Manage model lifecycle | Databricks on AWS [2022/10/27時点]の翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Databricksでは、MLflowモデルの完全なライフサイクルの管理に役立つホスティングバージョンのMLflowモデルレジストリを提供しています。モデルレジストリは以下の機能を提供します。
- 時系列順のモデルのリネージュ(どの時点でどのMLflowエクスペリメントとランがモデルを生成したのか)。
- サーバレスリアルタイム推論、あるいはクラシックMLflowモデルサービングによるモデルサービング。
- モデルのバージョン管理。
- ステージの移行(ステージングからプロダクション、アーカイブへなど)。
- レジストリのイベントに基づいて自動でアクションを起動するWebhook。
- モデルのイベントに対するメールの通知。
また、モデルの説明文を作成、参照したり、コメントすることができます。
本書では、機械学習ワークフローの一部としてどの様にモデルレジストリを使うのかと、モデルレジストリUIとモデルレジストリAPIの使用法をカバーしています。
モデルレジストリのコンセプトの概要については、Databricks MLflowガイドをご覧ください。
モデルの作成と登録
UIを用いたモデルの作成、登録
モデルレジストリにモデルを登録する方法は2つあります。MLflowに記録された既存のモデルを登録するか、新規の空のモデルを作成、登録し、過去に記録したモデルを割り当てることができます。
ノートブックから既存の記録済みモデルを登録する
-
ワークスペースで登録したいモデルを含むMLflowランを特定します。
- ノートブックツールバーの
 Experimentをクリックします。
Experimentをクリックします。

- エクスペリメントランのサイドバーの中で、ランの日付の隣にある
 アイコンをクリックします。MLflowランのページが表示されます。このページには、パラメーター、メトリクス、タグ、アーティファクト一覧を含むランの詳細が表示されます。
アイコンをクリックします。MLflowランのページが表示されます。このページには、パラメーター、メトリクス、タグ、アーティファクト一覧を含むランの詳細が表示されます。
- ノートブックツールバーの
-
アーティファクトのセクションで、xxx-modelといった名前のディレクトリをクリックします。
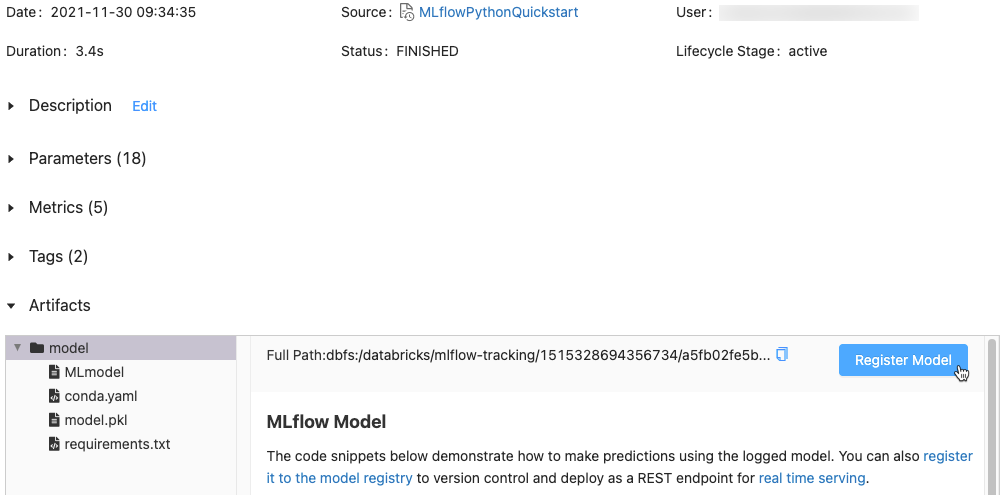
-
一番右にあるRegister Modelをクリックします。
-
ダイアログでは、Modelボックスをクリックし、以下のいずれかを行います。
- ドロップダウンメニューからCreate New Modelを選択します。Model Nameフィールドが表示されます。
scikit-learn-power-forecastingのようなモデル名を入力します。 - ドロップダウンメニューから既存のモデルを選択します。

- ドロップダウンメニューからCreate New Modelを選択します。Model Nameフィールドが表示されます。
-
Registerをクリックします。
-
Create New Modelを選択した場合、
scikit-learn-power-forecastingという名前のモデルを登録し、MLflowモデルレジストリによって管理されるセキュアな場所にモデルをコピーし、新規バージョンのモデルを作成します。 - 既存のモデルを選択した場合、選択したモデルの新たなバージョンを登録します。
少しすると、Register Modelボタンは新たに登録したモデルバージョンへのリンクに変化します。

-
Create New Modelを選択した場合、
-
モデルレジストリUIで新規モデルバージョンを開くためにリンクをクリックします。サイドバーの
 Modelsをクリックすることでも、モデルレジストリのモデルを参照することができます。
Modelsをクリックすることでも、モデルレジストリのモデルを参照することができます。
新規登録モデルを作成し、記録されたモデルを割り当てる
登録モデルページで新規の空のモデルを作成し、記録されたモデルを割り当てるためにCreate Modelボタンを使うことができます。以下の手順を踏んでください。
