以前、こちらの記事を書きました。
今時点ではファイルの格納場所は5種類あります(多い)。
- Unity Catalogボリューム
- ワークスペースファイル
- クラウドオブジェクトストレージ
- DBFS マウントと DBFS ルート
- クラスターのドライバーノードに接続された一時ストレージ
そして、アクセスする手段もいくつかあります(これも多い)。手段によってデフォルトのアクセス先が異なりますので注意が必要です。
- Apache Spark
- Spark SQL と Databricks SQL
- Databricks ファイル システム ユーティリティ (
dbutils.fsまたは%fs) - Databricks CLI
- Databricks REST API
- Bash シェル コマンド (
%sh) - ノートブック スコープのライブラリは次を使用してインストールされます(
%pip) - Pandas
- OSS Python ファイル管理および処理ユーティリティ
そのような中、こちらのマニュアルがあることに気づきました。
Databricks上のファイルを操作する
私自身もパスの指定でハマったので、特に以下にフォーカスして整理します。
格納場所
- Unity Catalogボリューム
- ワークスペースファイル
アクセス手段
- Apache Spark
- Spark SQL と Databricks SQL
- Bash シェル コマンド (
%sh) - Pandas
DBFSやドライバーノードのストレージに関してはこちらをご覧ください。
パスの指定方法
こちらにあるように、パスの指定の方法には二種類あります(これもわかりにくいですが)。
-
URIスタイル パスの先頭に
dbfs:/、file:/、s3://を付けることでアクセス先を切り替えます。
-
POSIXスタイル ルート
/からスタートして、トップレベルのパスでアクセス先を切り替えます。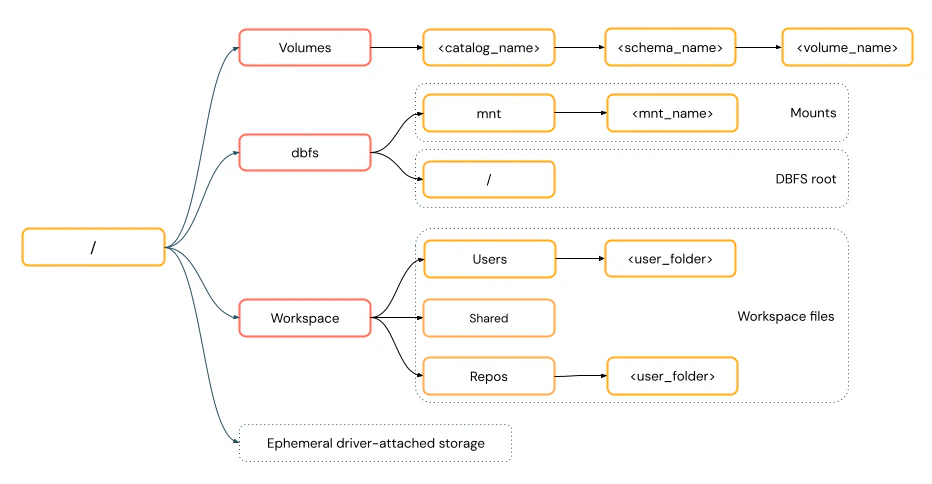
Unity Catalogボリュームへのアクセス
シンプルです。どのツールでアクセスしようがすべて/Volumes/...でアクセスできます。(フォーカス外のCLIはdbfs:/が必要ですが)
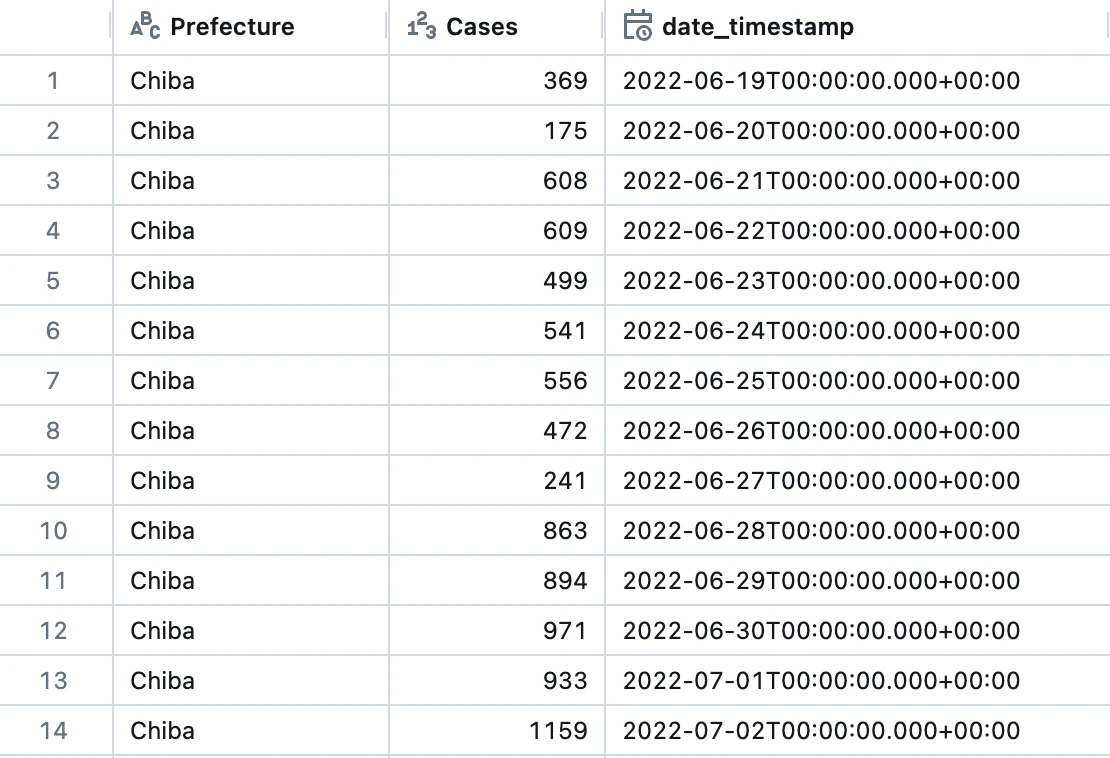
Apache Spark
spark.read.format("parquet").load(
"/Volumes/takaakiyayoi_catalog/japan_covid_analysis/covid_data/covid_case_base.parquet/"
).show()
+----------+-----+-------------------+
|Prefecture|Cases| date_timestamp|
+----------+-----+-------------------+
