この記事はトピックモデリングに関するシリーズの一つです。トピックモデリングは、一連のテキストドキュメントからトピックを抽出するプロセスです。大規模なテキストドキュメントのコレクションを理解したり、要約したりする際には有用です。ドキュメントは一行のテキストあるいは本におけるパラグラフ、章だったりします。ドキュメントの抽象化は、我々が操作するテキストの単独のユニットとなります。ドキュメントのコレクションはコーパスと呼ばれ、複数のコーパスはコーポラと呼ばれます。
ここでは、オープンソースのPyspark MLライブラリを用いてドキュメントのコーパスからトピックを抽出し、Plot.lyを用いて、抽出したトピックの単語の適切性を可視化します。理想的には、データエンジニアリングとモデル開発プロセスを結びつけたいと思いますが、データサイエンティストが特定のデータセットに対してモデル構築の実験をしたいという時もあります。このため、モデル実験に対して全てのETLパイプラインを実行することが、時間の浪費になるかもしれません。この記事では、抽出した特徴量を格納し、実験で再利用できるようにするためにDatabricksのFeature Store(特徴量ストア)を用いて、どのようにETLプロセスをデータサイエンス実験ステップから分離するのかを説明します。これにより、LDAのような様々なトピックモデリングアルゴリズムを用いた実験やハイパーパラメーターの最適化が容易になります。そして、Feature Storeはバージョン管理も行えるので、実験をよりシステマティックかつ再現可能なものにします。
プロセスの概要
ここでは、様々な主要政治家のツイートをダウンロードし、JSONフォーマットで格納しています。これらのツイートからトピックを抽出するワークフローは、以下のステップから構成されています。
- JSONデータの読み込み
- テキスト特徴量を生成するためにデータのクレンジングおよび変換
- Feature Storeのデータベースの作成
- 生成した特徴量をFeature Storeに書き込み
- Feature Storeから特徴量を読み込み、トピックモデリングを実行
特徴量ストアとは?
特徴量ストアの背後にある一般的な考え方は、異なるモデルが使用する特徴量を格納するための中央レポジトリというものです。DatabricksのFeature Storeを用いることで、Databricksのレイクハウスプラットフォームに統合された形で同じことを行うことができます。Feature Storeは、特徴量の検索、共有、リネージュ(系統情報)の追跡をサポートします。Feature Storeは、Sparkや他の処理エンジンに対して、ACIDトランザクションを提供するDeltaテーブルをベースとしています。
データのロードおよび変換
PySparkを用いてデータをロードし、トピック抽出に必要なフィールドを抽出するところからスタートします。重複するツイートを排除し、トークン化、ストップワードの除外を行います。ここでは、これ以上の処理は行いませんが、リンクや絵文字を除外することを強くお勧めします。
fs = feature_store.FeatureStoreClient()
df = spark.read.format("json").load("/FileStore/*.txt")
pub_extracted = df.rdd.map(lambda x: ( x['user']['screen_name'], x['id'], x['full_text']) ).toDF(['name','tweet_id','text'])
pub_sentences_unique = pub_extracted.dropDuplicates(['tweet_id'])
tokenizer = Tokenizer(inputCol="text", outputCol="words")
wordsData = tokenizer.transform(pub_sentences_unique)
remover = StopWordsRemover(inputCol="words", outputCol="filtered")
filtered = remover.transform(wordsData)
コーパス内の単語は、出現回数でベクトル化され、逆文書頻度(IDF)が計算されます。これらがこのモデルのための特徴量として抽出、保存され、モデル構築プロセスで再利用されます。IDFを保持する特徴量rawFeaturesはスパース(疎な)ベクトル型であり、Feature Storeは配列の格納をサポートしていないため、Feature Storeに保存できるようにこの列は文字列として変換します。我々は特徴量のスキーマを知っているので、Feature Storeから読み込む際にベクトルに戻すことができ、モデルに使用することができます。
cv = CountVectorizer(inputCol="filtered", outputCol="rawFeatures", vocabSize=5000, minDF=10.0)
