こちらの後編です。01-quickstart/02-Deploy-RAG-Chatbot-Modelを実行していきます。
前編で準備したVector Search Indexを用いて、RAGのアプリケーションを構築します。
翻訳版のノートブックはこちらです。
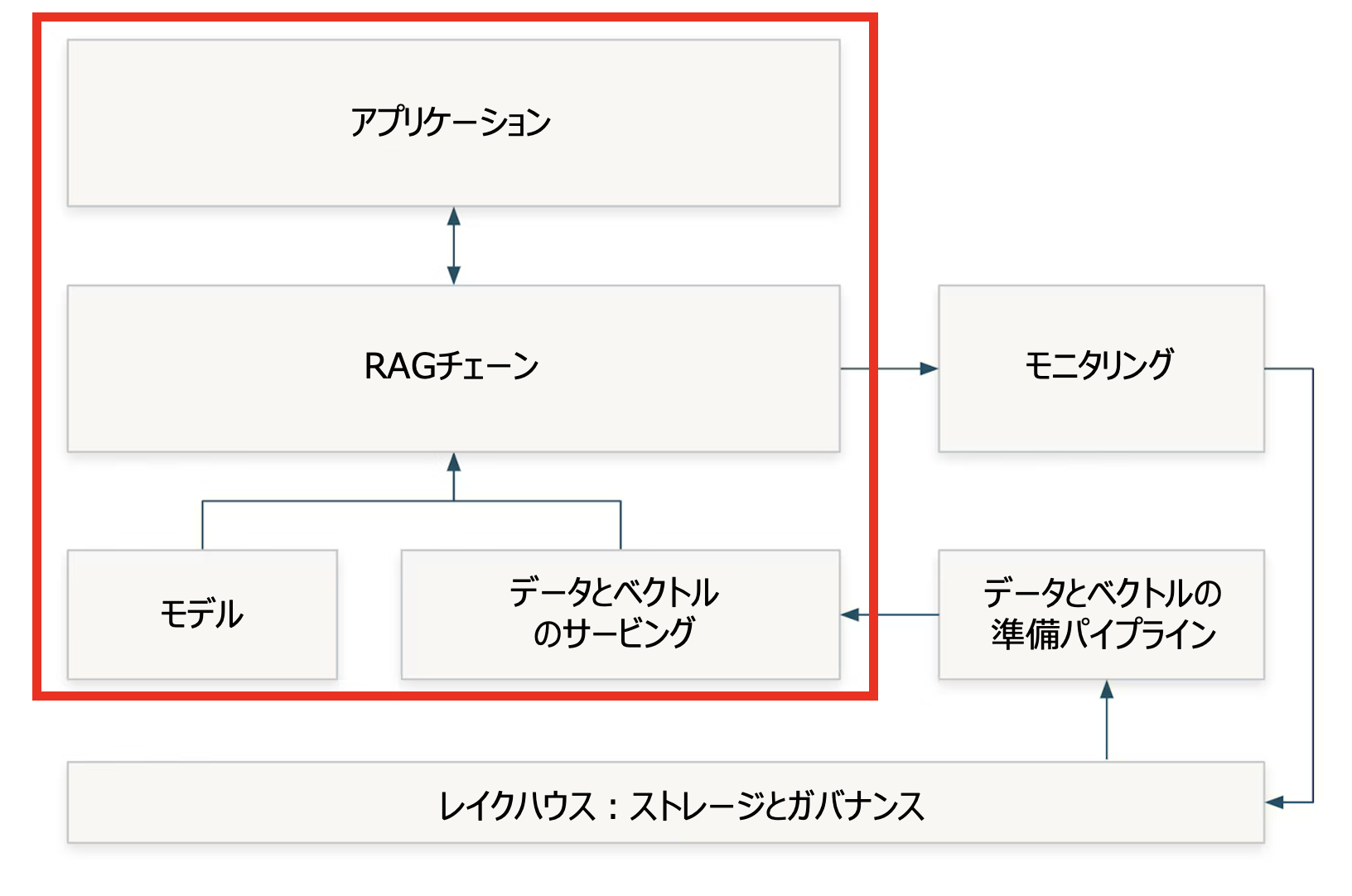
2/ Retrieval Augmented Generation (RAG)とDBRX Instructによるチャットbotの作成
Vector Search Indexの準備ができました!
