How to optimize and increase SQL query speed on Delta Lake - The Databricks Blogの翻訳です。
データシステムにおいては、二つの由緒あるクエリー実行の高速化テクニックが存在します。より高速にデータを処理するか、不要なデータをスキップしてシンプルに少ないデータを処理するかです。このブログ記事では、Databricksランタイムでデフォルトとなっている新たなデータスキップ手法、ダイナミックファイルプルーニング(DFP)を説明します。DFPはDelta Lakeのテーブルの非パーティションカラムにおける選択的ジョインのクエリー性能を劇的に改善します。
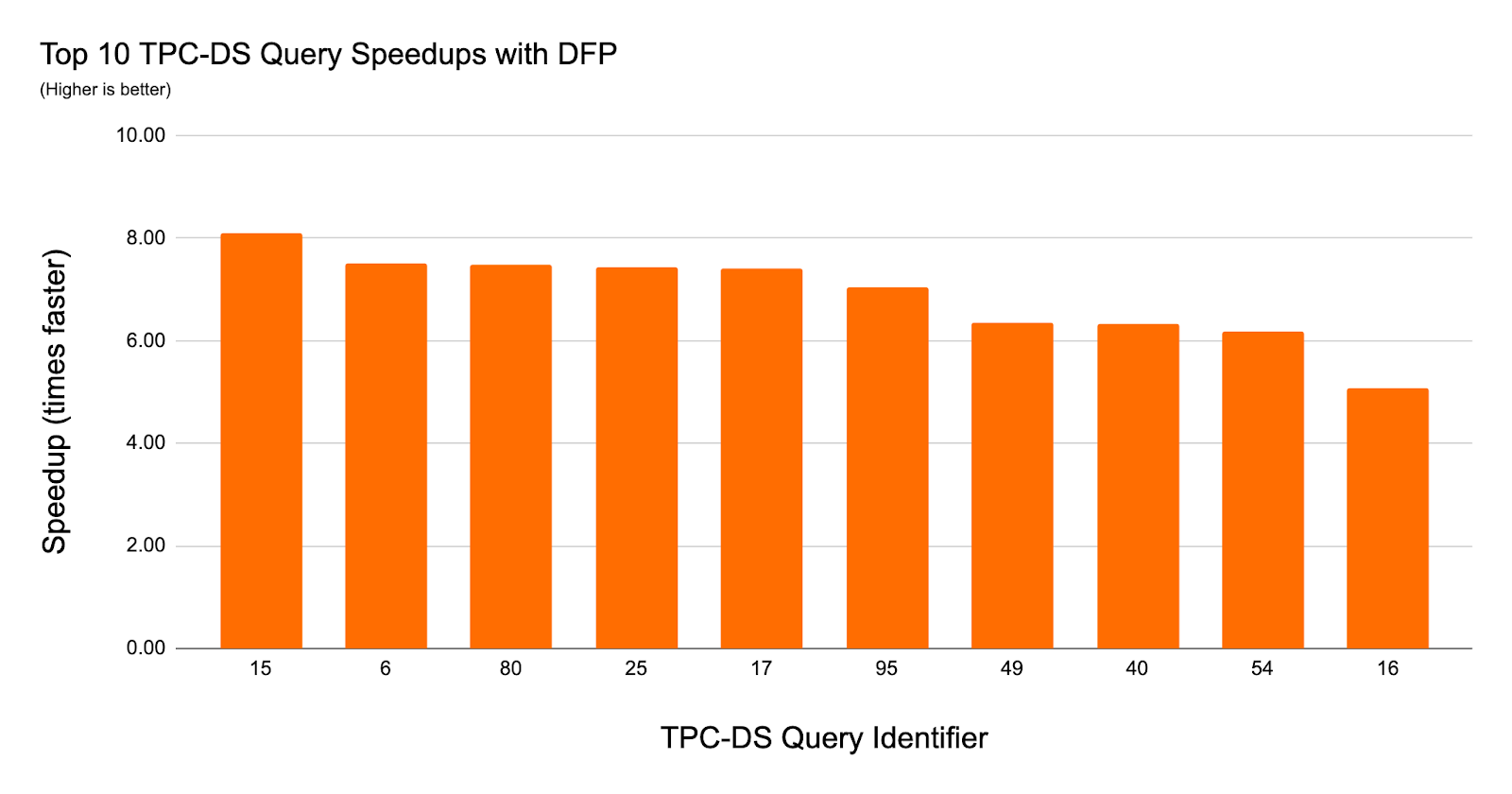
TCP-DSデータを用いたダイナミックファイルプルーニングのクエリーの実験においては、クエリー性能が8倍改善し、36のクエリーにおいては2倍以上の高速化を確認しています。
ダイナミックファイルプルーニングのメリット
テーブルにアクセスするクエリー、ジョブが大量データをスキップし、クエリーを高速化できるように、データエンジニアは大規模Delta Lakeテーブルに対するパーティション戦略を選択することが多くあります。パーティションのプルーニングは、クエリーにパーティションキーカラムに対する述語リテラルが明示的に含まれている際、クエリコンパイル時に実行される、あるいは、ダイナミックファイルプルーニングを通じて実行時にプルーニングが行われます。
Databricks Delta Lakeのパフォーマンスチューニング
パーティションの粒度でデータを除外することに加え、DatabirkcsのDelta Lakeにおいては、可能な場合には動的に不要なファイルをスキップします。これは、Delta Lakeが自身で管理するデータファイルのメタデータを自動で収集しており、データファイルにアクセスすることなしにスキップできるためです。ダイナミックファイルプルーニングが導入される前は、クエリーの述語にリテラル値が含まれる場合にのみファイルプルーニングは実行されていましたが、今はリテラルフィルターに加えジョインフィルターでもプルーニングが行われます。これは、ダイナミックファイルプルーニングによって、スタースキーマのクエリーにおいてもファイルレベルのデータスキッピングを活用できることを意味します。
| パーティション単位 | ファイル単位(Databricks Delta Lakeのみ) | |
|---|---|---|
| 静的(フィルターベース) | パーティションプルーニング | ファイルプルーニング |
| 動的(ジョインベース) | ダイナミックパーティションプルーニング | ダイナミックファイルプルーニング(New!) |
ダイナミックファイルプルーニングの動作原理
