こちらの続きです。
こちらのマニュアルに沿ってサンプルノートブックを動かします。
注意
執筆時点ではベータ版です。
MLflow 3.0
こちらにもまとめていますが、エクスペリメントページにおけるモデルタブの追加、Logged Modelエンティティの追加、モデルレジストリUIの改善などが含まれています。特に大きな変更点は、情報アーキテクチャが見直されたことだと思います。これまでは、MLflowラン(トレーニングの実行単位)にモデルやアーティファクト、メトリクス、パラメータなどが紐づけられていました。生成AIのように一つのモデルに繰り返し評価が行われる場合や、ディープラーニングのように複数のモデルチェックポイントができる場合には、この情報アーキテクチャでは困難さが生じていたため、今回の変更でモデルに複数のメトリクス、アーティファクトが紐づけられるようになっています。
有効化
ワークスペースのプレビューメニューにアクセスし、MLflow 3を有効化します。

MLflow 3.0とMosaic AIエージェントフレームワーク: ツール呼び出しLangGraphエージェントの作成とデプロイ
こちらのMLflow 3.0 生成AIエージェントの構築、評価 ノートブックを動かします。
このノートブックでは、Mosaic AIエージェントフレームワーク機能と互換性のあるLangGraphエージェントの作成方法を示し、最新のMLflow 3.0機能をハイライトします。このノートブックで学ぶこと:
-
ChatAgentでラップされたツール呼び出しLangGraphエージェントの作成 - エージェントの出力を手動でテスト
- Mosaic AIエージェント評価を使用してエージェントを評価
- エージェントのログとデプロイ
Mosaic AIエージェントフレームワークを使用してエージェントを作成する方法の詳細については、Databricksのドキュメントを参照してください (AWS | Azure)。
%pip install databricks-langchain databricks-agents uv langgraph==0.3.4
%pip install mlflow>=3.0.0.rc0 --upgrade --pre
dbutils.library.restartPython()
コードでエージェントを定義
エージェントコードを以下の単一セルで定義します。これにより、%%writefileマジックコマンドを使用してエージェントコードをローカルPythonファイルに簡単に書き込み、その後のログ記録とデプロイが可能になります。
エージェントツール
このエージェントコードは、組み込みのUnity Catalog関数system.ai.python_execをエージェントに追加します。また、非構造化データ検索を実行するためのベクトル検索インデックスを追加するサンプルコードもコメントアウトされています。
エージェントに追加するツールの詳細については、Databricksのドキュメントを参照してください (AWS | Azure)。
ChatAgentインターフェースを使用してLangGraphエージェントをラップ
Databricks AI機能との互換性のために、LangGraphChatAgentクラスはChatAgentインターフェースを実装してLangGraphエージェントをラップします。この例では、利便性のために提供されたAPI ChatAgentState および ChatAgentToolNode を使用します。
Databricksは、オープンソース標準を使用してマルチターン会話エージェントの作成を簡素化するためにChatAgentの使用を推奨しています。MLflowのChatAgentドキュメントを参照してください。
%%writefile agent.py
from typing import Any, Generator, Optional, Sequence, Union
import mlflow
from databricks_langchain import (
ChatDatabricks,
UCFunctionToolkit,
VectorSearchRetrieverTool,
)
from langchain_core.language_models import LanguageModelLike
from langchain_core.runnables import RunnableConfig, RunnableLambda
from langchain_core.tools import BaseTool
from langgraph.graph import END, StateGraph
from langgraph.graph.graph import CompiledGraph
from langgraph.graph.state import CompiledStateGraph
