こちらの記事を書いている途中で、Tavilyの存在を知りました。
エージェントを勉強している中で、個人的には「どういったエージェントが作れるのだろうか」ということを、ここ数日悶々としてました。いまでも悶々としてますが。以下は悶々のメモ書きです。
- RAGがエージェントの一種(あるいは先駆け)と言われるようになったのは、生成AIモデルが持たない知識でユーザーを支援できるようになったから(だと私は思ってます)
- RAGの場合、そのような生成AIモデルの持たない知識はベクトルDBに入っているドキュメント群。
- Genieの場合、スペースに追加された構造化テーブル。
- それ以外には、ネットの最新情報も含まれるだろう。
- エージェントというからには、ユーザー個人に対するエージェントになって欲しい。
- そのためには、ユーザーの文脈(コンテキスト) を示す情報が必要。
- ユーザーの注文履歴、行動履歴といった情報が文脈になるだろう。
- エージェントはメモリーを持つようになっているから、これも文脈になる。
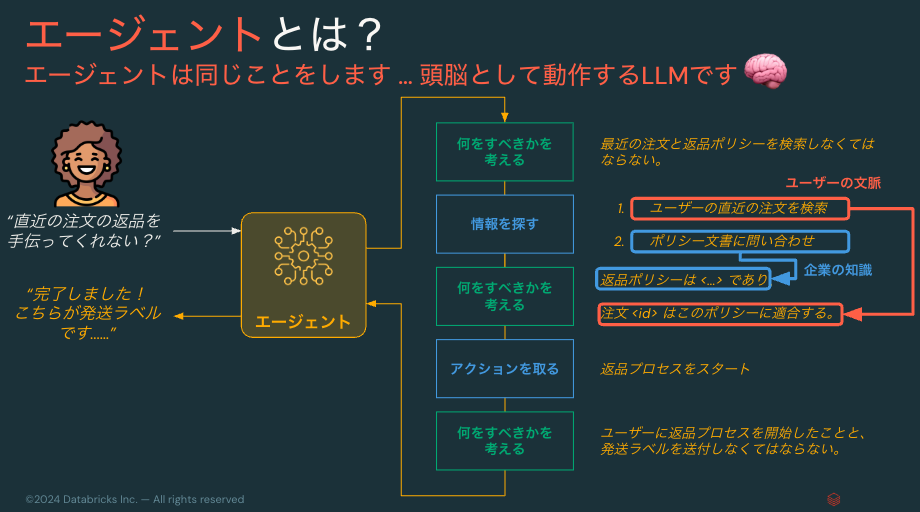
エージェント設計におけるユーザーの文脈と企業の知識
と、つらつらと書いてみると、エージェントのデザインでは以下の2つの情報をどのように取得して、それらをつなぎ合わせてアクションに繋げるのかが大切な気がしてきました。
- 問い合わせを行うユーザーの文脈をどのように表出化させるのか(データがあればラッキーですが、常にそうではないでしょう)。これをユーザーの文脈と呼ぶことにします。
- 文脈と突合させることでアクションにつながる情報。これはまだ言語化がうまくできていませんが、RAGの文脈になぞらえて企業の知識と呼ぶことにします。
図にすると以下のようなイメージです。
