以前こちらの記事を書きましたが、こちらはscikit-learnを用いたものでした。
マニュアルを見ていたら、(今更ですが)Sparkでもxgboostを使えることに気づきました。
xgboost.sparkを使用したXGBoostモデルの分散トレーニング
Python パッケージ
xgboost>=1.7には、新しいモジュールxgboost.sparkが含まれています。 このモジュールには、xgboost PySpark 推定器xgboost.spark.SparkXGBRegressor、xgboost.spark.SparkXGBClassifier、およびxgboost.spark.SparkXGBRankerが含まれています。 これらの新しいクラスは、SparkML パイプラインに XGBoost 推定器を含めることをサポートします。
こちらのノートブックをウォークスルーします。
クラスターのスペックはこちら。
XGBoostとMLlibパイプラインによる回帰
このノートブックでは、バイクシェアリングのデータセットを使用して、MLlibパイプラインとXGBoost機械学習アルゴリズムを説明します。課題は、曜日、天気、季節などのデータセットに含まれる特徴に基づいて、1時間あたりの自転車レンタル数を予測することです。需要予測はビジネス全般で一般的な問題であり、正確な予測は在庫の最適化や供給と需要のマッチングを可能にし、顧客満足度の向上と利益の最大化に寄与します。
このノートブックで使用されているPySpark MLのSparkXGBRegressor推定器の詳細については、Xgboost SparkXGBRegressor APIを参照してください。
要件
Databricks Runtime for Machine Learning 12.2 LTS ML以上。
from xgboost.spark import SparkXGBRegressor
データセットの読み込み
データセットはUCI Machine Learning Repositoryから取得され、Databricks Runtimeに提供されています。このデータセットには、2011年と2012年のCapital bikeshareシステムからの自転車レンタルに関する情報が含まれています。
CSVデータソースを使用してデータを読み込み、Spark DataFrameを作成します。
df = spark.read.csv("/databricks-datasets/bikeSharing/data-001/hour.csv", header="true", inferSchema="true")
# 次のコマンドはDataFrameをメモリにキャッシュします。これにより、後続のDataFrame呼び出しがディスクからデータを再読み込みする代わりにメモリから読み取ることができるため、パフォーマンスが向上します。
df.cache()
データの説明
このデータセットには以下の列が含まれています:
インデックス列:
- instant: レコードインデックス
特徴量列:
- dteday: 日付
- season: 季節 (1:春, 2:夏, 3:秋, 4:冬)
- yr: 年 (0:2011, 1:2012)
- mnth: 月 (1から12)
- hr: 時間 (0から23)
- holiday: 祝日なら1、そうでなければ0
- weekday: 曜日 (0から6)
- workingday: 週末または祝日なら0、そうでなければ1
- weathersit: (1:晴れ, 2:霧または曇り, 3:小雨または小雪, 4:大雨または大雪)
- temp: 正規化された摂氏温度
- atemp: 正規化された体感温度
- hum: 正規化された湿度
- windspeed: 正規化された風速
ラベル列:
- casual: カジュアルユーザーの数
- registered: 登録ユーザーの数
- cnt: カジュアルユーザーと登録ユーザーを含む総レンタルバイク数
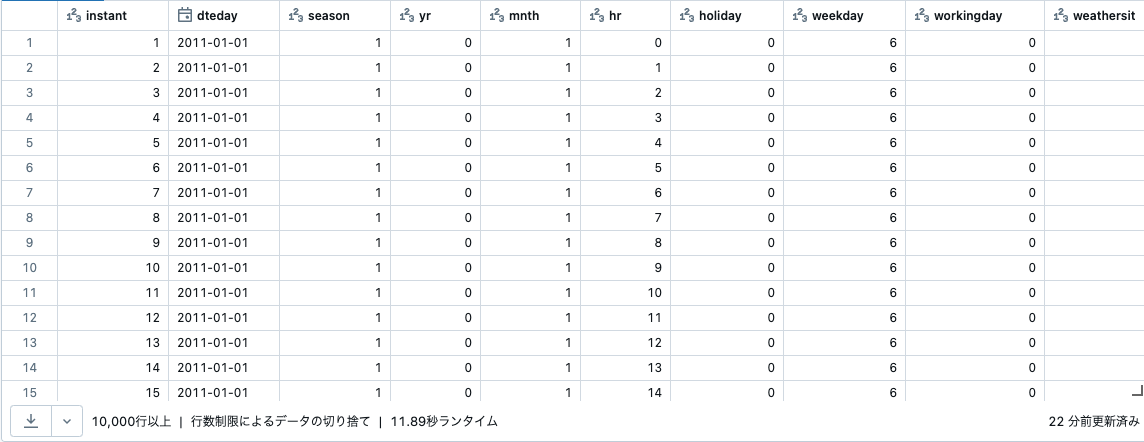
DataFrameに対してdisplay()を呼び出すと、データのサンプルが表示されます。最初の行は、2011年1月1日の午前0時から午前1時の間に16人が自転車をレンタルしたことを示しています。
display(df)
print("The dataset has %d rows." % df.count())
The dataset has 17379 rows.