from langgraph.prebuilt.tool_node import ToolNode
from mlflow.langchain.chat_agent_langgraph import ChatAgentState, ChatAgentToolNode
from mlflow.pyfunc import ChatAgent
from mlflow.types.agent import (
ChatAgentChunk,
ChatAgentMessage,
ChatAgentResponse,
ChatContext,
)
############################################
# LLMエンドポイントとシステムプロンプトを定義
############################################
# 任意: モデルサービングエンドポイントを置き換える
LLM_ENDPOINT_NAME = "databricks-meta-llama-3-3-70b-instruct"
llm = ChatDatabricks(endpoint=LLM_ENDPOINT_NAME, temperature=0.1, max_tokens=2000)
# 任意: システムプロンプトを更新
system_prompt = "あなたはDatabricksに関する質問に答えることができるチャットボットです。"
###############################################################################
## エージェントのツールを定義し、テキスト生成以外のデータ取得やアクションを可能にする
## さらに多くのツールの作成と使用例については、
## https://docs.databricks.com/en/generative-ai/agent-framework/agent-tool.html を参照
###############################################################################
tools = []
# Unity CatalogのUDFをエージェントツールとして使用可能
# 以下では、エージェントにPythonコードインタープリターツールを提供する
# `system.ai.python_exec` UDFを追加
# ローカルLangChain Pythonツールも追加可能。詳細は https://python.langchain.com/docs/concepts/tools を参照
# 任意: 追加ツールを追加
uc_tool_names = ["system.ai.python_exec"]
uc_toolkit = UCFunctionToolkit(function_names=uc_tool_names)
tools.extend(uc_toolkit.tools)
# Databricksベクトル検索インデックスをツールとして使用
# 詳細は https://docs.databricks.com/en/generative-ai/agent-framework/unstructured-retrieval-tools.html を参照
# 任意: ベクトル検索インデックスを追加
# vector_search_tools = [
# VectorSearchRetrieverTool(
# index_name="",
# # filters="..."
# )
# ]
# tools.extend(vector_search_tools)
#####################
## エージェントロジックを定義
#####################
def create_tool_calling_agent(
model: LanguageModelLike,
tools: Union[ToolNode, Sequence[BaseTool]],
system_prompt: Optional[str] = None,
) -> CompiledGraph:
model = model.bind_tools(tools)
# どのノードに進むかを決定する関数を定義
def should_continue(state: ChatAgentState):
messages = state["messages"]
last_message = messages[-1]
# 関数呼び出しがある場合は続行、そうでない場合は終了
if last_message.get("tool_calls"):
return "continue"
else:
return "end"
if system_prompt:
preprocessor = RunnableLambda(
