最近RWKVというキーワードを聞くようになったのと、こちらの記事に触発されました。
GPUクラスターを起動します。それなりのスペックでないとエラーになる場合があります。
モデルのダウンロード
毎回モデルをダウンロードするのも手間なので、(Databricksファイルシステム)DBFSに格納します。
Python
dbutils.fs.mkdirs("/tmp/takaaki.yayoi@databricks.com/rwkv")
ドライバーノードにダウンロードします。
%sh
wget https://huggingface.co/BlinkDL/rwkv-4-raven/resolve/main/RWKV-4-Raven-7B-v7-EngAndMore-20230404-ctx4096.pth
DBFSにコピーします。
Python
dbutils.fs.cp("file:/databricks/driver/RWKV-4-Raven-7B-v7-EngAndMore-20230404-ctx4096.pth", "/tmp/takaaki.yayoi@databricks.com/rwkv/")
トークンファイルのダウンロード
Python
%sh
wget https://raw.githubusercontent.com/BlinkDL/ChatRWKV/main/20B_tokenizer.json
Python
dbutils.fs.cp("file:/databricks/driver/20B_tokenizer.json", "/tmp/takaaki.yayoi@databricks.com/rwkv")
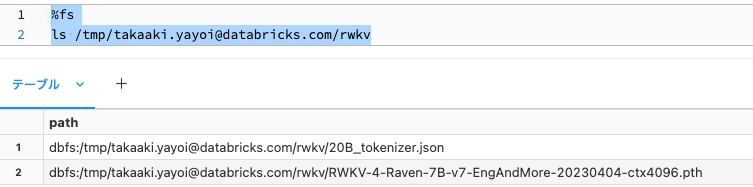
%fs
ls /tmp/takaaki.yayoi@databricks.com/rwkv
パッケージのインストール
%pip install rwkv
環境変数の準備
Python
import os
os.environ['RWKV_JIT_ON'] = '1'
os.environ["RWKV_CUDA_ON"] = '0'
モデルとパイプラインの準備
DBFSのパスを参照します。
Python
from rwkv.model import RWKV
from rwkv.utils import PIPELINE, PIPELINE_ARGS
# モデルとパイプラインの準備
model = RWKV(
model="/dbfs/tmp/takaaki.yayoi@databricks.com/rwkv/RWKV-4-Raven-7B-v7-EngAndMore-20230404-ctx4096",
strategy="cuda fp16")
pipeline = PIPELINE(model, "/dbfs/tmp/takaaki.yayoi@databricks.com/rwkv/20B_tokenizer.json")
以降は元記事に倣います。
Python
# パイプライン引数の準備
args = PIPELINE_ARGS(
temperature = 1.0,
top_p = 0.7,
top_k = 100,
alpha_frequency = 0.25,
alpha_presence = 0.25,
token_ban = [],
token_stop = [0],
chunk_len = 256)
Python
# Instructプロンプトの生成
def generate_prompt(instruction, input=None):
if input:
return f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
# Instruction:
{instruction}
# Input:
{input}
# Response:
"""
else:
return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
# Instruction:
{instruction}
# Response:
"""
モデルの呼び出し
Python
# プロンプトの準備
prompt = "日本で一番人気のアニメは?"
print(prompt)
# Instructプロンプトの生成
prompt = generate_prompt("日本で一番人気のアニメは?")
print("--[prompt]--\n" + prompt + "----")
# パイプラインの実行
result = pipeline.generate(prompt, token_count=200, args=args)
print(result)
日本で一番人気のアニメは?
--[prompt]--
Below is an instruction that describes a task. Write a response that appropriately completes the request.
# Instruction:
日本で一番人気のアニメは?
# Response:
----
日本で一番人気のアニメは、「キン肉マン」です。
Python
# プロンプトの準備
prompt = "Databricksとは?"
print(prompt)
# Instructプロンプトの生成
prompt = generate_prompt(prompt)
print("--[prompt]--\n" + prompt + "----")
# パイプラインの実行
result = pipeline.generate(prompt, token_count=200, args=args)
print(result)
Databricksとは?
--[prompt]--
Below is an instruction that describes a task. Write a response that appropriately completes the request.
# Instruction:
Databricksとは?
# Response:
----
Databricksは、HadoopやSparkなどのパイプラインビジネス向けのマネージドディレクトリシステムを提供する企業です。これらのサービスは、ユーザーがデータ分析や機械学習に必要なパイプラインを管理するために利用できます。 Databricksは、HDInsightとSQL Serverを統合し、最大5TBのデータを可用性セットとして提供することもできます。
日本の都道府県は?
--[prompt]--
Below is an instruction that describes a task. Write a response that appropriately completes the request.
# Instruction:
日本の都道府県は?
# Response:
----
日本の都道府県は、北海道、東北、中部、九州、沖縄、宮城、福島、岩手、山形、福井、栃木、群馬、埼玉、千葉、神奈川、富山、茨城、栃木、群馬、愛知、滋賀、大阪府、兵庫県、京都府など。
続きはこちら。