-
登録モデルページで、Create Modelをクリックします。モデル名を入力し、Createをクリックします。
-
ノートブックから既存の記録済みモデルを登録するのステップ1からステップ3を実施します。
-
登録モデルダイアログで、ステップ1で作成したモデル名を選択し、Registerをクリックします。これによって、作成した名前のモデルを登録し、MLflowモデルレジストリによって管理されるセキュアな場所にモデルをコピーし、モデルバージョン
Version 1を作成します。少しすると、Register Modelボタンは新たに登録したモデルバージョンへのリンクに変化します。Experiment RunsページのRegister ModelダイアログのModelドロップダウンリストからモデルを選択できる様になります。また、Create ModelVersionのようなAPIコマンドでモデル名を指定することで、モデルの新規バージョンを登録することができます。
APIによるモデルの登録
プログラムからモデルレジストリにモデルを登録する方法は3つあります。すべての方法はMLflowモデルレジストリによって管理されるセキュアな場所にモデルをコピーします。
-
MLflowエクスペリメントの過程でモデルを記録し、指定された他名前で登録するには、
mlflow.<model-flavor>.log_model(...)メソッドを使います。指定された名前の登録モデルが存在しない場合には、このメソッドは新規モデルを登録してバージョン1を作成し、ModelVersionMLflowオブジェクトを返却します。指定された名前の登録モデルがすでに存在しているのであれば、このメソッドは新規モデルバージョンを作成し、バージョンオブジェクトを返却します。Pythonwith mlflow.start_run(run_name=<run-name>) as run: ... mlflow.<model-flavor>.log_model(<model-flavor>=<model>, artifact_path="<model-path>", registered_model_name="<model-name>" ) -
すべてのエクスペリメントのランが完了した後に、指定した名前でモデルを登録し、どのモデルをレジストリに追加するのが最も適切であるのかを決定したのであれば、
mlflow.register_model()メソッドを使います。このメソッドには、引数mlruns:URIにランIDを指定する必要があります。指定された名前の登録モデルが存在しない場合、このメソッドは新規モデルを登録してバージョン1を作成し、ModelVersionMLflowオブジェクトを返却します。すでに指定された名前のモデルが登録されているのであれば、このメソッドは新規モデルバージョンを作成し、新規バージョンオブジェクトを返却します。Pythonresult=mlflow.register_model("runs:<model-path>", "<model-name>") -
指定された名前で新たに登録モデルを作成するには、MLflow Client APIの
create_registered_model()メソッドを使います。モデル名が存在する場合には、このメソッドはMLflowExceptionをスローします。Pythonclient = MlflowClient() result = client.create_registered_model("<model-name>")
また、Databricks Terraformプロバイダーやdatabricks_mlflow_modelを用いてモデルを登録することができます。
モデルのアクセスコントロール
モデルレジストリに登録されているモデルへのアクセスをどのようにコントロールするには、MLflowモデルのアクセス権をご覧ください。
モデルステージの移行
モデルバージョンは以下のステージのいずれかに存在することになります:None、Staging、Production、Archivedです。Stagingステージは、モデルのテストや検証を意味しますが、Productionステージはテストやレビュープロセスが完了したモデルバージョン向けのためのものであり、ライブなスコアリングのためのアプリケーションにデプロイされます。削除できると考えた時点でアーカイブされたモデルバージョンは、不活性状態と見なされます。バージョンが異なるモデルは異なるステージになることができます。
