意外にハマったのでメモ。
やりたいこと
m秒を含むUnixタイムスタンプをSparkで読み込んで、Sparkのtimestamp型に変換したい
簡単だろうと思ったら一筋縄では行きませんでした。そもそも、Unixタイムスタンプにm秒ありとなしがあることも知りませんでした。
こちらが参考になりました。
- m秒なし: 10桁
- m秒あり: 13桁
m秒なしならfrom_unixtimeを呼び出すだけです。しかし、説明にあるように対応しているのは秒までです。なので、以下のようにして変換するのですが、当然m秒は落ちてしまいます。
df = df.withColumn(
"spark_timestamp", F.from_unixtime(df.unix_timestamp / 1000).cast("timestamp")
) # unix timestamp から spark timestamp へ (m秒が丸められている)
色々探していたら、こちらを見つけました。
デフォルトの
to_timestamp,from_unixtime,unix_timestamp関数はm秒を返しません。しかし、ワークアラウンドとしてm秒のタイムスタンプを得るために、
from_unixtimeとconcat関数を使います。
なんと。試します。
import pyspark.sql.functions as F
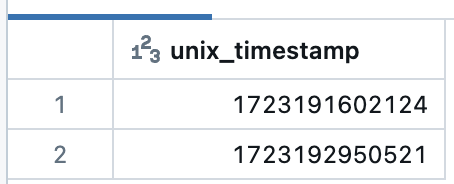
df = spark.createDataFrame([
{'unix_timestamp': 1723191602124},
{'unix_timestamp': 1723192950521}
])
display(df)
はじめに上述の手法を試します。
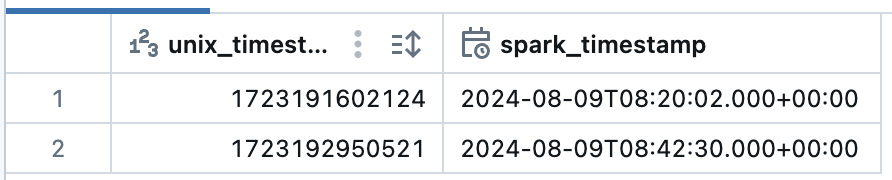
df = df.withColumn(
"spark_timestamp", F.from_unixtime(df.unix_timestamp / 1000).cast("timestamp")
) # unix timestamp から spark timestamp へ (m秒が丸められている)
display(df)
秒までしか入っていません。
ワークアラウンドを試します。わかりにくいですが、以下の流れです
- 秒までのタイムスタンプを日付表現に変換
- m秒を表現する文字列を抽出
-
concat_wsを用いて.を区切り文字として上の二つを文字列結合 -
yyyy-MM-dd HH:mm:ss.SSS形式の文字列から Spark timestamp に変換
df = df.withColumn(
"spark_timestamp_w_milli",
F.concat_ws( # (3) 秒までの文字列とm秒の文字列をカンマ区切りで結合
".",
F.from_unixtime(
F.substring(F.col("unix_timestamp"), 0, 10), "yyyy-MM-dd HH:mm:ss"
), # (1) タイムスタンプの最初の10文字からyyyy-MM-dd HH:mm:ssに変換
F.substring(F.col("unix_timestamp"), 11, 3), # (2) m秒を表現する11文字目から3文字を取得
).cast("timestamp") # (4) yyyy-MM-dd HH:mm:ss.SSS 形式の文字列から spark timestamp に変換
)
display(df)
できました!
