約一年前にこちらの記事を書きました。
Rayとは
RayはスケーラブルなAI、Pythonワークロードを実行するための有名な計算フレームワークであり、さまざまな分散機械学習ツール、大規模ハイパーパラメーターチューニング能力、強化学習アルゴリズム、モデルサービングなどを提供しています。
私は、Sparkはデータの並列分散が前提ですが、Rayを使うことでデータを伴わない処理を分散できると認識しています。
このたび、この機能がGAになりました!Databricksランタイム15.0以降ではデフォルトでRayがインストールされ、追加のインストールは不要になります。
マニュアルはこちら。
サンプルノートブックをウォークスルーします。
クラスターはノートブックの要件に沿って、4GPU * 2ノードのGPUクラスターを準備します。ランタイムは15.0 MLを指定します。

Rayのインストール
ランタイム15.0 MLの場合、Rayの追加インストールは不要です。
Rayクラスターの作成
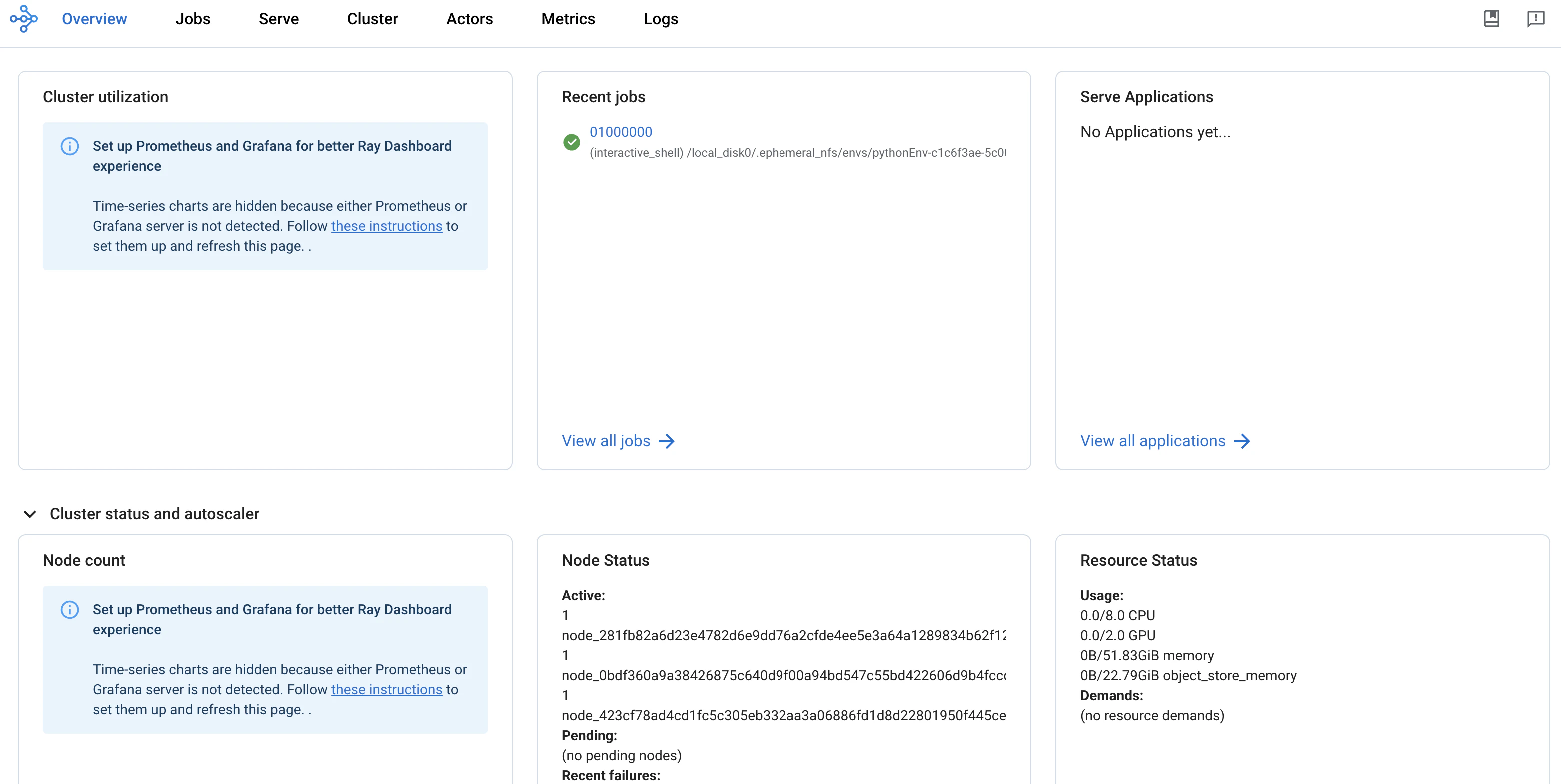
2台のRayワーカーノードを持つRayクラスターをセットアップします。それぞれのワーカーノードには4個のGPUコアが割り当てられています。クラスターが起動すると、Rayクラスターダッシュボードを参照するために、リンク"Open Ray Cluster Dashboard in a new tab"をクリックすることができます。
from ray.util.spark import setup_ray_cluster, shutdown_ray_cluster, MAX_NUM_WORKER_NODES
setup_ray_cluster(
num_worker_nodes=2,
num_cpus_per_node=4,
collect_log_to_path="/dbfs/tmp/raylogs",
)

作成したRayクラスターのリソースを表示します。
{'object_store_memory': 24466633522.0,
'CPU': 8.0,
'accelerator_type:T4': 2.0,
'memory': 55657155790.0,
'GPU': 2.0,
'node:10.0.7.67': 1.0,
'node:__internal_head__': 1.0,
'node:10.0.6.78': 1.0,
'node:10.0.6.91': 1.0}
Rayアプリケーションの実行
以下のコードでは、先程作成したRayクラスターで多数のRayタスクを作成するシンプルなRayアプリケーションを実行します。
import ray
import random
import time
import math
from fractions import Fraction
@ray.remote
def pi4_sample(sample_count):
"""pi4_sampleはsample_count回の実験を実行し、
円の中に含まれた回数の比率を返却します。
"""
in_count = 0
for i in range(sample_count):
x = random.random()
y = random.random()
if x*x + y*y <= 1:
in_count += 1
return Fraction(in_count, sample_count)
SAMPLE_COUNT = 1000 * 1000
start = time.time()
future = pi4_sample.remote(sample_count = SAMPLE_COUNT)
pi4 = ray.get(future)
end = time.time()
dur = end - start
print(f'Running {SAMPLE_COUNT} tests took {dur} seconds')
pi = pi4 * 4
print(float(pi))
Running 1000000 tests took 0.8532092571258545 seconds
3.14098
上で表示されたリンクをクリックすることで、Rayダッシュボードにアクセスできます。

FULL_SAMPLE_COUNT = 2000 * 1000 * 1000
BATCHES = int(FULL_SAMPLE_COUNT / SAMPLE_COUNT)
print(f'Doing {BATCHES} batches')
results = []
for _ in range(BATCHES):
results.append(pi4_sample.remote(sample_count = SAMPLE_COUNT))
output = ray.get(results)
pi = sum(output)*4/len(output)
print(float(pi))
Doing 2000 batches
3.141600784
Rayクラスターのシャットダウン
shutdown_ray_cluster()
ユースケース見ると、LLMとかでも使えるようですね。トライしてみます。