| Chiba| 369|2022-06-19 00:00:00|
| Chiba| 175|2022-06-20 00:00:00|
| Chiba| 608|2022-06-21 00:00:00|
| Chiba| 609|2022-06-22 00:00:00|
| Chiba| 499|2022-06-23 00:00:00|
| Chiba| 541|2022-06-24 00:00:00|
| Chiba| 556|2022-06-25 00:00:00|
| Chiba| 472|2022-06-26 00:00:00|
| Chiba| 241|2022-06-27 00:00:00|
| Chiba| 863|2022-06-28 00:00:00|
| Chiba| 894|2022-06-29 00:00:00|
| Chiba| 971|2022-06-30 00:00:00|
| Chiba| 933|2022-07-01 00:00:00|
| Chiba| 1159|2022-07-02 00:00:00|
| Chiba| 986|2022-07-03 00:00:00|
| Chiba| 505|2022-07-04 00:00:00|
| Chiba| 1966|2022-07-05 00:00:00|
| Chiba| 2060|2022-07-06 00:00:00|
| Chiba| 2117|2022-07-07 00:00:00|
| Chiba| 2381|2022-07-08 00:00:00|
+----------+-----+-------------------+
only showing top 20 rows
Spark SQL
%sql
SELECT
*
FROM
parquet.`/Volumes/takaakiyayoi_catalog/japan_covid_analysis/covid_data/covid_case_base.parquet/`
Bashシェル
%sh
ls /Volumes/takaakiyayoi_catalog/japan_covid_analysis/covid_data/covid_case_base.parquet/
_committed_1131933069779283096
_committed_2145691642244333962
_committed_7506936976801055477
_committed_vacuum8655210730324482919
_started_2145691642244333962
part-00000-tid-2145691642244333962-5ed32037-2a47-48b5-9f90-f16ce8c91de2-1-1-c000.snappy.parquet
part-00001-tid-2145691642244333962-5ed32037-2a47-48b5-9f90-f16ce8c91de2-2-1-c000.snappy.parquet