cvmodel = cv.fit(filtered)
vocab = cvmodel.vocabulary
featurizedData = cvmodel.transform(filtered)
idf = IDF(inputCol="rawFeatures", outputCol="features")
idfModel = idf.fit(featurizedData)
rescaledData = idfModel.transform(featurizedData)
rescaledData = rescaledData.withColumn('stringFeatures', rescaledData.rawFeatures.cast(StringType()))
rescaledData = rescaledData.withColumn('coltext', concat_ws(',', 'filtered' ))
特徴量ストア
特徴量の保存
特徴量テーブルを保存するデータベースを作成するところから着手します。特徴量ストアとやりとりを行うための、特徴量ストアのクライアントオブジェクトを作成します。特徴量ストアを作成するには、少なくとも特徴量ストアの名前と保存するキーとカラムを指定します。以下の例では、上で作成したデータフレームの4つのカラムを保存します。Feature StoreはDeltaテーブルなので、特徴量の再書き込みが可能で、特徴量の値はシンプルにバージョン管理され、後で取り出すことができるので、実験の再現性を確保することができます。
CREATE DATABASE IF NOT EXISTS lda_example2;
fs = feature_store.FeatureStoreClient()
fs.create_feature_table(name = "lda_example2.rescaled_features", keys = ['tweet_id', 'text', 'coltext', 'stringFeatures'], features_df = rescaledData.select('tweet_id', 'text', 'coltext', 'stringFeatures'))
Feature Storeのロード
特徴量を保存しておけば、次回以降データサイエンティストが別のモデルで実験したい際にETLパイプラインを再実行する必要がなくなりますので、時間や計算資源を節約することができます。fs.read_tableにテーブル名、特定のバージョンの特徴量を取得する必要があるのであればタイムスタンプを指定して、容易に特徴量を再ロードすることができます。
変換されたIDFの値は文字列として格納されているので、値を抽出しスパースベクトルフォーマットに変換する必要があります。この変換処理は以下に示されており、データフレームdf_newが生成され、トピックモデリングのアルゴリズムに入力されます。
fs = feature_store.FeatureStoreClient()
yesterday = datetime.date.today() + datetime.timedelta(seconds=36000)
# Read feature values
lda_features_df = fs.read_table(
name='lda_example2.rescaled_features',
#as_of_delta_timestamp=str(yesterday)
)
df_new = lda_features_df.withColumn("s", expr("split(substr(stringFeatures,2,length(stringFeatures)-2), ',\\\\s*(?=\\\\[)')")) \
.selectExpr("""
concat(
/* type = 0 for SparseVector and type = 1 for DenseVector */
'[{"type":0,"size":',
s[0],
',"indices":',
s[1],
',"values":',
s[2],
'}]'
) as vec_json
""") \
.withColumn('features', from_json('vec_json', ArrayType(VectorUDT()))[0])
トピックモデルの構築
抽出した特徴量によるデータフレームの準備ができれば、PySpark MLライブラリのLatent Dirichlet Allocation (LDA)を用いて、トピックを抽出することができます。LDAは以下のように定義されています。
Latent Dirichlet Allocation (LDA)は、文書コレクションに対する確率的生成モデルであり、潜在的なトピックの組み合わせで表現され、それぞれのトピックは単語の分布によって特徴付けられます。
