Reproducible Machine Learning with Data Lakehouse - Databricks Blogの翻訳です。
サンプルノートブックはこちらからダウンロードできます。
機械学習は、イノベーションの加速、パーソナライゼーション、需要予測など数えきれないユースケースで、企業やプロジェクトに前例のない価値を付加することを証明しました。しかし、機械学習(ML)は、変化し続けるツールや依存関係を伴う数多くのデータソースを活用し、このことはソリューションが流動的かつ再現が難しいものにしています。
誰もモデルが100%正しいことを保証できませんが、再現可能なモデルと結果を生み出したエクスペリメントの方が、そうでないものよりも信頼できるものと言えます。再現可能なMLエクスペリメントは少なくとも以下を再現できることを意味します:
- トレーニング/検証/テストデータ
- 計算
- 環境
- モデル(および関連付けられたハイパーパラメータなど)
- コード
しかし、MLの再現性確保は思ったよりも難しいタスクです。モデルのトレーニングに用いたデータにアクセスする必要がありますが、トレーニングが実行された時点からデータが変更されていないことをどのように保証できますか?データだけではなくソースコードのバージョン管理を行いましたか?さらには、どのライブラリ(バージョンも)、どのハイパーパラメータ、どのモデルを使用しましたか?最後に、コードはエンドツーエンドで処理を完了しましたか?
この記事では、Delta Lakeの上に構築されたレイクハウスアーキテクチャが、オープンソースライブラリであるMLflowと連携して、どのようにこれらの再現性確保における課題を解決するのかを説明します。特に、この記事では以下をカバーします:
- レイクハウスアーキテクチャ
- Delta Lakeによるデータのバージョン管理
- MLflowによるエクスペリメントのトラッキング
- Databrikcsにおけるエンドツーエンドの再現性確保
データレイクハウスとは何か、なぜ注意を払うべきか
データサイエンティストとしては、使用しているデータがどこから来ているのか(CSV、RDBMSなど)を気にしないかもしれません。しかし、例えば夜間に更新されるトレーニングデータを使用しているケースを考えてみます。あなたは、あるハイパーパラメータを用いてモデルを今日構築します。しかし、明日いくつかのハイパーパラメータを調整してモデルを改善しようとします。この際、モデルの性能が改善したのは、ハイパーパラメータを更新したからなのでしょうか?それとも使用しているデータが変更されたからなのでしょうか?データのバージョン管理を行いアップルツーアップルで比較しないことには、これを知る術はありません!「よし、それではすべてのデータのスナップショットを取ろう」と言うかもしれませんが、これはデータの鮮度がすぐに失われ、かつ、バージョン管理が大変で、非常にコストがかかるものです。全てのデータセットのスナップショットを取ることなしに、データのバージョン管理を行い、大規模データであっても最新の状態を維持できる、唯一の信頼できる情報源が必要です。
ここでレイクハウスの出番です。レイクハウスは、データウェアハウスとデータレイクの長所を兼ね備えたものです。これによって、データレイクのスケーラビリティ、低コスト、データウェアハウスのスピード、ACIDトランザクション保証を手に入れることができます。さらに、データに対する唯一の信頼できる情報源を手に入れることで、古いデータ、一貫性のないデータを目にすることがなくなります。このことは、既存のデータレイクを、性能を最適化するためのメタデータ管理機構で拡張することで、データウェアハウスにデータをコピーすることなしに実現します。オープンスタンダードを維持したまま、データのバージョン管理、信頼性、対障害性のあるトランザクション、高速なクエリーエンジンを手にすることができます。ストリーミング、分析、BI、データサイエンス、AIなど主要なワークロードに対応できる単一のソリューションを手に入れることができます。これは新たなスタンダードとなります。
これは理論的には素晴らしく聞こえます。ではどうやって始めたらいいのでしょうか?