データの前処理
このデータセットは機械学習アルゴリズムに適した形で準備されています。数値入力列(temp、atemp、hum、windspeed)は正規化され、カテゴリ値(season、yr、mnth、hr、holiday、weekday、workingday、weathersit)はインデックスに変換されており、日付(dteday)以外のすべての列は数値です。
目標はバイクレンタルの数(cnt列)を予測することです。データセットを確認すると、いくつかの列が重複した情報を含んでいることがわかります。例えば、cnt列はcasual列とregistered列の合計です。casual列とregistered列はデータセットから削除する必要があります。インデックス列instantも予測子としては役に立ちません。
また、dteday列は、他の日付関連列yr、mnth、weekdayにすでに含まれている情報であるため、削除することができます。
df = df.drop("instant").drop("dteday").drop("casual").drop("registered")
display(df)
データセットのスキーマを表示して、各列のタイプを確認します。
df.printSchema()
root
|-- season: integer (nullable = true)
|-- yr: integer (nullable = true)
|-- mnth: integer (nullable = true)
|-- hr: integer (nullable = true)
|-- holiday: integer (nullable = true)
|-- weekday: integer (nullable = true)
|-- workingday: integer (nullable = true)
|-- weathersit: integer (nullable = true)
|-- temp: double (nullable = true)
|-- atemp: double (nullable = true)
|-- hum: double (nullable = true)
|-- windspeed: double (nullable = true)
|-- cnt: integer (nullable = true)
トレーニングセットとテストセットにデータを分割
データをランダムにトレーニングセットとテストセットに分割します。これにより、トレーニングサブセットのみを使用してモデルをトレーニングおよびチューニングし、テストセットでモデルのパフォーマンスを評価することで、新しいデータに対するモデルのパフォーマンスを把握できます。
# データセットをランダムに分割し、70%をトレーニング用、30%をテスト用にします。決定論的な動作のためにシードを渡します
train, test = df.randomSplit([0.7, 0.3], seed = 0)
print("There are %d training examples and %d test examples." % (train.count(), test.count()))
There are 12081 training examples and 5298 test examples.