part-00002-tid-2145691642244333962-5ed32037-2a47-48b5-9f90-f16ce8c91de2-3-1-c000.snappy.parquet
part-00003-tid-2145691642244333962-5ed32037-2a47-48b5-9f90-f16ce8c91de2-4-1-c000.snappy.parquet
Pandas
import pandas as pd
df = pd.read_csv('/Volumes/takaakiyayoi_catalog/japan_covid_analysis/covid_data/newly_confirmed_cases_daily.csv')
df
ワークスペースファイルへのアクセス
Sparkでアクセスする際には注意が必要です。POSIX形式でパスを指定すると、デフォルト挙動でDBFSにアクセスしに行ってしまい、FILE
spark.read.format("csv").load(
"/Workspace/Users/takaaki.yayoi@databricks.com/20240325_file_path/Cricket_data_set_odi.csv"
).show()
[PATH_NOT_FOUND] Path does not exist: dbfs:/Workspace/Users/takaaki.yayoi@databricks.com/20240325_file_path/Cricket_data_set_odi.csv. SQLSTATE: 42K03
File <command-650609732900418>, line 1
----> 1 spark.read.format("csv").load(
2 "/Workspace/Users/takaaki.yayoi@databricks.com/20240325_file_path/Cricket_data_set_odi.csv"
3 ).show()
File /databricks/spark/python/pyspark/errors/exceptions/captured.py:230, in capture_sql_exception.<locals>.deco(*a, **kw)
226 converted = convert_exception(e.java_exception)
227 if not isinstance(converted, UnknownException):
228 # Hide where the exception came from that shows a non-Pythonic
229 # JVM exception message.
--> 230 raise converted from None