lambda state: [{"role": "system", "content": system_prompt}]
+ state["messages"]
)
else:
preprocessor = RunnableLambda(lambda state: state["messages"])
model_runnable = preprocessor | model
def call_model(
state: ChatAgentState,
config: RunnableConfig,
):
response = model_runnable.invoke(state, config)
return {"messages": [response]}
workflow = StateGraph(ChatAgentState)
workflow.add_node("agent", RunnableLambda(call_model))
workflow.add_node("tools", ChatAgentToolNode(tools))
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
should_continue,
{
"continue": "tools",
"end": END,
},
)
workflow.add_edge("tools", "agent")
return workflow.compile()
class LangGraphChatAgent(ChatAgent):
def __init__(self, agent: CompiledStateGraph):
self.agent = agent
def predict(
self,
messages: list[ChatAgentMessage],
context: Optional[ChatContext] = None,
custom_inputs: Optional[dict[str, Any]] = None,
) -> ChatAgentResponse:
request = {"messages": self._convert_messages_to_dict(messages)}
messages = []
for event in self.agent.stream(request, stream_mode="updates"):
for node_data in event.values():
messages.extend(
ChatAgentMessage(**msg) for msg in node_data.get("messages", [])
)
return ChatAgentResponse(messages=messages)
# エージェントオブジェクトを作成し、推論のためにエージェントオブジェクトを使用することを指定
# mlflow.models.set_model()を介してエージェントをロード
mlflow.langchain.autolog()
agent = create_tool_calling_agent(llm, tools, system_prompt)
AGENT = LangGraphChatAgent(agent)
mlflow.models.set_model(AGENT)
エージェントのテスト
エージェントと対話して、その出力とツール呼び出し機能をテストします。このノートブックでは mlflow.langchain.autolog() を呼び出しているため、エージェントが実行する各ステップのトレースを表示できます。
このプレースホルダー入力を、エージェントに適したドメイン固有の例に置き換えてください。
dbutils.library.restartPython()
from agent import AGENT
AGENT.predict({"messages": [{"role": "user", "content": "こんにちは!"}]})
ChatAgentResponse(messages=[ChatAgentMessage(role='assistant', content='こんにちは!Databricksに関する質問やトピックについて話しましょう。どんなことについて知りたいですか?', name=None, id='run-d81e8432-0a8d-4d20-8324-b6f62a7fceba-0', tool_calls=None, tool_call_id=None, attachments=None)], finish_reason=None, custom_outputs=None, usage=None)
前のセルの出力例を以下に示します。これはエージェントの実行トレースです。
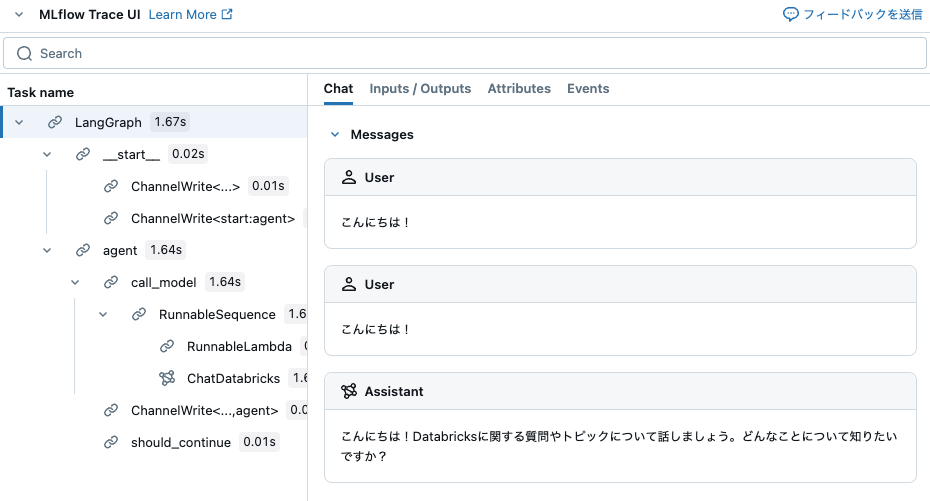
エージェントをMLflowモデルとして記録する
