How to Use Databricks to Scale Modern Industrial IoT Analytics - Part 1 - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
インダストリアルIoT分析に関するこの記事と3パートのシリーズは、DatabricksとマイクロソフトのCloud Solution Architectureチームの共著です。DatabricksのSolutions ArchitectであるSamir Guptaと、Microsoft Cloud Solution ArchitectsのLana KoprivicaとHubert Duaに感謝の意を表します。
お客さま達はインダストリアルIoT分析にAzure Databricksを活用しています
過去数年間を通じて主にオイル&ガス業界において基礎的なテクノロジースタックが検証され、これが製造、化学、ユーティリティ、輸送、エネルギーセクターに広がり導入されることでインダストリアルIoT(IIoT)は成長しました。ScadaやHistoriansのような従来型のIoTシステムやHadoopですら、以下の要素によって自身のアセットを予測的に最適化するために多くの企業によって必要とされるビッグデータ分析機能を提供していませんでした。
| 課題 | 必要な機能 |
|---|---|
| データボリュームが極端に大きく高頻度 | IoTデバイスから得られる一日あたりテラバイトのストリーミングデータを秒以下の粒度で信頼性高く、かつコスト効率高く読み込み、補足・格納する能力 |
| データ処理要件がさらに複雑 | 容易に古いデータを再処理できる能力と、時間ベースのウィンドウ、集計、ピボット、バックフィル、シフトなどのACID準拠のデータ処理 |
| より多くのユーザーペルソナがデータにアクセス | サイロを作ることなしに、オペレーショナルエンジニア、データアナリスト、データエンジニア、データサイエンティストに容易に共有できるオープンフォーマットのデータ |
| 意思決定にスケーラブルなMLが必要 | インテリジェントなアセット最適化の意思決定を行うために、粗い履歴データに他する予測モデルをクイックかつコラボレーティブにトレーニングする能力 |
| コスト削減の要件がこれまで以上に高く | 膨大な事前投資なしに、データとワークロードに独立でスケールする低コスト、オンデマンドのマネージドプラットフォーム |
企業はスケーラブルかつIIoTを実現できるテクノロジーを活用し、HistorianやSCADAシステムのような時系列データソースの取り込み、分析、サービングを容易にするために、Microsoft Azureのようなクラウドコンピューティングプラットフォームに目を向けています。
パート1では、エンドツーエンドのテクノロジースタックと、モダンなIoT分析のインダストリアルアプリケーションのアーキテクチャとデザインにおけるAzure Databricksの役割を議論します。
