Log, load, register, and deploy MLflow Models | Databricks on AWS [2021/7/6時点]の翻訳です。
Databricksクイックスタートガイドのコンテンツです。
MLflowのモデルは、様々な後段のツール、例えば、Apache Sparkにおけるバッチ推論やREST API経由のリアルタイムサービングで用いることができる機械学習モデルをパッケージングするための標準的なフォーマットです。このフォーマットは、別のモデルサービングや推論プラットフォームで解釈できるように、様々なフレーバー(python-function、pytorch、sklearnなど)でモデルを保存できるようなコンベンションを定義します。
モデルのログ、ロード
Databricksランタイム8.4ML以降、モデルをログする際、MLflowは自動でconda.yamlとrequirements.txtファイルを記録します。condaやpipを用いて、モデル開発環境の再現と依存関係の再インストールを行う際にこれらのファイルを使用することができます。
APIコマンド
MLflowトラッキングサーバーにモデルを記録するには、mlflow.<model-type>.log_model(model, ...)を使用します。
推論やさらなる開発のために、以前ロギングしたモデルをロードするには、mlflow.<model-type>.load_model(modelpath)を使用し、modelpathは以下のいずれかになります。
- ランからの相対パス(例えば、
runs:/{run_id}/{model-path}) - DBFSパス
-
登録されたモデルのパス(例えば、
models:/{model_name}/{model_stage})
MLflowモデルに対するオプションの完全なリストに関しては、Referencing Artifacts in the MLflow documentationを参照ください。
Python MLflowモデルにおいて、ジェネリックなPython関数としてモデルをロードするために、mlflow.pyfunc.load_model()で指定できるオプションがあります。モデルをロードし、データポイントのスコアリングを行う際、以下のコードスニペットを使用することができます。
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
あるいは、Sparkクラスターでスコアリングを行うために使用するApache Spark UDFとしてモデルをエクスポートすることもできます。
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(model_path)
df = input_data.withColumn("prediction", model_udf())
MLflow UIにおいて自動で生成されるコードスニペット
Databricksノートブックでモデルをロギングした際、Databricksは自動でコードスニペットを生成するので、それをコピーし、モデルをロード、実行するために使用することができます。これらのコードスニペットを参照するには以下の手順を踏みます。
- モデルを生成しRuns画面に移動します。(Runs画面をどのように表示するのかに関しては、ノートブックエクスペリメントの参照を参照ください)
- Artifactsセクションまでスクロールします。
- ロギングされたモデルの名前をクリックします。モデルをロードし、Sparkデータフレーム、pandasデータフレームに対して予測を行う際に使用できるコードが右側のパネルに表示されます。
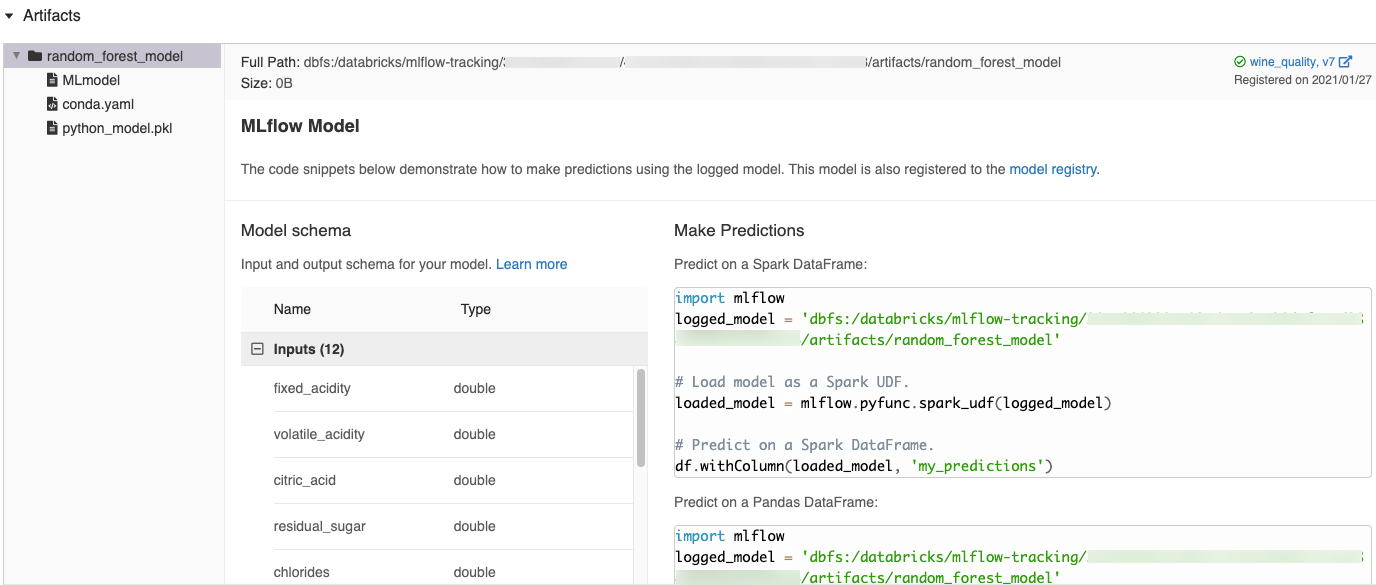
サンプル
モデルをロギングするサンプルに関しては、機械学習トレーニング実行トラッキングのサンプルを参照ください。推論のために記録されたモデルをロードするサンプルに関しては、以下のサンプルを参照ください。
モデルレジストリにモデルを登録
MLflowモデルの完全なライフサイクルを管理するためのUIと一連のAPIを提供する、集中管理されたモデルストアであるMLflowのモデルレジストリにモデルを登録することができます。モデルレジストリの一般的な情報に関しては、DatabricksにおけるMLflowモデルレジストリを参照ください。Databricksでモデルを管理するためにどのようにモデルレジストリを使うのかに関しては、Databricksにおける機械学習モデルの管理をご覧ください。
APIを用いてモデルを登録するには、mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}")を使用します。
DBFSにモデルを保存
ローカルにモデルを保存するには、mlflow.<model-type>.save_model(model, modelpath)を使用します。modelpathにはDBFSのパスを指定してください。例えば、プロジェクトの成果をDBFSのdbfs:/my_project_modelsに保存する場合には、モデルパスとして/dbfs/my_project_modelsを指定します。
modelpath = "/dbfs/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
モデルアーティファクトのダウンロード
様々なAPIを用いて、記録したモデルのアーティファクト(モデルファイル、プロット、メトリクスなど)をダウンロードすることができます。
Python APIのサンプル
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
model_uri = MlflowClient.get_model_version_download_uri(model_name, model_version)
ModelsArtifactRepository(model_uri).download_artifacts(artifact_path="")
Java APIのサンプル
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
CLIコマンドのサンプル
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
オンラインサービングへのモデルのデプロイ
サードパーティのサービングフレームワークにモデルをデプロイするには、mlflow.<deploy-type>.deploy()を使用します。以下のサンプルをご覧ください。
あるいは、DatabricksにおけるMLflowモデルサービングを利用することもできます。