How to Simply Scale ETL with Azure Data Factory and Azure Databricksの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
データレイクによって、企業は様々な種類のデータソースに対するセキュアかつタイムリーなアクセスを通じて、定常的に価値を提供することが可能になりました。このジャーニーにおける最初のステップは、堅牢なデータパイプラインを用いて取り込み処理をオーケストレーションし自動化することとなります。データのボリューム、種類、速度が急激に増加するにつれて、データを抽出、変換、ロード(ETL)するための高信頼かつセキュアなパイプラインへのニーズが高まりました。]
Databricksのユーザーは月当たり2エクサバイト(20億Gバイト)以上のデータを処理しており、Azure Databricksは現在Microsoft Azure上で急激に成長しているデータ&AIサービスとなっています。Azure Databricksと他のAzureサービスの間の密連携によって、お客様はデータ取り込みパイプラインをシンプルにし、スケールすることが可能となります。例えば、Azure Active Directoryとのインテグレーションによって、一貫性のあるクラウドベースのIDとアクセス管理を実現します。また、Azure Data Lake Storage (ADLS)との連携によって、ビッグデータ分析に対して高いスケーラビリティを持つセキュアなストレージを提供し、Azure Data Factory (ADF)を用いることで、大規模ETLをシンプルにするハイブリッドなデータ統合を実現します。
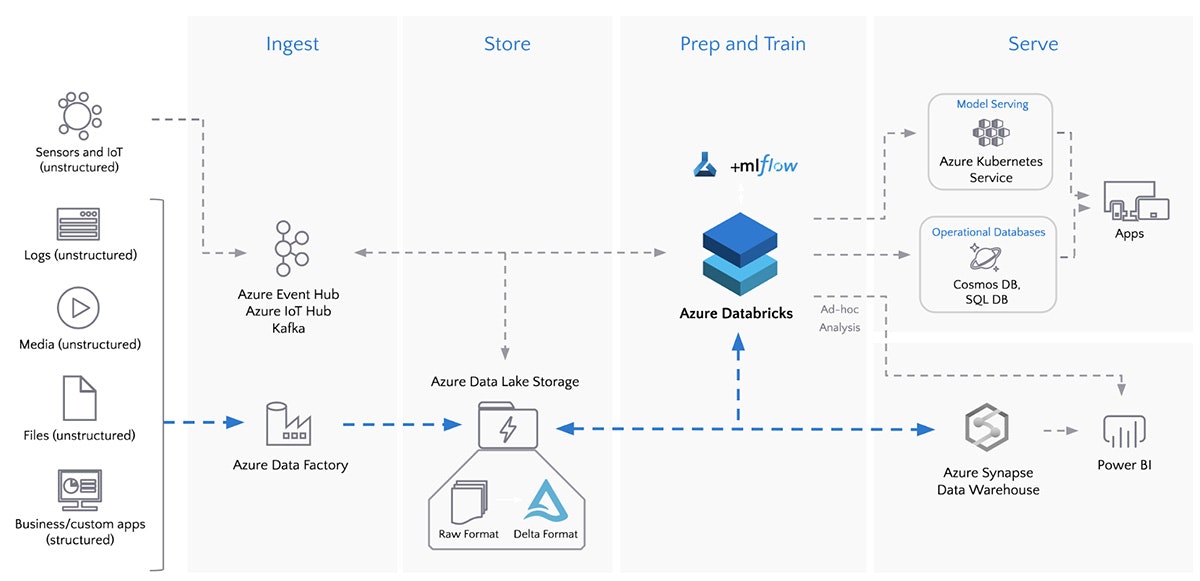
図: Azure Data FactoryとAzure DatabricksによるバッチETL
単一のワークフローによるデータへの接続、取り込み、変換
