2024/4/12に翔泳社よりApache Spark徹底入門を出版します!

書籍のサンプルノートブックをウォークスルーしていきます。Python/Chapter11/11-1 MLflowとなります。
翻訳ノートブックのリポジトリはこちら。
ノートブックはこちら
MLflowはDatabricks Runtime for MLにプレインストールされています。MLランタイムを使っていない場合には、MLflowをインストールする必要があります。
from pyspark.ml import Pipeline
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.regression import RandomForestRegressor
from pyspark.ml.evaluation import RegressionEvaluator
filePath = "dbfs:/databricks-datasets/learning-spark-v2/sf-airbnb/sf-airbnb-clean.parquet"
airbnbDF = spark.read.parquet(filePath)
(trainDF, testDF) = airbnbDF.randomSplit([.8, .2], seed=42)
categoricalCols = [field for (field, dataType) in trainDF.dtypes
if dataType == "string"]
indexOutputCols = [x + "Index" for x in categoricalCols]
stringIndexer = StringIndexer(inputCols=categoricalCols,
outputCols=indexOutputCols,
handleInvalid="skip")
numericCols = [field for (field, dataType) in trainDF.dtypes
if ((dataType == "double") & (field != "price"))]
assemblerInputs = indexOutputCols + numericCols
vecAssembler = VectorAssembler(inputCols=assemblerInputs,
outputCol="features")
rf = RandomForestRegressor(labelCol="price", maxBins=40, maxDepth=5,
numTrees=100, seed=42)
pipeline = Pipeline(stages=[stringIndexer, vecAssembler, rf])
