2年前にこちらの記事を翻訳した際には、Databricksの特徴量ストア(Databricks Feature Store)はUnity Catalogに対応していなかったのですが、今ではUnity Catalogにインテグレーションされるようになっています。
この変化において、特に重要なのはUnity Catalogで管理される主キーを持つテーブルはすべて特徴量テーブルとして使用することができるという点です。特徴量テーブルとして使用できるということは、後述するFeature Engineering and Workspace Feature Store Python APIを通じてテーブルの操作が行え、かつモデルに特徴量の検索ロジックをパッケージングして記録できるようになるということを意味します。以前はFeature StoreのAPIを通じて作成されたHiveメタストア配下のテーブルしか特徴量ストアとして取り扱うことができませんでした。これは(柔軟性が高まって)嬉しい。
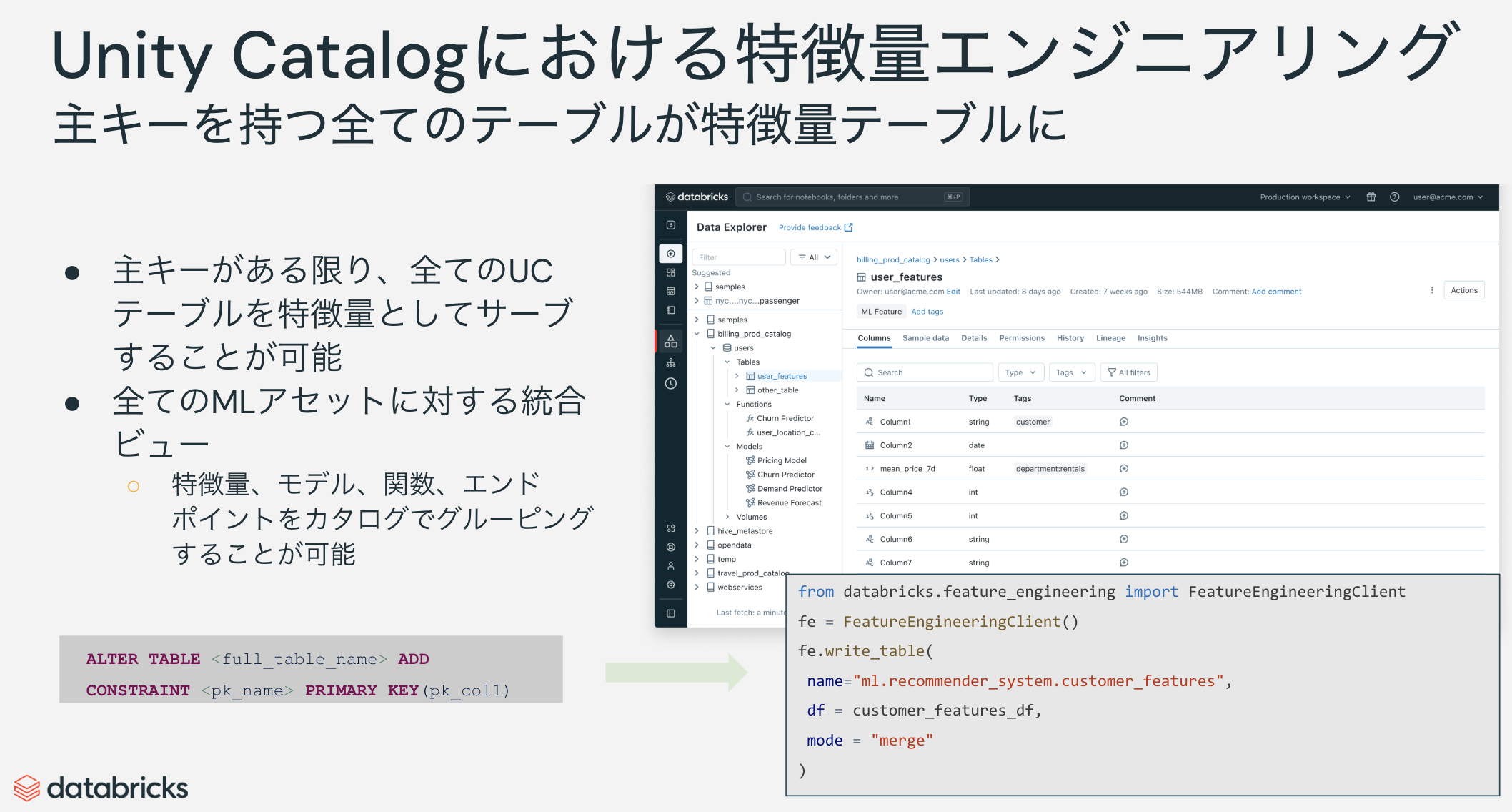
最新のマニュアルはこちら。
まずは、こちらの基本的な例からウォークスルーします。
このノートブックは、Databricks Feature EngineeringをUnity Catalogで使用して、Unity Catalogの特徴量を作成、保存、および管理し、MLモデルをトレーニングし、バッチ予測を行う方法を示します。この例では、さまざまな静的なワインの特徴量とリアルタイム入力を使用して、ワインの品質を予測することを目標としています。
このノートブックでは次のことを示します:
- 特徴量テーブルを作成し、それを使用して機械学習モデルのトレーニングデータセットを構築する方法。
- 特徴量テーブルを修正し、更新されたテーブルを使用して新しいバージョンのモデルを作成する方法。
- Databricks Features UIを使用して、特徴量がモデルにどのように関連しているかを確認する方法。
- 自動特徴量ルックアップを使用してバッチスコアリングを実行する方法。
要件
- Databricks Runtime 13.2 for Machine Learning以上。
- Databricks Runtime for Machine Learningにアクセスできない場合は、このノートブックをDatabricks Runtime 13.2以上で実行できます。その場合、このノートブックの最初に
%pip install databricks-feature-engineeringを実行してください。
- Databricks Runtime for Machine Learningにアクセスできない場合は、このノートブックをDatabricks Runtime 13.2以上で実行できます。その場合、このノートブックの最初に
import pandas as pd
from pyspark.sql.functions import monotonically_increasing_id, expr, rand
import uuid
from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup
import mlflow
import mlflow.sklearn
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
データセットの読み込み
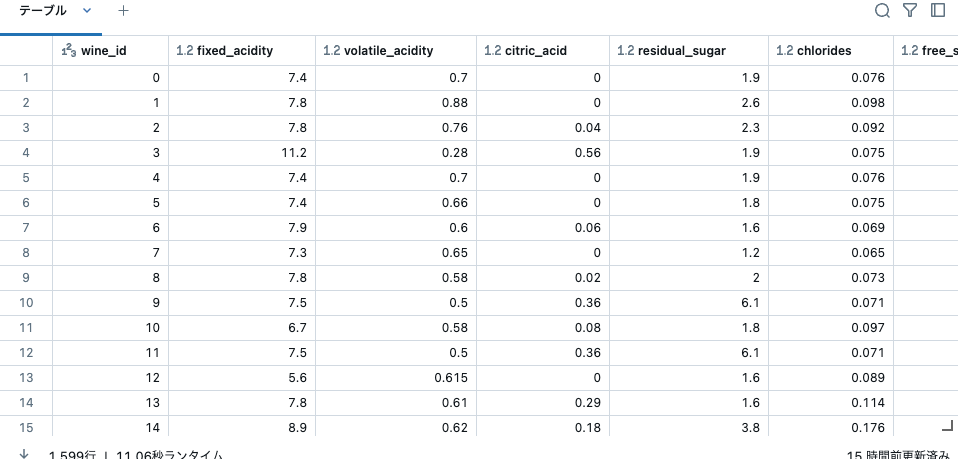
次のセルのコードは、データセットを読み込み、いくつかの小さなデータ準備を行います: 各観測値に一意のIDを作成し、列名からスペースを削除します。一意のID列(wine_id)は特徴量テーブルの主キーであり、特徴量のルックアップに使用されます。
raw_data = spark.read.load("/databricks-datasets/wine-quality/winequality-red.csv",format="csv",sep=";",inferSchema="true",header="true" )
def addIdColumn(dataframe, id_column_name):
"""データフレームにID列を追加"""
columns = dataframe.columns
new_df = dataframe.withColumn(id_column_name, monotonically_increasing_id())
return new_df[[id_column_name] + columns]
def renameColumns(df):
"""UCのFeature Engineeringに対応するために列名を変更"""
renamed_df = df
for column in df.columns:
renamed_df = renamed_df.withColumnRenamed(column, column.replace(' ', '_'))
return renamed_df
# 関数を実行
renamed_df = renameColumns(raw_data)
df = addIdColumn(renamed_df, 'wine_id')
# ターゲット列('quality')は特徴量テーブルに含まれないため削除
features_df = df.drop('quality')
display(features_df)
主キーとして使用するwine_idが追加されています。
新しいカタログを作成するか、既存のカタログを再利用する
新しいカタログを作成するには、メタストアに対する CREATE CATALOG 権限が必要です。
既存のカタログを使用するには、カタログに対する USE CATALOG 権限が必要です。
# 既存のカタログを再利用する場合:
spark.sql("USE CATALOG takaakiyayoi_catalog")
カタログに新しいスキーマを作成する
カタログに新しいスキーマを作成するには、カタログに対する CREATE SCHEMA 権限が必要です。
spark.sql("CREATE SCHEMA IF NOT EXISTS wine_db")
spark.sql("USE SCHEMA wine_db")
# 各実行ごとに一意のテーブル名を作成します。これにより、ノートブックを複数回実行してもエラーが発生しません。
table_name = f"takaakiyayoi_catalog.wine_db.wine_db_" + str(uuid.uuid4())[:6]
print(table_name)
takaakiyayoi_catalog.wine_db.wine_db_028c87
特徴量テーブルの作成
最初のステップは、FeatureEngineeringClientを作成することです。