ADFには90以上のビルトインデータソースコネクターが含まれており、お使いの全てのデータソースに接続するためにシームレースにAzure Databricksノートブックを実行し、単一のデータレイクに取り込みます。また、ADFは信頼性のあるデータパイプラインの作成を支援するビルトインのワークフローコントロール、データ変換、パイプラインのスケジュール、データインテグレーション、そして、その他の機能も提供しています。ADFを用いることで、お客様は生のフォーマットのデータを取り込み、Azure DatabricksとDelta Lakeを用いることで、お使いのデータをブロンズ、シルバー、ゴールドテーブルに変換します。例えば、お使いのデータレイクに対するSQLクエリーを実行できるようにし、機械学習のためのデータパイプラインを構築するために、お客様は多くのケースでAzure DatabricksとDelta Lakeを活用しています。
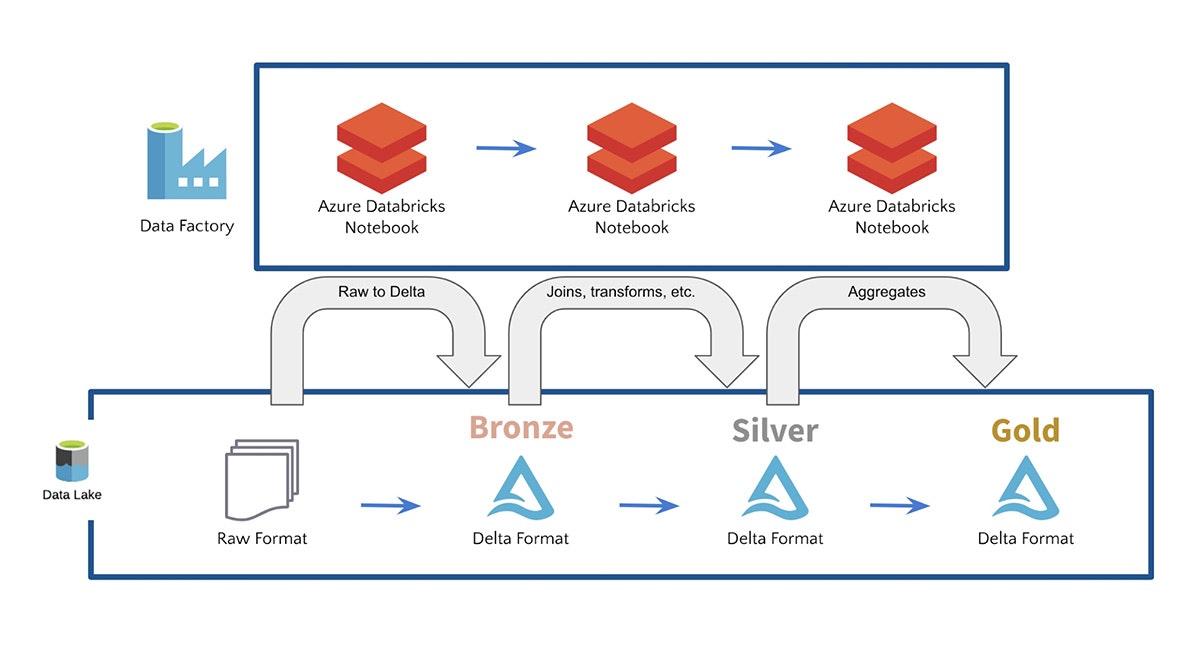
Azure DatabricksとAzure Data Factoryを使ってみる