RAGを実行するための新たなモデルサービングエンドポイントを作成して、デプロイしましょう。
流れは以下の通りとなります:
- ユーザーが質問します
- 質問がサーバレスChatbot RAGエンドポイントに送信されます
- エンドポイントがエンべディングを計算し、Vector Search Indexを活用して質問に類似した文書を検索します。
- エンドポイントは、文書で補強されたプロンプトを生成します
- プロンプトはDBRX Instruct Foundation Modelサービングエンドポイントに送信されます
- ユーザーにアウトプットを出力します!
注意
RAGはDatabricks Vector Searchを用いて文書を検索します。このノートブックでは、search indexの準備ができていることを前提としています。以前の01-Data-Preparation-and-Indexノートブックを必ず実行してください。
必要なライブラリのインストール
%pip install mlflow==2.10.1 langchain==0.1.5 databricks-vectorsearch==0.22 databricks-sdk==0.18.0 mlflow[databricks]
dbutils.library.restartPython()
%run ../_resources/00-init $reset_all_data=false
このデモを動作させるにはシークレットが必要です:
使用するモデルサービングエンドポイントには、あなたのVector Search Indexに対して認証を行うためのシークレットが必要です。(ドキュメントをご覧ください)
共有のデモワークスペースを使用している場合、シークレットがセットアップされている場合があるので、以下のステップを実行して値を上書きしないようにしてください。
- ラップトップあるいはクラスターのターミナルでDatabricks CLIをセットアップする必要があります:
pip install databricks-cli - CLIを設定します。お使いのワークスペースのURLや自分のプロフィールページからPATトークンが必要となります。
databricks configure - シークレットのスコープを作成します:
databricks secrets create-scope dbdemos - サービスプリンシパルのシークレットを保存します。モデルのエンドポイントが認証を行うために使用されます。これがデモやテストの場合、ご自身のPATトークンを使うことができます。
databricks secrets put-secret dbdemos rag_sp_token
注意
お使いのサービスプリンシパルがVector Search indexへのアクセス権を持つことを確認してください:
spark.sql('GRANT USAGE ON CATALOG <catalog> TO `<YOUR_SP>`');
spark.sql('GRANT USAGE ON DATABASE <catalog>.<db> TO `<YOUR_SP>`');
from databricks.sdk import WorkspaceClient
import databricks.sdk.service.catalog as c
WorkspaceClient().grants.update(c.SecurableType.TABLE, <index_name>,
changes=[c.PermissionsChange(add=[c.Privilege["SELECT"]], principal="<YOUR_SP>")])
お使いのSPがご自身のVector Search Indexに読み取り権限があることを確認してください
index_name=f"{catalog}.{db}.databricks_documentation_vs_index"
host = "https://" + spark.conf.get("spark.databricks.workspaceUrl")
test_demo_permissions(host, secret_scope="demo-token-takaaki.yayoi", secret_key="rag_sp_token", vs_endpoint_name=VECTOR_SEARCH_ENDPOINT_NAME, index_name=index_name, embedding_endpoint_name="taka-text-embedding-ada-002")
----------------------------
You are in a Shared FE workspace. Please don't override the secret value (it's set to the SP `takaaki.yayoi@databricks.com`).
---------------------------
Secret and permissions seems to be properly setup, you can continue the demo!
Langchain retriever

Langchain retrieverの構築を始めましょう。
これは以下のことに責任を持ちます:
- 入力の質問を作成します (我々のマネージドVector Search Indexがエンべディングの計算を行なってくれます)
- プロンプトを拡張するための類似文書を検索するためにvector search indexを呼び出します
Databricks Langchainラッパーは、1ステップでこれを行うことを簡単にし、背後のロジックやAPIの呼び出しの面倒を見てくれます。
モデルの認証のセットアップ
# サーバレスエンドポイントからモデルにリクエストを送るために使用されるURL
host = "https://" + spark.conf.get("spark.databricks.workspaceUrl")
os.environ['DATABRICKS_TOKEN'] = dbutils.secrets.get("demo-token-takaaki.yayoi", "rag_sp_token")
Databricks Embedding Retriever
from databricks.vector_search.client import VectorSearchClient
from langchain_community.vectorstores import DatabricksVectorSearch
from langchain_community.embeddings import DatabricksEmbeddings
# エンべディングLangchainモデルのテスト
# 注意: お使いの質問のエンべディングモデルは以前のノートブックのチャンクで用いられたものとマッチしなくてはなりません
embedding_model = DatabricksEmbeddings(endpoint="taka-text-embedding-ada-002")
print(f"Test embeddings: {embedding_model.embed_query('Sparkとは?')[:20]}...")