適切なアクセス権を持つユーザーが、ステージ間でモデルバージョンを移行することができます。特定のステージにモデルバージョンを移行する権限を持っているのであれば、移行を直接行うことができます。権限がない場合には、ステージ移行をリクエストし、モデルバージョンの移行できる権限を持つユーザーが、リクエストを承認、却下、キャンセルします。
UIによるモデルのステージ移行
モデルのステージを移行するには以下の手順に従ってください。
- 使用できるモデルのステージの一覧と、あなたが使える選択肢の一覧を表示するには、モデルバージョンページでStageの隣のドロップダウンリストをクリックします: 別のステージへのリクエストあるいは移行を選択します。
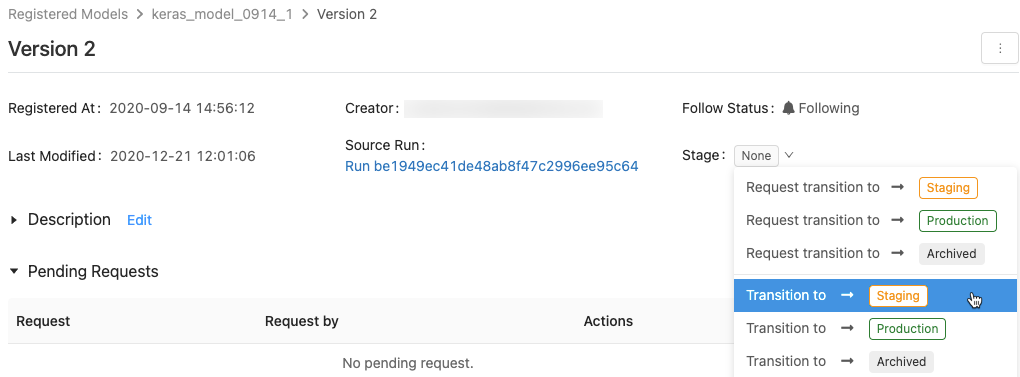
- オプションのコメントを入力してOKをクリックします。
モデルバージョンをプロダクションステージに移行する
テストや検証の後に、プロダクションステージへの移行や移行のリクエストを行うことができます。
モデルレジストリでは、1つ以上のバージョンの登録モデルがそれぞれのステージに存在することを許容します。プロダクションに1つのバージョンのみのモデルが存在する様にしたい場合には、Transition existing Production model versions to Archivedをチェックすることで、現在プロダクションにあるすべてのモデルバージョンをアーカイブすることができます。
モデルバージョンのステージ移行リクエストの承認、却下、キャンセル
ステージ移行の権限を持たないユーザーは、ステージ移行のリクエストを行うことができます。リクエストはモデルバージョンページのPending Requestsセクションに表示されます。
![]()
ステージ移行リクエストを承認、却下、キャンセルするには、Approve、Reject、Cancelのリンクをクリックします。
移行リクエストを作成したユーザーもリクエストをキャンセルすることができます。
モデルバージョンに対するアクティビティの参照
モデルバージョンに適用されたすべての移行リクエスト、承認、承認待ちを参照するには、Activitiesセクションに移動します。アクティビティの記録は、監査や調査のためにモデルのライフサイクルに関するリネージュを提供します。
APIによるモデルのステージ移行
適切な権限を持つユーザーは、モデルバージョンを新たなステージに移行することができます。
モデルバージョンを新たなステージにアップデートするには、MLflow Client APIのtransition_model_version_stage()メソッドを使います。
client = MlflowClient()
client.transition_model_version_stage(
name="<model-name>",
version=<model-version>,
stage="<stage>",
description="<description>"
)
<stage>に使える値は、"Staging"|"staging"、"Archived"|"archived"、"Production"|"production"、"None"|"none"です。
モデルを推論に使う
プレビュー
本機能はパブリックプレビューです。
モデルレジストリにモデルを登録した後に、バッチ推論やストリーミング推論のためのモデルを使用するノートブックを自動で生成することができます。あるいは、Databricksのサーバレスリアルタイム推論、あるいはクラシックMLflowモデルサービングを用いて、リアルタイムサービングにモデルを使用するエンドポイントを作成することができます。
登録モデルページかモデルバージョンページの右上にある をクリックします。モデル推論設定ダイアログが表示され、バッチ、ストリーミング、リアルタイム推論を設定することができます。
をクリックします。モデル推論設定ダイアログが表示され、バッチ、ストリーミング、リアルタイム推論を設定することができます。
重要!
