こちらのイベントでお話しした内容です。
スライドはこちら。
冒頭は自己紹介、書籍の宣伝、会社紹介という流れでした。
Databricksとは?
Apache Sparkを開発した人たちが創業した会社です。

Databricksは会社名であると同時にプラットフォームの名前です。全ての会社がデータ+AIカンパニーになるための手助けをするためのプラットフォームを提供しています。
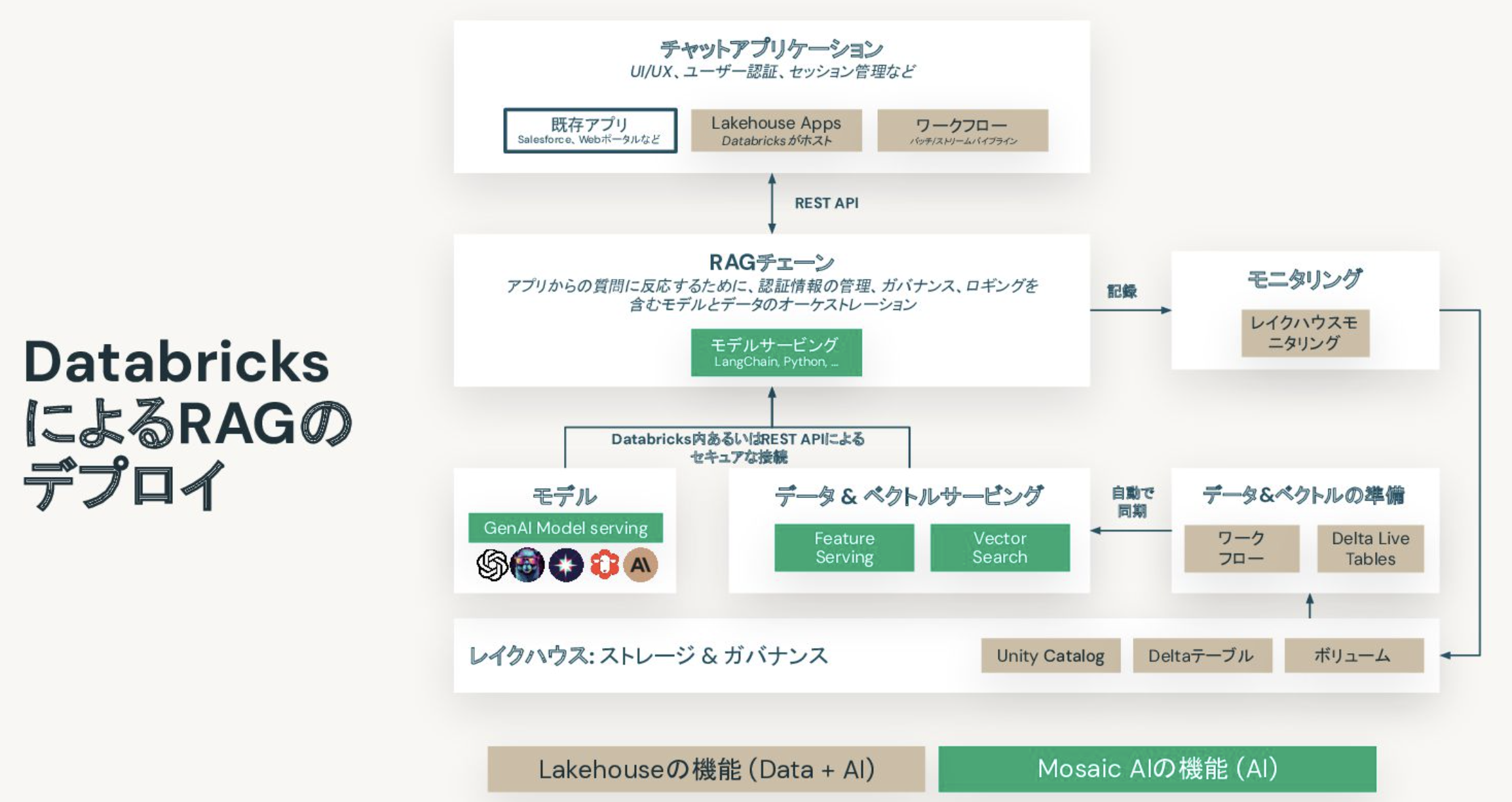
DatabricksにおけるRAGのデプロイメント
ここで言いたいのは、RAGで必要なものはほぼ揃ってます! ということです。GUI部分が執筆時点ではカバーされていませんが、間も無く提供されるLakehouse Appsでカバーされます!