Delta Lakeによるデータのバージョン管理
Delta Lakeはレイクハウスアーキテクチャを支援するオープンソースプロジェクトです。いくつかのレイクハウスのオープンソースプロジェクトが存在しますが、我々はApache Spark™と密接にインテグレートされ、以下の機能を提供するDelta Lakeを活用しています。
- ACIDトランザクション
- 大規模メタデータ管理
- タイムトラベル
- スキーマエボリューション
- 監査ログ
- DELETE、UPDATE
- バッチ、ストリーミングの統合
良いMLは高品質のデータからスタートします。Delta Lakeと上述の機能のいくつかを活用することで、あなたのデータサイエンスプロジェクトが堅牢な基盤からスタートできることを保証できます。データに対して定常的に更新が行われる際には、バッチであろうがストリーミングであろうが、同時の書き込み、読み込みにおいても、ACIDトランザクションによってデータの一貫性は保持されます。このようにして、すべての人がデータに対して一貫性のあるビューを手に入れることができます。
Delta Lakeは以前のコミットからの"delta"、変更のみをトラッキングし、Deltaトランザクションログに格納します。これによって、データバージョンに対するタイムトラベルが可能になり、モデル、ハイパーパラメータなどに変更を加える間でもデータを一定に保つことができます。しかし、Deltaのスキーマエボリューションがあるので、Deltaによってスキーマがロックインされることはありませんので、機械学習モデルに新たな特徴量を追加することができます。
Delta APIのhistory()メソッドを用いてトランザクションログ上の変更を参照することができます。
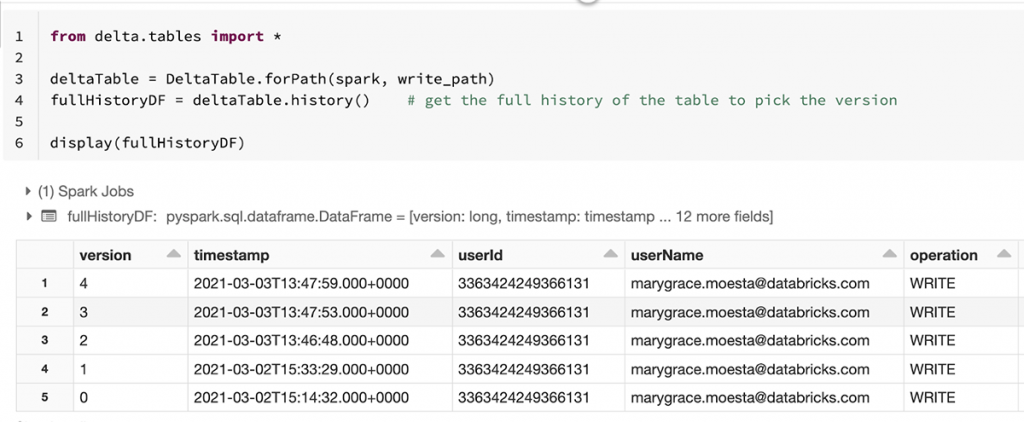
これによって、使用しているデータに対する全ての変更のリネージュを容易に追跡することができるので、モデルを構築する際に使用したデータと全く同じものを用いて、モデルを再現することができます。Delta Lakeからデータをロードする際に、特定のバージョンあるいはタイムスタンプを指定することができます。
version = 1
wine_df_delta = spark.read.format('delta').option('versionAsOf', version).load(data_path)
# Version by Timestamp
timestamp = '2021-03-02T15:33:29.000+0000'