def get_retriever(persist_dir: str = None):
os.environ["DATABRICKS_HOST"] = host
# vector search indexの取得
vsc = VectorSearchClient(workspace_url=host, personal_access_token=os.environ["DATABRICKS_TOKEN"])
vs_index = vsc.get_index(
endpoint_name=VECTOR_SEARCH_ENDPOINT_NAME,
index_name=index_name
)
# retrieverの作成
vectorstore = DatabricksVectorSearch(
vs_index, text_column="content", embedding=embedding_model
)
return vectorstore.as_retriever()
# retrieverのテスト
vectorstore = get_retriever()
similar_documents = vectorstore.get_relevant_documents("Databricksクラスターとは?")
print(f"Relevant documents: {similar_documents[0]}")
Test embeddings: [-0.0044542723, -0.017397067, 0.0047252546, -0.017993227, -0.018182915, 0.0040545734, -0.009802787, -0.0018850209, -0.009545353, -0.018210014, 0.01811517, 0.022586377, -0.010859617, -0.015730524, 0.0014726197, 0.0028503956, 0.025553634, -0.027884083, 0.009707943, -0.026474975]...
[NOTICE] Using a Personal Authentication Token (PAT). Recommended for development only. For improved performance, please use Service Principal based authentication. To disable this message, pass disable_notice=True to VectorSearchClient().
Relevant documents: page_content='クラスター\nDatabricks Data Science & Engineeringクラスターと Databricks Machine Learningクラスターは、本番運用ETLパイプラインの実行、ストリーミング分析、アドホック分析、機械学習などのさまざまなユースケースに対応する統合プラットフォームを提供します。クラスターは、Databricksコンピュートリソースの一種です。他のコンピュートリソースタイプには、Databricks SQLウェアハウスなどがあります。 \nクラスターの管理と使用の詳細については、「 コンピューティング」を参照してください。\n\nノートブック' metadata={'id': 13439.0}
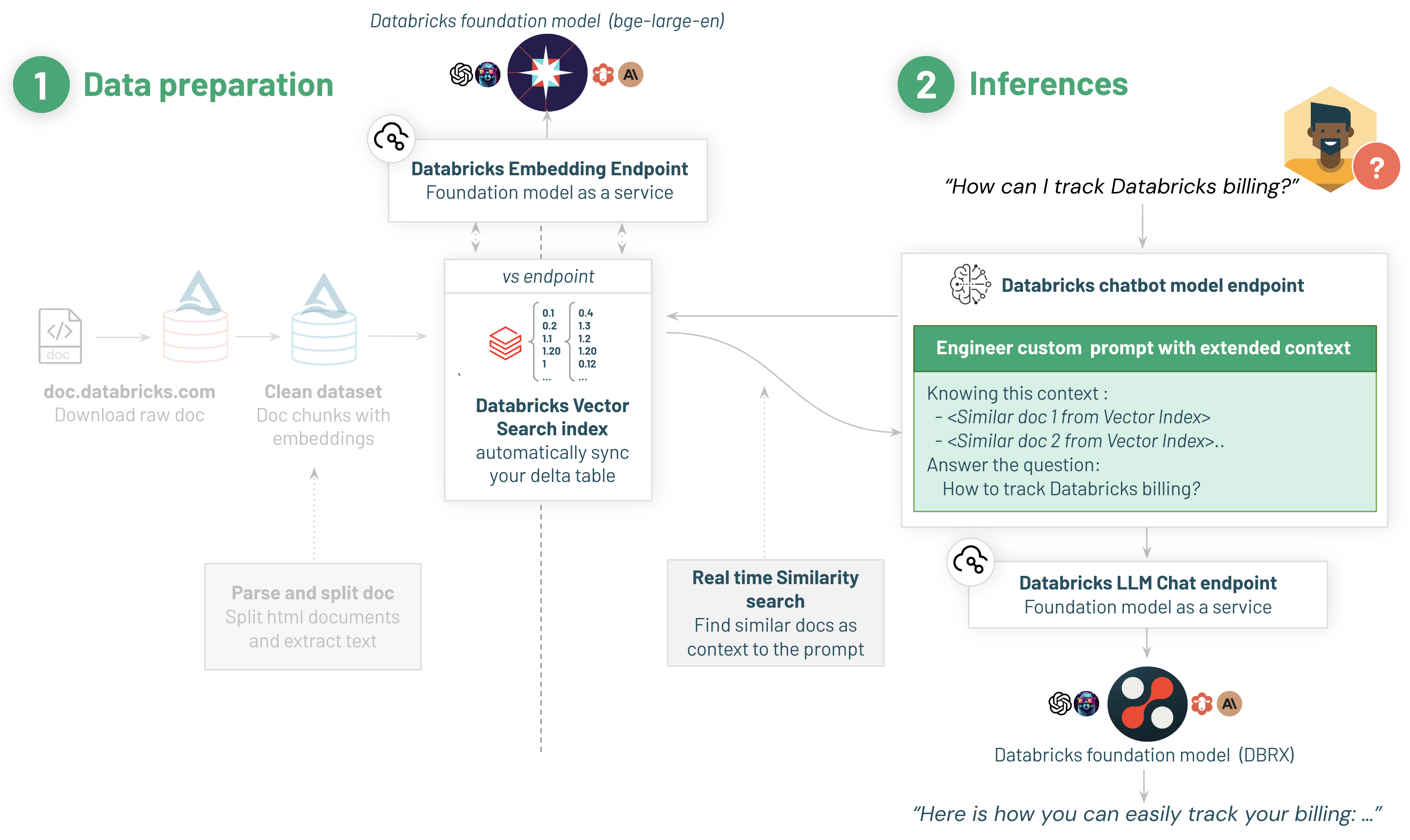
