バッチ推論感情抽出デモ
このノートブックでは、金融Twitterデータから感情を抽出するためのエンドツーエンドのバッチ推論ソリューションを紹介します。ノートブックでは以下をカバーします:
- 環境、関連変数、および基礎となるUCデータの設定
- 最適化されたバッチ推論パフォーマンスのためのプロビジョンドスループット(PT)エンドポイントの設定
-
ai_queryを使用したプロンプトのみのバッチ推論クエリの実行 - 構造化された出力とバッチ推論を組み合わせて、より信頼性の高い出力を生成
環境変数の設定
!pip install transformers datasets mlflow
dbutils.library.restartPython()
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
user_email = w.current_user.me().display_name
username = user_email.split("@")[0]
default_schema_name = username.replace(" ", "_").lower()
dbutils.widgets.text("model_uc_path", "system.ai.meta_llama_v3_1_8b_instruct", "Model UC Path")
dbutils.widgets.text("endpoint_name", "llama_batch_inference", "Endpoint Name")
dbutils.widgets.text("catalog_name", "users", "Data UC Catalog")
dbutils.widgets.text("schema_name", default_schema_name, "Data UC Schema")
dbutils.widgets.text("table_name", "batch_sentiment_data", "Data UC Table")
catalog_name = dbutils.widgets.get("catalog_name")
schema_name = dbutils.widgets.get("schema_name")
table_name = dbutils.widgets.get("table_name")

データの設定
オープンソースのHuggingface金融ニュースデータセットを使用して、企業の感情を分類します。
from datasets import load_dataset
dataset = load_dataset("zeroshot/twitter-financial-news-sentiment", cache_dir=None)
train = dataset['train'].to_pandas()
validation = dataset['validation'].to_pandas()
validation
train_spark = spark.createDataFrame(train)
validation_spark = spark.createDataFrame(validation)
train_spark.write.mode('overwrite').saveAsTable(".".join([catalog_name, schema_name, f"{table_name}_train"]))
validation_spark.write.mode('overwrite').saveAsTable(".".join([catalog_name, schema_name, f"{table_name}_val"]))
display(
spark.sql(
f"SELECT * FROM {catalog_name}.{schema_name}.{table_name}_train LIMIT 10"
)
)