fe = FeatureEngineeringClient()
# ノートブックで特徴量エンジニアリングクライアントAPI関数のヘルプを取得できます:
# help(fe.<function_name>)
# 例えば:
# help(fe.create_table)
help(fe.create_table)
Help on method create_table in module databricks.feature_engineering.client:
create_table(*, name: str, primary_keys: Union[str, List[str]], df: Optional[pyspark.sql.dataframe.DataFrame] = None, timeseries_column: Optional[str] = None, partition_columns: Union[str, List[str], NoneType] = None, schema: Optional[pyspark.sql.types.StructType] = None, description: Optional[str] = None, tags: Optional[Dict[str, str]] = None, **kwargs) -> databricks.ml_features.entities.feature_table.FeatureTable method of databricks.feature_engineering.client.FeatureEngineeringClient instance
Create and return a feature table with the given name and primary keys.
The returned feature table has the given name and primary keys.
Uses the provided ``schema`` or the inferred schema
of the provided ``df``. If ``df`` is provided, this data will be saved in
a Delta table. Supported data types for features are: ``IntegerType``, ``LongType``,
``FloatType``, ``DoubleType``, ``StringType``, ``BooleanType``, ``DateType``,
``TimestampType``, ``ShortType``, ``ArrayType``, ``MapType``, and ``BinaryType``,
``DecimalType``, and ``StructType``.
:param name: A feature table name. The format is ``<catalog_name>.<schema_name>.<table_name>``, for example ``ml.dev.user_features``.
:param primary_keys: The feature table's primary keys. If multiple columns are required,
specify a list of column names, for example ``['customer_id', 'region']``.
:param df: Data to insert into this feature table. The schema of
``df`` will be used as the feature table schema.
:param timeseries_column: Column containing the event time associated with feature value.
Timeseries column should be part of the primary keys.
Combined, the timeseries column and other primary keys of the feature table uniquely identify the feature value
for an entity at a point in time.
.. note::
Experimental: This argument may change or be removed in
a future release without warning.
:param partition_columns: Columns used to partition the feature table. If a list is
provided, column ordering in the list will be used for partitioning.
.. Note:: When choosing partition columns for your feature table, use columns that do
not have a high cardinality. An ideal strategy would be such that you
expect data in each partition to be at least 1 GB.
The most commonly used partition column is a ``date``.
Additional info: `Choosing the right partition columns for Delta tables
<https://bit.ly/3ueXsjv>`_
:param schema: Feature table schema. Either ``schema`` or ``df`` must be provided.
:param description: Description of the feature table.
:param tags: Tags to associate with the feature table.
特徴量テーブルを作成します。完全なAPIリファレンスについては、AWS、Azure、GCPを参照してください。
fe.create_table(
name=table_name,
primary_keys=["wine_id"],
df=features_df,
schema=features_df.schema,
description="ワインの特徴量"
)
カタログエクスプローラで特徴量テーブルが作成されたことを確認できます。なお、特にアイコンは変化しません。