データの可視化
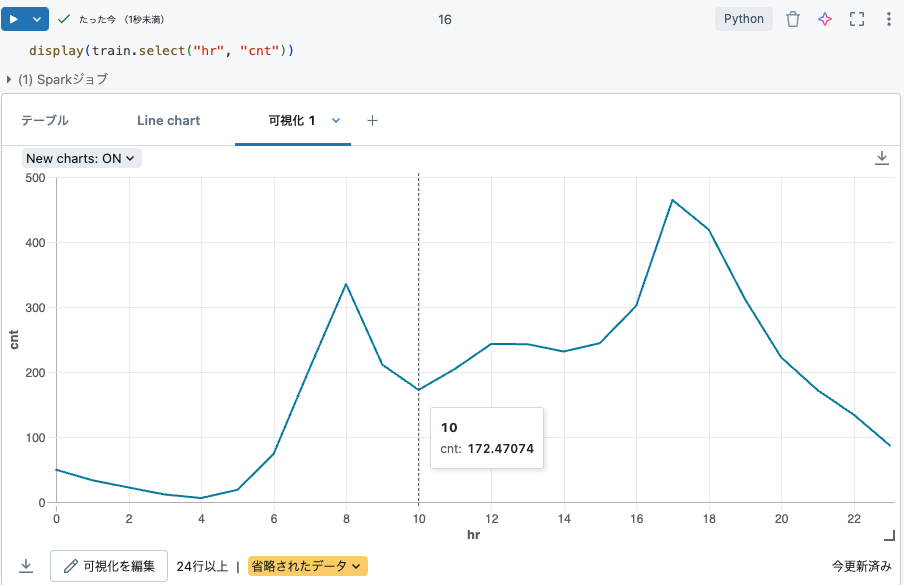
データを視覚的に探索するためにプロットを作成できます。次のプロットは、1日の各時間帯における自転車レンタルの数を示しています。予想通り、夜間のレンタルは少なく、通勤時間にピークを迎えます。
プロットを作成するには、DatabricksでDataFrameに対してdisplay()を呼び出し、テーブルの下にあるプロットアイコンをクリックします。
表示されたプロットを作成するには、次のセルでコマンドを実行します。結果はテーブルに表示されます。テーブルの下のドロップダウンメニューから「Line」を選択します。Plot Options...をクリックします。ダイアログでhrをKeysフィールドにドラッグし、cntをValuesフィールドにドラッグします。また、Keysフィールドで<id>の横にある「x」をクリックして削除します。Aggregationドロップダウンで「AVG」を選択します。
注意
上の可視化の設定手順は古いものです。テーブルを追加してから可視化を追加してください。
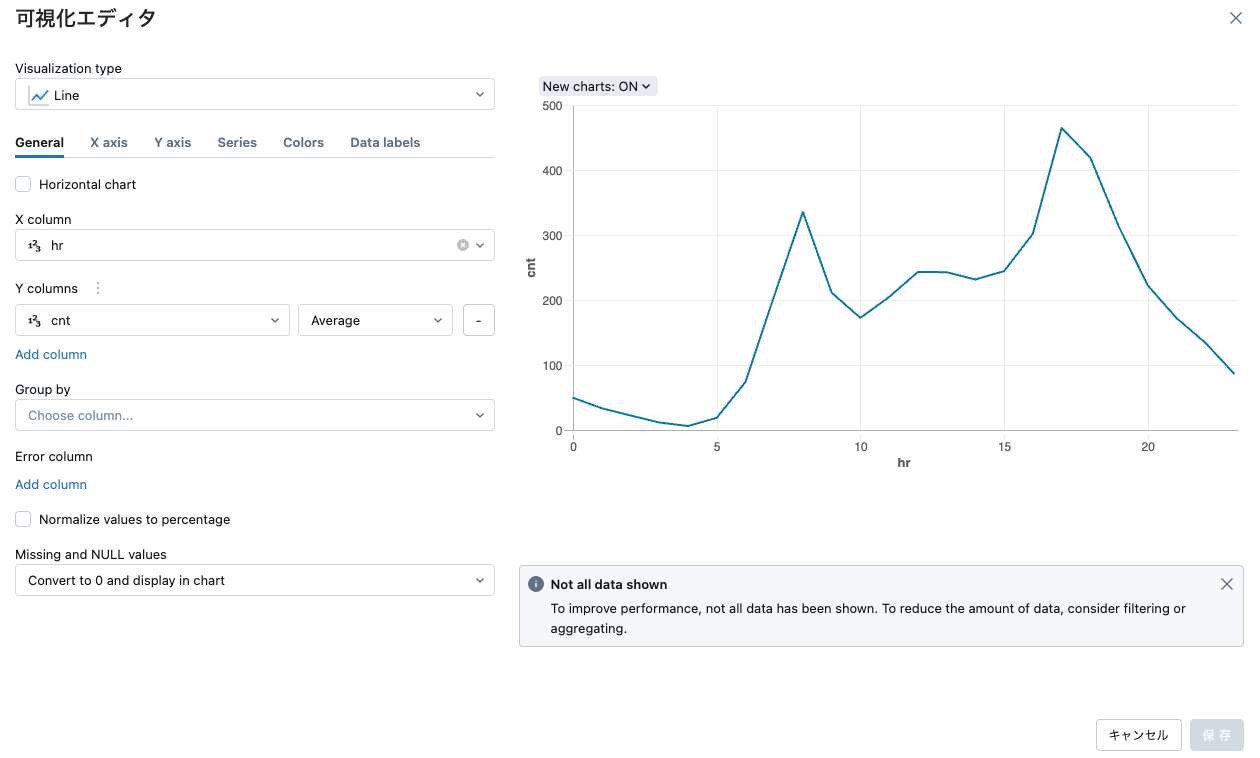
display(train.select("hr", "cnt"))
機械学習パイプラインのトレーニング
データを確認し、数値データを含むDataFrameとして準備したので、将来の自転車シェアリングのレンタルを予測するモデルをトレーニングする準備が整いました。
ほとんどのMLlibアルゴリズムは、特徴ベクトルを含む単一の入力列と単一のターゲット列を必要とします。現在のDataFrameには、各特徴の列が1つずつあります。MLlibは、データセットを必要な形式に準備するための関数を提供しています。
MLlibパイプラインは、複数のステップを単一のワークフローに結合し、モデルの開発を進める際に反復しやすくします。
この例では、次の関数を使用してパイプラインを作成します:
-
VectorAssembler: 特徴列を特徴ベクトルにまとめます。 -
VectorIndexer: カテゴリカルとして扱うべき列を識別します。これはヒューリスティックに行われ、少数の異なる値を持つ列をカテゴリカルとして識別します。この例では、次の列がカテゴリカルと見なされます:yr(2値)、season(4値)、holiday(2値)、workingday(2値)、およびweathersit(4値)。 -
SparkXGBRegressor: SparkXGBRegressor推定器を使用して、特徴ベクトルからレンタル数を予測する方法を学習します。 -
CrossValidator: XGBoost回帰アルゴリズムにはいくつかのハイパーパラメータがあります。このノートブックでは、Sparkでのハイパーパラメータチューニングの使用方法を示します。この機能は、ハイパーパラメータのグリッドを自動的にテストし、最良のモデルを選択します。
詳細情報:
最初のステップは、VectorAssemblerとVectorIndexerのステップを作成することです。
from pyspark.ml.feature import VectorAssembler, VectorIndexer