Databricks DBRX Instruct基盤モデルに問い合わせを行うDatabricks Chatモデルの構築

我々のチャットボットは回答を提供するために、Databricks DBRX Instruct基盤モデルを使用します。DBRX Instructは、企業レベルのGenAIアプリケーションの開発のために構築された汎用LLMであり、これまではクローズドモデルのAPIに限定されていた機能で、皆様のユースケースを解放します。
我々の計測によれば、DBRXはGPT-3.5を上回っており、Gemini 1.0 Proと並ぶものとなっています。汎用LLMとしての強みに加えて、優れたコードモデルであり、プログラミングに特化したCodeLLaMA-70Bのような特化モデルと比類するものとなっています。
注意: 複数タイプのエンドポイントやlangchainモデルを活用することができます:
- Databricks基盤モデル (こちらを使います)
- ご自身でファインチューンしたモデル
- 外部のモデルプロバイダー (Azure OpenAIなど)
# Databricks Foundation LLMモデルのテスト
from langchain_community.chat_models import ChatDatabricks
chat_model = ChatDatabricks(endpoint="databricks-dbrx-instruct", max_tokens = 500)
print(f"Test chat model: {chat_model.predict('Apache Sparkとは?日本語で教えて')}")
Test chat model: Apache Sparkは、データ処理のためのオープンソースの分散型計算システムです。高速で、拡張性があり、高度な分析を実行することができます。Sparkは、MapReduceの代替として設計されており、Hadoopのような分散ストレージシステムと組み合わせて使用することができます。Sparkは、SQL、Machine Learning、Graph Processingなど、さまざまな処理をサポートしています。
完全なRAGチェーンの構築

単一のLangchainのチェーンにretrieverとモデルをまとめましょう。
アシスタントが適切な回答を提供できるように、カスタムのlangchainテンプレートを使用します。
ご自身の要件に基づき、様々なテンプレートを試し、アシスタントの口調や個性を調整するのにある程度の時間を取るようにしてください。
Databricksアシスタントのチェーン
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatDatabricks
TEMPLATE = """私はDatabricksユーザーのためのアシスタントです。Python、コーディング、SQL、データエンジニアリング、Spark、データサイエンス、DWおよびプラットフォーム、APIまたはインフラ管理に関連する質問に回答します。これらのトピックに関連しない質問の場合は、丁重に回答を辞退します。答えがわからない場合は、「わかりません」とだけ言います。回答はできるだけ簡潔な日本語にしてください。
最後に質問に回答するために以下のコンテキストのピースを使ってください:
{context}
質問: {question}
回答:
"""
prompt = PromptTemplate(template=TEMPLATE, input_variables=["context", "question"])