最小帯域でPT(Provisioned Throughput)エンドポイントを設定
これにより、バッチ推論に使用できるPTエンドポイントがワークスペースにデプロイされます。
import mlflow
import requests
import json
import time
from mlflow.utils.databricks_utils import get_databricks_host_creds, get_workspace_url
host = get_databricks_host_creds("databricks").host
assert host, "ホストURLを取得できません"
def monitor_endpoint(name):
# エンドポイントが準備完了になるまで監視します。これには数分かかる場合があります。
start_time = time.time()
timeout = 2 * 60 * 60
while True:
response = requests.get(
url=f"{host}/api/2.0/serving-endpoints/{name}", headers=getHeaders()
)
if response.status_code == 404:
raise Exception(f"エンドポイント {name} が見つかりません")
elif response.status_code != 200:
print(f"リクエストが失敗しました。ステータス: {response.status_code}, {response.text}")
else:
serving_endpoint = response.json()
state = serving_endpoint["state"]
if state["ready"] == "READY" and state["config_update"] == "NOT_UPDATING":
print(f"エンドポイント {name} は準備完了です")
break
else:
print(f"エンドポイント {name} は準備ができていません。状態: {state}")
time.sleep(30)
if time.time() - start_time > timeout:
raise Exception(f"エンドポイント {name} の作成がタイムアウトしました")
def getHeaders():
credentials = get_databricks_host_creds("databricks")
return {
"Authorization": f"Bearer {credentials.token}",
"Content-Type": "application/json",
}
def get_model_version(model_name):
model_versions = requests.get(
url=f"{host}/api/2.1/unity-catalog/models/{model_name}/versions",
headers=getHeaders(),
).json()
model_version = max(version['version'] for version in model_versions['model_versions'])
return model_version
def get_chunk_size(model_name, model_version):
optimizable_info = requests.get(
url=f"{host}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=getHeaders(),
).json()
if "optimizable" not in optimizable_info or not optimizable_info["optimizable"]:
raise ValueError(
f"モデル {model_name} バージョン {model_version} は存在しないか、プロビジョニングスループットの対象ではありません"
)
return optimizable_info["throughput_chunk_size"]
def create_endpoint(name, model_name, ptu):
model_version = get_model_version(model_name)
pt = ptu * get_chunk_size(model_name, model_version)
data = {
"name": name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": pt,
"max_provisioned_throughput": pt,
}
]
},
}
response = requests.post(
url=f"{host}/api/2.0/serving-endpoints", json=data, headers=getHeaders()
)
print(json.dumps(response.json(), indent=4))
return model_version, pt
num_ptus = 1
endpoint_name = dbutils.widgets.get("endpoint_name")
model_uc_path = dbutils.widgets.get("model_uc_path")
model_version, pt = create_endpoint(endpoint_name, model_uc_path, num_ptus)
monitor_endpoint(endpoint_name)
print(f"プロビジョニングされたスループットエンドポイントが作成されました:")
print(f"エンドポイント: {endpoint_name}, モデル: {model_uc_path}")
print(f"同時実行数: {pt} ({num_ptus} PTU)")
少し待つとエンドポイントがデプロイされます。
{
"name": "taka_llama_batch_inference",
"creator": "takaaki.yayoi@databricks.com",
"creation_timestamp": 1738743336000,
"last_updated_timestamp": 1738743336000,
"state": {
"ready": "NOT_READY",
"config_update": "IN_PROGRESS",
"suspend": "NOT_SUSPENDED"
},
"pending_config": {
"served_entities": [
{
"name": "meta_llama_v3_1_8b_instruct-3",
"entity_name": "system.ai.meta_llama_v3_1_8b_instruct",
"entity_version": "3",
"min_provisioned_throughput": 19000,
"max_provisioned_throughput": 19000,
"workload_size": "Small",
"workload_type": "GPU_XLARGE_8",
"min_dbus": 106.0,
"max_dbus": 106.0,
"state": {
"deployment": "DEPLOYMENT_CREATING",
"deployment_state_message": "Creating resources for served entity."
},
"creator": "takaaki.yayoi@databricks.com",
"creation_timestamp": 1738743336000
}
],
"served_models": [
{
"name": "meta_llama_v3_1_8b_instruct-3",
"min_provisioned_throughput": 19000,
"max_provisioned_throughput": 19000,
"workload_size": "Small",
"workload_type": "GPU_XLARGE_8",
"model_name": "system.ai.meta_llama_v3_1_8b_instruct",
"model_version": "3",
"min_dbus": 106.0,
"max_dbus": 106.0,
"state": {
"deployment": "DEPLOYMENT_CREATING",
"deployment_state_message": "Creating resources for served entity."
},
"creator": "takaaki.yayoi@databricks.com",
"creation_timestamp": 1738743336000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "meta_llama_v3_1_8b_instruct-3",
"traffic_percentage": 100,
"served_entity_name": "meta_llama_v3_1_8b_instruct-3"
}
]
},
"config_version": 1,
"start_time": 1738743336000
},
"id": "2938319d953c40f5919f2f3bf944a68a",
"permission_level": "CAN_MANAGE",
"route_optimized": false,
"creator_display_name": "Takaaki Yayoi",
"creator_kind": "User",
"effective_budget_policy_id": "8ec51ab9-cc71-4f24-a572-a82227251d5a",
"resource_credential_strategy": "EMBEDDED_CREDENTIALS"
}
エンドポイント taka_llama_batch_inference は準備ができていません。状態: {'ready': 'NOT_READY', 'config_update': 'IN_PROGRESS', 'suspend': 'NOT_SUSPENDED'}
エンドポイント taka_llama_batch_inference は準備ができていません。状態: {'ready': 'NOT_READY', 'config_update': 'IN_PROGRESS', 'suspend': 'NOT_SUSPENDED'}
エンドポイント taka_llama_batch_inference は準備ができていません。状態: {'ready': 'NOT_READY', 'config_update': 'IN_PROGRESS', 'suspend': 'NOT_SUSPENDED'}
エンドポイント taka_llama_batch_inference は準備完了です
プロビジョニングされたスループットエンドポイントが作成されました:
エンドポイント: taka_llama_batch_inference, モデル: system.ai.meta_llama_v3_1_8b_instruct
同時実行数: 19000 (1 PTU)