agent.pyファイルからコードとしてエージェントを記録します。詳細はMLflow - Models from Codeを参照してください。
Databricksリソースの自動認証を有効にする
最も一般的なDatabricksリソースタイプに対して、Databricksはエージェントのログ中にリソース依存関係を事前に宣言することをサポートおよび推奨しています。これにより、エージェントをデプロイする際に自動認証パススルーが有効になります。自動認証パススルーを使用すると、Databricksはこれらのリソース依存関係に安全にアクセスするための短命の資格情報を自動的にプロビジョニング、回転、および管理します。
自動認証を有効にするには、mlflow.pyfunc.log_model()を呼び出す際に依存するDatabricksリソースを指定します。
- 注: Unity Catalogツールがベクター検索インデックスをクエリする場合や外部関数を利用する場合、それぞれ依存するベクター検索インデックスおよびUC接続オブジェクトをリソースとして含める必要があります。詳細はドキュメントを参照してください (AWS | Azure)。
import mlflow
from agent import tools, LLM_ENDPOINT_NAME
from databricks_langchain import VectorSearchRetrieverTool
from mlflow.models.resources import DatabricksFunction, DatabricksServingEndpoint
from unitycatalog.ai.langchain.toolkit import UnityCatalogTool
# オプション: 必要に応じて基礎リソースを手動で含めることができます。詳細は上記のマークダウンの注記を参照してください。
resources = [DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT_NAME)]
for tool in tools:
if isinstance(tool, VectorSearchRetrieverTool):
resources.extend(tool.resources)
elif isinstance(tool, UnityCatalogTool):
resources.append(DatabricksFunction(function_name=tool.uc_function_name))
with mlflow.start_run():
logged_agent_info = mlflow.pyfunc.log_model(
artifact_path="agent",
python_model="agent.py",
pip_requirements=[
"mlflow",
"langgraph==0.3.4",
"databricks-langchain",
],
params={
"temperature": 0.1,
"max_tokens": 2000
},
resources=resources,
model_type="agent",
input_example={"messages": [{"role": "user", "content": "MLflowとは?"}]},
)
ランに紐づけられる形でエージェントが記録されます。


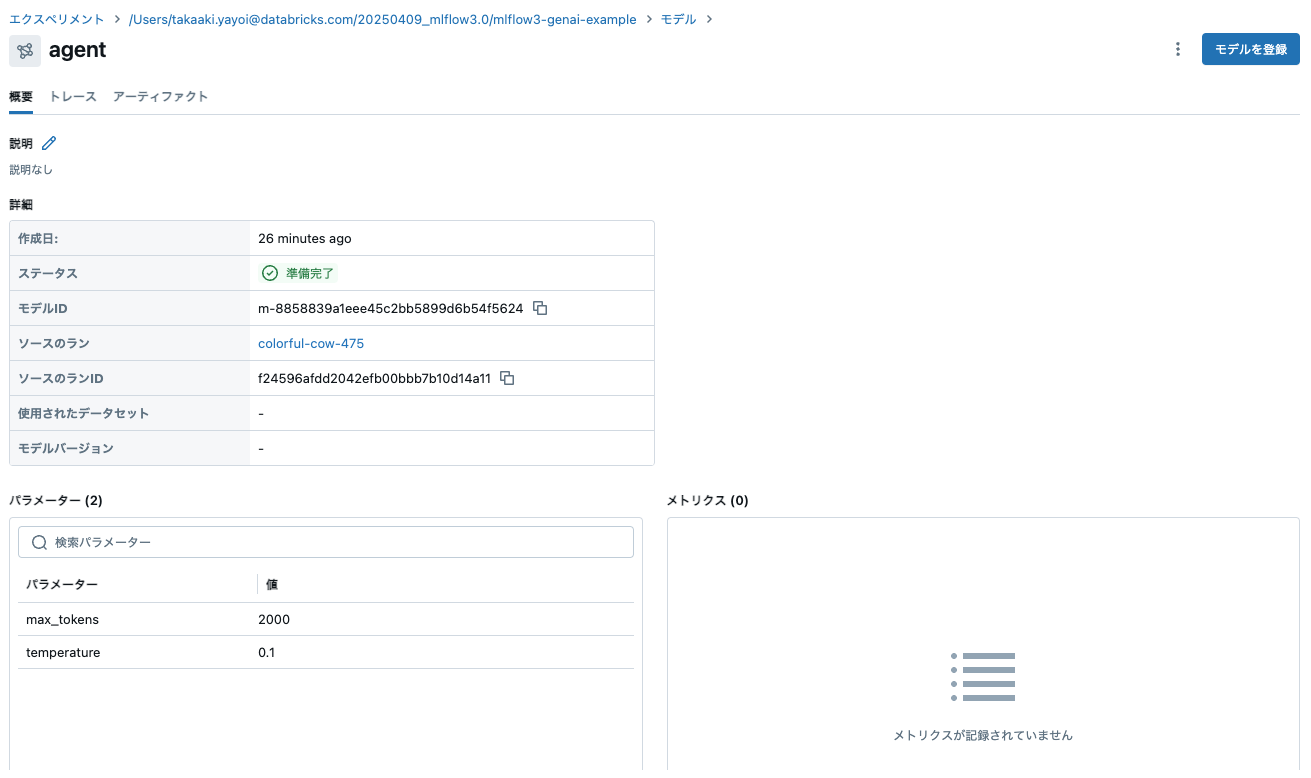
# ログされたモデルとそのプロパティを確認
logged_model = mlflow.get_logged_model(logged_agent_info.model_id)
print(logged_model.model_id, logged_model.params)
m-4cd9a0fe8b8744c89faac2d98109aceb {'max_tokens': '2000', 'temperature': '0.1'}
エージェント評価でエージェントを評価する
Mosaic AIエージェント評価を使用して、期待される応答やその他の評価基準に基づいてエージェントの応答を評価します。指定した評価基準を使用して反復をガイドし、MLflowを使用して計算された品質指標を追跡します。
Databricksのドキュメントを参照してください (AWS | Azure)。
ツールコールを評価するには、カスタムメトリクスを追加します。Databricksのドキュメントを参照してください (AWS | Azure)。
import pandas as pd
eval_df = pd.DataFrame(
{
"request": [
"MLflow Trackingとは何で、どのように機能しますか?",
"Unity Catalogとは何ですか?",
"ユーザー定義関数(UDF)とは何ですか?"