前振りが長くなりましたが、タイトルの話です。個人的には、エージェントというからには自然言語をメインに取り扱うエージェントというものがどういうものになるのかが気になっています。RAGも自然言語を取り扱っていることに間違いはないのですが、ベクトルDBにあるものを検索するという手法が確立されています。ここでは、それ以外の方法で言語系のエージェントが組めないかなと思った訳です。
となると、最初に思いつくのがAPIですが、いろいろ探してみましたがこれぞというものが見つかっていなかったのです。WikipediaのAPIはありましたが、これからどうエージェントに繋げるのかで詰まってしまってました。もっと考えればいいのが出てくるかもしれませんが。
そこで、冒頭のTavilyです。検索エンジンAPIも探していた中、今回の文脈ではぴったりだと思いました。
問い合わせに基づきインターネット検索を行うエージェントのプロトタイピング
ということで、Databricksで簡単にプロトタイピングしてみます。
TavilyのREST APIを使います。
まずは、ノートブックで動作確認します。
import requests
query = "Databricksとは"
# tavilyのエンドポイント
URL = "https://api.tavily.com/search"
# ヘッダー
headers = {"Content-Type": "application/json"}
# 検索パラメータ
search_params = {
"api_key": "<TavilyのAPIキー>",
"query": query
}
# tavilyから検索結果の取得
search_response = requests.post(url=URL, headers=headers, json=search_params)
search_data = search_response.json()
