こちらの記事で発表されました。
こちらのデータセットとなります。
我々における最初のボリュームのリスティングとなる、Shutterstockの画像のDatabricksマーケットプレースへの提供によって膨大なコレクションを提供する革新的なコラボレーションを発表できることを嬉しく思っています。Shutterstockの5.5億の画像ライブラリから提供された1,000の画像と関連メタデータから構成される無料のサンプルデータセットは即座のアクセスで利用できるようになっています。
Shutterstockで実現できそうなユースケースはどのようなものでしょうか?店舗に50,000の商品を持ち、毎年の回転率が20%である架空の小売業者Berkeley FoodMartを想像してみましょう。彼らはすべての商品の説明文を手動でメンテナンスすることに苦戦しています。今では、新たな商品の画像からメタデータとキーワードを生成するimage-to-textモデルを構築するために、Shutterstockのデータセットと堅牢なメタデータを活用することができます。Shutterstockの画像データセットは、Berkeley FoodMartがきれいなデータの源泉を用いて自身のモデルを安全にキュレーションすることができます。ユーザーフレンドリーな商品説明分を生成するためにLLMを用いてこれらのキーワードを活用することもできるでしょう。
データへのアクセス
マーケットプレースからアクセスし、即時アクセス権を取得をクリックします。
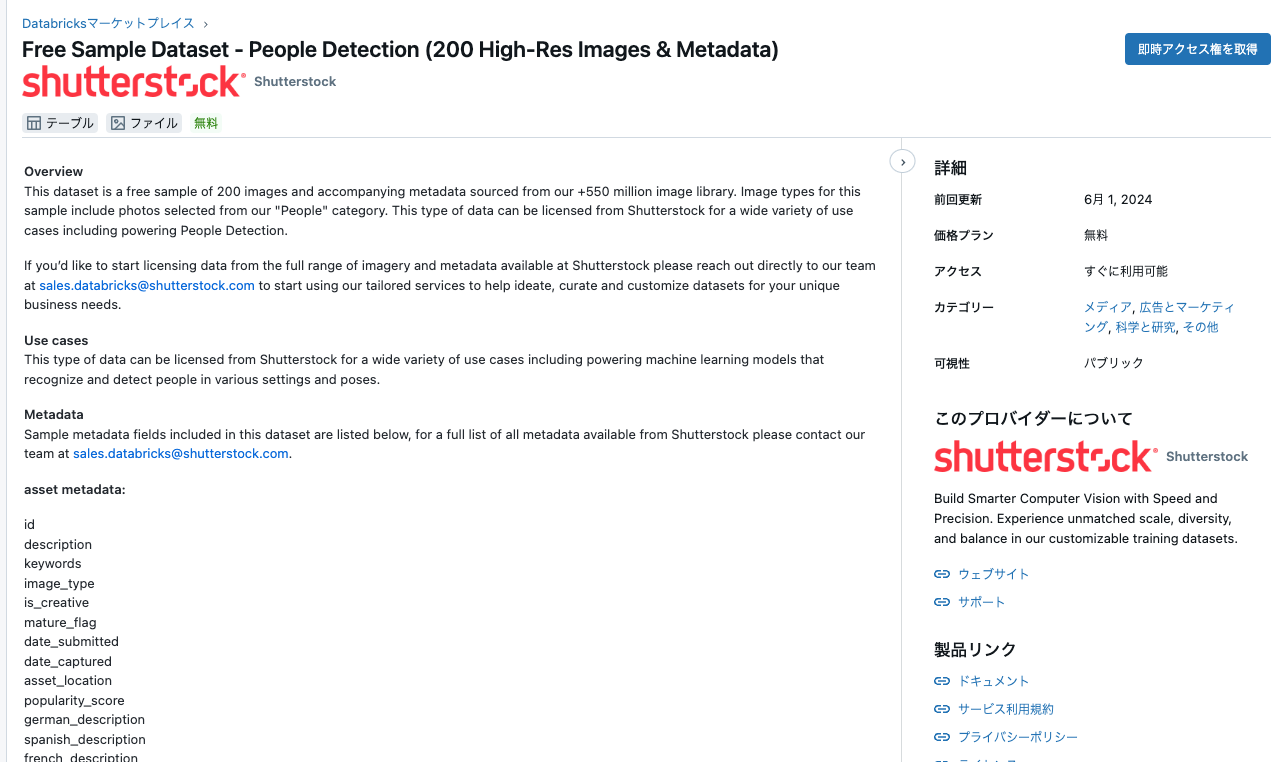
データセット(テーブル)とファイル(ボリューム)が含まれていることがわかります。
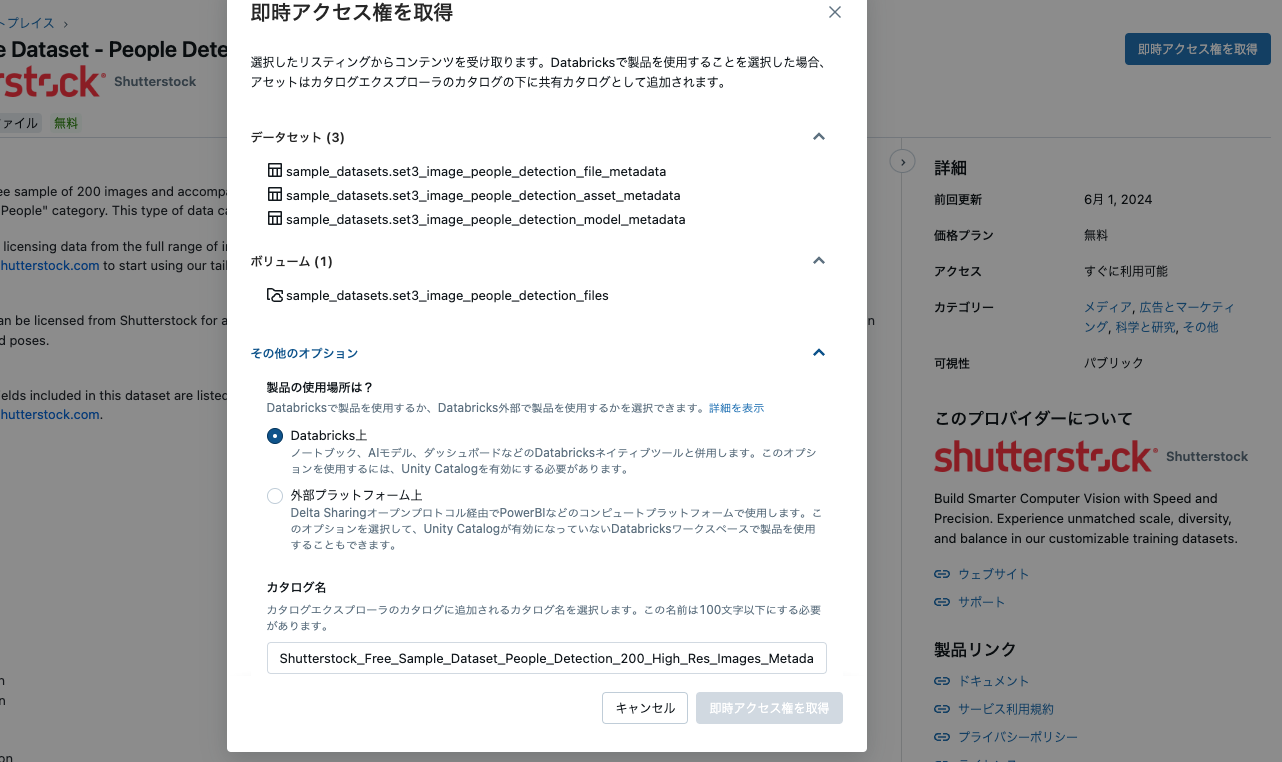
必要に応じてカタログ名を変更して即時アクセス権を取得をクリックします。
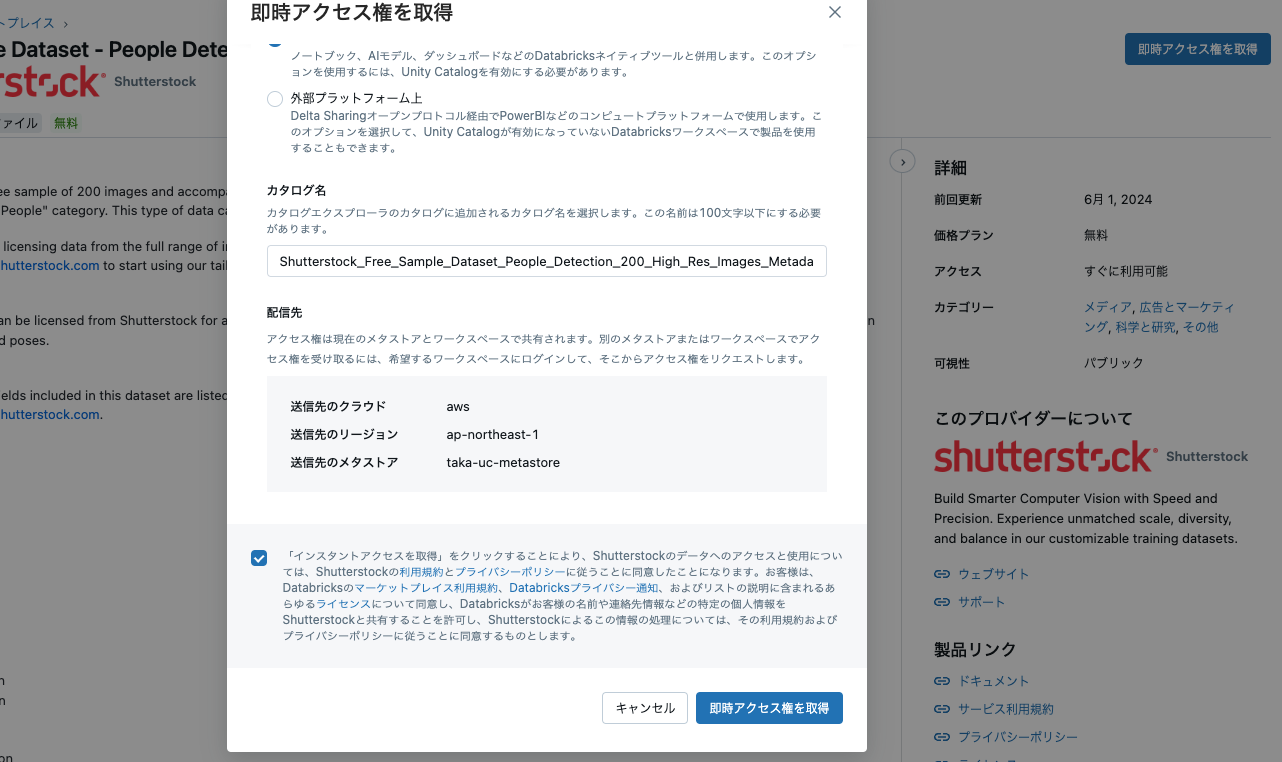
開くをクリックします。

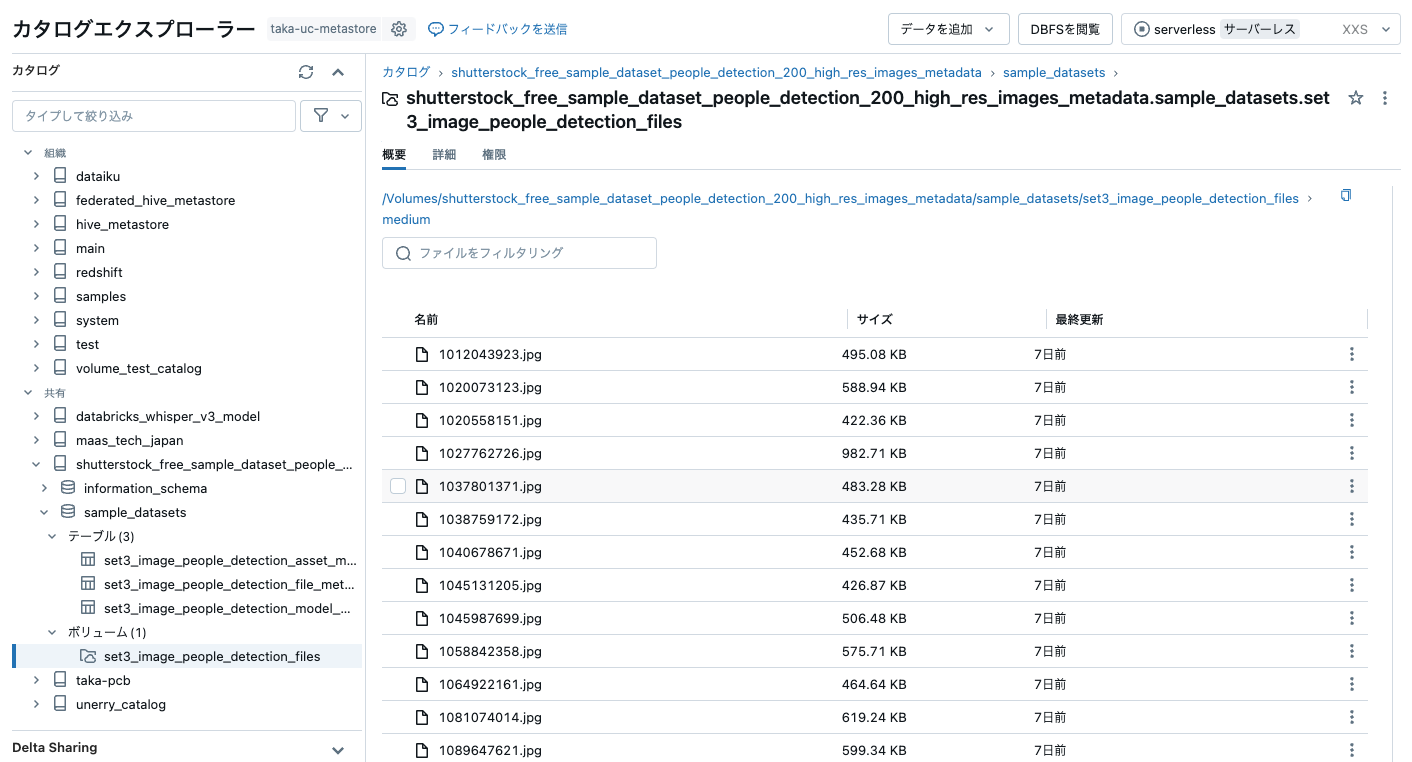
カタログとして登録されました。

画像ファイルも確認できます。
データの操作
まずはテーブルを確認します。
SELECT ASSET_ID, JAPANESE_DESCRIPTION FROM set3_image_people_detection_asset_metadata;