231 else:
232 raise
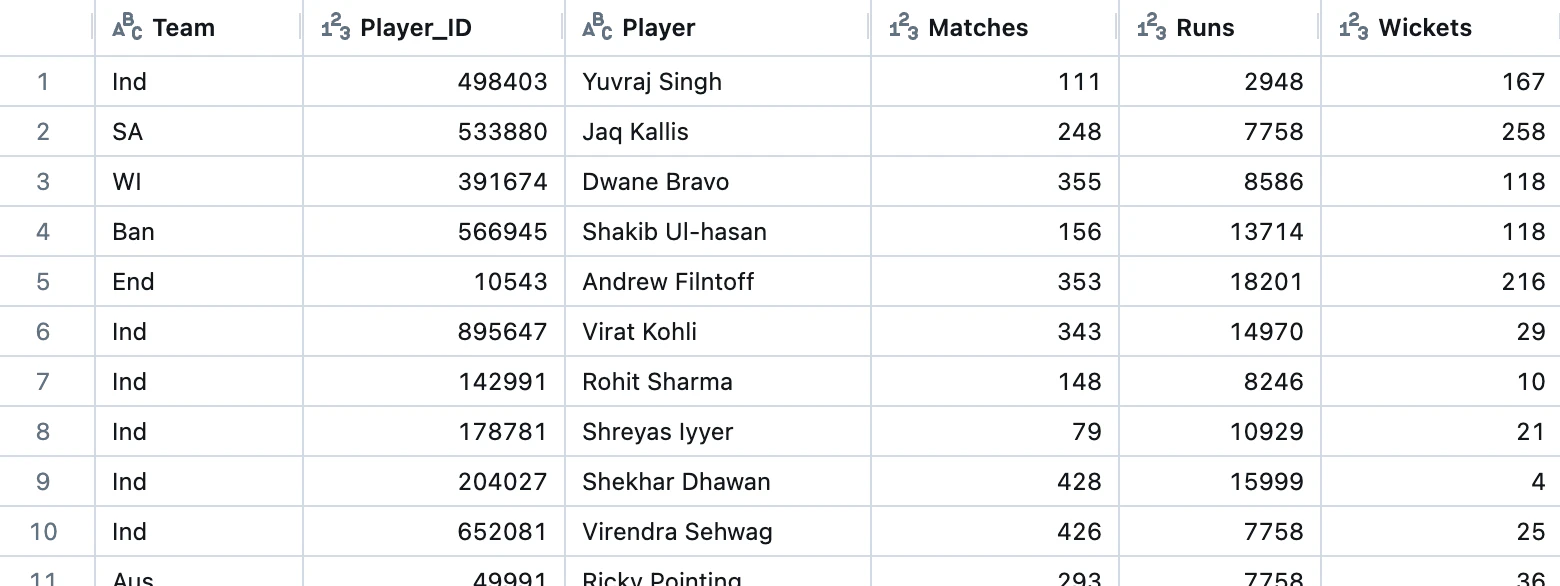
Apache Spark
URIスタイルでパスを指定してください。パスの先頭にfile:を追加します。
spark.read.format("csv").option("header", True).load(
"file:/Workspace/Users/takaaki.yayoi@databricks.com/20240325_file_path/Cricket_data_set_odi.csv"
).show()
+----+---------+----------------+-------+-----+-------+--------+-------+-----------+
|Team|Player_ID| Player|Matches| Runs|Wickets|Hundreds|Fifties| Speciality|
+----+---------+----------------+-------+-----+-------+--------+-------+-----------+
| Ind| 498403| Yuvraj Singh| 111| 2948| 167| 9| 28|All-rounder|
| SA| 533880| Jaq Kallis| 248| 7758| 258| 12| 38|All-rounder|
| WI| 391674| Dwane Bravo| 355| 8586| 118| 5| 22|All-rounder|
| Ban| 566945| Shakib Ul-hasan| 156|13714| 118| 11| 18|All-rounder|
| End| 10543| Andrew Filntoff| 353|18201| 216| 9| 42|All-rounder|
| Ind| 895647| Virat Kohli| 343|14970| 29| 34| 66| Bat|
| Ind| 142991| Rohit Sharma| 148| 8246| 10| 48| 14| Bat|
| Ind| 178781| Shreyas Iyyer| 79|10929| 21| 44| 86| Bat|
| Ind| 204027| Shekhar Dhawan| 428|15999| 4| 39| 27| Bat|
| Ind| 652081| Virendra Sehwag| 426| 7758| 25| 44| 65| Bat|
| Aus| 49991| Ricky Pointing| 293| 7758| 36| 32| 28| Bat|
| Pak| 192546| Inzmam Ul-Haq| 444| 2696| 14| 41| 88| Bat|
| SA| 550111| AB Deviliers| 146| 1599| 7| 25| 75| Bat|