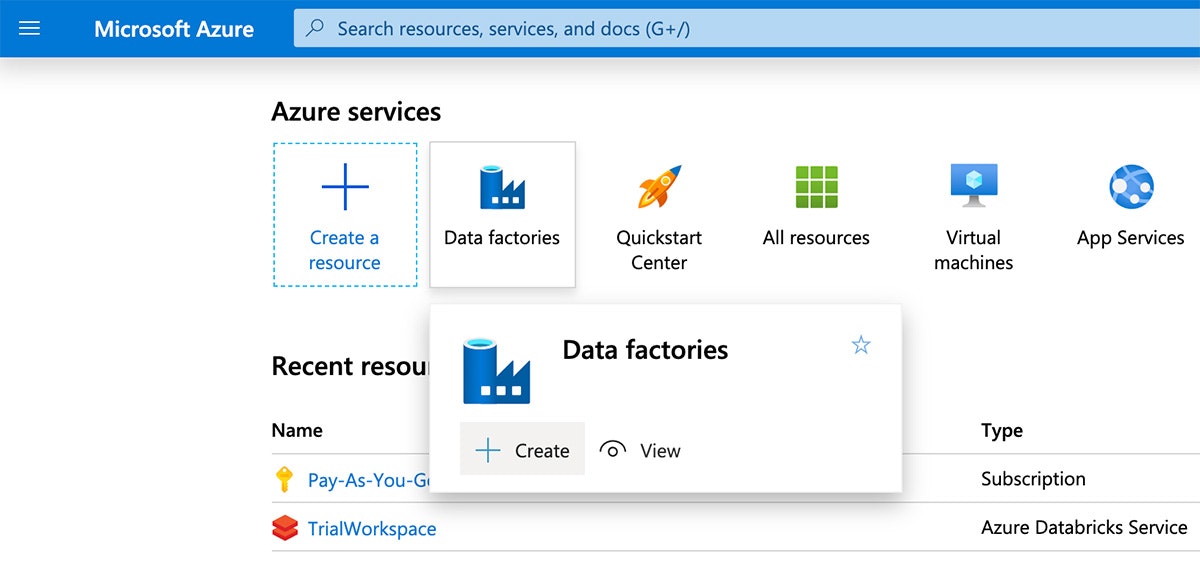
Azure Data Factoryを用いてAzure Databricksノートブックを実行するためには、Azureポータルに移動し、"Data factories"を検索し、新規データファクトリーを定義するために"create"をクリックします。
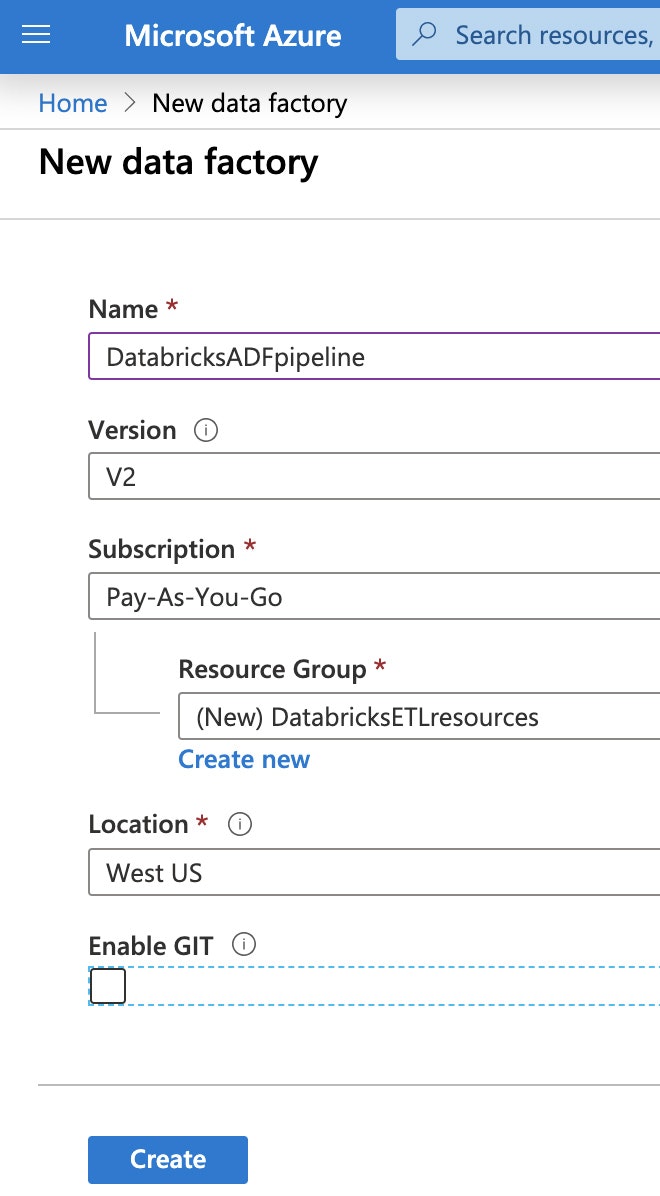
次に、データファクトリーの一意の名前を指定し、サブスクリプションを選択し、リソースグループとリージョンを選択します。"Create"をクリックします。
作成が終わったら、新規データファクトリーを参照するために"Go to resource"をクリックします。
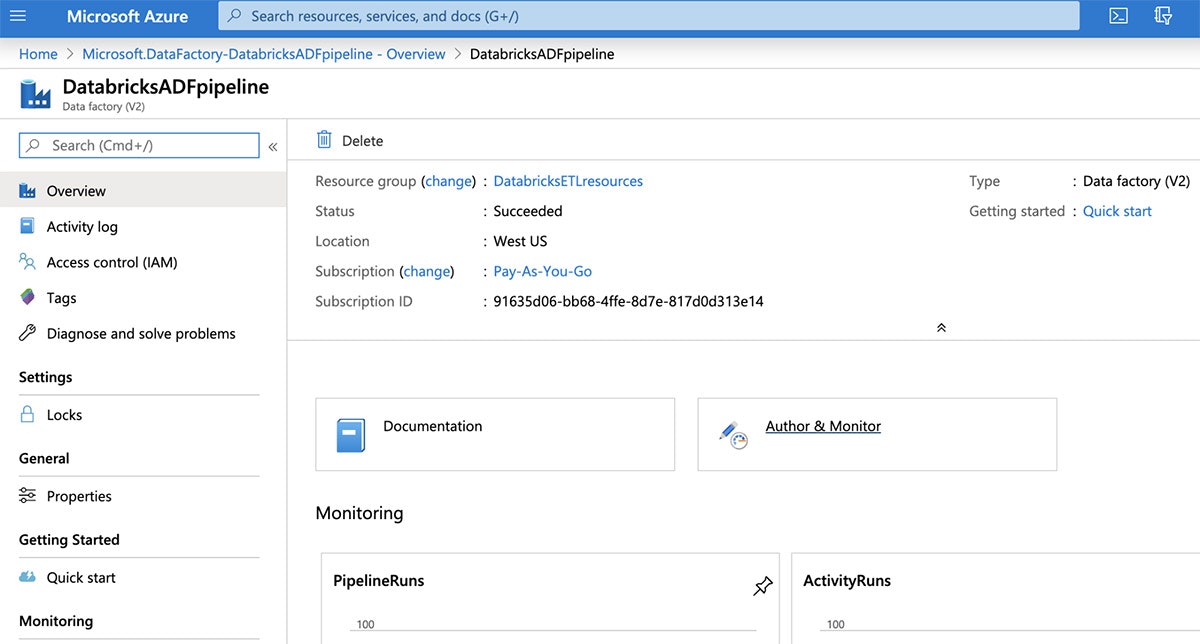
"Author & Monitor"タイルをクリックすることで、Data Factoryのユーザーインタフェースを開きます。