簡単に言えば、それぞれのドキュメントは複数のトピックから構成され、それらのトピックの比率はドキュメントごとに異なります。トピック自身は、単語の組み合わせとトピックへの関連性を表現する単語の分布で表現されます。トピック、ドキュメントそれぞれの類似性のレベルを指定するために、betaと呼ばれるトピック集中パラメーターと、alphaと呼ばれるドキュメント集中パラメータが使用されます。高いalphaはドキュメントに似たトピックを生成し、低いalphaは少ないが異なるトピックを生成することになります。非常に大きなalpha、alphaが無限大に向かっていくと、全てのドキュメントは同じトピックで構成されるようになります。同様に、大きなbetaは類似のトピックを生成しますが、小さいbetaは少ない単語を持つ異なるトピックを生成するようになります。
LDAは教師なし学習アルゴリズムなので、モデルの精度を測るための正解データは存在しません。モデルのperplexityのようなメトリックを用いて、トピックの数kのハイパーパラメーターチューニングを行うことができます。ハイパーパラメーターalpha、betaはsetDocConcentration、setTopicConcentrationを用いて設定することができます。
抽出した特徴量を用いてモデルのフィッティングが終われば、Plot.lyを用いてトピックの可視化を行うことができます。
lda_model = LDA(k=10, maxIter=20)
# learning_offset - large values downweight early iterations
# DocConcentration - optimized using setDocConcentration, e.g. setDocConcentration([0.1, 0.2])
# TopicConcentration - set using setTopicConcentration. e.g. setTopicConcentration(0.5)
model = lda_model.fit(df_new)
lda_data = model.transform(df_new)
ll = model.logLikelihood(lda_data)
lp = model.logPerplexity(lda_data)
vocab_read = spark.read.format("delta").load("/tmp/cvvocab")
vocab_read_list = vocab_read.toPandas()['vocab'].values
vocab_broadcast = sc.broadcast(vocab_read_list)
topics = model.describeTopics()
def map_termID_to_Word(termIndices):
words = []
for termID in termIndices:
words.append(vocab_broadcast.value[termID])
return words
udf_map_termID_to_Word = udf(map_termID_to_Word , ArrayType(StringType()))
ldatopics_mapped = topics.withColumn("topic_desc", udf_map_termID_to_Word(topics.termIndices))
topics_df = ldatopics_mapped.select(col("termweights"), col("topic_desc")).toPandas()
display(topics_df)
以下のピロっとでは、それぞれの行がトピックに対応する一連の棒グラフとしてトピックの分布を示しています。それぞれの行の個々の棒グラフは、トピックに関連づけられた単語と、トピックに対する相対的な重要度を示しています。上で述べた通り、トピックの数はドメイン知識あるいはハイパーパラメーターチューニングを必要とするハイパーパラメーターとなります。
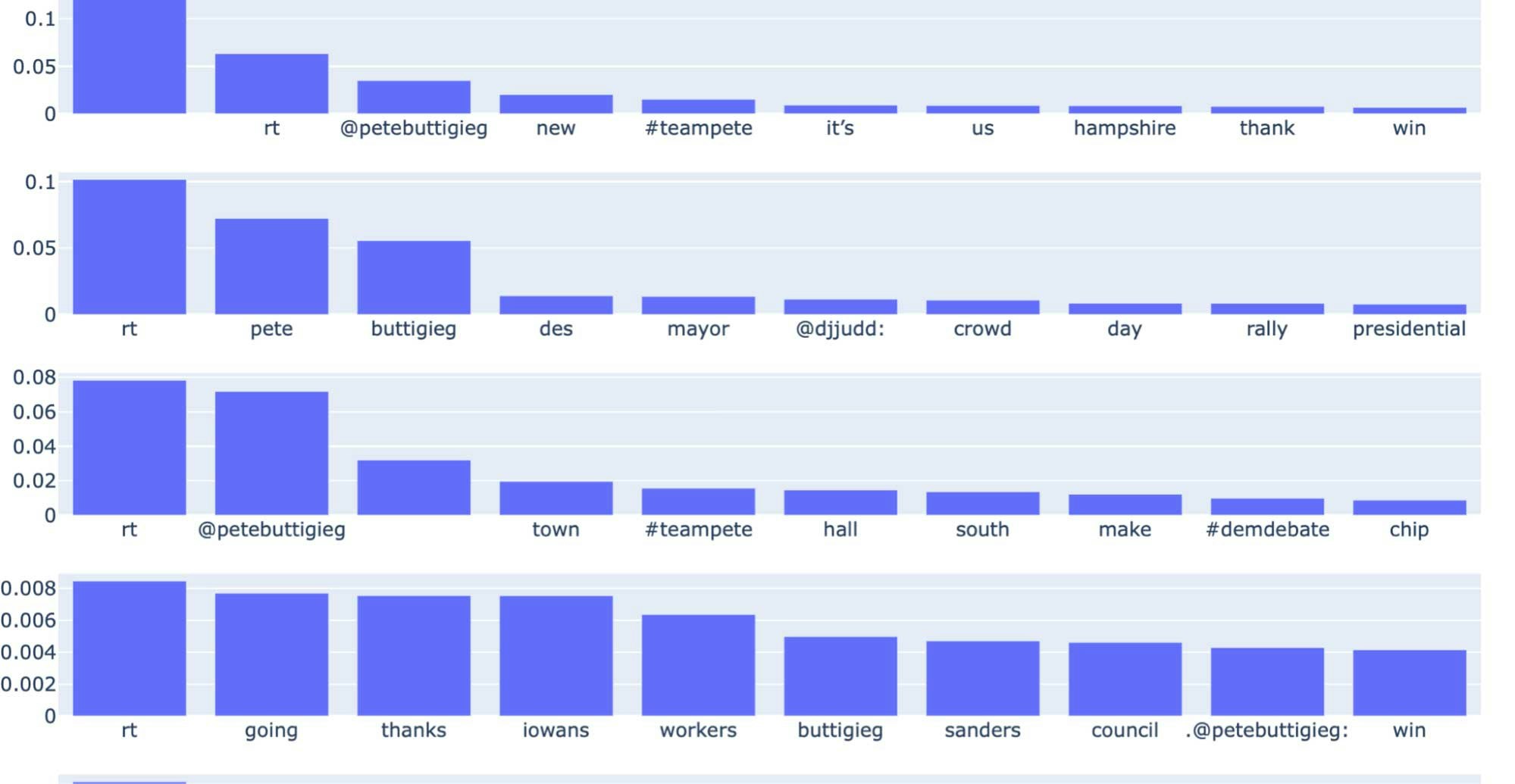
トピックごとの単語の棒グラフ、それぞれの行がトピック、棒グラフの高さが単語の重みを示す
まとめ
どのようにツイートのJSONファイルのコレクションをロードし、比較的綺麗なテキストデータを取得するのかをお見せしました。NLPの機械学習アルゴリズムで利用できるように、テキストはベクトルに変換されました。Databricks Feature Storeを用いて、ベクトル化されたデータを特徴量として保存し、データサイエンティストの実験で再利用できるようにしました。特徴量はPySparkのLDAアルゴリズムに入力され、抽出されたトピックはPlot.lyで可視化されました。是非、下のノートブックで、このパイプラインによる実験にトライし、トピック数などのハイパーパラメーターを調整してどのように動作するのかを確認してみてください!
参考資料