プロダクションレベルの生成AIアプリ(RAG)の構築
生成AI、特にLLMの具体的なアプリケーションで一番具現化されているものはRAG(Retrieval Augmented Generation)であると言えます。ただ、RAGの構築においても様々な課題がありますし、その運用に関しても検討すべきことはたくさんあります。
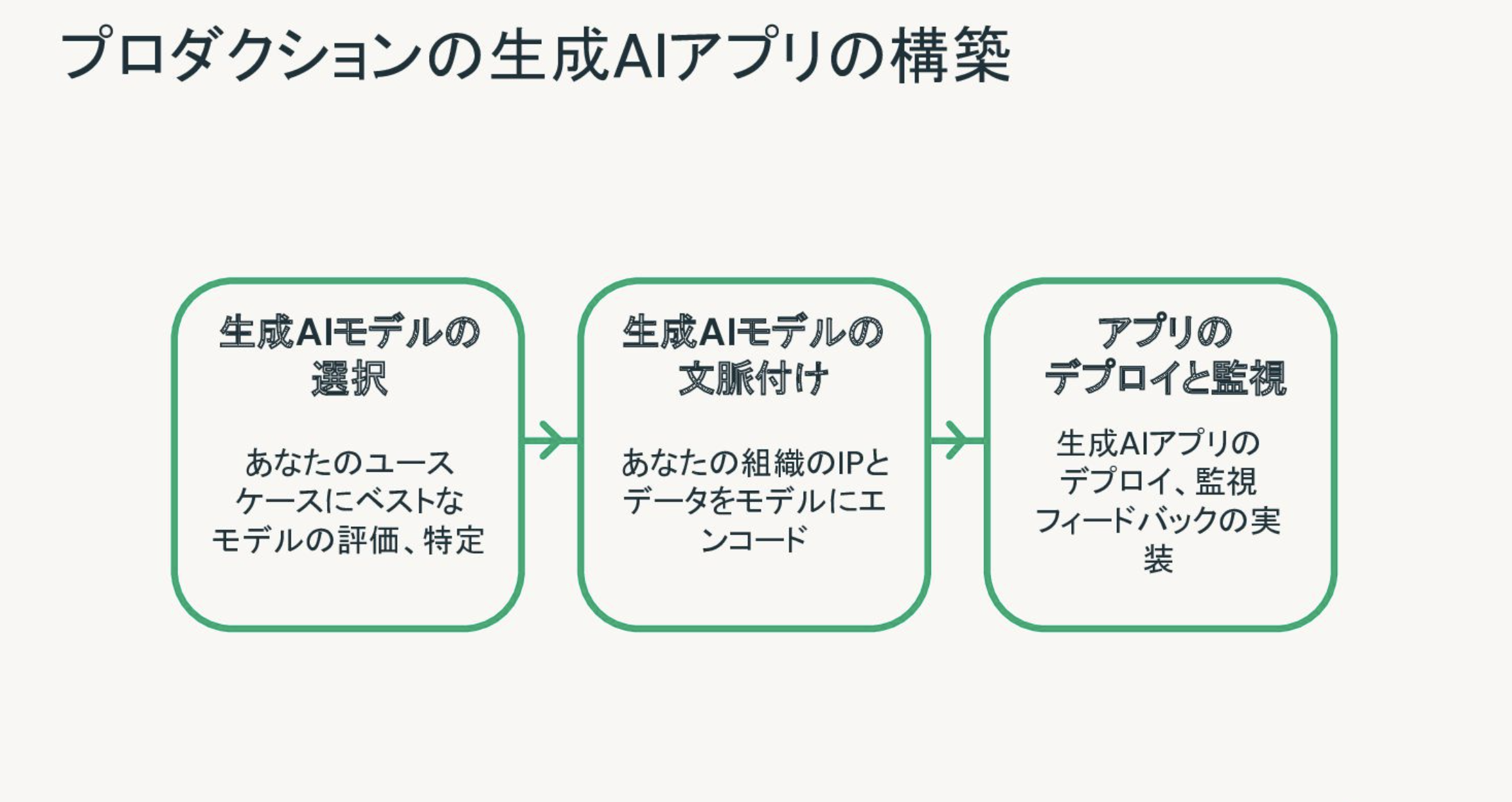
以降では、以下に示すRAG構築におけるステップごとにどのような課題があり、Databricksがどのように取り組んでいるのかを説明します。
- 生成AIモデルの選択: 今では世の中に膨大な数の生成AIモデルが存在しています。あなたのユースケースではどのモデルが最適なのでしょうか?