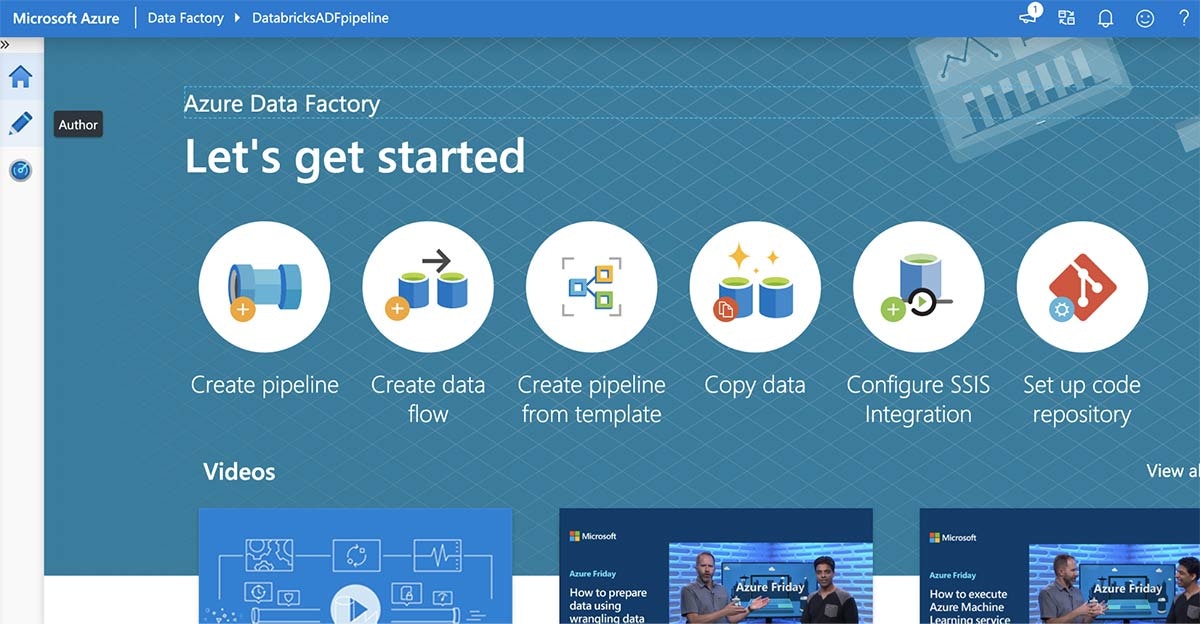
Azure Data Factoryの"Let’s get started"ページから、左のパネルの"Author"ボタンをクリックします。
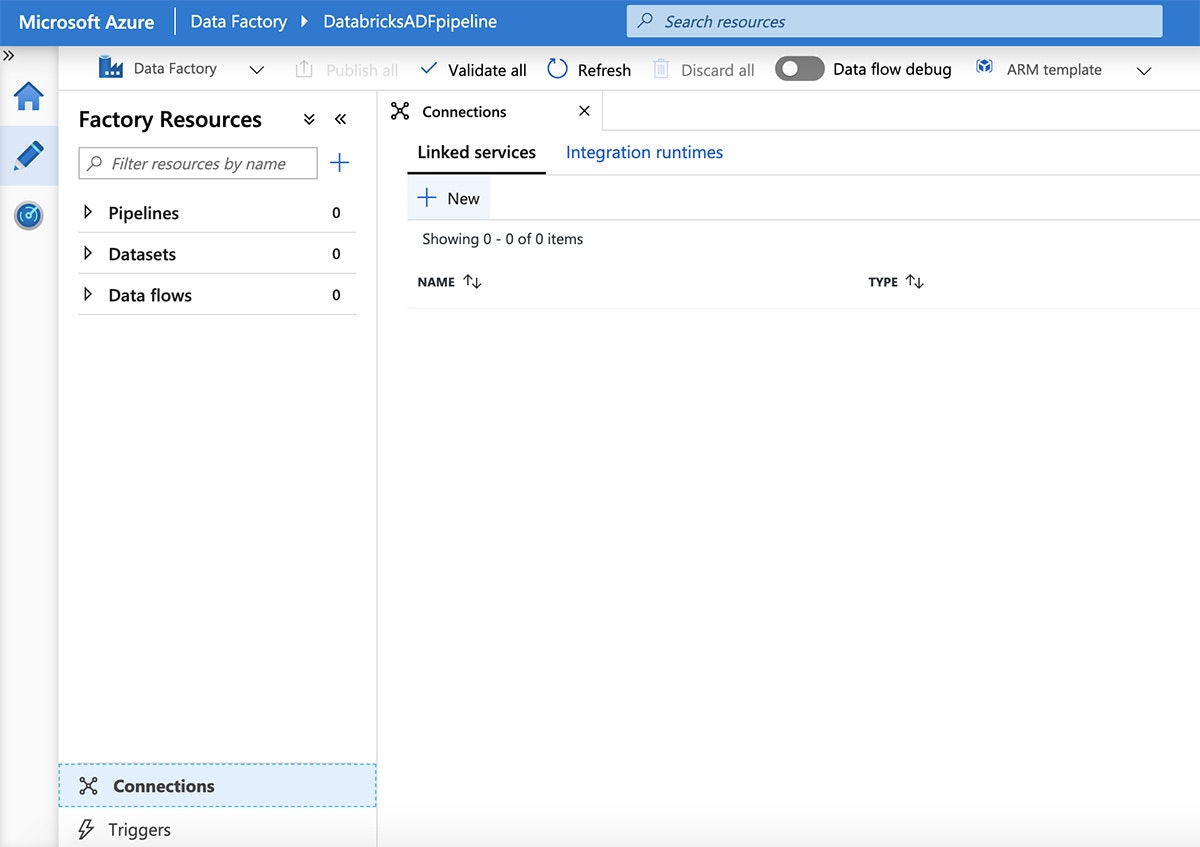
次に、画面下部の"Connections"をクリックし、"New"をクリックします。
"New linked service"ペインから"Compute"タブをクリックし、"Azure Databricks"を選択し、"Continue"をクリックします。
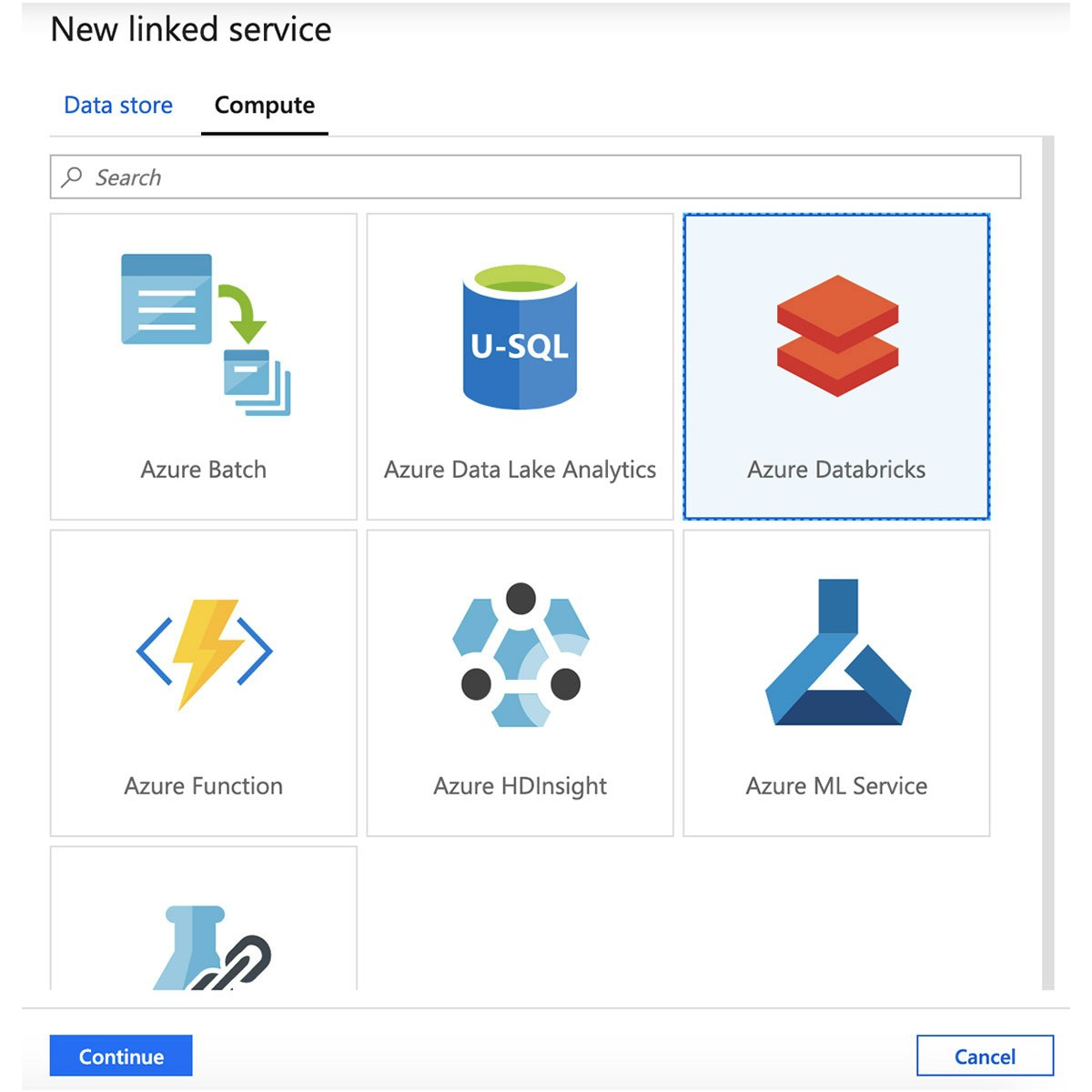
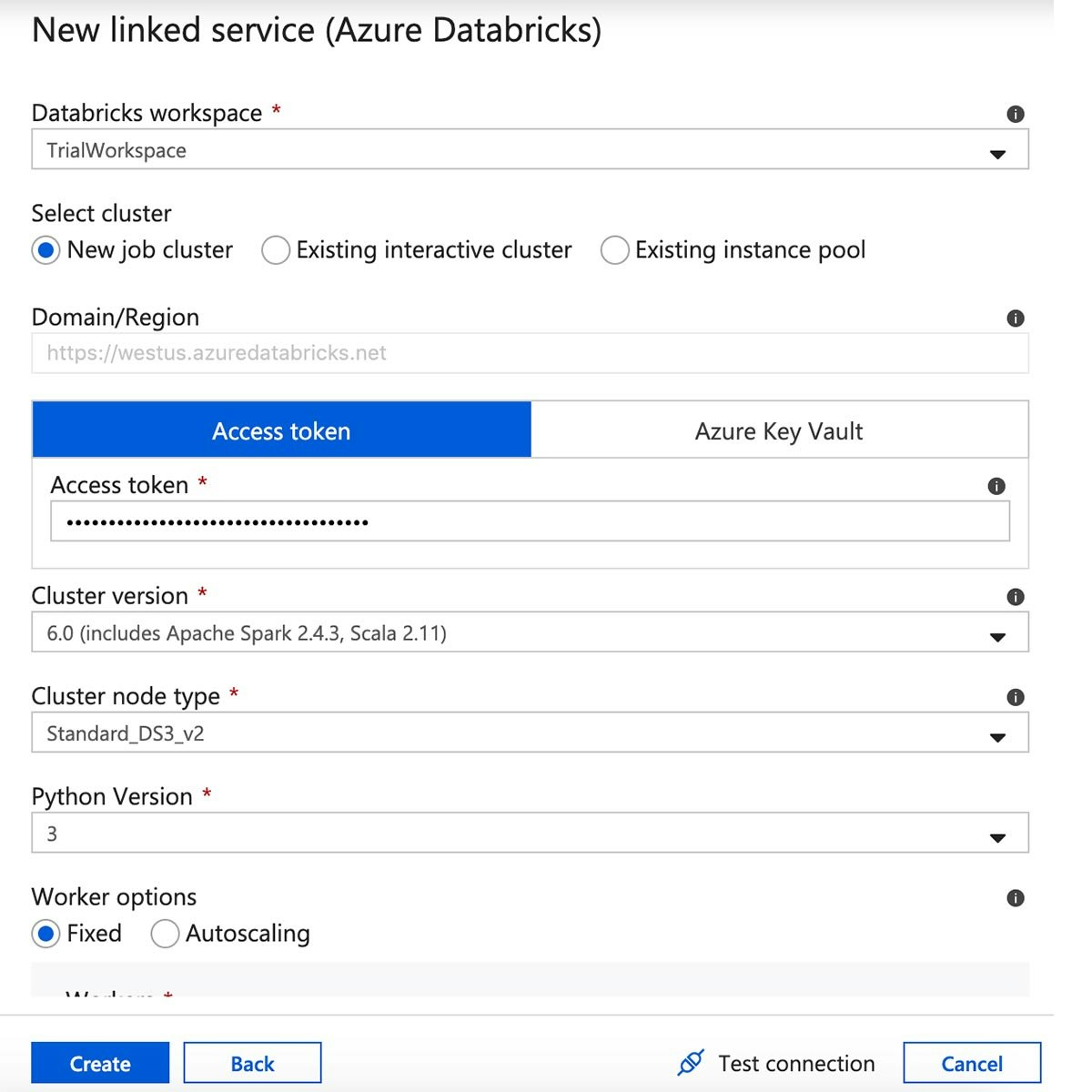
Azure Databricksのリンクサービスの名前を入力し、ワークスペースを選択します。
画面の右上にあるユーザーアイコンをクリックすることで、Azure Databricksワークスペースからアクセストークンを作成します。