パート2では、モダンIIoT分析のデプロイにディープダイブし、フィールドデバイスからのIIoTマシンtoマシンのデータのAzure Data Lake Storageへのリアルタイム取り込み、データレイクに対する直接の複雑な時系列処理の実行を行います。
パート3では、インダストリアルIoTデータによる機械学習と分析を見ていきます。
ユースケース - 風力タービンの最適化
多くのIIoT分析プロジェクトは、長期的なメンテナンスコストを最小化しつつも、短期的なインダストリアル資産の使用率を最大化するように設計されます。本書では、風力タービンを最適化しようとする架空のエネルギー供給者にフォーカスします。最終的なゴールは、故障発生時間を最小化しつつも、それぞれのタービンの電力出力を最大化する最適なタービンの稼働パラメーターのセットを特定するというものです。
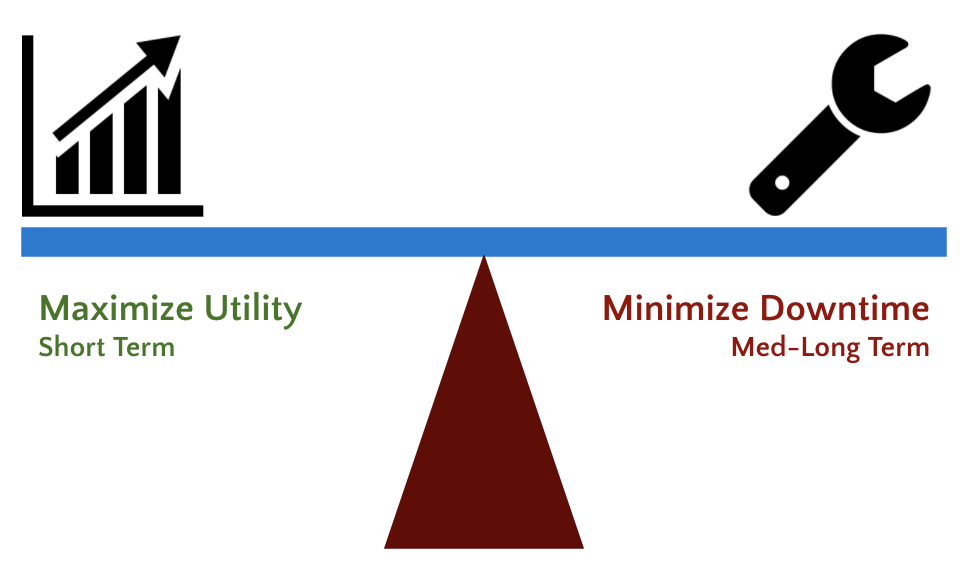
このプロジェクトの最終成果物は以下のようなものとなります。
- 全てのエンドユーザーに対してデータをストリーミングする自動化されたデータ取り込み・処理のパイプライン
- 現在の気候と稼働条件におけるそれぞれのタービンの出力電力を推定する予測モデル
- 現在の気候と稼働条件におけるそれぞれのタービンの寿命を推定する予測モデル
- 出力電力を最大化し、メンテナンスコストを最小化する、すなわちトータルの利益を最大化するための最適な稼働パラメーターを決定する最適化モデル
- 以下のように、風力ファームの現在と将来の状態を可視化する、経営層向けリアルタイムダッシュボード

アーキテクチャ - 取り込み、格納、準備、トレーニング、サービング、可視化
以下のアーキテクチャでは、AzureがIIoT分析向けに提供すべきすべてを活用している多くの企業によって用いられている、モダンかつベストオブブリードのプラットフォームを示しています。
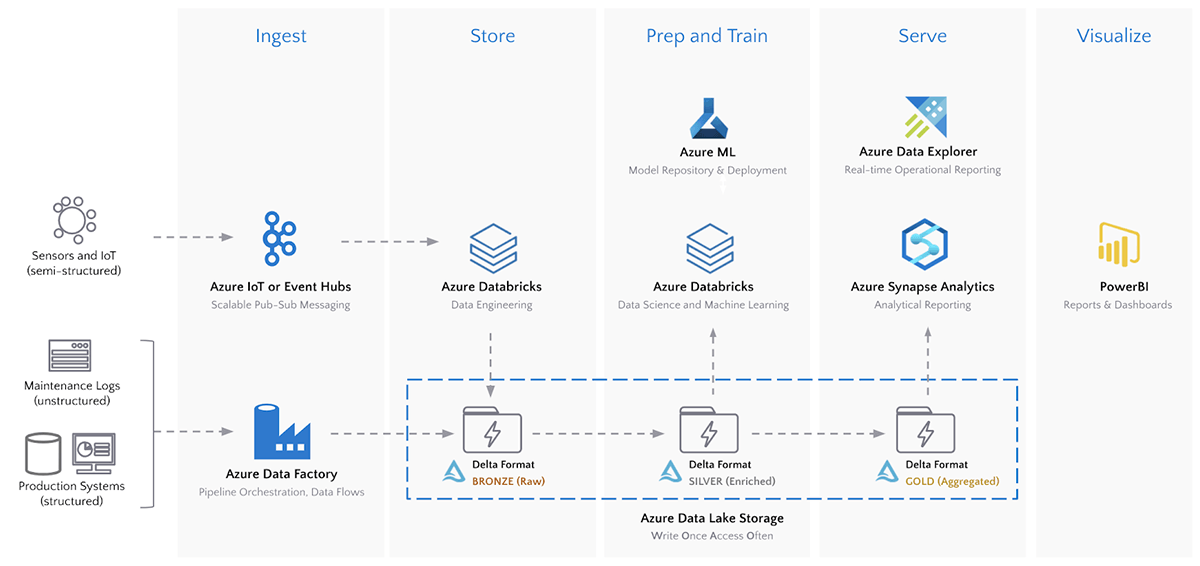
このアーキテクチャのキーとなるコンポーネントは、Azureにおける一度のみの書き込み、高頻度アクセスの分析パターンを可能とするAzure Data Lake Storage(ADLS)です。しかし、データレイク単体では、時系列ストリーミングデータとともにもたらされるリアルワールドの課題を解決することができません。Deltaストレージフォーマットは、ADLSに格納される全てのデータソースに回復可能性とパフォーマンスのレイヤーを提供します。特に時系列データに対して、DeltaはADLS上の他のストレージフォーマットに対するメリットを提供します。
| 必要な機能 | ADLS Gen 2における他のフォーマット | ADLS Gen 2におけるDeltaフォーマット |
|---|---|---|