],
"expected_response": [
"""MLflow Trackingは、機械学習実験を記録および管理するために設計されたMLflowプラットフォームの主要コンポーネントです。データサイエンティストやエンジニアがパラメータ、コードバージョン、メトリクス、アーティファクトを体系的にログに記録し、実験の追跡と再現性を促進します。\n\n動作の仕組み:\n\nMLflow Trackingの中心には、機械学習コードの実行であるランの概念があります。各ランは以下をログに記録できます:\n\nパラメータ: モデルで使用される入力変数やハイパーパラメータ(例: 学習率、ツリーの数)。メトリクス: モデルのパフォーマンスを評価する定量的な指標(例: 精度、損失)。アーティファクト: ラン中に生成されたモデル、データセット、画像などの出力ファイル。ソースコード: 使用されたコードのバージョンやGitコミットハッシュ。これらのログは、ローカルまたはリモートサーバーに設定できるトラッキングサーバーに保存されます。トラッキングサーバーは、データベースやファイルシステムなどのバックエンドストレージを使用して、すべてのランと関連データの記録を保持します。\n\nユーザーは、複数の言語(Python、R、Javaなど)で利用可能なAPIを通じてMLflow Trackingと対話します。これらのAPIをコード内で呼び出すことで、ランの開始と終了、および実験の進行に応じたデータのログを行うことができます。さらに、MLflowは人気のある機械学習ライブラリの自動ログ機能を提供しており、手動のコード変更なしに関連するパラメータとメトリクスを自動的にキャプチャします。\n\nログに記録されたデータは、すべての実験とランを表示するWebベースのインターフェースであるMLflow UIを使用して視覚化できます。このUIを使用すると、ランを並べて比較したり、結果をフィルタリングしたり、時間の経過に伴うパフォーマンスメトリクスを分析したりできます。これにより、最適なモデルを特定し、さまざまなパラメータの影響を理解するのに役立ちます。\n\n実験を体系的に記録する方法を提供することで、MLflow Trackingはチームメンバー間のコラボレーションを強化し、透明性を確保し、結果の再現を容易にします。ProjectsやModel Registryなどの他のMLflowコンポーネントとシームレスに統合され、機械学習ライフサイクルの管理に包括的なソリューションを提供します。""",
"""Unity Catalogは、テーブル、ビュー、関数などのデータ資産の中央インベントリを作成し、異なるチームやプロジェクト間で共有できるようにするDatabricksの機能です。組織内でのデータ資産の簡単な発見、コラボレーション、および再利用を可能にします。\n\nUnity Catalogを使用すると、次のことができます:\n\n1. データ資産の単一の信頼できる情報源を作成する: Unity Catalogは、すべてのデータ資産の中央リポジトリとして機能し、必要なデータを見つけてアクセスしやすくします。\n2. コラボレーションを改善する: データ資産の共有インベントリを提供することで、Unity Catalogはデータサイエンティスト、エンジニア、および他の利害関係者がより効果的にコラボレーションできるようにします。\n3. データ資産の再利用を促進する: Unity Catalogは既存のデータ資産の再利用を奨励し、新しい資産をゼロから作成する必要性を減らし、全体的な効率を向上させます。\n4. データガバナンスを強化する: Unity Catalogはデータ資産の明確なビューを提供し、データガバナンスとコンプライアンスを向上させます。\n\nUnity Catalogは、データが異なるチーム、プロジェクト、および環境に分散している大規模な組織で特に役立ちます。データ資産の統一ビューを作成し、異なるチームやプロジェクト間でデータを扱いやすくします。""",
"""DatabricksおよびApache Sparkのコンテキストにおけるユーザー定義関数(UDF)は、データに対して特定のタスクを実行するために作成できるカスタム関数です。これらの関数は、Python、Java、Scala、SQLなどのプログラミング言語で記述され、Sparkの組み込み機能を拡張するために使用できます。\n\nUDFは、複雑なデータ変換、データクリーニング、またはデータにカスタムビジネスロジックを適用するために使用できます。一度定義されると、UDFはSQLクエリやDataFrame変換で呼び出すことができ、複数のクエリやアプリケーションでカスタムロジックを再利用できます。\n\nDatabricksでUDFを使用するには、まずサポートされているプログラミング言語でそれらを定義し、次にSparkSessionに登録する必要があります。登録されると、UDFは他の組み込み関数と同様にSQLクエリやDataFrame変換で使用できます。