chain = RetrievalQA.from_chain_type(
llm=chat_model,
chain_type="stuff",
retriever=get_retriever(),
chain_type_kwargs={"prompt": prompt}
)
ノートブックから直接チャットbotを試しましょう
# langchain.debug = True # チェーンの詳細や送信される完全なプロンプトを確認するにはコメントを解除してください
#question = {"query": "How can I track billing usage on my workspaces?"}
question = {"query": "ワークスペースの使用量を追跡するにはどうしたらいいですか?"}
answer = chain.run(question)
print(answer)
ワークスペースの使用量を追跡するには、Databricks のアカウント コンソールにアクセスし、使用量タブをクリックします。このページには、ワークスペースの使用量 (DBU)、ストレージ使用量、およびその他の関連情報が表示されます。
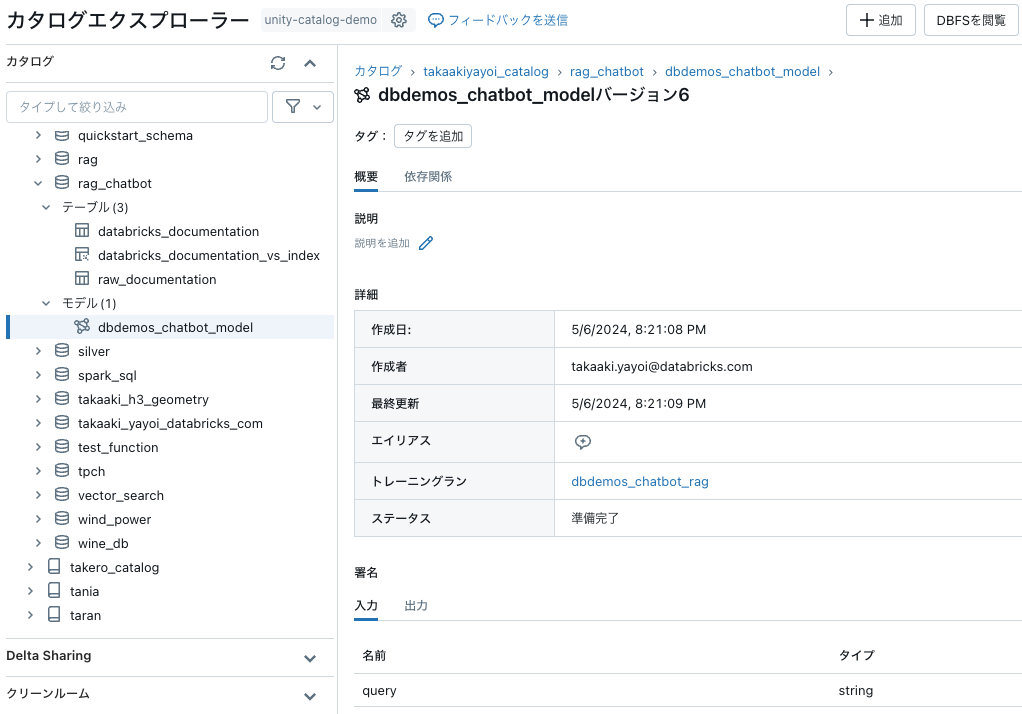
Unity Catalogレジストリにモデルを保存
モデルの準備ができたので、Unity Catalogのスキーマにモデルを登録することができます:
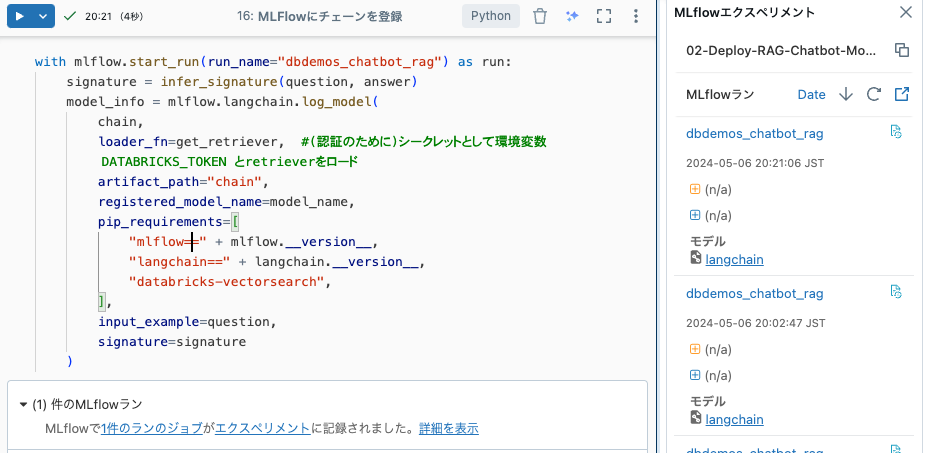
MLFlowにチェーンを登録
from mlflow.models import infer_signature
import mlflow
import langchain
mlflow.set_registry_uri("databricks-uc")
model_name = f"{catalog}.{db}.dbdemos_chatbot_model"
with mlflow.start_run(run_name="dbdemos_chatbot_rag") as run:
signature = infer_signature(question, answer)
model_info = mlflow.langchain.log_model(
chain,
loader_fn=get_retriever, #(認証のために)シークレットとして環境変数 DATABRICKS_TOKEN とretrieverをロード
artifact_path="chain",
registered_model_name=model_name,
pip_requirements=[
"mlflow==" + mlflow.__version__,
"langchain==" + langchain.__version__,
"databricks-vectorsearch",
],
input_example=question,
signature=signature
)
サーバレスモデルエンドポイントにChatモデルをデプロイ
モデルがUnity Catalogに保存されたので、最後のステップはこれをモデルサービングにデプロイすることとなります。
これによって、アシスタントのフロントエンドからリクエストを送信できるようになります。
# サービングエンドポイントの作成、更新
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedModelInput, ServedModelInputWorkloadSize