Anaconda Inc.はanaconda.orgチャンネルの利用条件を更新しました。Anacondaのパッケージングやディストリビューションに依存しているのであれば、新たな利用条件によって商用ライセンスが必要になる場合があります。詳細はAnaconda Commercial Edition FAQをご覧ください。Anacondaチャンネルを使用する際には、彼らの利用条件の影響下にあることになります。
v1.18以前に記録されたMLflowモデルは、依存関係としてデフォルトでcondaのdefaultsチャンネル( https://repo.anaconda.com/pkgs/ )を用いて記録されます。DatabricksではMLflow v1.18移行を用いて記録したモデルでは、defaultsチャンネルの利用を停止しています。現在記録されるデフォルトチャンネルは、コミュニティ https://conda-forge.org/ で管理されているconda-forgeとなっています。
モデルでconda環境のdefaultsチャンネルを除外しないで、MLflow v1.18以前でモデルを記録してる場合、意図せずにモデルにdefaults チャンネルの依存関係が含まれる場合があります。モデルにこの依存関係があるかどうかを手動で確認するには、記録されたモデルにパッケージングされているconda.yamlファイルのchannelの値を確認します。例えば、defaultsチャンネルの依存関係を持つモデルのconda.yamlは以下の様になります。
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Databricksでは、皆様がお使いのモデルとやり取りしているAnacondaリポジトリの使用がAnacondaに許可されているかどうかを判断できないので、Databricksがお客様に変更を強制することはありません。Anacondamの使用条件のもと、Databricksの使用を通じたAnaconda.comのリポジトリの使用が許可されているのであれば、いかなるアクションも不要です。
モデルの環境で使用されるチャンネルを変更したい場合には、新たなconda.yamlを用いてモデルレジストリにモデルを再登録することができます。log_model()のconda_envパラメーターにチャンネルを指定することで、これを行うことができます。
log_model()APIの詳細に関しては、log_model for scikit-learnのように、お使いのモデルフレーバーに関するMLflowドキュメントを参照ください。
conda.yamlファイルの詳細については、MLflow documentationをご覧ください。
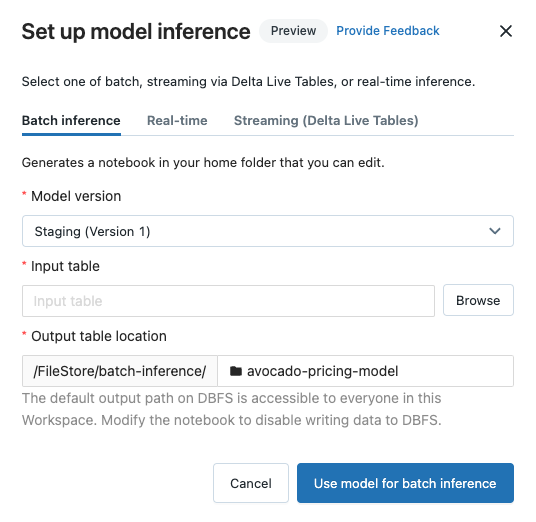
バッチ推論を設定する
バッチ推論ノートブックを作成するためにこれらのステップを踏む際、モデル名のフォルダー配下のBatch-Inferenceフォルダーにノートブックが保存されます。
-
Batch inferenceタブをクリックします。
-
Model versionドロップダウンから、使用するモデルバージョンを選択します。ドロップダウンの最初の2つの項目は、(存在する場合には)モデルの現在のプロダクションとステージングバージョンになります。これらの選択肢のいずれかを選択すると、ノートブックは自動でランの実行時のプロダクションとステージングバージョンを使用します。モデルの開発を進めている際にはこのノートブックをアップデートする必要はありません。
-
Input tableの隣のBrowseボタンをクリックします。Select input dataダイアログが表示されます。必要に応じて、Computeドロップダウンでクラスターを変更することができます。
注意
Unity Catalogが有効化されているワークスペースでは、Select input dataダイアログで3レベルの<catalog_name>.<database_name>.<table_name>を選択することができます。
-
モデルに対する入力データを含むテーブルを選択し、Selectをクリックします。生成されるノートブックは自動でこのデータをインポートし、モデルに送信します。モデルに入力する前に何かしらの変換処理がデータに必要な場合には、生成されたノートブックを編集することができます。
-
予測結果はディレクトリ
dbfs:/FileStore/batch-inferenceのフォルダーに保存されます。デフォルトでは、モデル名と同じ名前のフォルダーの中に保存されます。生成されたノートブックのそれぞれのランは、名前にタイムスタンプを追加した新規ファイルを書き込みます。また、以降のノートブックのランにおいてはタイムスタンプを含めずにファイルを上書きする様にすることもできます。手順は生成されたノートブックに含まれています。Output table locationフィールドに新たなフォルダー名を入力するか、ディレクトリをブラウズして異なるフォルダーを選択することで、予測結果が保存されるフォルダーを変更することができます。
Unity Catalogのロケーションに予測結果を保存するには、ノートブックを編集する必要があります。サンプルノートブックでは、Unity Catalogのデータを使用するモデルをどの様にトレーニングし、結果をUnity Catalogを書き戻すのかを説明しています。Python ML model training with Unity Catalog dataをご覧ください。
Delta Live Tablesを用いたストリーミング推論を設定する
ストリーミング推論ノートブックを作成するためにこれらのステップを踏む際には、モデル名のフォルダーの配下のフォルダーDLT-Inference配下にノートブックが保存されます。
-
