苦戦してましたが、同僚のエンジニアの方に教えてもらいました。
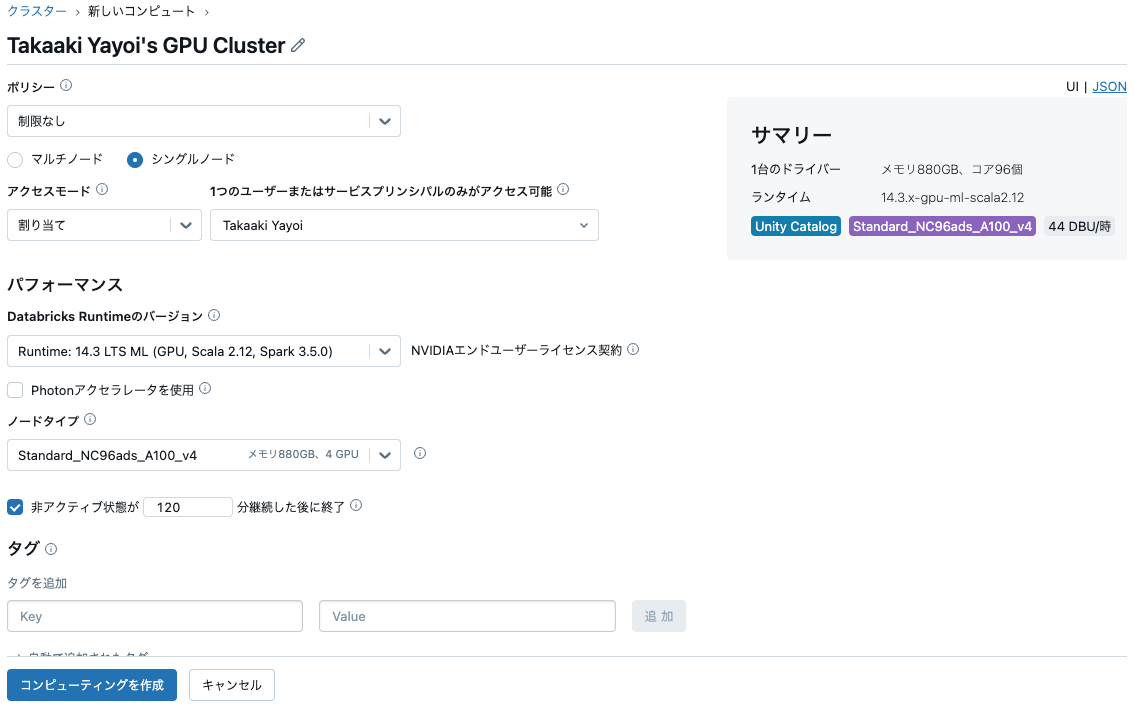
クラスターの設定
- Azure Databricks
- ランタイム: 14.3 LTS ML (GPU)
- ノードタイプ: シングルノード、Standard_NC96ads_A100_v4
Hugging Faceにアクセス
モデルへのアクセスが許可されていることを確認してください。

自分のアクセストークンをコピーしておきます。

ノートブックの実行
ライブラリのインポート
%pip install -U transformers tiktoken torch accelerate hf_transfer
dbutils.library.restartPython()
Hugging Face Hubへのログイン
from huggingface_hub import login
login()
ここでアクセストークンを入力します。
モデルのダウンロードおよび推論
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained(
"databricks/dbrx-instruct",
trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"databricks/dbrx-instruct",
device_map="auto",
torch_dtype=torch.bfloat16,
cache_dir="/local_disk0/hf",
trust_remote_code=True)
input_text = "What does it take to build a great LLM?"
messages = [{"role": "user", "content": input_text}]
input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=200, pad_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0]))
<|im_start|> system
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY. <|im_end|>
<|im_start|> user
What does it take to build a great LLM? <|im_end|>
<|im_start|> assistant
To build a great language learning model (LLM), several key components are necessary:
1. **High-Quality Data**: A large and diverse dataset is crucial for training a robust LLM. The data should cover various topics, styles, and domains to ensure the model can handle a wide range of inputs.
2. **Advanced Algorithms**: State-of-the-art machine learning algorithms, such as deep neural networks and transformer architectures, are essential for building a high-performing LLM.
3. **Computational Resources**: Training LLMs requires significant computational power, including GPUs or TPUs, to process large datasets and complex algorithms.
4. **Expertise in NLP**: Building a great LLM requires a deep understanding of natural language processing (NLP) techniques, including tokenization, part-of-speech tagging, named entity recognition, and sentiment analysis.
5. **Evaluation and Optimization**: Regular evaluation and optimization of the model are necessary to ensure its performance and improve its capabilities. This involves using
日本語でも試してみます。
input_text = "Databricksの特徴を日本語で教えてください"
messages = [{"role": "user", "content": input_text}]
input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=200, pad_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0]))
<|im_start|> system
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY. <|im_end|>
<|im_start|> user
Databricksの特徴を日本語で教えてください <|im_end|>
<|im_start|> assistant
Databricksは、Apache Sparkをベースとした統合データ分析プラットフォームです。Databricksは、データサイエンス、エンジニアリング、ビジネス分析のためのコラボレーティブなワークスペースを提供しています。Databricksは、データの処理、分析、機械学習、データの可視化など、データ駆動型のタスクを実行するための機能を備えています。Databricksは、クラウドベースのサービスとして提供されており、ユーザーはブラウザを通じてアクセス
とりあえず動きました。