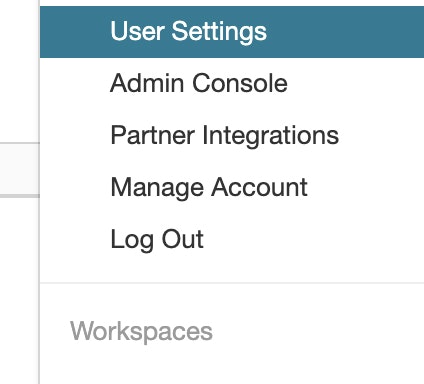
"Generate New Token"をクリックします。
リンクされたサービスのフォームにトークンをコピー&ペーストし、クラスターのバージョン、サイズ、Pythonのバージョンを選択します。設定を確認し、"Create"をクリックします。
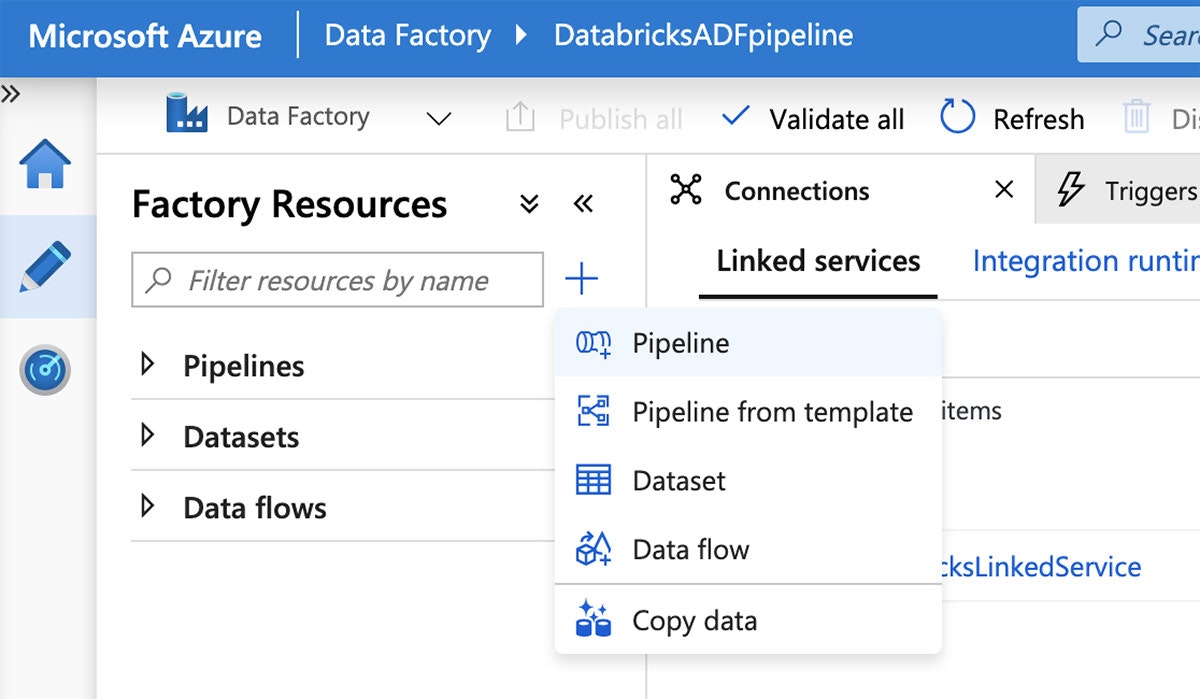
リンクされたサービスが出来上がったので、パイプラインを作成する準備が整いました。Azure Data FactoryのUIから、プラス(+)ボタンをクリックし、"Pipeline"を選択します。
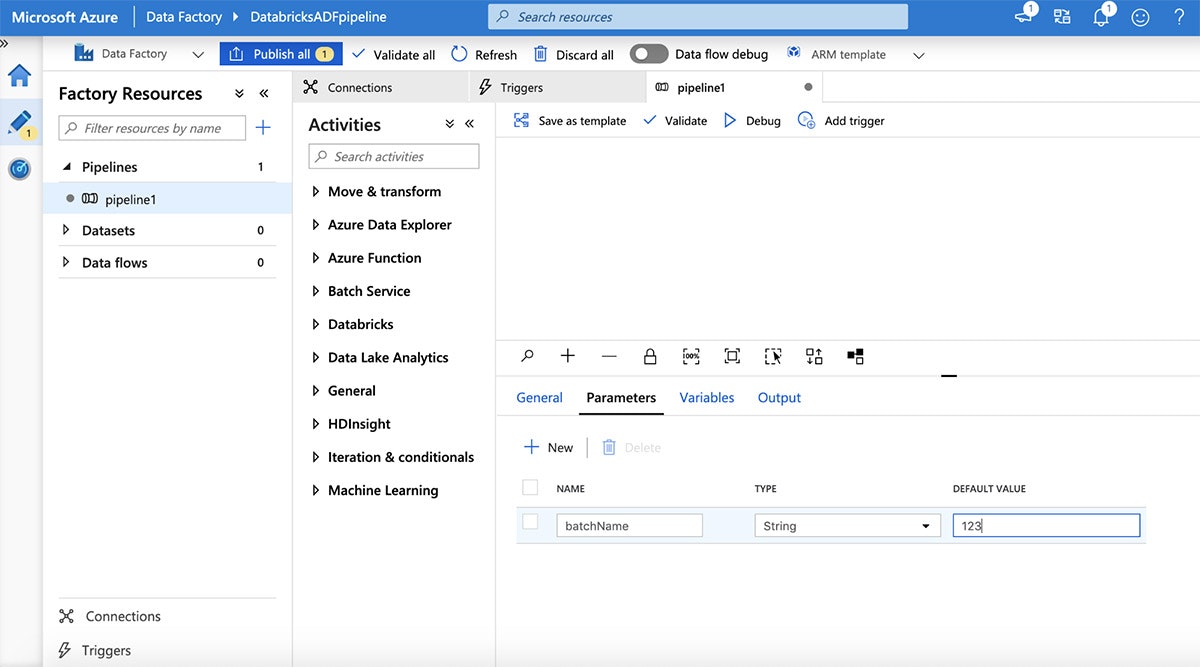
"Parameters"タブをクリックすることでパラメーターを追加し、プラス(+)ボタンをクリックします。