search_data["results"]
動きました。
{'query': 'Databricksとは',
'follow_up_questions': None,
'answer': None,
'images': [],
'results': [{'title': 'Databricksとは|Databricks on AWS',
'url': 'https://docs.databricks.com/ja/introduction/index.html',
'content': 'Databricksは、エンタープライズレベルのデータ分析とAIソリューションを提供する統合されたオープンな分析プラットフォームです。 Databricksは、クラウドストレージとセキュリティと統合し、生成AI、データレイクハウス、ETL、機械学習、データウェアハウジングなどの用途に対応したツールとプログラムによるアクセスを可能にします。',
'score': 0.93624437,
'raw_content': None},
{'title': 'Databricksとは?特長やSnowflakeとの違いも解説|MarTechLab(マーテックラボ)',
'url': 'https://martechlab.gaprise.jp/archives/lpolab/databricks/',
'content': 'Databricksはレイクハウスプラットフォームと呼ばれるデータ分析とAIが統合したクラウド型プラットフォームです。データの統一、高速処理、セキュリティ対策などの特長や、競合サービスとの比較、導入事例などを紹介します。',
'score': 0.9242583,
'raw_content': None},
{'title': 'Azure Databricks とは - Azure Databricks | Microsoft Learn',
'url': 'https://learn.microsoft.com/ja-jp/azure/databricks/introduction/',
'content': 'Azure Databricks は、クラウドでデータ インテリジェンス ソリューションを構築、デプロイ、共有、保守するための統合されたツール セットです。 Databricks は、オープンソース コミュニティとの連携、独自のツールとプログラムのアクセス、Azure との連携などの機能を提供します。',
'score': 0.9152729,
'raw_content': None},
{'title': 'Databricks データインテリジェンスプラットフォーム|Databricks',
'url': 'https://www.databricks.com/jp/product/data-intelligence-platform',
'content': 'Databricks は、レイクハウスを基盤とするオープンな統合環境で、データと AI のジャーニーをシンプルにします。自然言語アシスタント機能やプライバシーとセキュリティのサポートなど、ビジネスのニーズに即したデータインテリジェンスエンジンを提供します。',
'score': 0.9125066,
'raw_content': None},
{'title': 'Azure Databricksとは?その特徴や使い方、料金体系をわかりやすく解説 | AI総合研究所',
'url': 'https://www.ai-souken.com/article/azure-databricks-overview',