create_table をデータフレームを提供せずに使用し、後で fe.write_table を使用して特徴量テーブルを埋めることもできます。
例:
fe.create_table(
name=table_name,
primary_keys=["wine_id"],
schema=features_df.schema,
description="wine features"
)
fe.write_table(
name=table_name,
df=features_df,
mode="merge"
)
Feature Engineering in Unity Catalogを使用してモデルを訓練する
特徴量テーブルには予測ターゲットが含まれていません。しかし、トレーニングデータセットには予測ターゲットの値が必要です。また、モデルが推論に使用される時点まで利用できない特徴量も存在する可能性があります。
この例では、特徴量 real_time_measurement を使用して、推論時にのみ観察できるワインの特性を表します。この特徴量はトレーニングに使用され、ワインの特徴量の値は推論時に提供されます。
## inference_data_dfにはwine_id(主キー)、quality(予測対象)、およびリアルタイムの特徴量が含まれています
inference_data_df = df.select("wine_id", "quality", (10 * rand()).alias("real_time_measurement"))
display(inference_data_df)

指定された lookup_key を使用して特徴テーブルとオンライン特徴量 real_time_measurement から特徴量を照合し、トレーニングデータセットを構築するために FeatureLookup を使用します。feature_names パラメータを指定しない場合、主キー以外のすべての特徴量が返されます。
def load_data(table_name, lookup_key):
# FeatureLookupで`feature_names`パラメータを指定しない場合、主キーを除くすべての特徴量が返されます
model_feature_lookups = [FeatureLookup(table_name=table_name, lookup_key=lookup_key)]
# fe.create_training_setは、inference_data_dfの主キーと一致するmodel_feature_lookupsの特徴量を検索します
training_set = fe.create_training_set(df=inference_data_df, feature_lookups=model_feature_lookups, label="quality", exclude_columns="wine_id")
training_pd = training_set.load_df().toPandas()
# 訓練データセットとテストデータセットを作成します
X = training_pd.drop("quality", axis=1)
y = training_pd["quality"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
return X_train, X_test, y_train, y_test, training_set
# 訓練データセットとテストデータセットを作成します
X_train, X_test, y_train, y_test, training_set = load_data(table_name, "wine_id")
X_train.head()

