_cuda -ltorch_cpu -ltorch_cuda -ltorch -ltorch_python -L/usr/local/cuda/lib64 -lcudart -o cpu_adam.so
Loading extension module cpu_adam...
Time to load cpu_adam op: 31.73735213279724 seconds
Parameter Offload: Total persistent parameters: 266240 in 65 params
0%| | 0/1 [00:00<?, ?it/s]You're using a LlamaTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
0%| | 0/1 [00:00<?, ?it/s]You're using a LlamaTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
0%| | 0/1 [00:00<?, ?it/s]You're using a LlamaTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...
`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...
`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...
{'train_runtime': 216.6907, 'train_samples_per_second': 1.108, 'train_steps_per_second': 0.005, 'train_loss': 2.538902759552002, 'epoch': 0.02}
{'train_runtime': 216.9241, 'train_samples_per_second': 1.106, 'train_steps_per_second': 0.005, 'train_loss': 2.4253015518188477, 'epoch': 0.02}
{'train_runtime': 216.9245, 'train_samples_per_second': 1.106, 'train_steps_per_second': 0.005, 'train_loss': 2.430245876312256, 'epoch': 0.02}
100%|██████████| 1/1 [03:36<00:00, 216.76s/it]
Saving Model to /Volumes/users/takaaki_yayoi/llama2_models/Llama-2-7b-chat-hf/output
100%|██████████| 1/1 [03:36<00:00, 216.85s/it]
Saving Model to /Volumes/users/takaaki_yayoi/llama2_models/Llama-2-7b-chat-hf/output
100%|██████████| 1/1 [03:36<00:00, 216.85s/it]
Saving Model to /Volumes/users/takaaki_yayoi/llama2_models/Llama-2-7b-chat-hf/output
Training finished.
Training finished.
Training finished.
Finished distributed training with 3 executor processes
run() が完了すると、ローカルの出力パスからモデルをロードできるようになります(このノートブックでは /Volumes/users/takaaki_yayoi/llama2_models/Llama-2-7b-chat-hf/output)。
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH)
tokenizer.pad_token = tokenizer.eos_token
pipeline = transformers.pipeline(
"text-generation",
model= LOCAL_OUTPUT_DIR,
tokenizer=tokenizer,
torch_dtype=torch.float16,
trust_remote_code=True,
device_map="auto",
return_full_text=False
)
pipeline("What is ML?")
[{'generated_text': '\n\nMachine learning (ML) is a subfield of artificial intelligence (AI'}]