Streaming (Delta Live Tables) タブをクリックします。
-
Model versionドロップダウンから、使用するモデルバージョンを選択します。ドロップダウンの最初の2つの項目は、(存在する場合には)モデルの現在のプロダクションとステージングバージョンになります。これらの選択肢のいずれかを選択すると、ノートブックは自動でランの実行時のプロダクションとステージングバージョンを使用します。モデルの開発を進めている際にはこのノートブックをアップデートする必要はありません。
-
Input tableの隣のBrowseボタンをクリックします。Select input dataダイアログが表示されます。必要に応じて、Computeドロップダウンでクラスターを変更することができます。
注意
Unity Catalogが有効化されているワークスペースでは、Select input dataダイアログで3レベルの<catalog_name>.<database_name>.<table_name>を選択することができます。
- モデルに対する入力データを含むテーブルを選択し、Selectをクリックします。生成されたノートブックは、ソースとしての入力テーブルを使用するデータ変換処理を作成し、モデル予測を実行するためにMLflowのPySpark推論UDFとインテグレーションします。モデルを適用する前後で追加の変換処理が必要であれば、生成されたノートブックを編集することができます。
- 出力のDelta Live Table名を指定します。ノートブックは指定された名前でライブテーブルを作成し、モデル予測結果を格納するために使用します。必要に応じてターゲットデータセットをカスタマイズするために、生成されたノートブックを編集することができます。例えば、出力としてストリーミングライブテーブルを定義し、スキーマ情報やデータ品質制約を追加します。
- このノートブックを用いて新たなDelta Live Tablesパイプラインを作成するか、追加のノートブックライブラリとして既存のライブラリに追加します。
リアルタイム推論を設定する
-
モデル推論ダイアログの設定ダイアログでReal-timeタブをクリックします。
-
モデルに対してサービングが有効化されていない場合はEnable servingをクリックします。登録モデルページのサービングタブが開き、StatusはPendingとなっています。数分後にStatusはReadyに変化します。
サービングがすでに有効化されているのであれば、サービングタブを表示するために、View existing real-time inferenceをクリックします。
フィードバックを提供する
この機能はプレビューであり、皆様からのフィードバックをいただければと考えています。フィードバックを提供するには、Configure model inferenceダイアログのProvide Feedbackをクリックします。
モデルバージョンを比較する
モデルレジストリでモデルバージョンを比較することができます。
- 登録モデルページで、モデルバージョンの左のチェックボックスをクリックすることで2つ以上のモデルバージョンを選択します。
- Compareをクリックします。
-
<N>バージョンを比較する画面が表示され、選択されたモデルバージョンのパラメーター、スキーマ、メトリクスを比較するテーブルが表示されます。画面の下には、プロットのタイプ(scatter、contour、parallel coordinates)とプロットするパラメーターやメトリクスを選択することができます。
通知設定を制御する
指定した登録モデルとモデルバージョンにおけるアクティビティに関して、メール通知を行う様にモデルレジストリを設定することができます。
登録モデルページで、Notify me aboutメニューに3つのオプションが表示されます。

- All new activity: このモデルのすべてのモデルバージョンのすべてのアクティビティについてメールの通知を送信します。登録モデルを作成した際、この設定がデフォルトになります。
- Activity on versions I follow: フォローしているモデルバージョン位関してのみメール通知を行います。この選択によって、フォローしているすべてのモデルバージョンの通知を受け取ります。特定のモデルバージョンの通知をオフにすることはできません。
- Mute notifications: この登録モデルのアクティビティについてメール通知を送信しません。
以下のイベントによって通知が行われます。
- 新規モデルバージョンの作成
- ステージ移行のリクエスト
- ステージ移行
- 新規コメント
以下のいずれかを行った際にはモデルの通知を自動で購読します。
- モデルバージョンへのコメント
- モデルバージョンのステージの移行
- モデルのステージの移行をリクエスト
モデルバージョンをフォローしているのかどうか確認するには、モデルバージョンページ、あるいは登録モデルページのモデルバージョンのテーブルのFollow Statusフィールドを参照します。
すべてのメール通知をオフにする
User SettingsメニューのModel Registry Settingsタブでメール通知をオフにすることができます。
- Databricksワークスペースの左下の
 Settingsをクリックします。
Settingsをクリックします。 - User Settingsをクリックします。
- Email preferencesタブに移動します。
- Model Registry email notificationsをオフにします。
管理者はAdmin Consoleで企業全体でメール通知をオフにすることができます。
メール送信の最大数
