Introducing Ingestion Time Clustering with DBR 11.2 - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
すぐに19倍のクエリーパフォーマンスを体験いただけます
Databricksのお客様は、大量の時系列ベースのファクトデータをDelta Lakeを用いてDatabricksレイクハウスプラットフォームで毎日エクサバイト以上のデータを処理しています。このように大規模のデータに対しては、お客様は自身のテーブルの読み書き性能を最適化する必要に迫られ、通常はテーブルのパーティショニングやOPTIMIZE ZORDER BYによって最適化が行われています。これらの最適化によって、データのクラスタリングやデータのスキッピングを有効にすることで、データを効率的に取得、更新できる様にテーブルの構成を変更します。効果的ではありますが、これらのテクニックはテーブルに対して最適な読み込みクエリーパフォーマンスを維持するために、ユーザーは膨大な労力を必要とします。さらに、データの再書き込みを行うことで追加の処理コストを発生させます。
我々Databricksにおいては、キーとなるゴールの一つが、追加の設定や最適化を行うことなしに、すぐに業界最高のクエリー性能をお客様に提供することとなっています。さまざまなユースケースを通じて、Databricksはベストな読み書きクエリーパフォーマンスの維持に必要なユーザーのアクションと設定を削減したいと考えています。
お客様がすぐに最適なクエリーパフォーマンスで時系列のファクトテーブルを活用できる様にするために、取り込み時間クラスタリング(Ingestion Time Clustering) を導入できることを嬉しく思っています。取り込み時間クラスタリングは、データ取り込みを行う時間に基づいた自然なクラスタリングを可能にするDatabricksの書き込みの最適化機能です。これを行うことで、時系列ファクトテーブルのレイアウトを最適化するためにお客様は作業することなしに、すぐに素晴らしいデータスキッピングを活用できる様になります。本書では、Deltaにおけるデータクラスタリングに関連する課題にディープダイブし、取り込み時間クラスタリングでどの様に問題を解決するのか、取り込み時間クラスタリングされたテーブルに対する現実世界のクエリーパフォーマンスの結果を説明します。
データクラスタリングの課題
現時点では、お客様は優れたパフォーマンスのためにデータレイアウトを最適化するために2つのパワフルなテクニックを利用することができます。パーティショニングとz-orderingです。データレイアウトに対するこれらの最適化技術によって、クエリーが読み込む必要があるデータ量を劇的に削減し、オペレーションごとにテーブルのスキャンに必要な時間を削減することができます。
パーティショニングやz-orderingから得られるクエリーパフォーマンスは大きなものではありますが、いくつかのお客様においては、これらの最適化技術を実装、メンテナンスすることが困難となっていました。多くのお客様は、どのカラムを使用するのか、自分達のテーブルに対してz-orderを実行するかどうか、どの程度の頻度で実行するのか、パーティショニングが有用なのか、害を及ぼすのがいつなのかに関する質問を持っています。これらのお客さまの懸念を解決するために、我々はユーザーのアクション無しにこれらの最適化技術を提供することを目指しました。
取り込み時間クラスタリング(Ingestion Time Clustering)のご紹介
我々のチームは、可能な限り多くのDeltaテーブルに適用でき、このすぐに利用できるソリューションを見つけ出すためのミッションを開始しました。そして、データ分析と証拠収集にディープダイブしました。
我々は多くのデータはインクリメンタルに取り込まれ、多くの場合時間でソートされていることに気づきました。例えば、日次ベースでDelta Lake注文データを時系列順で取り込むオンラインストア企業をイメージしてみましょう。これは、パーティショニングされたテーブルの51%が日付/時間でパーティショニングされているという事実によって確認されており、z-orderingに関しても同様です。さらに、Databricksのクエリーの2/3以上で、述語やjoinのキーとして日付/時刻を使用していることに気づきました。

Deltaにおけるパーティショニングやz-orderingでは日付/時間が好まれます
この分析に基づいて、この最もシンプルなソリューションは多くの場合適用でき、最も効果的であることがわかりました。デフォルトでは、すべてのテーブルに取り込まれたデータの順序に基づいて、シンプルにデータをクラスタリングすることができます。これは素晴らしいソリューションではありますが、MERGE、DELETEのようなデータ操作コマンド、OPTIMIZEのようなコンパクションのコマンドを使用することで、時間が経過するごとにこのクラスタリングが失われることに気づきました。このクラスタリングの喪失によって、お客様は良いクラスタリングを維持し、優れたクエリーパフォーマンスを保持するために、定期的にz-orderを実行する必要があります。
この課題を解決するために、我々はDeltaテーブルに対する新たな書き込み最適化技術である取り込み時間クラスタリングを導入することを決定しました。取り込み時間クラスタリングは、パーティショニングやz-orderingを使っているお客さまの多くの課題に対応します。これはすぐに動作するものであり、日付/時間の述語を用いる際のクエリーパフォーマンスを高速にするために、自然にクラスタリングされたテーブルを維持するためにユーザーのアクションは不要です。
取り込み時間クラスタリングとは?