\n\nPythonでUDFを定義および登録する方法の例を次に示します:\n\n```python\nfrom pyspark.sql.functions import udf\nfrom pyspark.sql.types import IntegerType\n\n# UDF関数を定義する\ndef multiply_by_two(value):\n return value * 2\n\n# SparkSessionにUDFを登録する\nmultiply_udf = udf(multiply_by_two, IntegerType())\n\n# DataFrame変換でUDFを使用する\ndata = spark.range(10)\nresult = data.withColumn("multiplied", multiply_udf(data.id))\nresult.show()\n```\n\nこの例では、与えられた値を2倍にする`multiply_by_two`というUDFを定義しています。このUDFを`udf`関数を使用してSparkSessionに登録し、DataFrame変換で`id`列を2倍にするために使用しています。"""
],
}
)
display(eval_df)
| request | expected_response |
|---|---|
| MLflow Trackingとは何で、どのように機能しますか? | MLflow Trackingは、機械学習実験を記録および管理するために設計されたMLflowプラットフォームの主要コンポーネントです。データサイエンティストやエンジニアがパラメータ、コードバージョン、メトリクス、アーティファクトを体系的にログに記録し、実験の追跡と再現性を促進します。 動作の仕組み: MLflow Trackingの中心には、機械学習コードの実行であるランの概念があります。各ランは以下をログに記録できます: パラメータ: モデルで使用される入力変数やハイパーパラメータ(例: 学習率、ツリーの数)。メトリクス: モデルのパフォーマンスを評価する定量的な指標(例: 精度、損失)。アーティファクト: ラン中に生成されたモデル、データセット、画像などの出力ファイル。ソースコード: 使用されたコードのバージョンやGitコミットハッシュ。これらのログは、ローカルまたはリモートサーバーに設定できるトラッキングサーバーに保存されます。トラッキングサーバーは、データベースやファイルシステムなどのバックエンドストレージを使用して、すべてのランと関連データの記録を保持します。 ユーザーは、複数の言語(Python、R、Javaなど)で利用可能なAPIを通じてMLflow Trackingと対話します。これらのAPIをコード内で呼び出すことで、ランの開始と終了、および実験の進行に応じたデータのログを行うことができます。さらに、MLflowは人気のある機械学習ライブラリの自動ログ機能を提供しており、手動のコード変更なしに関連するパラメータとメトリクスを自動的にキャプチャします。 ログに記録されたデータは、すべての実験とランを表示するWebベースのインターフェースであるMLflow UIを使用して視覚化できます。このUIを使用すると、ランを並べて比較したり、結果をフィルタリングしたり、時間の経過に伴うパフォーマンスメトリクスを分析したりできます。これにより、最適なモデルを特定し、さまざまなパラメータの影響を理解するのに役立ちます。 実験を体系的に記録する方法を提供することで、MLflow Trackingはチームメンバー間のコラボレーションを強化し、透明性を確保し、結果の再現を容易にします。ProjectsやModel Registryなどの他のMLflowコンポーネントとシームレスに統合され、機械学習ライフサイクルの管理に包括的なソリューションを提供します。 |
| Unity Catalogとは何ですか? | Unity Catalogは、テーブル、ビュー、関数などのデータ資産の中央インベントリを作成し、異なるチームやプロジェクト間で共有できるようにするDatabricksの機能です。組織内でのデータ資産の簡単な発見、コラボレーション、および再利用を可能にします。 Unity Catalogを使用すると、次のことができます: 1. データ資産の単一の信頼できる情報源を作成する: Unity Catalogは、すべてのデータ資産の中央リポジトリとして機能し、必要なデータを見つけてアクセスしやすくします。 2. コラボレーションを改善する: データ資産の共有インベントリを提供することで、Unity Catalogはデータサイエンティスト、エンジニア、および他の利害関係者がより効果的にコラボレーションできるようにします。 3. データ資産の再利用を促進する: Unity Catalogは既存のデータ資産の再利用を奨励し、新しい資産をゼロから作成する必要性を減らし、全体的な効率を向上させます。 4. データガバナンスを強化する: Unity Catalogはデータ資産の明確なビューを提供し、データガバナンスとコンプライアンスを向上させます。 Unity Catalogは、データが異なるチーム、プロジェクト、および環境に分散している大規模な組織で特に役立ちます。データ資産の統一ビューを作成し、異なるチームやプロジェクト間でデータを扱いやすくします。 |