モデルレジストリは、アクティビティごとの日毎のユーザーに通知するメールの数に制限を設けています。例えば、ある登録モデルにおいて新規モデルバージョンに関するメールを1日に20回受け取った場合、モデルレジストリは1日の制限に達したことを告げるメールを送信し、次の日までイベントに関するメールを送信しません。
許可するメールの数の制限を増やすには、Databricks担当者にお問い合わせください。
Webhook
プレビュー
本機能はパブリックプレビューです。
Webhookを用いることで、お使いのインテグレーションが自動でアクションを起動できる様に、モデルレジストリのイベントをリッスンできるようになります。自動化や既存のCI/CDツールやワークフローとお使いの機械学習パイプライン解いて具レーションするためにwebhookを使うことができます。例えば、新規モデルバージョンが作成された際にCIのビルドを起動したり、モデルのプロダクションへの移行がリクエストされるたびにSlackを通じてチームメンバーに通知を行うことができます。
モデルやモデルバージョンに注釈をつける
注釈をつけることで、モデルやモデルバージョンに関する情報を提供することができます。例えば、問題の概要や使用した方法論やアルゴリズムに関する情報を含めたいと考えるかもしれません。
UIを用いてモデルやモデルバージョンに注釈を付ける
DatabricksのUIは、モデルとモデルバージョンに注釈をつけるための方法をいくつか提供しています。説明やコメントを用いてテキスト情報を追加し、検索可能なキーバリューのタグを追加することができます。説明文とタグはモデルとモデルバージョンで使用できます。コメントはモデルバージョンでのみ使用できます。
- 説明文はモデルに関する情報を提供することを意図しています。
- コメントは、モデルバージョン上のアクティビティに関する継続中の議論を維持するための手段を提供します。
- タグを用いることで、特定のモデルを様に検索できるようにするモデルのメタデータをカスタマイズできます。
モデルやモデルバージョンの説明文を追加、更新する
-
登録モデルページ、モデルバージョンページで、Descriptionの隣のEditをクリックします。編集ウィンドウが表示されます。
-
編集ウィンドウで説明文を入力、編集します。
-
変更を保存するにはSave、ウィンドウを閉じるにはCancelをクリックします。
モデルバージョンの説明文を入力すると、登録モデルページのテーブルのDescriptionカラムに説明文が表示されます。カラムには最大32文字あるいは1行のテキストの短い方が表示されます。
モデルバージョンにコメントする
- モデルバージョンページをスクロールダウンし、Activitiesの隣の下向き矢印をクリックします。
- 編集ウィンドウにコメントを入力し、Add Commentをクリックします。
モデルバージョンにタグをつける
-
登録モデルページ、モデルバージョンページで、展開されていない場合には
 をクリックします。タグのテーブルが表示されます。
をクリックします。タグのテーブルが表示されます。
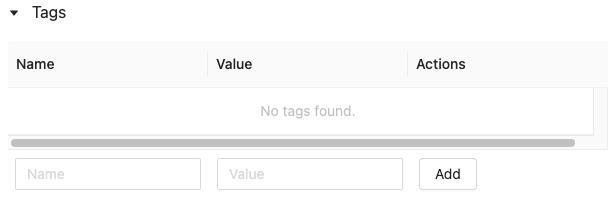
- NameとValueフィールドをクリックし、タグのキーとばビューを入力します。
-
Addをクリックします。
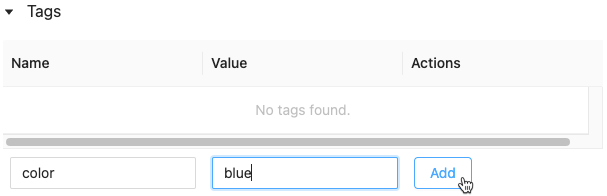
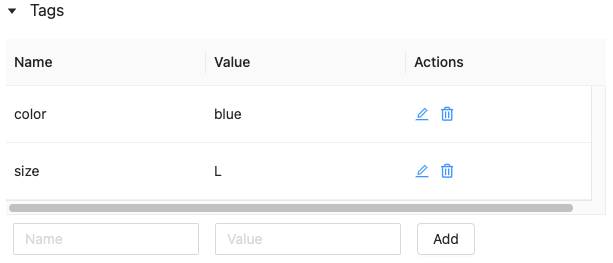
モデルやモデルバージョンのタグを編集、削除する
既存のタグを編集、削除するには、Actionsカラムのアイコンをクリックします。
APIを用いてモデルバージョンに注釈を付ける
モデルバージョンの説明文を更新するには、MLflow Client APIのupdate_model_version()メソッドを使います。
client = MlflowClient()
client.update_model_version(
name="<model-name>",
version=<model-version>,
description="<description>"
)
登録モデルやモデルバージョンのタグを設定、更新するには、MLflow Client APIのset_registered_model_tag()かset_model_version_tag()を使います。
client = MlflowClient()
client.set_registered_model_tag()(
name="<model-name>",
key="<key-value>",
tag="<tag-value>"
)
client = MlflowClient()
client.set_model_version_tag()(
name="<model-name>",
version=<model-version>,
key="<key-value>",
tag="<tag-value>"
)
モデル名を変更する(APIのみ)
登録モデルの名称を変更するには、MLflow Client APIのrename_registered_model()メソッドを使います。
client=MlflowClient()
client.rename_registered_model("<model-name>", "<new-model-name>")
注意
バージョンを持たない、あるいはすべてのバージョンがNone、Archivedステージにある場合にのみ、登録モデルの名称を変更することができます。
モデルを検索する
すべての登録モデルはMLflowモデルレジストリに存在します。UIかAPIを用いてモデルを検索することができます。
注意
モデルを検索する際には、少なくとも読み取り権限を持っているモデルのみが返却されます。
UIによるモデルの検索
すべての登録モデルを表示するには、サイドバーの![]() Modelsをクリックします。
Modelsをクリックします。