- 生成AIモデルの文脈付け: 生成AIモデルの選定が完了したら、ベクトルDBを用いるなどしてRAGを構築する必要があります。
- アプリのデプロイと監視: RAGを作って終わりではありません。RAGアプリケーションがリクエストに対して適切なレスポンスをしているのかを監視し、必要に応じてモデルの見直しを行う必要があります。
生成AIモデルの選択
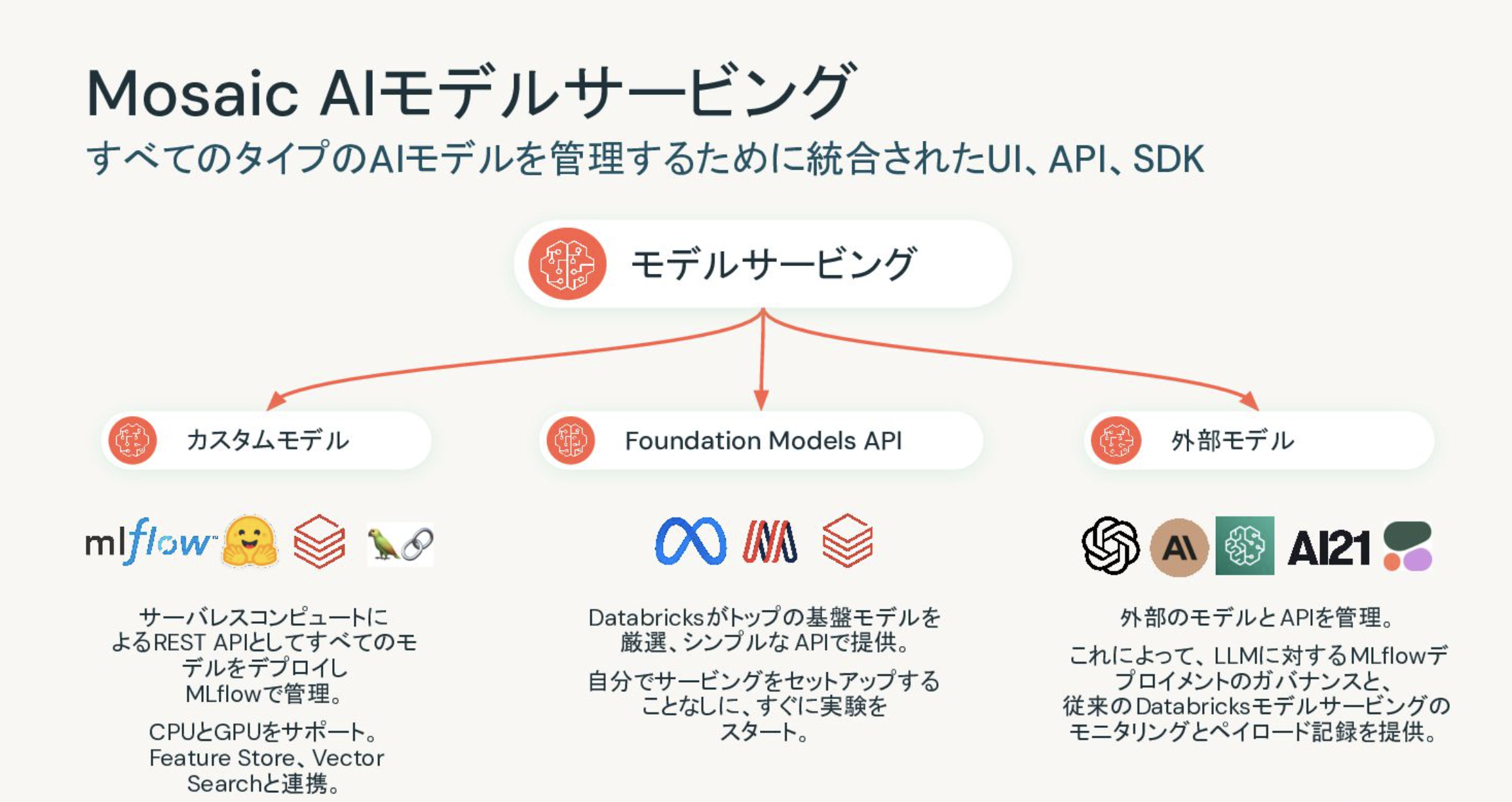
一つの企業において複数のRAGアプリケーションを構築するケースも増えてきています。そうなると、それぞれのアプリケーションで使用しているLLMの管理も課題になってきます。資格情報やレート制限の管理など。