'content': 'Azure Databricksは、Azureのクラウド上で動くApache Sparkベースのデータ分析プラットフォームです。高速な分散処理、複数言語対応、共同開発機能などが特徴で、データ処理、機械学習、リアルタイム分析などに対応します。この記事では、基本からメリット、使い方、活用事例、料金体系まで詳しく解説します。',
'score': 0.903098,
'raw_content': None}],
'response_time': 2.76}
これをベースにエージェントツールを作成します。
CREATE OR REPLACE FUNCTION takaakiyayoi_catalog.agent_demo.searchWeb(query STRING)
RETURNS STRING
LANGUAGE PYTHON
AS $$
import requests
# tavilyのエンドポイント
#session = requests.Session()
URL = "https://api.tavily.com/search"
# ヘッダー
headers = {"Content-Type": "application/json"}
# 検索パラメータ
search_params = {
"api_key": "<TavilyのAPIキー>",
"query": query
}
# tavilyから検索結果の取得
search_response = requests.post(url=URL, headers=headers, json=search_params)
search_data = search_response.json()
return search_data["results"]
$$
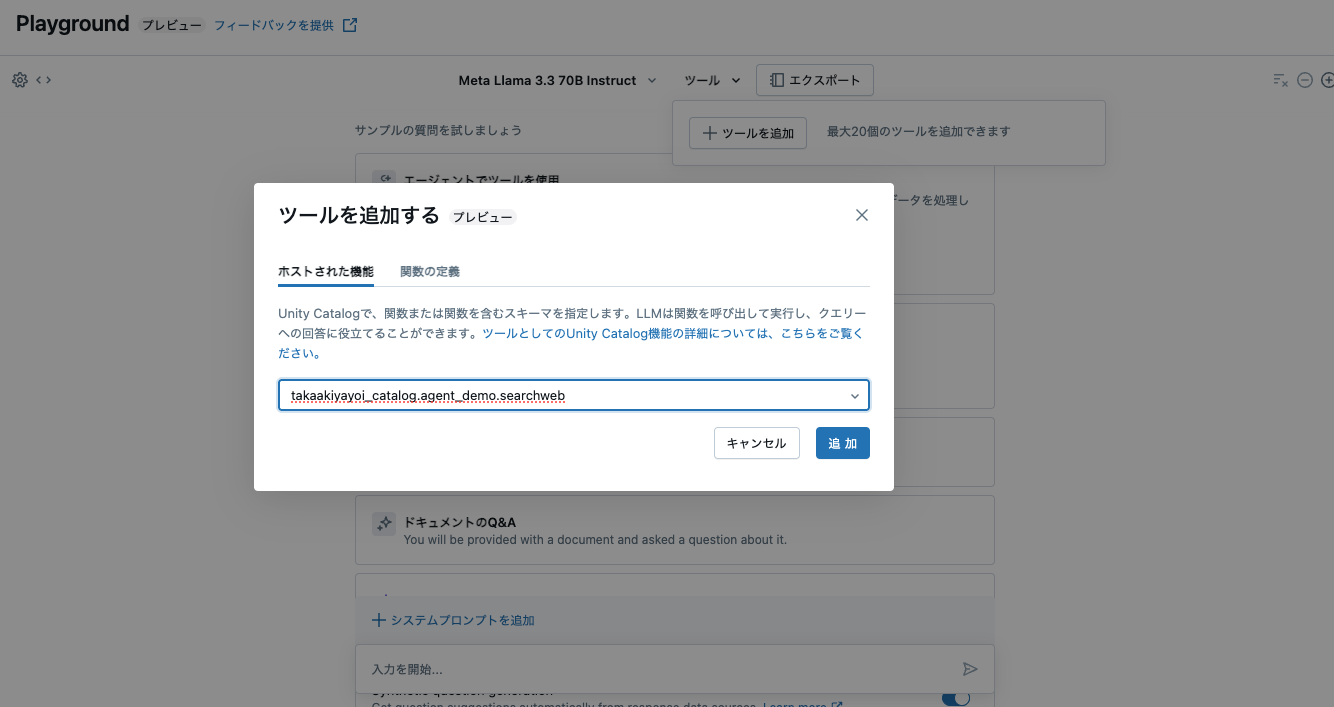
次に、AI Playgroundで動かしてみます。ツールとして上の関数を選択します。
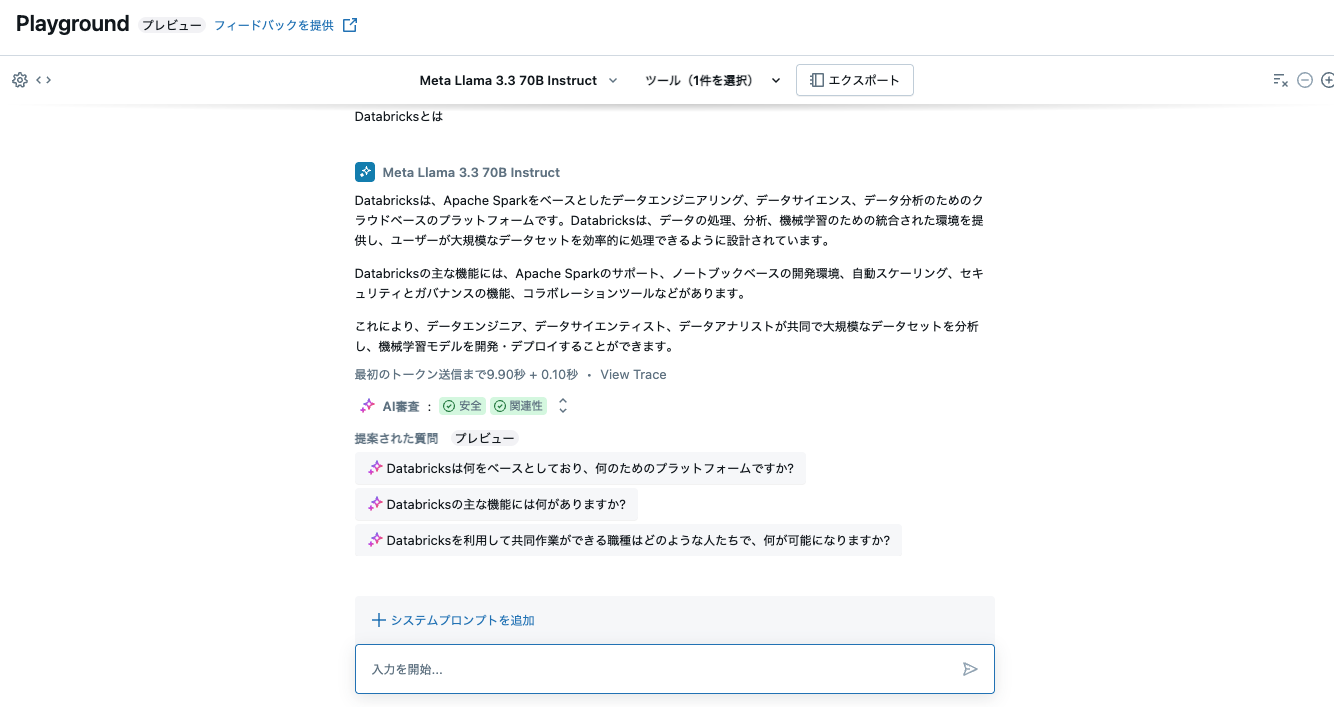