ダイナミックファイルプルーニングの詳細に入る前に、述語リテラルの場合にファイルプルーニングがどのように動作するのかを説明します。
例1 - 静的ファイルプルーニング
シンプルにするために、TCP-DSスキーマから作成した以下のクエリーを用いて、ファイルプルーニングがどのようにスキャン操作のサイズを削減するのかを説明します。
-- Q1
SELECT sum(ss_quantity)
FROM store_sales
WHERE ss_item_sk IN (40, 41, 42)
Delta Lakeはファイルごとにそれぞれのカラムの最大値と最小値を格納します。このため、ss_item_skの値がフィルターに指定された(40, 41, 42)の範囲外のファイルはすべてスキップされます。Z-Orderingのようなデータクラスタリング技術を用いることで、ファイルごとの値のレンジを短縮することができます。ファイルごとのレンジを短縮することでスキッピングの効果を高めるため、これは非常に魅力的なものです。このため、ここではss_item_skカラムによるstore_salesテーブルのZ-orderを実行します。
クエリーQ1では述語プッシュダウンが行われ、ファイルプルーニングはSCANオペレーターの一部として実行されますが、その後にマッチしない行を除外するFILTERオペレーションが続きます。
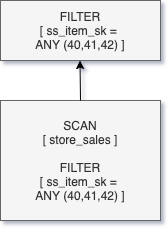
フィルターに述語リテラルが含まれている場合には、クエリーコンパイラはこれらの述語リテラルをクエリーの実行計画に埋め込みます。しかし、多くの一般的なデータウェアハウスのクエリー(例:スタースキーマのジョイン)にあるように述語がジョインの一部に指定されている場合には、他のアプローチが必要となります。このような場合、クエリーコンパイル時においては、ファクトテーブルにおけるジョインフィルターは不明となります。
例2 - DFPなしでのスタースキーマのジョイン
典型的なスタースキーマのジョインのクエリーは以下のようなものになります。
-- Q2
SELECT sum(ss_quantity)
FROM store_sales
JOIN item ON ss_item_sk = i_item_sk
WHERE i_item_id = 'AAAAAAAAICAAAAAA'
クエリーQ2はQ1と同じ結果を返しますが、述語をファクトテーブル(store_sales)ではなくディメンジョンテーブル(item)に指定しています。これは、itemテーブルにおけるSCAN、FILTERオペレーションが行われるまでss_item_skがわからないため、store_salesに対する行のフィルタリングが主にJOINオペレーションの一部として行われることを意味します。
