S3ではオブジェクトにメタデータを付与することができます。
今回はDLTのパイプラインでこのメタデータを操作してみます。
メタデータの付与
Python
import boto3
bucketname = 'ty-db-data-bucket'
key = 'dlt_data/metadata.jpg'
s3 = boto3.resource('s3', aws_access_key_id='<アクセスキーID>', aws_secret_access_key='<シークレットアクセスキー>')
s3_client = s3.meta.client
with open(filepath, 'rb') as body:
response_put = s3_client.put_object(
Bucket=bucketname,
Body=body,
Key=key,
ServerSideEncryption='AES256',
Metadata={
'test': 'test metadata'
}
)
print(response_put)
メタデータを確認します。
Python
response_get = s3_client.get_object(
Bucket=bucketname,
Key=key
)
metadata = response_get['Metadata']
print(metadata)
{'test': 'test metadata'}
DLTパイプラインの構築
シンプルな1つのテーブルのパイプラインを作成します。
Python
import dlt
import pyspark.sql.functions as F
from pyspark.sql.functions import lit
import boto3
# S3バケット
bucketname = 'ty-db-data-bucket'
メタデータを取り出すUDFを定義します。アクセスキー以外の方法を使った方がいいとは思っていますが、一旦こちらで。
Python
def get_bronze_meta_json(path: str) -> str:
# AWSキーを用いたboto3の設定
s3 = boto3.resource('s3', aws_access_key_id='<アクセスキーID>', aws_secret_access_key='<シークレットアクセスキー>')
s3_client = s3.meta.client
# メタデータの取得
response_get = s3_client.get_object(
Bucket=bucketname,
Key=key
)
# リテラルを返します
metadata = response_get['Metadata']
return lit(metadata['test'])
Auto Loaderで読み込んだデータにUDFを適用します。
Python
@dlt.table(name="recordings_bronze_w_metadata")
def recordings_bronze_w_metadata():
df = (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "binaryFile")
.load("dbfs:/mnt/dlt_data/dlt_data/"))
df = df.withColumn("json_meta", get_bronze_meta_json(F.col("path")))
return df
パイプラインの実行
1行のみの処理ですが、うまく動きました。
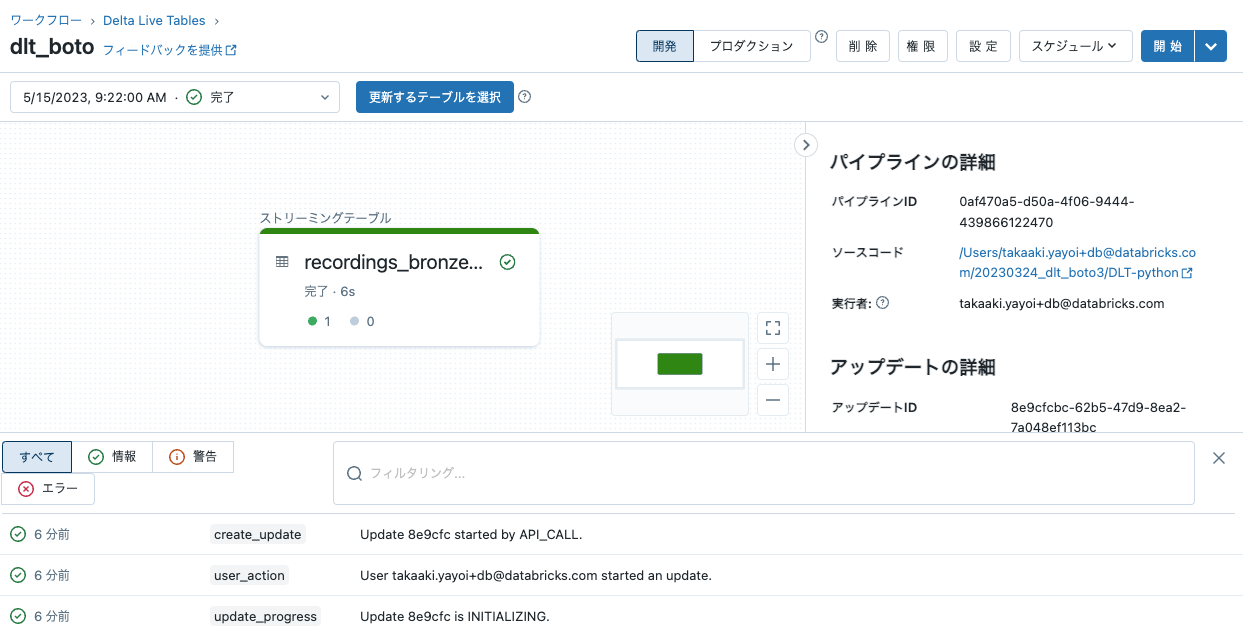
DLTの設定でターゲットスキーマを指定しているので、結果がテーブルに格納されています。結果のテーブルも確認します。
SQL
SELECT path,json_meta FROM recordings_bronze_w_metadata

ちゃんとS3のメタデータが取得できています!