# 目的変数を入力特徴量セットから削除します。
featuresCols = df.columns
featuresCols.remove('cnt')
# vectorAssemblerは、すべての特徴量カラムを単一の特徴ベクターカラム「rawFeatures」に結合します。
vectorAssembler = VectorAssembler(inputCols=featuresCols, outputCol="rawFeatures")
# vectorIndexerはカテゴリカル特徴量を識別してインデックスを付け、新しいカラム「features」を作成します。
vectorIndexer = VectorIndexer(inputCol="rawFeatures", outputCol="features", maxCategories=4)
次に、モデルを定義します。分散トレーニングを使用するには、num_workersをトレーニング中に同時に実行したいSparkタスクの数に設定します。すべてのSparkタスクスロットを使用するには、num_workers=sc.defaultParallelismに設定します。
from xgboost.spark import SparkXGBRegressor
# パイプラインのモデルトレーニングステージを定義します。
# 次のコマンドは、デフォルトで入力カラム「features」を取り、「cnt」カラムのラベルを予測することを学習するXgboostRegressorモデルを定義します。
# `num_workers`を、xgboostモデルのトレーニング中に同時に実行したいSparkタスクの数に設定します。
xgb_regressor = SparkXGBRegressor(num_workers=sc.defaultParallelism, label_col="cnt", missing=0.0)
第三のステップは、先ほど定義したモデルをCrossValidatorステージにラップすることです。CrossValidatorは、異なるハイパーパラメータ設定でXgboostRegressor推定器を呼び出します。複数のモデルをトレーニングし、指定されたメトリックを最小化することで最適なモデルを選択します。この例では、メトリックは二乗平均平方根誤差 (RMSE)です。
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
from pyspark.ml.evaluation import RegressionEvaluator
# テストするハイパーパラメータのグリッドを定義します:
# - maxDepth: 各決定木の最大深度
# - maxIter: イテレーション数、または木の総数
paramGrid = ParamGridBuilder()\
.addGrid(xgb_regressor.max_depth, [2, 5])\
.addGrid(xgb_regressor.n_estimators, [10, 100])\
.build()
# 評価指標を定義します。CrossValidatorは、各パラメータの組み合わせに対して真のラベルと予測値を比較し、この値を計算して最適なモデルを決定します。
evaluator = RegressionEvaluator(metricName="rmse",