Databricksのモデルサービングの機能を用いることで、モデルプロバイダーのLLM、オープンソースのLLM、お客様自身が構築したLLMを効率的に管理、運用できるようになります。これは一種のLLMに対するゲートウェイとして動作し、資格情報やレート制限を一元管理できるようになります。
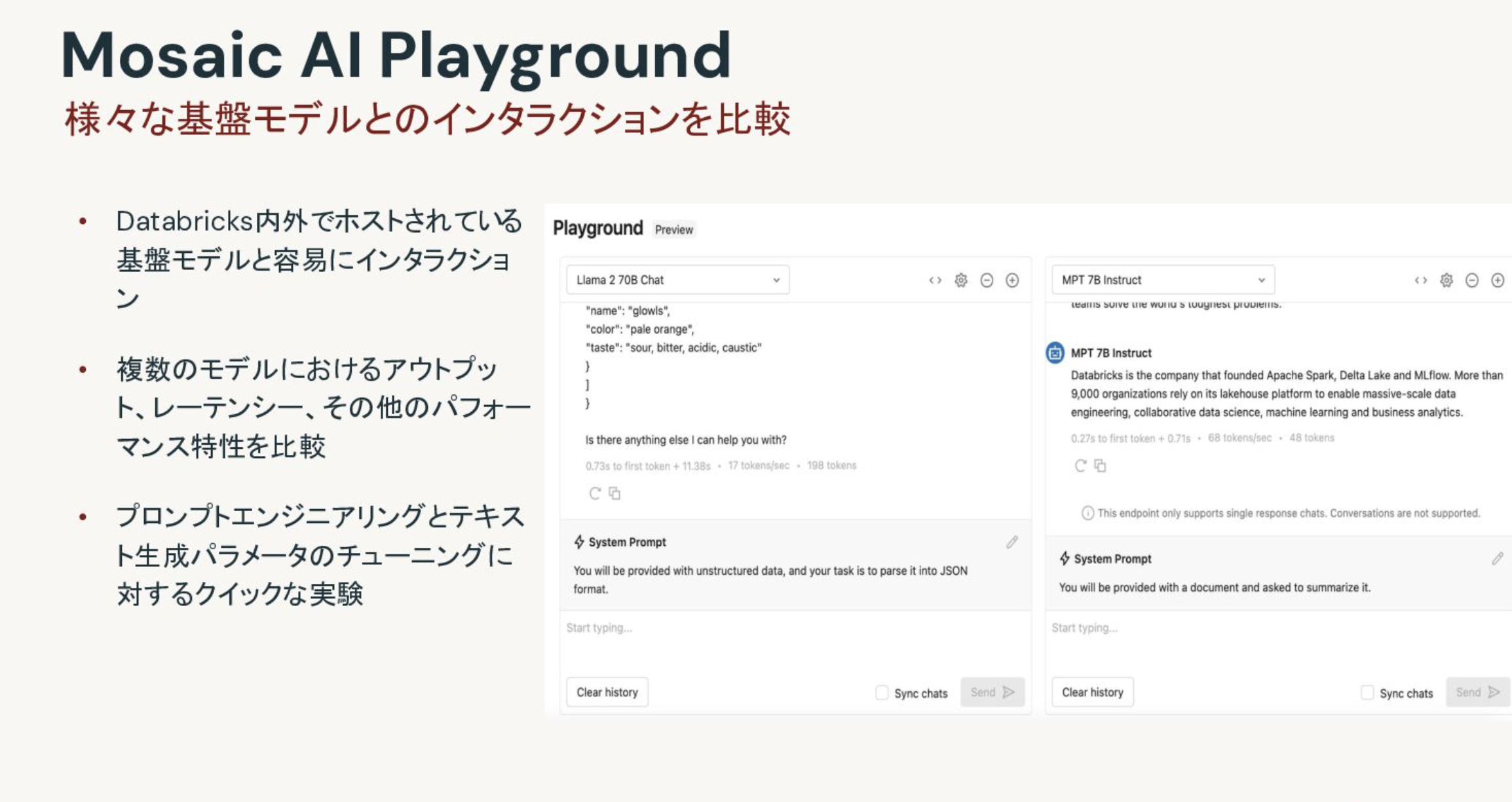
この他にも、RAGの構築では欠かせないプロンプトエンジニアリングに役立つ機能も提供しています。これがAI Playgroundです。AI Playgroundでは、様々なLLMに対して同時に同じプロンプトを投入することができます。これによってレスポンスを直接比較することができるようになります。