MLflowによるモデルのトラッキング
import mlflow
import mlflow.spark
import pandas as pd
with mlflow.start_run(run_name="random-forest") as run:
# パラメーターの記録: Num Trees と Max Depth
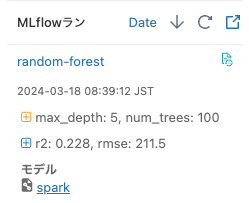
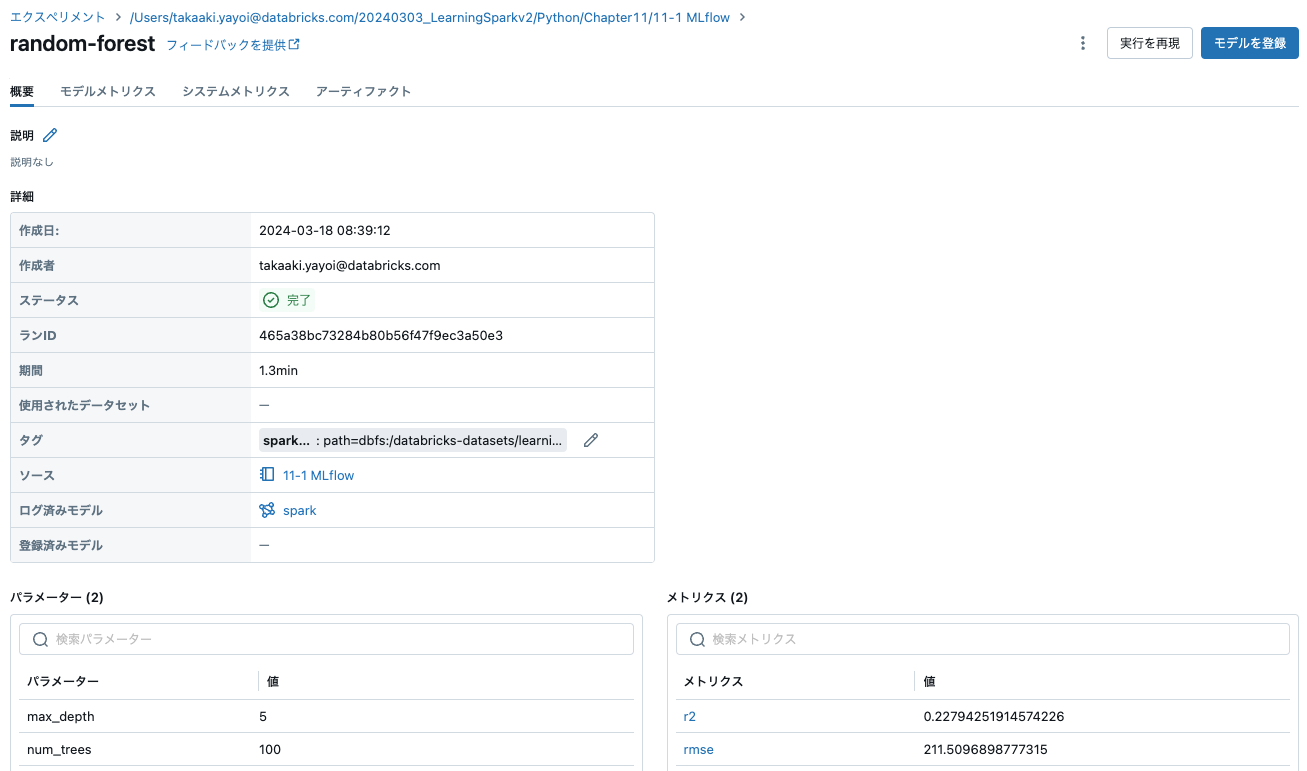
mlflow.log_param("num_trees", rf.getNumTrees())
mlflow.log_param("max_depth", rf.getMaxDepth())
# モデルの記録
pipelineModel = pipeline.fit(trainDF)
mlflow.spark.log_model(pipelineModel, "model")
# メトリクスの記録: RMSE と R2
predDF = pipelineModel.transform(testDF)
regressionEvaluator = RegressionEvaluator(predictionCol="prediction",
labelCol="price")
rmse = regressionEvaluator.setMetricName("rmse").evaluate(predDF)
r2 = regressionEvaluator.setMetricName("r2").evaluate(predDF)
mlflow.log_metrics({"rmse": rmse, "r2": r2})
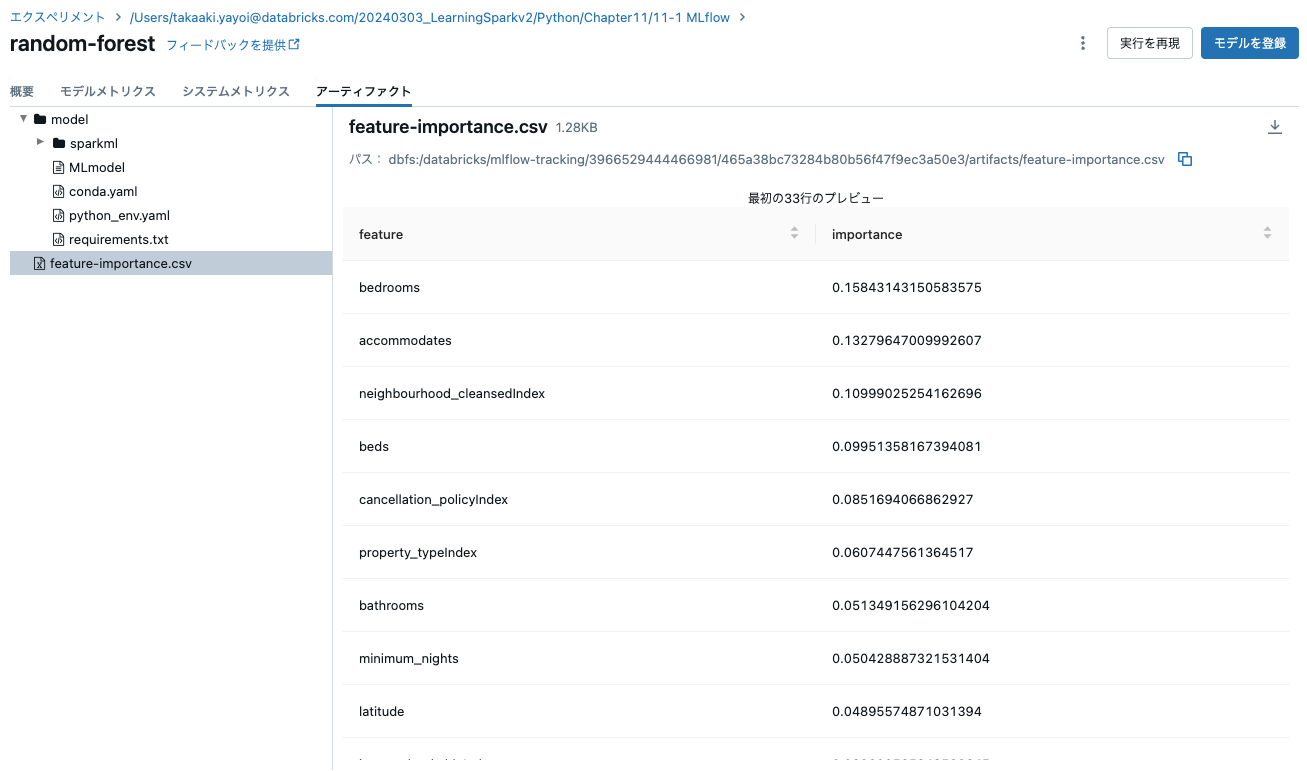
# アーティファクトの記録: 特徴量の重要度スコア
rfModel = pipelineModel.stages[-1]
pandasDF = (pd.DataFrame(list(zip(vecAssembler.getInputCols(),
rfModel.featureImportances)),
columns=["feature", "importance"])
.sort_values(by="importance", ascending=False))
# 最初にローカルファイルシステムに書き出し、MLflowにファイルの場所を通知
pandasDF.to_csv("/tmp/feature-importance.csv", index=False)
mlflow.log_artifact("/tmp/feature-importance.csv")
モデルがトラッキングされます。
MLflowClient