| バッチとストリーミングの統合 | 多くのケースでデータレイクはCosmosDBのようなストリーミングストアと組み合わせて使用されますが、複雑なアーキテクチャとなってしまいます。 | ACID準拠のトランザクションによって、データエンジニアはADLS上の同じ場所でストリーミングの取り込みと履歴データのバッチロードを行うことができます。 |
| スキーマ強制と進化 | データレイクはスキーマを強制せず、信頼性を保つためには全てのデータをリレーショナルデータベースにプッシュしなくてはなりません。 | デフォルトでスキーマが強制されます。データストリームに新たなIoTデバイスが追加されると、安全にスキーマを進化させることができるので後段のアプリケーションは失敗しません。 |
| 効率的なUpsert | データレイクはインラインでのアップデートやマージをサポートせず、更新を行うためにはパーティション全体の削除と取り込みを必要とします。 | 遅延したIoTの読み取りデータの取り扱いや、リアルタイムでのデータ補強のための修正ディメンジョンテーブルやデータを再処理する必要があるときにMERGEコマンドが有効です。 |
| ファイルコンパクション | データレイクに対する時系列データのストリーミングは、数百、数千もの小さいファイルを生成します。 | Deltaにおける自動コンパクションは、スループットと並列度を増加させるためにファイルサイズを最適化します。 |
| 多次元クラスタリング | データレイクはパーティションに対するフィルタリングのプッシュダウンのみを提供します。 | タイムスタンプやセンサーIDのようなフィールドに対する時系列データのZオーダリングによって、Databricksはこれらのカラムに対するフィルタリング、joinをシンプルなパーティショニング技術よりも最大100倍高速にします。 |
サマリー
この記事では、従来型のIIoTシステムが直面しているさまざまな課題をレビューしました。また、モダンなIIoT分析のユースケースとゴールをウォークスルーし、企業が既に大規模にデプロイしている再現可能なアーキテクチャを共有し、必要とされる能力に対するDeltaフォーマットの利点を探索しました。
次の記事では、フィールドデバイスからのリアルタイムIIoTデータをAzureに取り込み、データレイク上で直接複雑な時系列処理を行います。
すべてを結びつけるキーテクノロジーがDelta Lakeです。ADLSにおけるDeltaは、信頼性のあるストリーミングデータパイプラインと、膨大なボリュームの時系列データに対する高性能なデータサイエンス、分析クエリーを提供します。最後になりますが、これによって企業はベストオブブリードのAzureツールに一度のみの書き込み、高頻度アクセスのデータストアを持ち込むことで、真のレイクハウスパターンを導入することができます。
次は?
この3パートのトレーニングシリーズでAzure Databricksを学んでみてください。また、こちらのウェビナーに参加してモダンなデータアーキテクチャの構築方法をご覧ください。