それでは取り込み時間クラスタリングとは何でしょうか?取り込み時間クラスタリングによって、テーブルのクラスタリングは取り込み時間によってメンテナンスされ、日付や時間でフィルタリングするクエリーにおけるデータスキッピングによって、劇的なクエリーパフォーマンスの改善を実現し、クエリーに回答するために読み込む必要があるファイルの数を劇的に削減します。
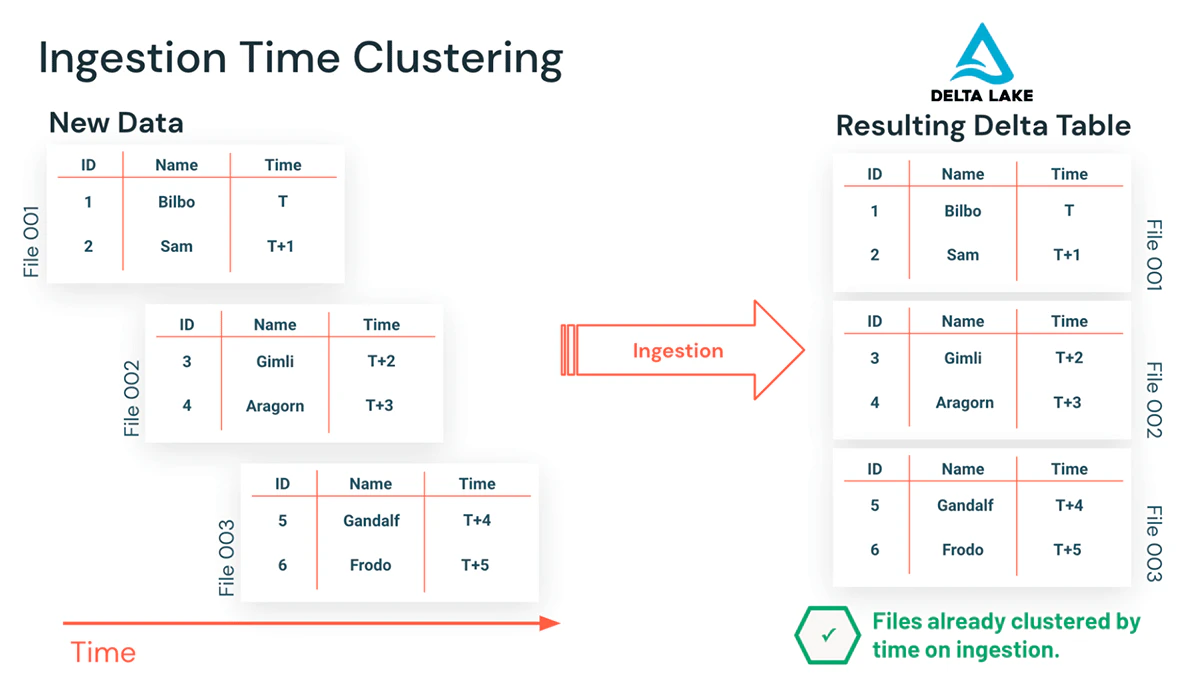
取り込み時間クラスタリングは、取り込み順でデータがメンテナンスされる様にし、クラスタリングを劇的に改善します
我々はすでに新たなローシャッフルマージ実装を用いて、Databricksランタイム10.4以降のMERGEにおけるクラスタリングの保持を改善しています。取り込み時間クラスタリングの一環として、お客様に一貫性を持って劇的なパフォーマンス改善を提供できる様に、DELETE、UPDATE、OPTIMIZEのようなデータ操作、メンテナンスコマンドでも取り込み順が維持されることを確認しました。取り込み順の保持に加え、取り込み順に関する追加作業によって、取り込み性能が劣化しないことを確実にする必要がありました。以下のベンチマークでは、現実世界のシナリオに基づく内容を正確に示しています。
大規模オンライン小売業者におけるベンチーマーク - 19倍の改善!