Databricksとはと一般的な問い合わせをしてみます。この場合はツールが呼び出されませんでした。
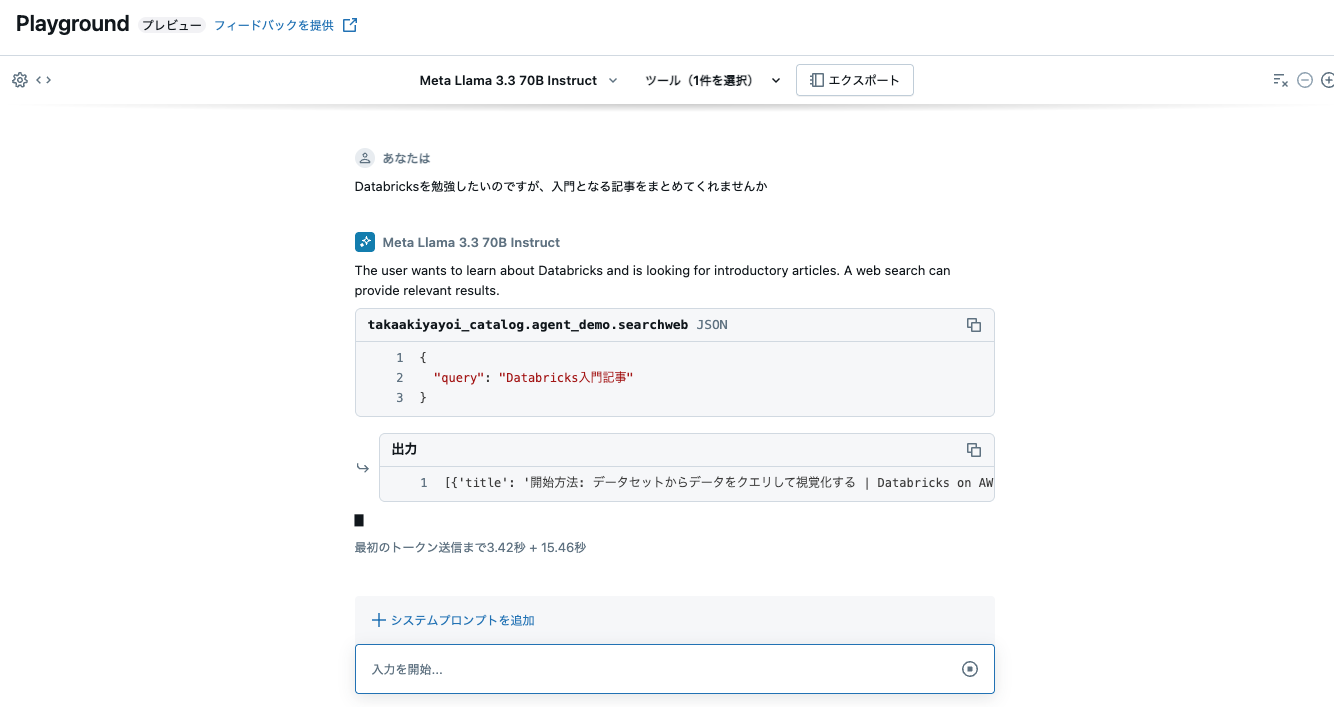
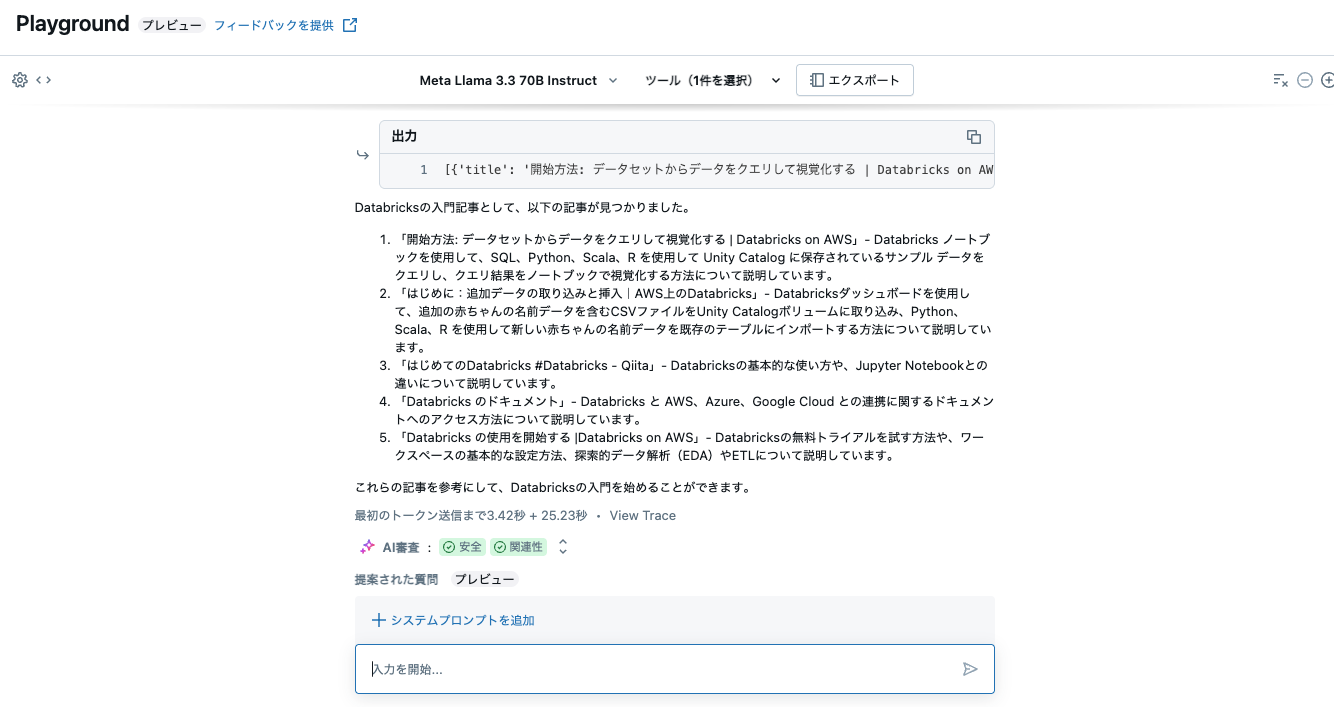
次に、Databricksを勉強したいのですが、入門となる記事をまとめてくれませんかと問い合わせてみます。
今度はツールが呼び出され、ネット検索の結果をベースに回答が生成されました。
これだけでも楽しいのですが、ツールのレスポンスにはURLが含まれているので、これを活用して欲しいところです。そこで、システムプロンプトを追加します。
あなたはインターネット書士です。質問に対してインターネットを検索して情報を取得します。得られた情報にURLが含まれる場合には、適切にリンクを生成して情報を提供します。
再度、はじめてDatabricksを触るのですが何から勉強すればいいですかと問い合わせてみます。すると、今度は適切にリンクが生成されるようになりました。面白い。
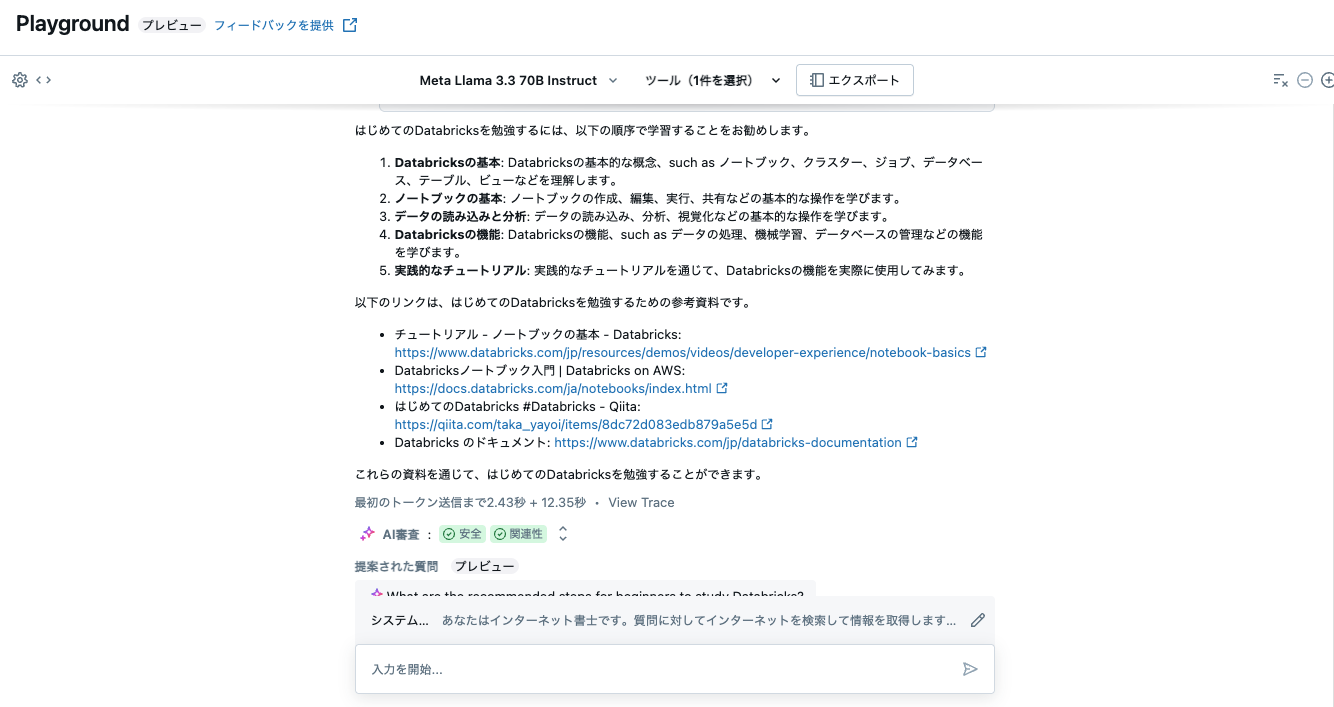
(あと、いつの間にかにPlaygroundで追加質問が提案されるようになってます)
まとめ
- ネット検索APIと組み合わせるとエージェントの幅が広がる。
- やりたいことに必要なAPIを特定することが大事。無い場合には自作することも必要。
- システムプロンプトやツールチェーンを工夫すれば、もっと色々なことができそう。
- 今回はユーザーの文脈を検索キーワードでしか表現できていないので、今後もっと高度なことにトライしてみよう。メールやカレンダーとか。メモリーも追加したい。
- いい感じのものができたら、Agent FrameworkとDatabricks Apps使って自分エージェントを作ろう。