from mlflow.tracking.client import MlflowClient
# Unity CatalogのモデルにアクセスするためにMLflowクライアントを設定します
mlflow.set_registry_uri("databricks-uc")
model_name = "takaakiyayoi_catalog.wine_db.wine_model"
client = MlflowClient()
try:
client.delete_registered_model(model_name) # 既に作成されている場合はモデルを削除します
except:
None
次のセルのコードは、scikit-learnのRandomForestRegressorモデルをトレーニングし、Feature Engineering in UCでモデルをログします。
このコードは、トレーニングのパラメータと結果を追跡するためにMLflowの実験を開始します。モデルの自動ログ記録は無効になっています(mlflow.sklearn.autolog(log_models=False))。これは、モデルがfe.log_modelを使用してログされるためです。
# MLflowの自動ロギングを無効にし、代わりにUCのFeature Engineeringを使用してモデルをログに記録します
mlflow.sklearn.autolog(log_models=False)
def train_model(X_train, X_test, y_train, y_test, training_set, fe):
## モデルのフィットとログ
with mlflow.start_run() as run:
rf = RandomForestRegressor(max_depth=3, n_estimators=20, random_state=42)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
mlflow.log_metric("test_mse", mean_squared_error(y_test, y_pred))
mlflow.log_metric("test_r2_score", r2_score(y_test, y_pred))
fe.log_model(
model=rf,
artifact_path="wine_quality_prediction",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name=model_name,
)
train_model(X_train, X_test, y_train, y_test, training_set, fe)
ログされたモデルを表示するには、このノートブックのMLflow実験ページに移動します。実験ページにアクセスするには、左側のナビゲーションバーの実験アイコンをクリックします: ![]()
リストからノートブックのエクスペリメントを見つけます。ノートブックと同じ名前で、この場合は「feature-store-with-uc-basic-example」となります。
実験名をクリックして実験ページを表示します。fe.log_modelを呼び出したときに作成されたパッケージ化されたUnity CatalogのFeature Engineeringモデルが、このページのArtifactsセクションに表示されます。このモデルはバッチスコアリングに使用できます。