日本語の説明文もあります。ASSET_IDがキーですね。

ファイル名の拡張子を除外したものもASSET_IDのようです。こちらを参考にファイルパスからASSET_IDを抽出します。
from pyspark.sql.functions import input_file_name, regexp_extract
# 画像データソースを用いて画像データソースを作成します
image_df = spark.read.format("image").load(
"/Volumes/shutterstock_free_sample_dataset_people_detection_200_high_res_images_metadata/sample_datasets/set3_image_people_detection_files/medium/"
)
# 拡張子を除くファイル名を抽出
image_df = image_df.withColumn("sourcefile", input_file_name())
regex_str = "([^\/]+[^\/]+).jpg$"
image_df = image_df.withColumn("ASSET_ID", regexp_extract("sourcefile", regex_str, 1))
# データフレームを表示します
display(image_df)

SQLを使うので一次ビューとして登録します。
image_df.createOrReplaceTempView("image_df")
メタデータのテーブルとjoinします。
%sql
select
image_df.ASSET_ID,
image_df.image,
meta.JAPANESE_DESCRIPTION
from
image_df
INNER join shutterstock_free_sample_dataset_people_detection_200_high_res_images_metadata.sample_datasets.set3_image_people_detection_asset_metadata meta ON image_df.ASSET_ID = meta.ASSET_ID
LIMIT
10;

set3_image_people_detection_model_metadataには年代のデータも含まれているので、いろいろなユースケースで活用できそうです。