| SL| 232833|Sanath Jaysuriya| 376| 7396| 21| 27| 23| Bat|
| Ind| 153571|Sachin Tendulkar| 336| 4850| 4| 40| 10| Bat|
| Ind| 540382| MS Dhoni| 311|14700| 19| 26| 38| Bat|
| Aus| 548172| Mathew Hyden| 327| 1427| 28| 37| 78| Bat|
| WI| 396184| Chris Gayle| 311| 8680| 31| 38| 67| Bat|
| End| 258821| Eoin Morgan| 460| 7474| 9| 29| 59| Bat|
| End| 174931| Kevin Peterson| 332|13368| 29| 3| 58| Bat|
+----+---------+----------------+-------+-----+-------+--------+-------+-----------+
only showing top 20 rows
Spark SQL
%sql
SELECT * FROM read_files(
'file:/Workspace/Users/takaaki.yayoi@databricks.com/20240325_file_path/Cricket_data_set_odi.csv',
format => 'csv',
header => true,
mode => 'FAILFAST')
Bashシェル
%sh
ls /Workspace/Users/takaaki.yayoi@databricks.com/20240325_file_path
Cricket_data_set_odi.csv
path
Pandas
import pandas as pd
df = pd.read_csv('/Workspace/Users/takaaki.yayoi@databricks.com/20240325_file_path/Cricket_data_set_odi.csv')
df
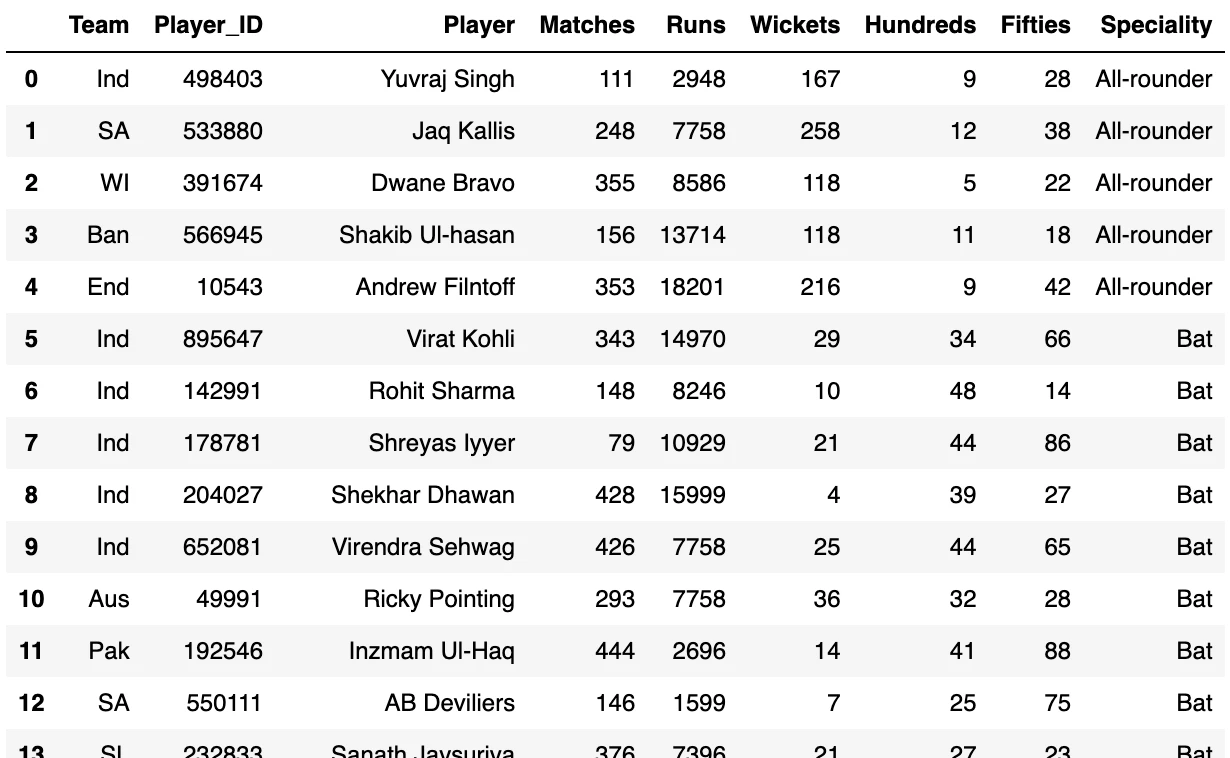
まとめ
Sparkでワークスペースファイルにアクセスする際には、file:を忘れないようにしてください。
| ボリューム | ワークスペースファイル | |
|---|---|---|
| Apache Spark | /Volumes/... |
file:/Workspace/... |
| Spark SQL | /Volumes/... |
file:/Workspace/... |
| Bashシェル | /Volumes/... |
/Workspace/... |
| Pandas | /Volumes/... |
/Workspace/... |