wine_df_delta = spark.read.format('delta').option('timeStampAsOf', timestamp).load(data_path)
MLflowによるモデルのトラッキング
信頼性を持ってデータを再現できるようになったら、次のステップではモデルを再現することになります。オープンソースライブラリMLflowにはMLライフサイクルを管理するための4つのコンポーネントがあり、エクスペリメントの再現性をシンプルにすることができます。

MLflowトラッキングによって、ハイパーパラメータ、メトリクス、コード、モデル、あらゆる追加のアーティファクト(ファイル、グラフ、データバージョンなど)を一つの場所に記録することができます。これには、それぞれのラン(トレーニング)におけるデータの整合性を保つために、Deltaテーブルと対応するバージョンの記録も含まれます。データ全体のスナップショットを取ったり、コピーすることを回避します。ワインのデータセットに対するランダムフォレストモデルを構築する例を取り、MLflowでエクスペリメントを記録します。すべてのコードはこちらのノートブックから参照できます。
with mlflow.start_run() as run:
# Log params
n_estimators = 1000
max_features = 'sqrt'
params = {'data_version': data_version,
'n_estimators': n_estimators,
'max_features': max_features}
mlflow.log_params(params)
# Train and log the model
rf = RandomForestRegressor(n_estimators=n_estimators,
max_features=max_features,
random_state=seed)
rf.fit(X_train, y_train)
mlflow.sklearn.log_model(rf, 'model')
# Log metrics
metrics = {'rmse': rmse,
'mae': mae,
'r2' : r2}
mlflow.log_metrics(metrics)
結果はMLflowトラッキングUIに記録され、(別のエクスペリメントのロケーションを指定していない限り)Databricksノートブックの右上にあるExperimentアイコンを選択することでアクセスすることができます。ここでは、複数のランを比較したり、特定のメトリクス、パラメーターなどでフィルタリングすることができます。