特定のモデルを検索するには、検索ボックスにテキストを入力します。モデル名やモデル名の一部を入力することができます。

また、タグで検索することができます。tags.<key>=<value>という書式でタグを入力します。複数のタグで検索するにはANDオペレーターを使用します。
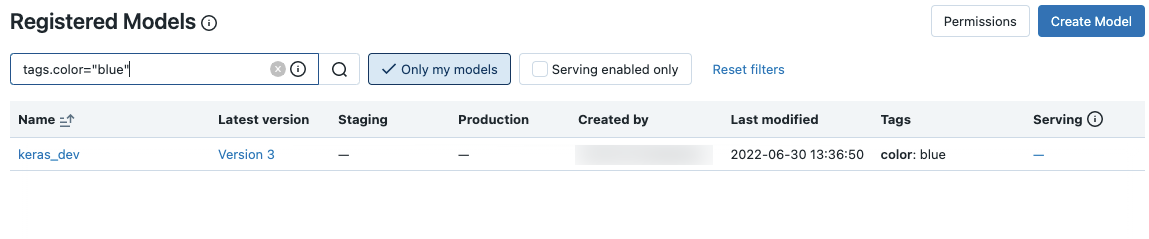
以下の様に、MLflow search syntaxを用いてモデル名とタグを検索することができます。

APIによるモデルの検索
すべての登録モデルの一覧を取得するには、MLflow Client APIのlist_registered_models()メソッドを使います。
from pprint import pprint
client = MlflowClient()
for rm in client.list_registered_models():
pprint(dict(rm), indent=4)
アウトプット
{ 'creation_timestamp': 1582671933216,
'description': None,
'last_updated_timestamp': 1582671960712,
'latest_versions': [<ModelVersion: creation_timestamp=1582671933246, current_stage='Production', description='A random forest model containing 100 decision trees trained in scikit-learn', last_updated_timestamp=1582671960712, name='sk-learn-random-forest-reg-model', run_id='ae2cc01346de45f79a44a320aab1797b', source='./mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model', status='READY', status_message=None, user_id=None, version=1>,
<ModelVersion: creation_timestamp=1582671960628, current_stage='None', description=None, last_updated_timestamp=1582671960628, name='sk-learn-random-forest-reg-model', run_id='d994f18d09c64c148e62a785052e6723', source='./mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model', status='READY', status_message=None, user_id=None, version=2>],
'name': 'sk-learn-random-forest-reg-model'}
また、MLflow Client APIのsearch_model_versions()メソッドを用いることで、特定のモデル名とバージョン詳細の一覧を検索することができます。
from pprint import pprint
client=MlflowClient()
[pprint(mv) for mv in client.search_model_versions("name='<model-name>'")]
アウトプット
{ 'creation_timestamp': 1582671933246,
'current_stage': 'Production',
'description': 'A random forest model containing 100 decision trees '
'trained in scikit-learn',
'last_updated_timestamp': 1582671960712,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'ae2cc01346de45f79a44a320aab1797b',
'source': './mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 1 }
{ 'creation_timestamp': 1582671960628,
'current_stage': 'None',
'description': None,
'last_updated_timestamp': 1582671960628,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'd994f18d09c64c148e62a785052e6723',
'source': './mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 2 }
モデルにタグが設定されている場合、MLflow Client APIのsearch_registered_models()メソッドを用いて、タグによる検索を行うこともできます。
print(f"Find registered models with a specific tag value")
for m in client.search_registered_models(f"tags.`<key-value>`='<tag-value>'"):
pprint(dict(m), indent=4)
モデルやモデルバージョンを削除する
UIやAPIを用いてモデルを削除することができます。
UIを用いてモデルバージョンやモデルを削除する
警告!