labelCol=xgb_regressor.getLabelCol(),
predictionCol=xgb_regressor.getPredictionCol())
# モデルチューニングを実行するCrossValidatorを宣言します。
cv = CrossValidator(estimator=xgb_regressor, evaluator=evaluator, estimatorParamMaps=paramGrid)
パイプラインを作成します。
from pyspark.ml import Pipeline
pipeline = Pipeline(stages=[vectorAssembler, vectorIndexer, cv])
パイプラインをトレーニングします。
ワークフローを設定したので、単一の呼び出しでパイプラインをトレーニングできます。
fit()を呼び出すと、パイプラインは特徴量処理、モデルチューニング、およびトレーニングを実行し、見つかった最良のモデルを持つフィット済みパイプラインを返します。
このステップには数分かかります。
pipelineModel = pipeline.fit(train)
予測を行い、結果を評価する
最後のステップは、フィット済みモデルを使用してテストデータセットに対して予測を行い、モデルのパフォーマンスを評価することです。テストデータセットでのモデルのパフォーマンスは、新しいデータに対してどのように機能するかの概算を提供します。例えば、来週の天気予報があれば、来週の自転車レンタルの予測を行うことができます。
評価指標を計算することは、予測の質を理解するため、またモデルを比較しパラメータを調整するために重要です。
transform() メソッドは、パイプラインモデルを入力データセットに適用します。パイプラインは、データセットに対して特徴量処理ステップを適用し、フィット済みの Xgboost 回帰モデルを使用して予測を行います。パイプラインは、新しい列 predictions を持つ DataFrame を返します。
predictions = pipelineModel.transform(test)
display(predictions.select("cnt", "prediction", *featuresCols))
回帰モデルの性能を評価する一般的な方法は、二乗平均平方根誤差 (RMSE)を計算することです。この値自体はあまり情報を提供しませんが、異なるモデルを比較するために使用できます。CrossValidatorは、RMSEを最小化するモデルを選択することで最適なモデルを決定します。
rmse = evaluator.evaluate(predictions)
print("RMSE on our test set: %g" % rmse)
RMSE on our test set: 41.5454
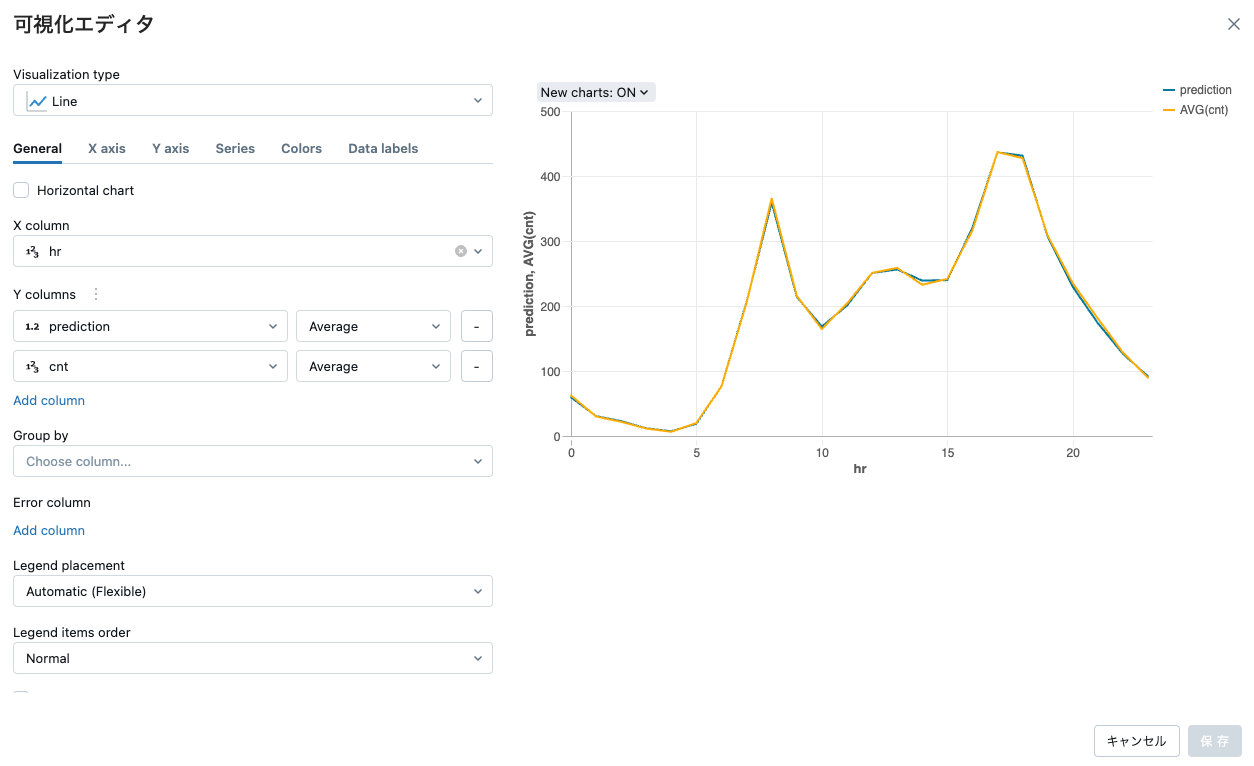
元のデータセットと同様に、結果をプロットすることもできます。この場合、時間ごとのレンタル数は同様の形状を示します。
display(predictions.select("hr", "prediction", "cnt"))
モデルの保存と再読み込みは割愛します。