我々はベンチマークを行うために、大規模オンライン小売業者と取り組みを行い、彼らの分析データを表現するベンチマークを作成しました。このお客様のシナリオにおいては、売上が発生するたびに売上レコードが生成され、ファクトテーブルに取り込まれます。このテーブルに対するクエリーの多くは、多くの時間ベースの分析ワークロードでは共通のパターンにあるように、特定の時間ウィンドウで集計された売上レコードを返却します。このベンチマークでは、新規データ取り込みの時間、DELETEオペレーションの実行時間、さまざまなSELECTクエリーを計測し、取り込み時間クラスタリングにおけるクラスタリング保持機能を検証するために、全てを逐次実行しました。
クラスタリングの保持に追加の処理があるにもかかわらず、取り込み時間クラスタリングによる性能劣化は認められませんでした。一方、DELETEとSELECTクエリーでは劇的なパフォーマンス改善が認められました。取り込み時間クラスタリングなしでは、DELETE文は意図したクラスタリングを解体することで、データスキッピングの効果を削減し、ベンチマークにおける以降のSELECT文のパフォーマンスをスローダウンさせました。取り込み時間クラスタリングが保持されることで、SELECTクエリーは平均19倍パフォーマンスが改善され、オリジナルの取り込み順で意図されたクラスタリングを保持することで、テーブルのクエリーに必要な時間を劇的に削減しました。
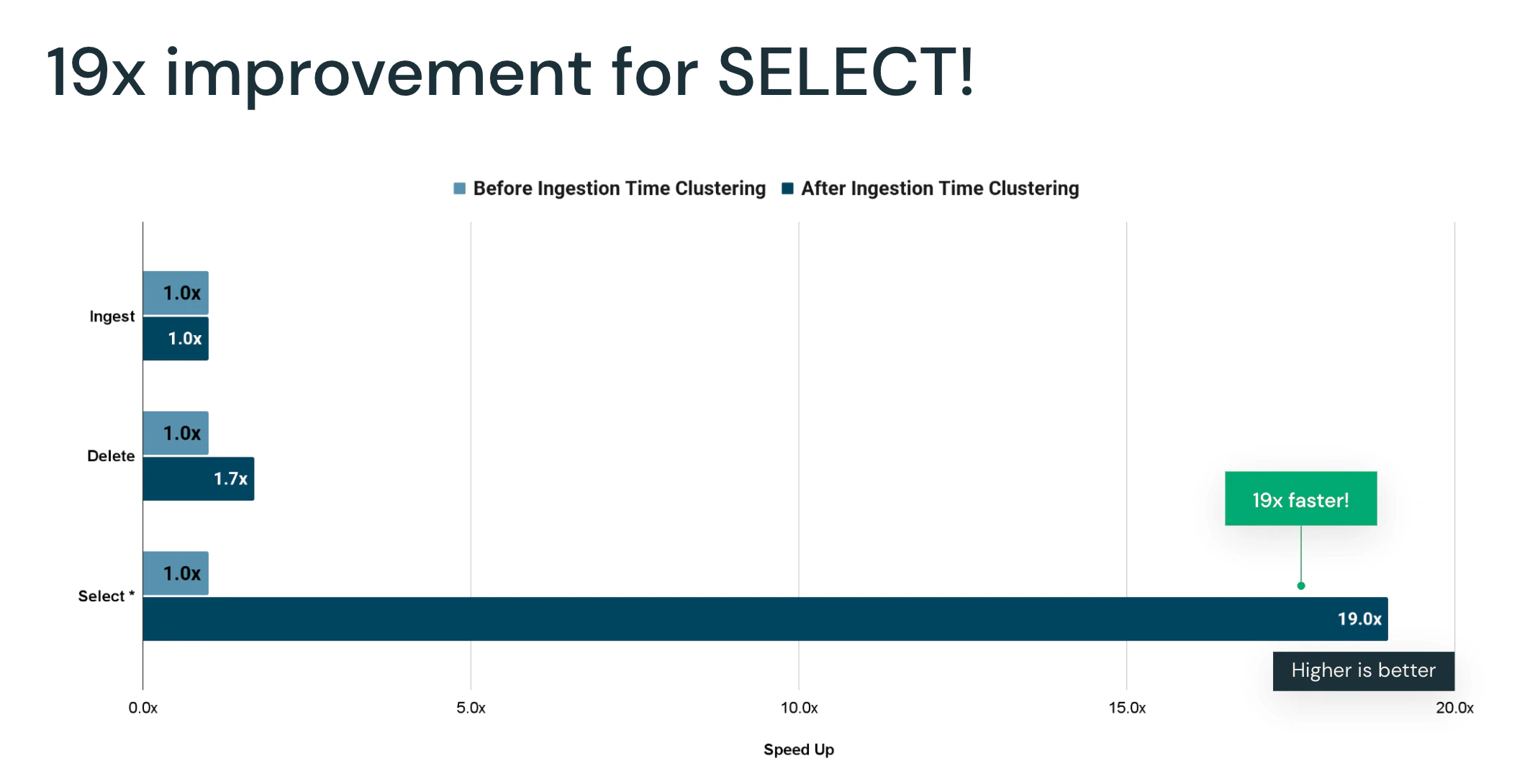
ベンチマークでは、取り込みのパフォーマンスを劣化させることなしに、クエリーパフォーマンスが劇的に改善されていることが示されています
使ってみる
我々は、取り込み時間クラスタリングによるメリットをお客様に提供できることに興奮しています。取り込み時間クラスタリングは、Databricksランタイム11.2とDatabricks SQLではデフォルトで有効化されます。パーティショニングされていないすべてのテーブルは、新規データが取り込まれた際に自動で取り込み時間クラスタリングの恩恵を受けることができます。1TB以下のテーブルについては、日付/タイムスタンプでのパーティショニングを行わず、取り込み時間クラスタリングに自動で対応させることをお勧めします。