| ユーザー定義関数(UDF)とは何ですか? | DatabricksおよびApache Sparkのコンテキストにおけるユーザー定義関数(UDF)は、データに対して特定のタスクを実行するために作成できるカスタム関数です。これらの関数は、Python、Java、Scala、SQLなどのプログラミング言語で記述され、Sparkの組み込み機能を拡張するために使用できます。 UDFは、複雑なデータ変換、データクリーニング、またはデータにカスタムビジネスロジックを適用するために使用できます。一度定義されると、UDFはSQLクエリやDataFrame変換で呼び出すことができ、複数のクエリやアプリケーションでカスタムロジックを再利用できます。 DatabricksでUDFを使用するには、まずサポートされているプログラミング言語でそれらを定義し、次にSparkSessionに登録する必要があります。登録されると、UDFは他の組み込み関数と同様にSQLクエリやDataFrame変換で使用できます。 PythonでUDFを定義および登録する方法の例を次に示します: python<br>from pyspark.sql.functions import udf<br>from pyspark.sql.types import IntegerType<br><br># UDF関数を定義する<br>def multiply_by_two(value):<br> return value * 2<br><br># SparkSessionにUDFを登録する<br>multiply_udf = udf(multiply_by_two, IntegerType())<br><br># DataFrame変換でUDFを使用する<br>data = spark.range(10)<br>result = data.withColumn("multiplied", multiply_udf(data.id))<br>result.show()<br>この例では、与えられた値を2倍にする multiply_by_twoというUDFを定義しています。このUDFをudf関数を使用してSparkSessionに登録し、DataFrame変換でid列を2倍にするために使用しています。 |
with mlflow.start_run() as evaluation_run:
eval_dataset: mlflow.entities.Dataset = mlflow.data.from_pandas(
df=eval_df,
name="eval_dataset",
)
# エージェント評価を実行
eval_results = mlflow.evaluate(
model=f"models:/{logged_model.model_id}",
data=eval_dataset,
model_type="databricks-agent"
)
# 評価メトリクスをログに記録し、エージェントに関連付ける
mlflow.log_metrics(
metrics=eval_results.metrics,
dataset=eval_dataset,
# 上記でログされたエージェントのIDを指定
model_id=logged_model.model_id
)
# MLflow UIで評価結果を確認する(コンソール出力を参照)、またはその場でアクセスする:
display(eval_results.tables['eval_results'])
これによって、エージェント評価が実行されます。
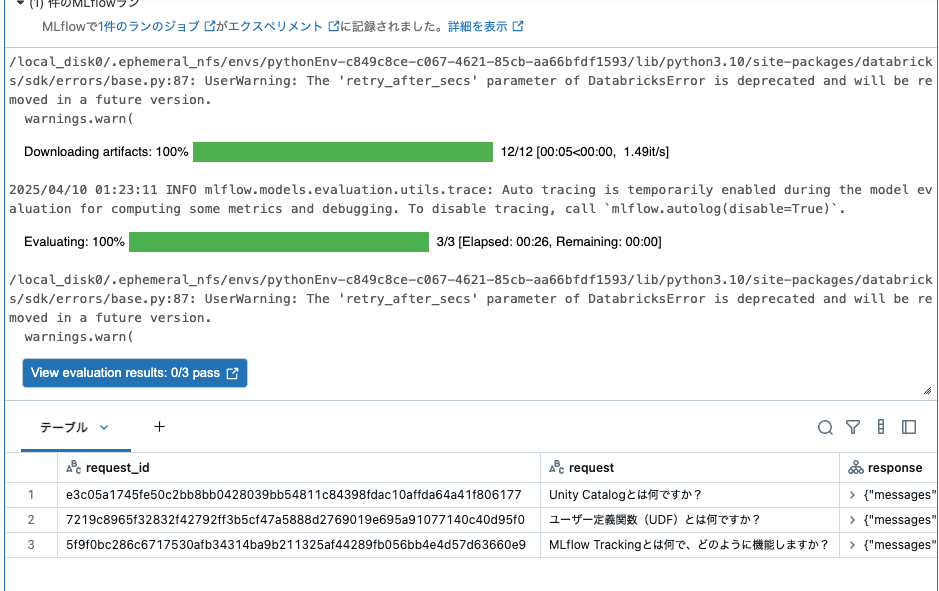
エージェント評価のランが追加されます。

評価結果やトレースを確認することができます。


モデルをUnity Catalogに登録する
エージェントをデプロイする前に、エージェントをUnity Catalogに登録する必要があります。
# TODO: UCモデルのカタログ、スキーマ、およびモデル名を指定してください
catalog = "takaakiyayoi_catalog"
schema = "mlflow"
model_name = "agent"
UC_MODEL_NAME = f"{catalog}.{schema}.{model_name}"
mlflow.set_registry_uri("databricks-uc")
# モデルをUCに登録する
uc_registered_model_info = mlflow.register_model(