次に、"Databricks"アクティビティを展開してパイプラインにDatabricksノートブックを追加し、パイプラインのデザインキャンバス上にDatabricksノートブックをドラッグ&ドロップします。
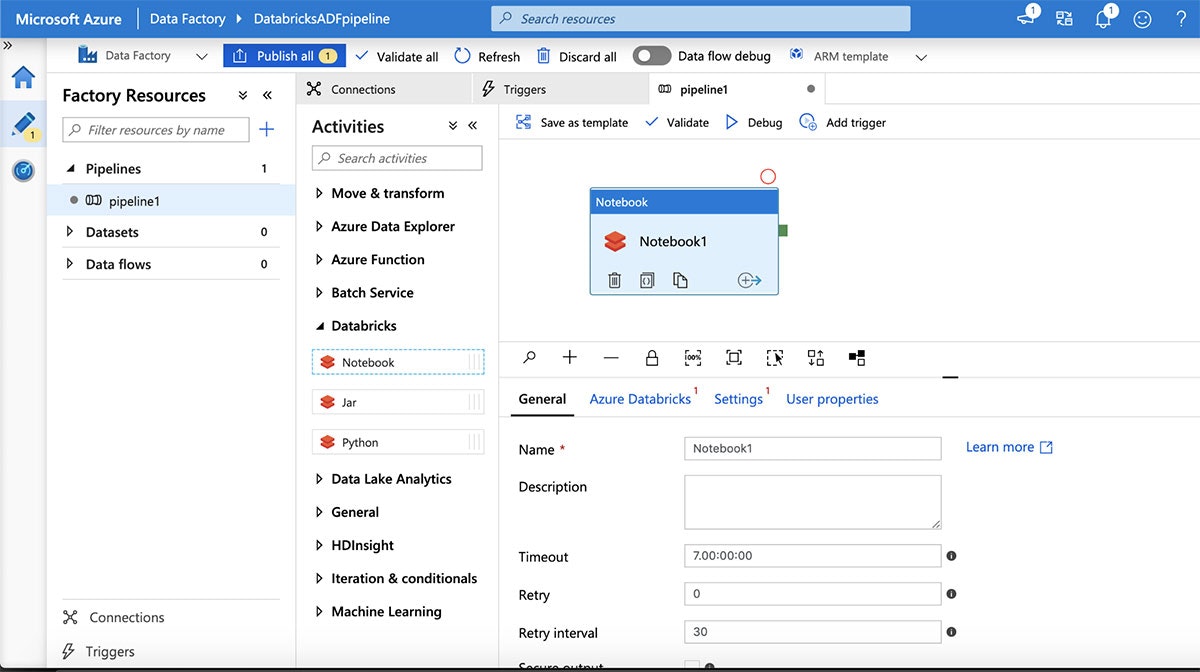
"Azure Databricks"タブを選択することで、Azure Databricksワークスペースに接続し、上で作成したリンクサービスを選択します。次に、ノートブックパスを指定するために"Settings"をクリックします。次に"Validate"ボタンをクリックし、ADFサービスに公開するために"Publish All"をクリックします。
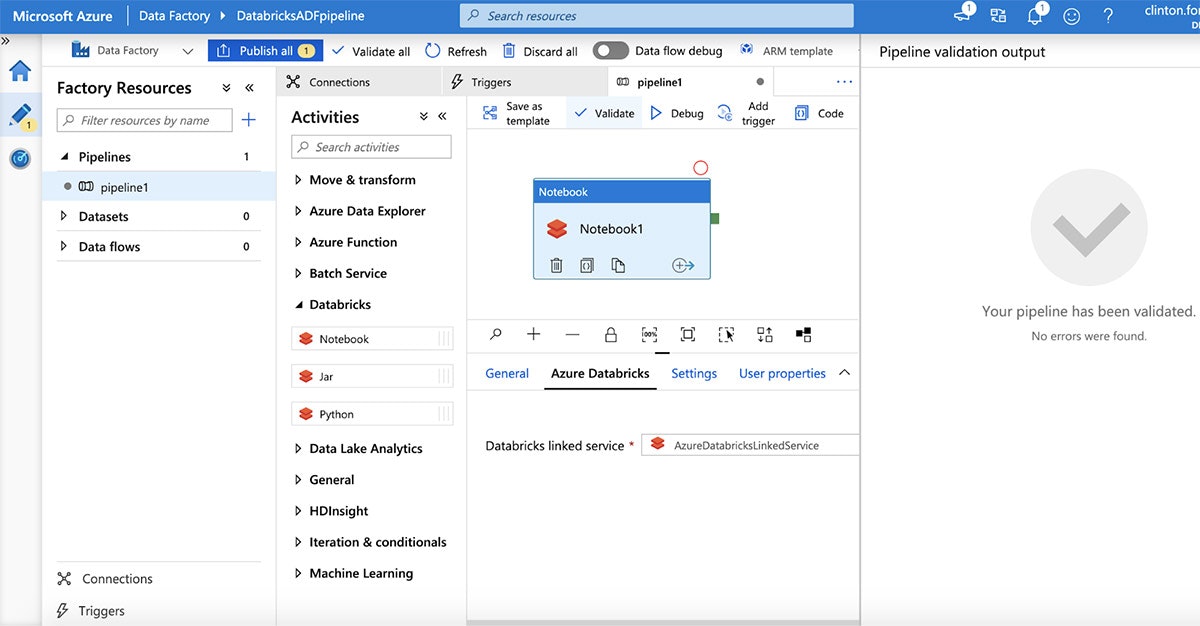
公開されたら、"Add Trigger | Trigger now"をクリックすることでパイプラインの実行を起動します。
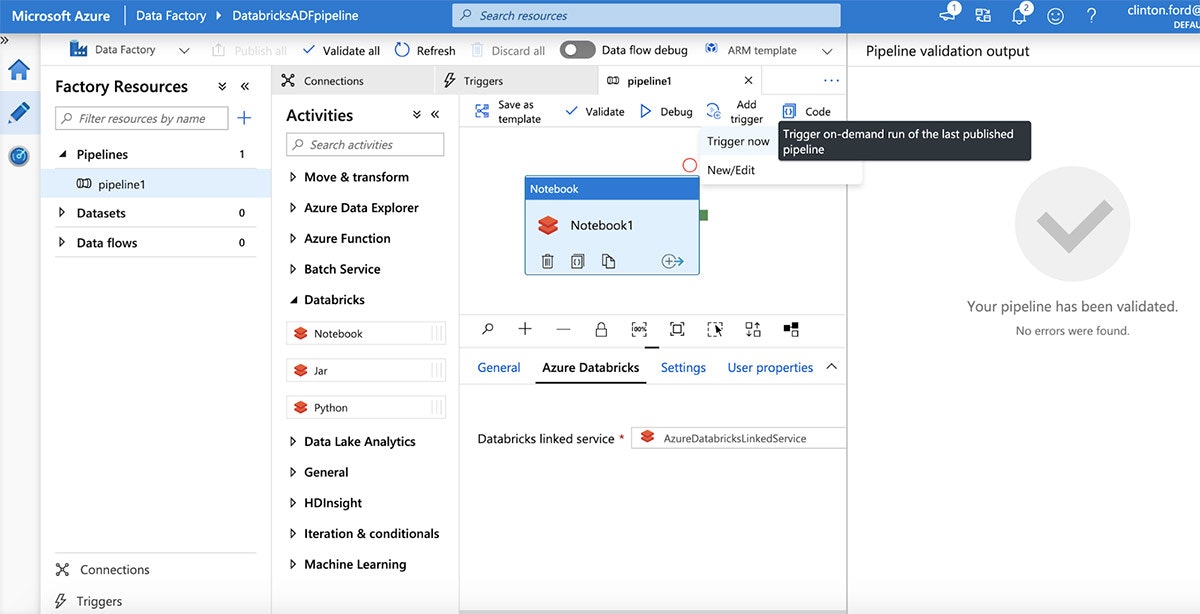
パラメーターを確認し、パイプラインを起動するために"Finish"をクリックします。