Q2における論理的クエリー実行計画を以下に示します。
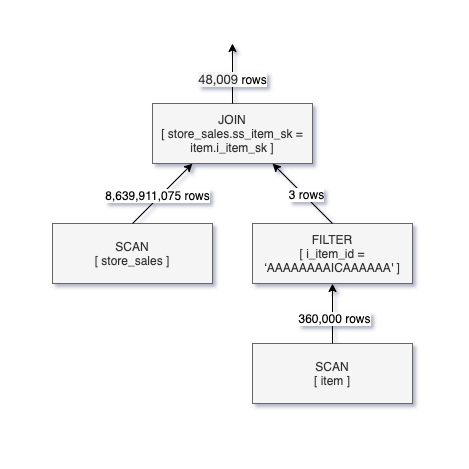
Q2のクエリープランから、store_salesテーブルからは86億レコードを読み込まなくてはいけないにもかかわらず、48,000行のみがJOINの条件に合致していることがわかります。ことことから、JOINフィルターをstore_salesのSCANにプッシュダウンする方法があればクエリーの実行時間を劇的に短縮できることがわかります。
例3 - DFPありでのスタースキーマのジョイン
Q2においてダイナミックファイルプルーニングを有効化することで、join側で動的なフィルターが生成され、store_salesに対するSCANオペレーションが引き渡されている様子を確認できます。この最適化の様子を以下の論理クエリー実行計画の図で示します。
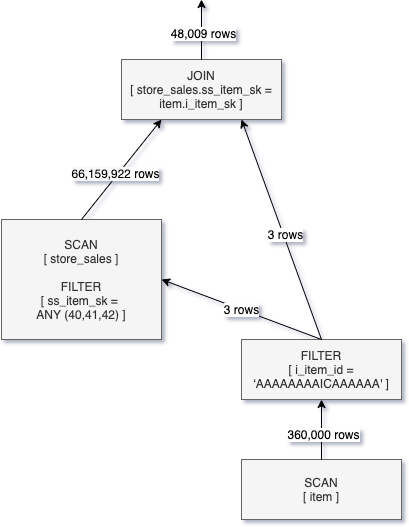
store_salesのSCANオペレーションにダイナミックファイルプルーニングを適用することで、スキャンされる行は86億から6600万に削減されました。大きな改善がなされましたが、DFPは行レベルではなくファイルレベルで操作を行うため、必要とする以上のデータを読み込まなくてはなりません。
(以下に示す)Spark UIのDAGから、SCANオペレーションをstore_salesテーブルに拡張することによるダイナミックファイルプルーニングのインパクトを観察することができます。特に、クエリーにダイナミックファイルプルーニングを適用することで入力データの99%を削減し、クエリーの実行時間を10秒から1秒以下に削減しています。

ダイナミックファイルプルーニングなしのケース
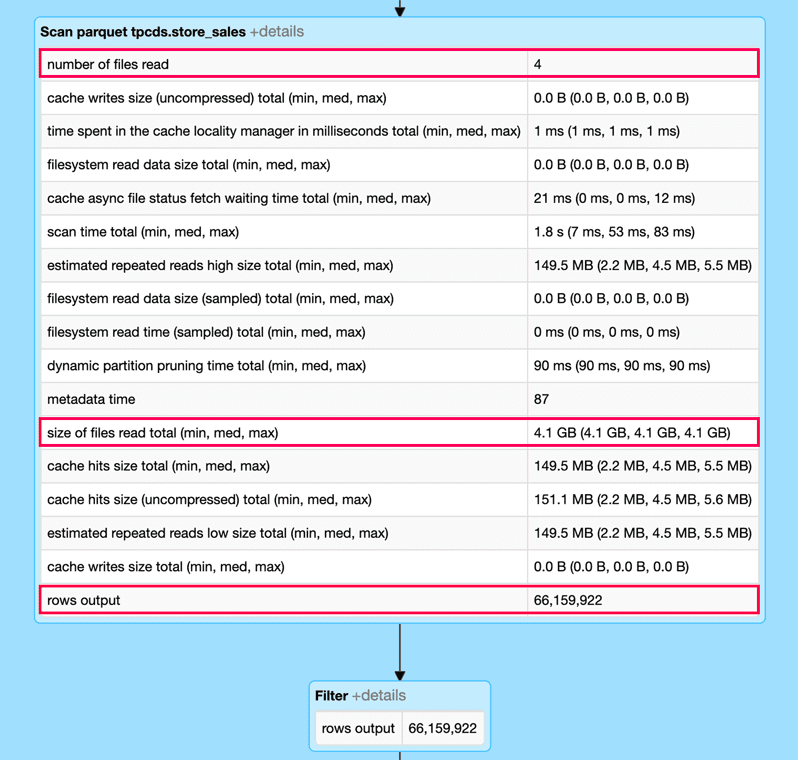
ダイナミックファイルプルーニングありのケース
ダイナミックファイルプルーニングの有効化
DFPはDatabricksランタイム6.1以降では自動的に有効化されおり、クエリーが以下の条件に合致している場合に適用されます。
- ジョインされるinnerテーブル(プローブ側)がDelta Lakeフォーマット
- ジョインがINNERあるいはLEFT-SEMI
- ジョイン戦略がBROADCAST HASH JOIN
- innerテーブルのファイル数が
spark.databricks.optimizer.deltaTableFilesより大きい
以下の設定パラメーターでDFPを制御できます。
-
spark.databricks.optimizer.dynamicFilePruning(デフォルトはtrue)によってオプティマイザーがDFPフィルターをプッシュダウンするかどうかを指定します。 -