生成AIモデルの文脈付け
RAGにおいては、クエリーにヒットしたドキュメントとクエリーを組み合わせてレスポンスを生成します。この際、クエリーにヒットする文書を取得する際に重要な役割を担うのがベクトルデータベースです。すでにFAISSやChromaを使われているかもしれませんが、Databricks謹製のベクトルデータベースもあります。それが、Vector Searchです。

このVector Searchの良いところは、ソーステーブルの更新に合わせてベクトルDBを自動で更新できる機能だったり、Databricks環境に組み込まれているので既にお持ちのデータをベースにして容易にRAGを構築できるということです。
アプリのデプロイと監視
RAGを作って終わりではありません(自分自身、この論調頻繁に使ってますが)。そのアプリケーションが期待した通りに動作しているのかどうかを監視する必要があります。
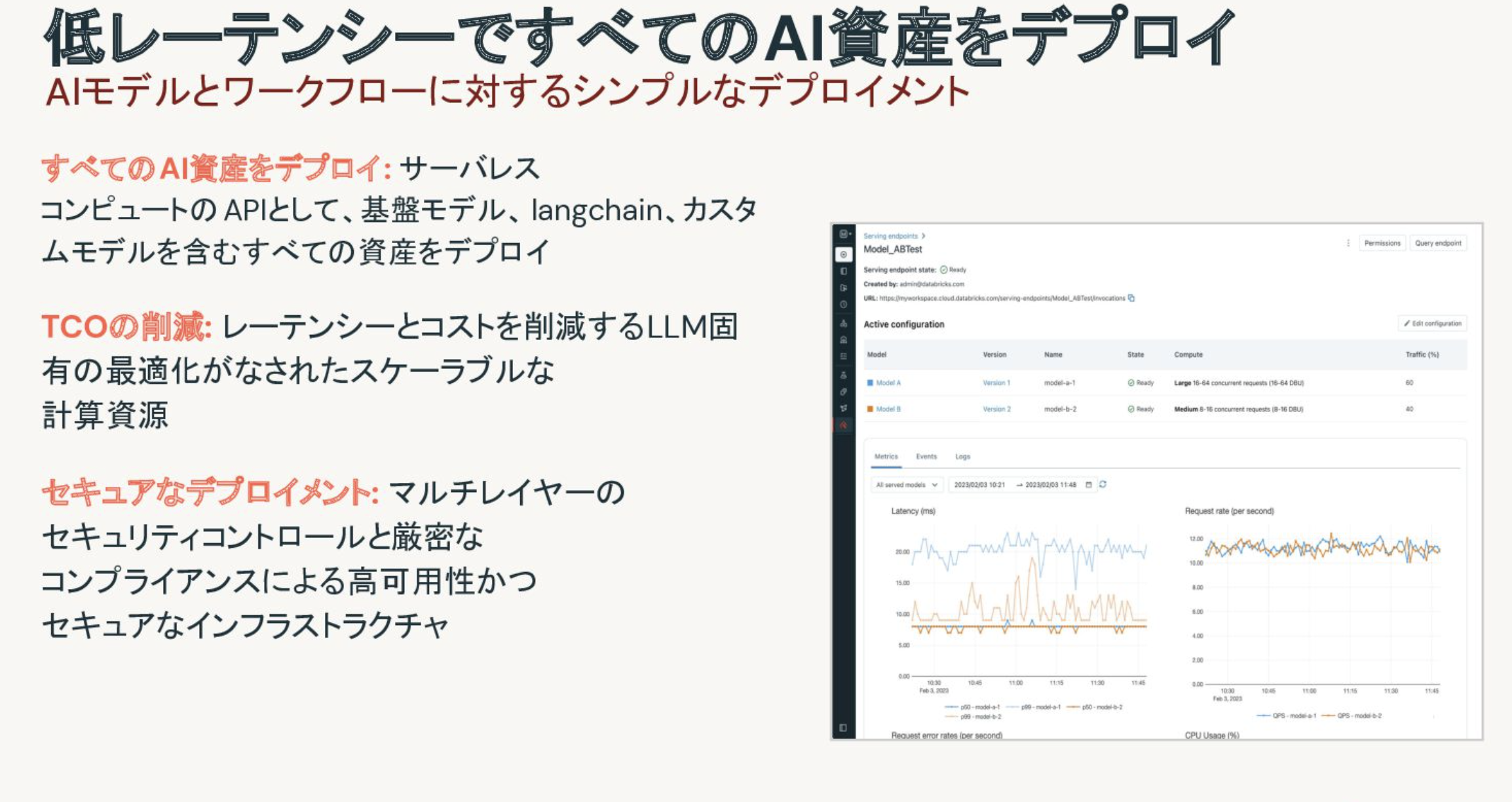
そのためには、上述のモデルサービングに推論テーブルとレイクハウスモニタリングを組み合わせることができます。この機能を活用することで、RAGアプリケーションへの入力とそれに対するレスポンスを記録することができ、必要に応じてアクションを講じることができるようになります。
デモ
ここまで資料での説明でしたので、このあとは実機デモを行いました。以下の記事に記載されている内容です。
LTということでしたので、これで9分弱でした。