このアクションを取り消すことはできません。モデルバージョンをレジストリから削除するのではなく、Archivedステージに移行することができます。モデルを削除する際には、モデルレジストリによって格納されているすべてのモデルアーティファクトと、登録モデルに関連づけられているすべてのメタデータが削除されます。
注意
NoneあるいはArchivedステージにあるモデルバージョンとモデルのみを削除することができます。登録モデルにStaging、Productionステージのモデルバージョンが含まれている場合には、モデルを削除する前にNoneかArchivedに移行する必要があります。
モデルバージョンを削除するには:
- サイドバーのModelsをクリックします。
- モデル名をクリックします。
- モデルバージョンをクリックします。
- 画面右上の
 をクリックし、ドロップダウンメニューからDeleteを選択します。
をクリックし、ドロップダウンメニューからDeleteを選択します。
モデルを削除するには:
- サイドバーのModelsをクリックします。
- モデル名をクリックします。
- 画面右上のをクリックし、ドロップダウンメニューからDeleteを選択します。
APIを用いてモデルバージョンやモデルを削除する
警告!
このアクションを取り消すことはできません。モデルバージョンをレジストリから削除するのではなく、Archivedステージに移行することができます。モデルを削除する際には、モデルレジストリによって格納されているすべてのモデルアーティファクトと、登録モデルに関連づけられているすべてのメタデータが削除されます。
注意
NoneあるいはArchivedステージにあるモデルバージョンとモデルのみを削除することができます。登録モデルにStaging、Productionステージのモデルバージョンが含まれている場合には、モデルを削除する前にNoneかArchivedに移行する必要があります。
モデルバージョンを削除する
モデルバージョンを削除するには、MLflow Client APIのdelete_model_version()メソッドを使います。
# Delete versions 1,2, and 3 of the model
client = MlflowClient()
versions=[1, 2, 3]
for version in versions:
client.delete_model_version(name="<model-name>", version=version)
モデルを削除する
モデルを削除するには、MLflow Client APIのdelete_registered_model()メソッドを使います。
client = MlflowClient()
client.delete_registered_model(name="<model-name>")
ワークスペース間でモデルを共有する
Databricksでは、複数ワークスペースでのモデル共有をサポートしています。例えば、お使いのワークスペースでモデルを開発・記録し、中央管理されているモデルレジストリに登録することができます。これは、複数のチームがモデルにアクセスする際に有用です。複数のワークスペースを作成し、これらの環境横断でモデルを利用、管理することができます。
ワークスペース間でMLflowオブジェクトをコピーする
お使いのDatabricksワークスペース間でMLflowオブジェクトをインポート、エクスポートするために、ワークスペース間でMLflowエクスペリメント、モデル、ランを移行するためのコミュニティ主導のオープンソースプロジェクトであるMLflow Export-Importを活用することができます。
このツールを使うことで、以下のことが可能となります。
- 同一あるいは異なるトラッキングサーバーにいる他のデータサイエンティストとの共有、コラボレーション。例えば、他のユーザーからのエクスペリメントを、あなたのワークスペースにコピーすることができます。
- 開発ワークスペースからプロダクションワークスペースの様に、別のワークスペースへのモデルのコピー。
- お使いのローカルトラッキングサーバーからMLflowエクスペリメントやランを、Databricksワークスペースにコピー。
- ミッションクリティカルなエクスペリメントやモデルを別のDatabricksワークスペースにバックアップ。
サンプル
このサンプルでは、機械学習アプリケーションを構築するためにどのようにモデルレジストリを使うのかを説明しています。