serving_endpoint_name = f"dbdemos_endpoint_{catalog}_{db}"[:63]
latest_model_version = get_latest_model_version(model_name)
w = WorkspaceClient()
endpoint_config = EndpointCoreConfigInput(
name=serving_endpoint_name,
served_models=[
ServedModelInput(
model_name=model_name,
model_version=latest_model_version,
workload_size=ServedModelInputWorkloadSize.SMALL,
scale_to_zero_enabled=True,
environment_vars={
"DATABRICKS_TOKEN": "{{secrets/demo-token-takaaki.yayoi/rag_sp_token}}", # アクセストークンを保持する <scope>/<secret>
}
)
]
)
existing_endpoint = next(
(e for e in w.serving_endpoints.list() if e.name == serving_endpoint_name), None
)
serving_endpoint_url = f"{host}/ml/endpoints/{serving_endpoint_name}"
if existing_endpoint == None:
print(f"Creating the endpoint {serving_endpoint_url}, this will take a few minutes to package and deploy the endpoint...")
w.serving_endpoints.create_and_wait(name=serving_endpoint_name, config=endpoint_config)
else:
print(f"Updating the endpoint {serving_endpoint_url} to version {latest_model_version}, this will take a few minutes to package and deploy the endpoint...")
w.serving_endpoints.update_config_and_wait(served_models=endpoint_config.served_models, name=serving_endpoint_name)
displayHTML(f'Your Model Endpoint Serving is now available. Open the <a href="/ml/endpoints/{serving_endpoint_name}">Model Serving Endpoint page</a> for more details.')
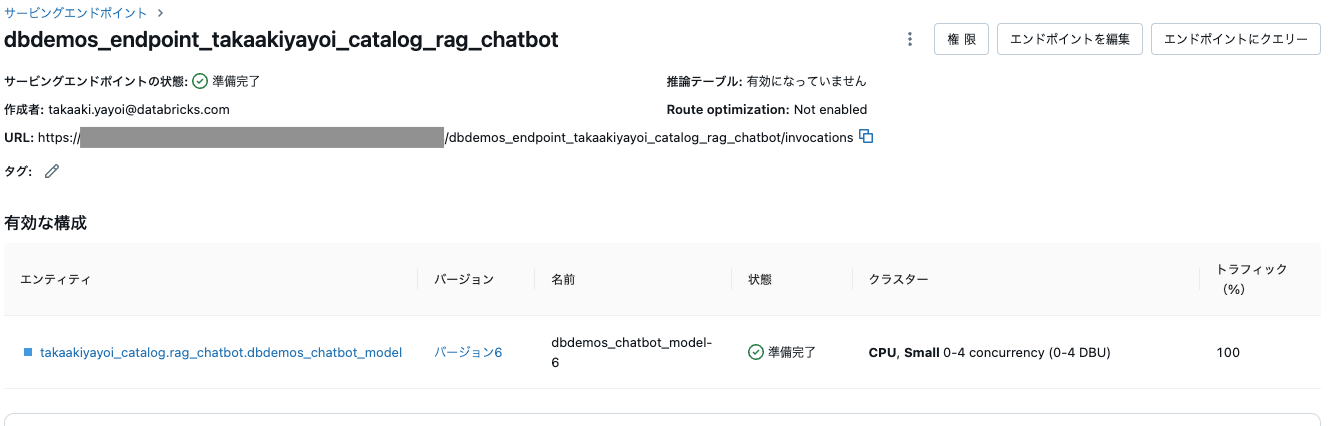
エンドポイントがデプロイされました!サービングエンドポイントのUIでエンドポイントを検索し、パフォーマンスを可視化することができます!