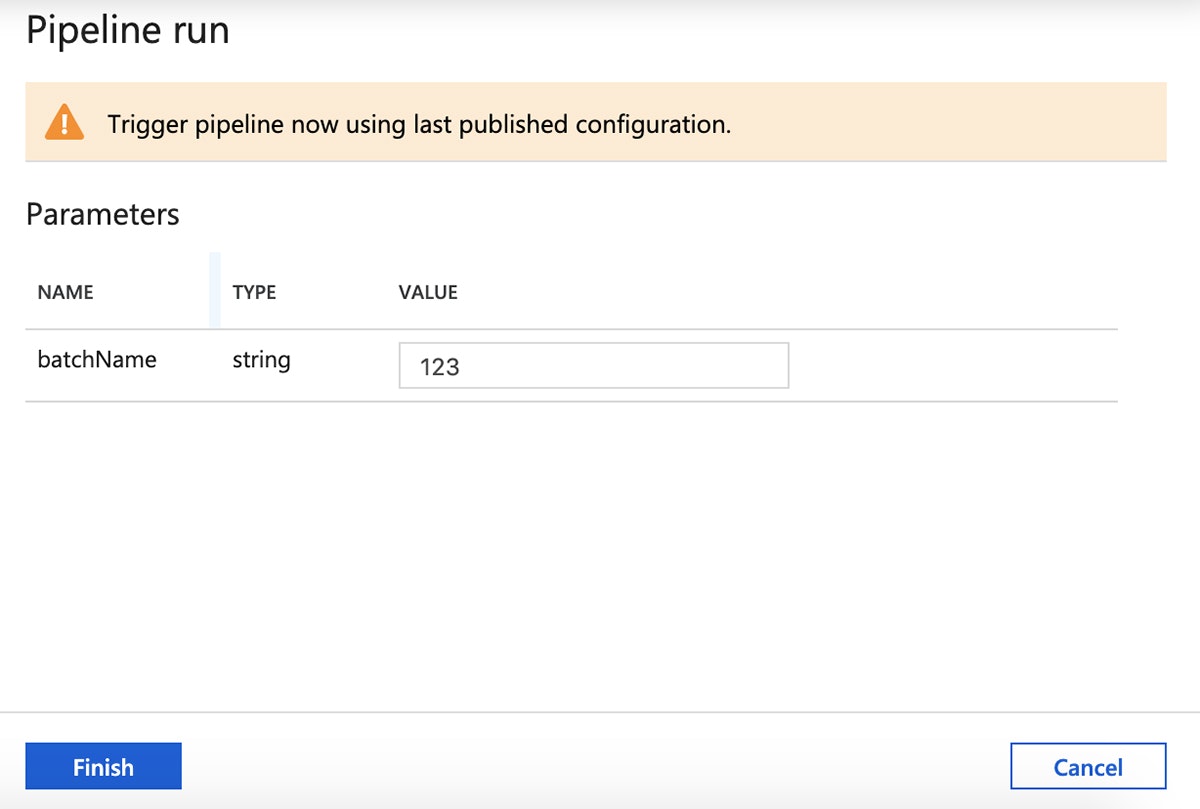
次にパイプライン実行の進捗を確認するために、右側のパネルの"Monitor"タブに切り替えます。
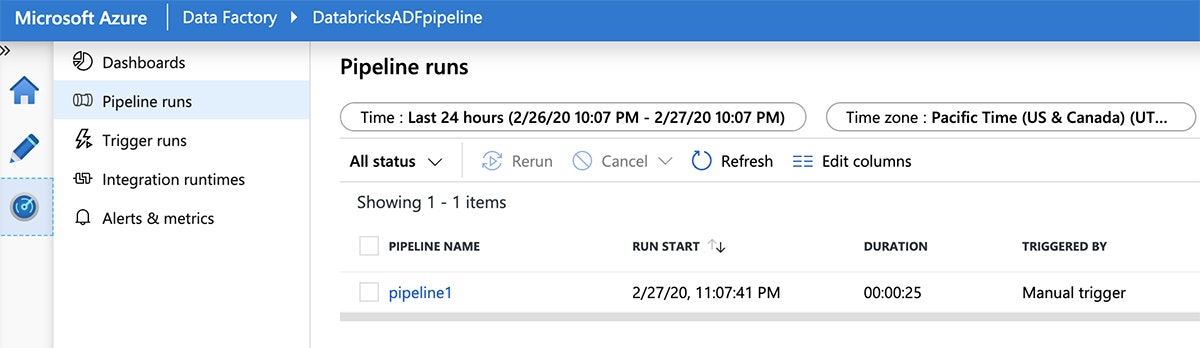
Azure DatabricksノートブックをAzure Data Factoryパイプラインにインテグレーションすることで、お使いのカスタムETLコードをパラメータ化し、本格運用するための柔軟かつスケーラブルな方法を提供します。Azure DatabricksがどのようにAzure Data Factory (ADF)とインテグレーションしているのかを学びたいのであれば、ADFのブログ記事やADFチュートリアルをご覧ください。データレイクのデータをどのように探索し、クエリーを実行するのかに関しては、こちらのウェビナー、Using SQL to Query Your Data Lake with Delta Lakeをご覧ください。