spark.databricks.optimizer.deltaTableSizeThreshold(デフォルトは10GB)。このパラメーターは、DFPを実行するジョインのプローブ側のDelta Lakeテーブルの最小サイズを指定します。 -
spark.databricks.optimizer.deltaTableFiles(デフォルトは1000)。このパラメーターは、DFPを実行するジョインのプローブ側のDelta Lakeテーブルの最小ファイル数を指定します。
注意: この記事で報告している実験においては、store_sales のファイルが1000以下だったため、DFPを実行するためにspark.databricks.optimizer.deltaTableFilesを100に設定しています。
TCP-DSによる実験結果
SQLワークロードにおけるダイナミックファイルプルーニングのインパクトを理解するために、1TBのデータセットにおいてパーティショニングされていないスキーマに対するTCP-DSクエリーの性能を比較しました。ここでは、ジョインされるファクトテーブルの日付とアイテムキーでZ-Orderingしました。ほぼすべてのクエリーにおいてDFPは優れた性能を示しています。103クエリーのうち36クエリーにおいては、2倍以上の高速化、最大で8倍の高速化を達成しています。以下のチャートでは特に改善が著しかったトップ10を示しています。
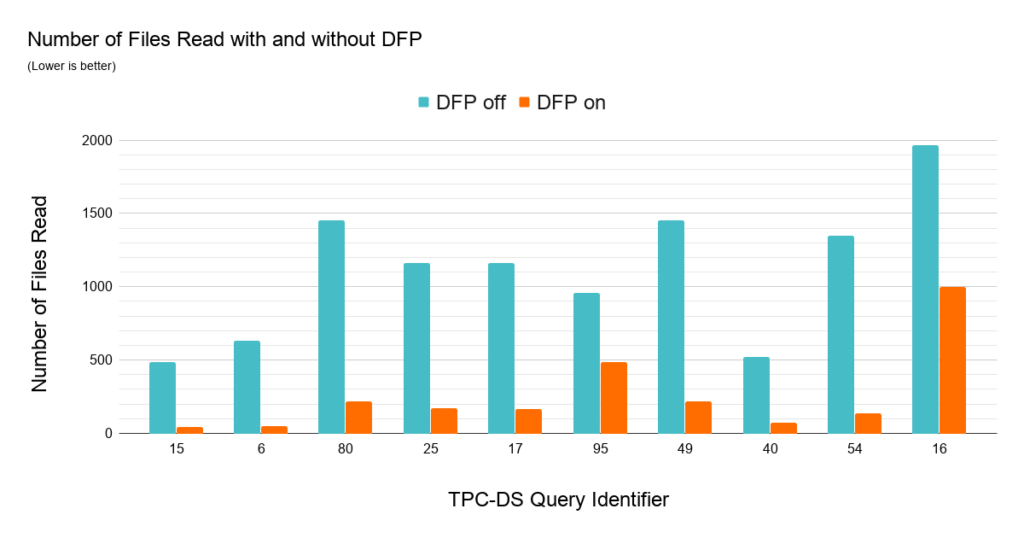
多くのTCP-DSクエリーは、DFPのインパクトを説明できる素晴らしいワークロードである、日付でフィルタリングを行う、典型的な日付のディメンジョンテーブルとファクトテーブルのスタースキーマのジョインを行います。上のチャートで説明されたデータは、なぜDFPが一連のクエリーで効果的なのかを示しています。これらにおいては、読み込むデータ量を削減することができます。それぞれのクエリーにおいて、(5年分のデータを格納する)ファクトテーブルに対するジョインフィルターの期間を30から90日に限定できています。最大3つのファクトテーブルにアクセスするこのようなワークロードにおいて、DFPは非常に魅力的なものになります。
ダイナミックファイルプルーニングを使い始めてみる
Databricksランタイムでデフォルトで有効化されている新機能のダイナミックファイルプルーニング(DFP)は、Delta Lakeにおけるクエリー性能を劇的に改善します。特にパーティショニングされていないテーブルに対してジョインを行うクエリーでは効率的です。DFPによる性能改善はデータのクラスタリングとも密接に関係していますので、DFPのメリットを最大化するためにZ-Orderingの利用を検討されるのがよろしいかと思います。これらの最新の性能最適化テクニックを利用するためには、Databricksにサインアップしてください!