プロンプトのみを使用して ai_query でバッチ推論を使用
予測結果は0、1、または2のみであるべきです。プロンプトで出力を保証できますか?
検証セット (2.4K行)
import time
# 19000 トークン/秒のエンドポイント - 高スループットのエンドポイントで増加可能
start_time = time.time()
command = f"""
SELECT text,
ai_query(
\'{endpoint_name}\', --エンドポイント名
CONCAT('金融ニュース関連のツイートの感情を分類します。0は弱気、1は強気、2は中立を表します。番号だけを示してください。', text)
) AS sentiment_pred,
label as sentiment_gt
FROM {catalog_name}.{schema_name}.{table_name}_val
"""
result = spark.sql(command)
display(result)
end_time = time.time()
execution_time = end_time - start_time
print(f"実行時間: {execution_time} 秒")
実行時間: 12.340470314025879 秒

適切なフォーマットで推論が生成されましたか?
result_baseline_pd = result.toPandas()
result_baseline_pd.sentiment_pred.value_counts()
1 2009
2 290
0 81
ツイートの内容がわかりません。 1
1 1 1 1 1
1\n1\n2 1
1 1 2 2 1
ツイートの感情を分類するには、特定のツイートのテキストが必要です。ただし、一般的な金融ニュース関連のツイートの感情を予測するために、以下の分類を示します。\n\n$SPY (S&P 500指数): \n- 0: 市況が下落した場合\n- 1: 市況が上昇した場合\n- 2: 市況が安定した場合\n\n$XLF (金融部門): \n- 0: 金融部門の業績が悪化した場合\n 1
A: 1\nE: 0\nM: 2\nD: 1 1
BNTC: 1 1
1 2 1 2 1 1
Name: sentiment_pred, dtype: int64
result_baseline_pd.sentiment_gt.value_counts()
2 1566
1 475
0 347
Name: sentiment_gt, dtype: int64
正解データと比較して推論はどれだけ正確ですか?
confusion_matrix = result_baseline_pd.pivot_table(index='sentiment_gt', columns='sentiment_pred', aggfunc='size', fill_value=0)
display(confusion_matrix)
出力が構造化されていないので、不適切にフォーマットされた応答がいくつかあります。結果として、適切に分類が行われていません。

バッチ推論で構造化出力を使用
プロンプトに頼るのではなく、フォーマット制約を強制できます。
response_schema = """
{
"type": "json_schema",
"json_schema":
{
"name": "sentiment_score",
"schema":
{
"type": "object",
"properties":
{
"sentiment": { "type": "string" ,
"enum": ["0", "1", "2"]}
}
},
"strict": true
}
}
"""
import time
start_time = time.time()
result_structured = spark.sql(
f"""
SELECT text,
ai_query(
\'{endpoint_name}\', --endpoint name
CONCAT('金融ニュース関連のツイートの感情を分類します。0は弱気、1は強気、2は中立を表します。番号だけを示してください。', text),
responseFormat => '{response_schema}'
) AS sentiment_pred,
label as sentiment_gt,
CAST(get_json_object(sentiment_pred, '$.sentiment') AS LONG) AS sentiment_pred_value
FROM {catalog_name}.{schema_name}.{table_name}_val
"""
)
display(result_structured)
end_time = time.time()
execution_time = end_time - start_time
print(f"Execution time: {execution_time} seconds")

Execution time: 20.854150533676147 seconds
構造化出力を用いることで、推論は適切なフォーマットで生成されましたか?
result_structured_pd = result_structured.toPandas()
result_structured_pd.sentiment_pred_value.value_counts()
2 1313
1 722
0 353
Name: sentiment_pred_value, dtype: int64
result_structured_pd.sentiment_gt.value_counts()
2 1566
1 475
0 347
Name: sentiment_gt, dtype: int64
正解データと比較して推論はどれだけ正確ですか?
confusion_matrix_structured = result_structured_pd.pivot_table(index='sentiment_gt', columns='sentiment_pred_value', aggfunc='size', fill_value=0)
display(confusion_matrix_structured)
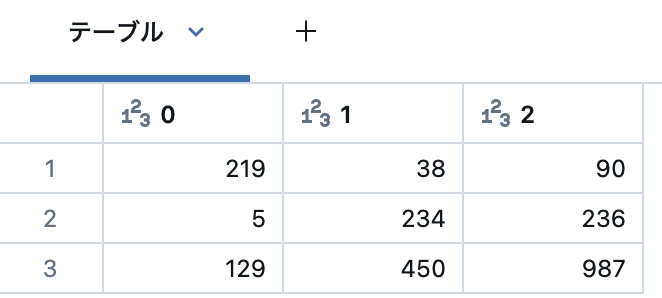
構造化出力は許可された結果への準拠を保証します。実行時間は少し長くなるだけです!