MLflowClientは、MLflowエクスペリメント、ラン、モデルバージョン、登録モデルに対するPythonのCRUDインタフェースを提供します。
from mlflow.tracking import MlflowClient
client = MlflowClient()
runs = client.search_runs(run.info.experiment_id,
order_by=["attributes.start_time desc"],
max_results=1)
run_id = runs[0].info.run_id
runs[0].data.metrics
{'rmse': 211.5096898777315, 'r2': 0.22794251914574226}
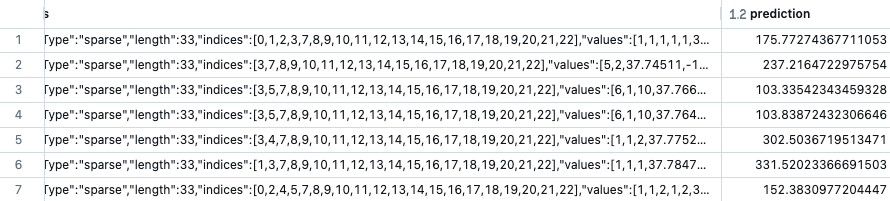
バッチ予測の生成
バッチ予測を生成するためにモデルをロードしなおしましょう。
# MLflowで保存したモデルのロード
pipelineModel = mlflow.spark.load_model(f"runs:/{run_id}/model")
# 予測の生成
inputPath = "dbfs:/databricks-datasets/learning-spark-v2/sf-airbnb/sf-airbnb-clean.parquet"
inputDF = spark.read.parquet(inputPath)
predDF = pipelineModel.transform(inputDF)
display(predDF)
ストリーミング予測の生成
ストリーミングの予測結果を生成するために同じことを行えます。
# MLflowで保存したモデルのロード
pipelineModel = mlflow.spark.load_model(f"runs:/{run_id}/model")
# シミュレーションされたストリーミングデータをセットアップ
repartitionedPath = "dbfs:/databricks-datasets/learning-spark-v2/sf-airbnb/sf-airbnb-clean-100p.parquet"
schema = spark.read.parquet(repartitionedPath).schema
streamingData = (spark
.readStream
.schema(schema) # このようにスキーマを設定可能
.option("maxFilesPerTrigger", 1)
.parquet(repartitionedPath))
# 予測の生成
streamPred = pipelineModel.transform(streamingData)
# ストリーミング予測結果の表示
display(streamPred)