手動でのパラメーター、メトリクスなどのロギングに加えて、いくつかのMLflowがサポートしているビルトインモデルフレーバーにおけるオートロギング機能を利用できます。例えば、sklearnのモデルを自動的に記録するのであれば、シンプルにmlflow.sklearn.autolog()を追加するだけです。これによって、estimator.fit()が呼び出された際に、パラメーター、メトリクス、分類問題における混合行列などを記録します。
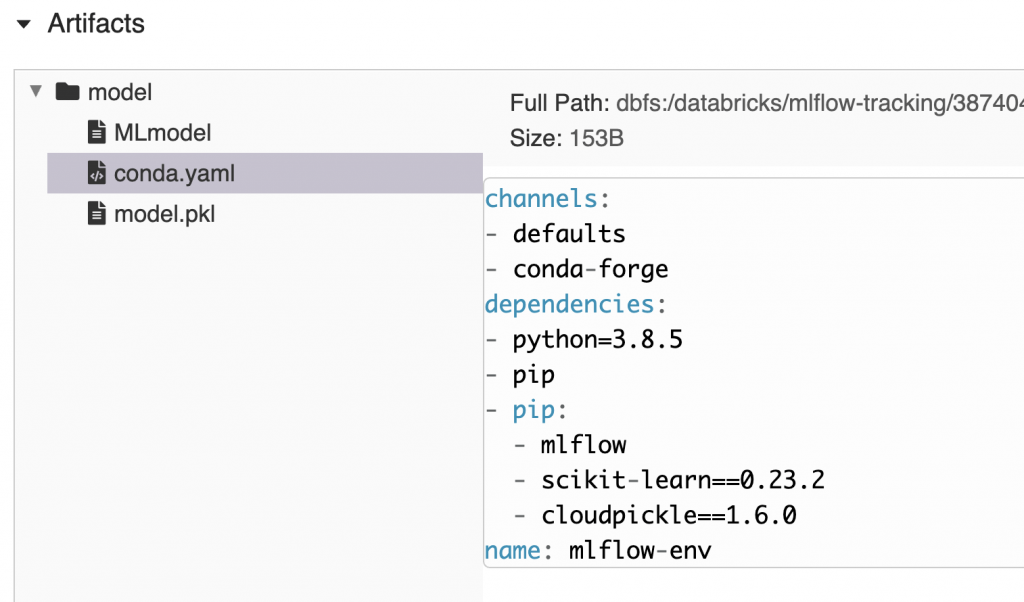
トラッキングサーバーにモデルを記録する際に、MLflowは標準的なモデルパッケージングフォーマットを作成します。モデルをロードするために必要な環境を再作成するのに必要なチャネル、依存関係、バージョンを記述したconda.yamlファイルを自動で作成します。これによって、MLflowに記録されたあらゆるモデルを実行するための環境を簡単に再現できるようになります。
DatabricksプラットフォームのマネージドMLflowを使う際には、ボタンのクリックでトレーニングを再現できる**‘reproduce run’**機能を利用できます。これはDatabricksノートブック、クラスター設定、インストールした追加のライブラリのスナップショットを自動で作成します。
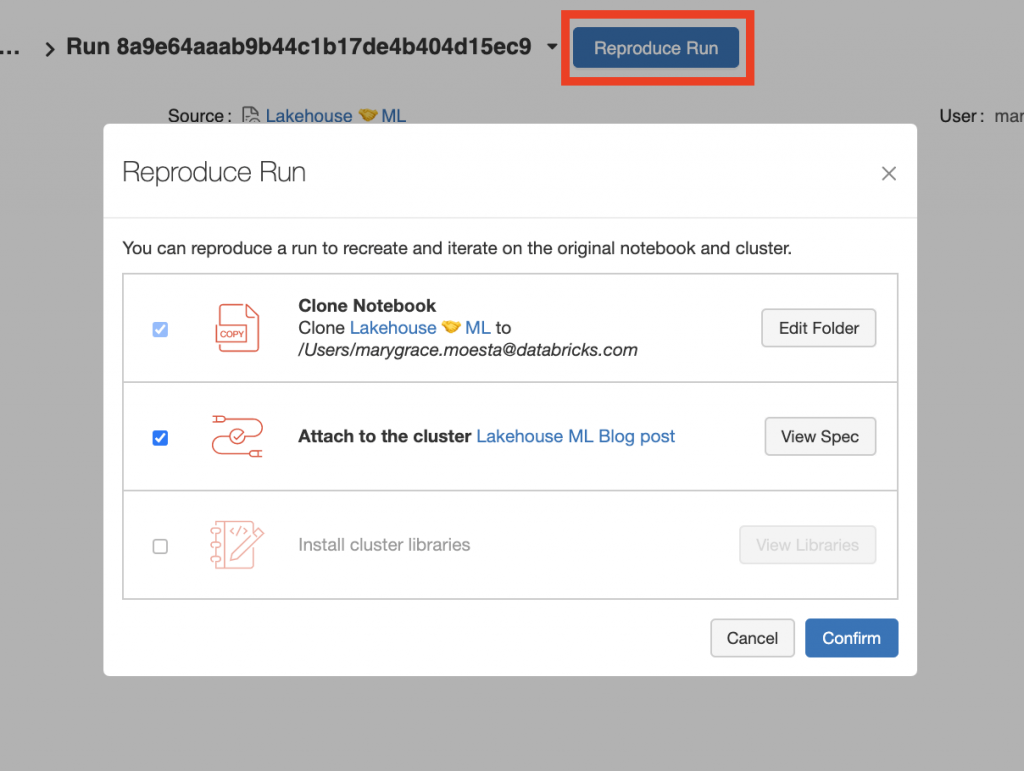
是非この"reproduce run"機能をチェックしていただき、ご自身、あるいは同僚の方が実施されたエクスペリメントを再現してみてください!
全てを統合する
ここまでで、レイクハウスアーキテクチャがDelta Lake、MLflowと共に、どのようにMLにおけるデータ、モデル、コード、環境の再現性の課題に取り組んでいるのかを学びました。ノートブックに目を通していただき、エクスペリメントを再現してみてください!上述した項目を再現できる機能であっても、あなたがコントロールできないことがいくつか存在します。しかしながら、DatabricksにおけるDelta Lake、MLflowによるMLソリューションは、MLエクスペリメントを再現する際に人々が直面する課題の大部分に取り組んでいるものです。
データレイクハウスが解決する他の問題に興味がありますか?最近のブログ記事従来型の2層アーキテクチャにおける課題をご一読いただき、どのようにレイクハウスアーキテクチャが課題解決を支援しているのを知っていただければと思います。