PythonでRESTクエリーを実行して試してみましょう。
チャットbotにクエリーを送信してみましょう
#question = "How can I track billing usage on my workspaces?"
question = "ワークスペースの使用量を追跡するにはどうしたらいいですか?"
answer = w.serving_endpoints.query(serving_endpoint_name, inputs=[{"query": question}])
print(answer.predictions[0])
ワークスペースの使用量を追跡するには、Databricks のアカウント コンソールにアクセスし、使用量タブをクリックします。このページには、ワークスペースの使用量、DBU の使用量、およびストレージの使用量など、ワークスペースの使用状況に関する詳細情報が表示されます。
question = "サーバレスを使うことのメリットは"
answer = w.serving_endpoints.query(serving_endpoint_name, inputs=[{"query": question}])
print(answer.predictions[0])
サーバレスコンピューティングを使用することのメリットには、次のようなものがあります。
1. オートスケーリング: サーバレスコンピューティングでは、ワークロードに応じて自動的にリソースをスケールアウトまたはスケールインします。これにより、リソースの使用率を最適化し、コストを削減することができます。
2. クエリーキューイング: サーバレスコンピューティングでは、クエリーキューイング機能を使用して、リソースが利用可能になるまでクエリをキューに入れることができます。これにより、ワークロードのピーク時にも高いパフォーマンスを維持することができます。
3. カスタマーマネージドキー: サーバレスコンピューティングでは、カスタマーマネージドキーを使用して、データを暗号化することができます。これにより、データのセキュリティを強化することができます。
4. 管理の容易さ: サーバレスコンピューティングでは、インフラストラクチャの管理を行う必要がないため、ユーザーはアプリケーションの開発に専念することができます。
これらのメリットにより、サーバレスコンピューティングは、データ処理や分析などのワークロードに適した選択肢となります。
なお、これまでに作成したデータセットやベクトルストア、モデルはすべてUnity Catalogで管理されています。
おめでとうございます!最初のGenAI RAGモデルをデプロイしました!
Lakehouse AIを活用することで、皆様の内部の知識に対して同じロジックをデプロイすることができる準備ができました。
皆様のGenAIの課題の解決にLakehouse AIがどのようにユニークに位置づけられるのかを見てきました:
- Databricksのエンジニアリング機能でデータの取り込みと準備をシンプルに
- 完全にマネージドなインデックスでVector Searchのデプロイメントを加速
- Databricks DBRX Instruct基盤モデルエンドポイントの活用
- RAGを実行し、Q&A機能を提供するためのリアルタイムモデルエンドポイントのデプロイ
Lakehouse AIは皆様のGenAIデプロイメントを加速するためのユニークなソリューションです。
おまけ: GUIの構築
せっかくなのでGUIを作ります。Streamlitを使います。
import streamlit as st
import numpy as np
import json
import requests
import pandas as pd
from databricks.sdk.runtime import dbutils
st.title('Databricks Q&A bot')
#st.header('Databricks Q&A bot')
def generate_answer(question):
# Driver Proxyと異なるクラスター、ローカルからDriver Proxyにアクセスする際にはパーソナルアクセストークンを設定してください
token = dbutils.secrets.get("demo-token-takaaki.yayoi", "rag_sp_token")
url = "<モデルサービングエンドポイントのURL>"
headers = {
"Content-Type": "application/json",
"Authentication": f"Bearer {token}"
}
data = {
"query": question
}
prompt = pd.DataFrame(