モデルはUnity Catalogにも自動的に登録されます。
バッチスコアリング
score_batchを使用して、UCモデルのパッケージ化されたFeature Engineeringを新しいデータに適用して推論を行います。入力データには、主キー列wine_idとリアルタイムフィーチャーreal_time_measurementのみが必要です。モデルは他のすべてのフィーチャー値をフィーチャーテーブルから自動的に検索します。
# ヘルパー関数
def get_latest_model_version(model_name):
latest_version = 1
mlflow_client = MlflowClient()
for mv in mlflow_client.search_model_versions(f"name='{model_name}'"):
version_int = int(mv.version)
if version_int > latest_version:
latest_version = version_int
return latest_version
## 簡単のため、この例では推論データを予測の入力データとして使用します
batch_input_df = inference_data_df.drop("quality") # ラベル列を削除
latest_model_version = get_latest_model_version(model_name)
predictions_df = fe.score_batch(model_uri=f"models:/{model_name}/{latest_model_version}", df=batch_input_df)
display(predictions_df["wine_id", "prediction"])

特徴量テーブルの修正
データフレームに新しい特徴量を追加したと仮定します。fe.write_table を mode="merge" と共に使用して特徴量テーブルを更新できます。
## 特徴量を含むデータフレームを修正
so2_cols = ["free_sulfur_dioxide", "total_sulfur_dioxide"]
new_features_df = (features_df.withColumn("average_so2", expr("+".join(so2_cols)) / 2))
display(new_features_df)
新たな特徴量の列average_so2が追加されています。

mode="merge" を使用して fe.write_table で特徴テーブルを更新します。
fe.write_table(
name=table_name,
df=new_features_df,
mode="merge"
)
特徴量テーブルから特徴量データを読み取るには、fe.read_table() を使用します。
# 特徴量テーブルの最新バージョンを表示
# 現在のバージョンで削除された特徴量は、値がnullとしてテーブルに表示されることに注意してください。
display(fe.read_table(name=table_name))

更新された特徴量テーブルを使用して新しいモデルバージョンをトレーニングする
def load_data(table_name, lookup_key):
model_feature_lookups = [FeatureLookup(table_name=table_name, lookup_key=lookup_key)]
# fe.create_training_setは、inference_data_dfから一致するキーを持つmodel_feature_lookupsの特徴量を検索します
training_set = fe.create_training_set(df=inference_data_df, feature_lookups=model_feature_lookups, label="quality", exclude_columns="wine_id")
training_pd = training_set.load_df().toPandas()
# 訓練データセットとテストデータセットを作成
X = training_pd.drop("quality", axis=1)
y = training_pd["quality"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
return X_train, X_test, y_train, y_test, training_set
X_train, X_test, y_train, y_test, training_set = load_data(table_name, "wine_id")
X_train.head()

指定された key を使用して特徴量を検索するトレーニングデータセットを作成します。
def train_model(X_train, X_test, y_train, y_test, training_set, fe):
## モデルのフィットとログ
with mlflow.start_run() as run:
rf = RandomForestRegressor(max_depth=3, n_estimators=20, random_state=42)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
mlflow.log_metric("test_mse", mean_squared_error(y_test, y_pred))
mlflow.log_metric("test_r2_score", r2_score(y_test, y_pred))
fe.log_model(
model=rf,
artifact_path="feature-store-model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name=model_name,
)
train_model(X_train, X_test, y_train, y_test, training_set, fe)
登録された MLflow モデルの最新バージョンを score_batch を使用して特徴量に適用します。
## 簡単のため、この例ではinference_data_dfを予測の入力データとして使用します
batch_input_df = inference_data_df.drop("quality") # ラベル列を削除
latest_model_version = get_latest_model_version(model_name)
predictions_df = fe.score_batch(model_uri=f"models:/{model_name}/{latest_model_version}", df=batch_input_df)
display(predictions_df["wine_id","prediction"])

特徴量テーブルの権限を管理し、削除する
- Unity Catalog の特徴量テーブルへのアクセス権を管理するには、カタログエクスプローラーのテーブル詳細ページにある 権限 ボタンを使用します。
- Unity Catalog の特徴量テーブルを削除するには、カタログエクスプローラーのテーブル詳細ページにあるケバブメニューをクリックし、削除 を選択します。UI を使用して Unity Catalog の特徴量テーブルを削除すると、対応する Delta テーブルも削除されます。
特徴量テーブルのリネージ
上記APIを通じてトレーニングされたモデルには特徴量テーブルとのリネージが記録されます。

こちらではさらに高度な例をウォークスルーしています。