{"query": [question]}
)
#print(prompt)
ds_dict = {"dataframe_split": prompt.to_dict(orient="split")}
response = requests.post(url, headers=headers, data=json.dumps(ds_dict))
if response.status_code != 200:
raise Exception(
f"Request failed with status {response.status_code}, {response.text}"
)
response_json = response.json()
#print(response_json)
return response_json
if "messages" not in st.session_state:
st.session_state.messages = []
# アプリの再実行の際に履歴のチャットメッセージを表示
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# ユーザー入力に対する反応
if prompt := st.chat_input("Databricksに関して何を知りたいですか?"):
# チャットメッセージコンテナにユーザーメッセージを表示
st.chat_message("user").markdown(prompt)
# チャット履歴にユーザーメッセージを追加
st.session_state.messages.append({"role": "user", "content": prompt})
with st.spinner('回答を生成中...'):
bot_response = generate_answer(prompt)
#answer = bot_response["answer"]
answer = bot_response["predictions"][0]
#source = bot_response["source"]
response = f"""{answer}"""
#**ソース:** {source}"""
# チャットメッセージコンテナにアシスタントのレスポンスを表示
with st.chat_message("assistant"):
st.markdown(response)
# チャット履歴にアシスタントのレスポンスを追加
st.session_state.messages.append({"role": "assistant", "content": response})
上のアプリケーションを動作させるノートブックを作成します。
%pip install streamlit
dbutils.library.restartPython()
from dbruntime.databricks_repl_context import get_context
def front_url(port):
"""
フロントエンドを実行するための URL を返す
Returns
-------
proxy_url : str
フロントエンドのURL
"""
ctx = get_context()
proxy_url = f"https://{ctx.browserHostName}/driver-proxy/o/{ctx.workspaceId}/{ctx.clusterId}/{port}/"
return proxy_url
PORT = 1502
# Driver ProxyのURLを表示
print(front_url(PORT))
# 利便性のためにリンクをHTML表示
displayHTML(f"<a href='{front_url(PORT)}' target='_blank' rel='noopener noreferrer'>別ウインドウで開く</a>")
streamlit_fileのパスは適宜変更してください。
streamlit_file = "/Workspace/Users/takaaki.yayoi@databricks.com/20240505_databricks_rag/llm-rag-chatbot/01-quickstart/streamlit.py"
!streamlit run {streamlit_file} --server.port {PORT}
これで一通り動きました!
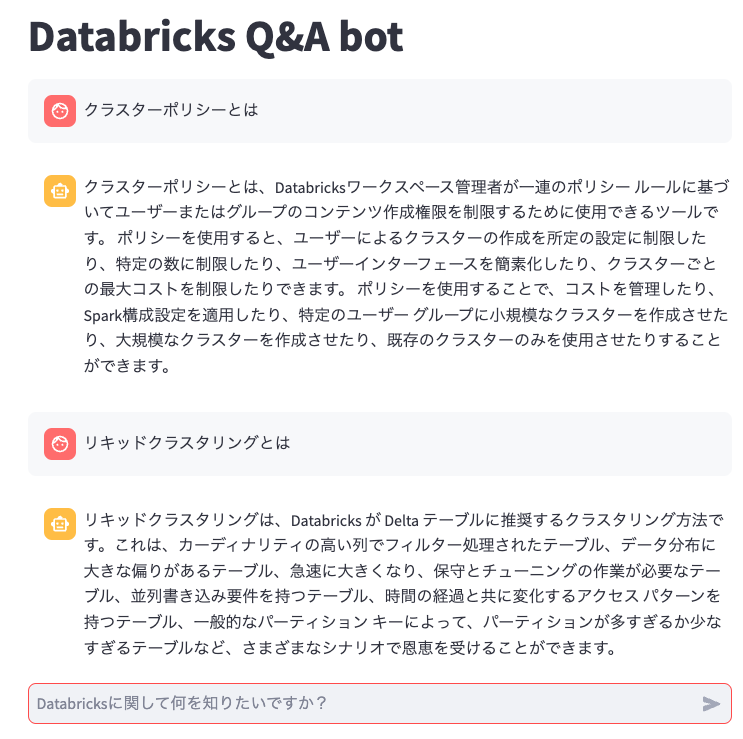
オリジナルから変更した点は以下の通りです。
- ソースデータを日本語にした
- エンべディングモデルを変更した
- プロンプトテンプレートを日本語にして、日本語で返すように指示した
- GUIを作った