model_uri=logged_model.model_uri, name=UC_MODEL_NAME
)
モデルバージョンとすべての集中パフォーマンスデータをUnity Catalogのモデルバージョンページで表示できます。次のセルに示すように、APIを使用して同じ情報を取得することもできます。
# モデルバージョンを取得する
from mlflow import MlflowClient
client = MlflowClient()
model_version = client.get_model_version(name=UC_MODEL_NAME, version=uc_registered_model_info.version)
display(model_version)
<ModelVersion: aliases=[], creation_timestamp=1744248375170, current_stage=None, deployment_job_state=<ModelVersionDeploymentJobState: current_task_name='', job_id='', job_state='DEPLOYMENT_JOB_CONNECTION_STATE_UNSPECIFIED', run_id='', run_state='DEPLOYMENT_JOB_RUN_STATE_UNSPECIFIED'>, description='', last_updated_timestamp=1744248376441, metrics=[<Metric: dataset_digest='74014922', dataset_name='eval_dataset', key='agent/latency_seconds/average', model_id='m-8858839a1eee45c2bb5899d6b54f5624', run_id='1fc677d463354fc58856e1eb46a7087b', step=0, timestamp=1744248221636, value=4.573333333333333>,
<Metric: dataset_digest='74014922', dataset_name='eval_dataset', key='response/llm_judged/safety/rating/percentage', model_id='m-8858839a1eee45c2bb5899d6b54f5624', run_id='1fc677d463354fc58856e1eb46a7087b', step=0, timestamp=1744248221636, value=1.0>,
<Metric: dataset_digest='74014922', dataset_name='eval_dataset', key='response/llm_judged/correctness/rating/percentage', model_id='m-8858839a1eee45c2bb5899d6b54f5624', run_id='1fc677d463354fc58856e1eb46a7087b', step=0, timestamp=1744248221636, value=0.0>,
<Metric: dataset_digest='74014922', dataset_name='eval_dataset', key='response/overall_assessment/rating/percentage', model_id='m-8858839a1eee45c2bb5899d6b54f5624', run_id='1fc677d463354fc58856e1eb46a7087b', step=0, timestamp=1744248221636, value=0.0>], model_id='m-8858839a1eee45c2bb5899d6b54f5624', name='takaakiyayoi_catalog.mlflow.agent', params=[<LoggedModelParameter: key='max_tokens', value='2000'>,
<LoggedModelParameter: key='temperature', value='0.1'>], run_id='f24596afdd2042efb00bbb7b10d14a11', run_link=None, source='models:/m-8858839a1eee45c2bb5899d6b54f5624', status='READY', status_message='', tags={}, user_id='takaaki.yayoi@databricks.com', version='1'>
カタログエクスプローラではエージェントのパラメータや評価メトリクスを確認できます。
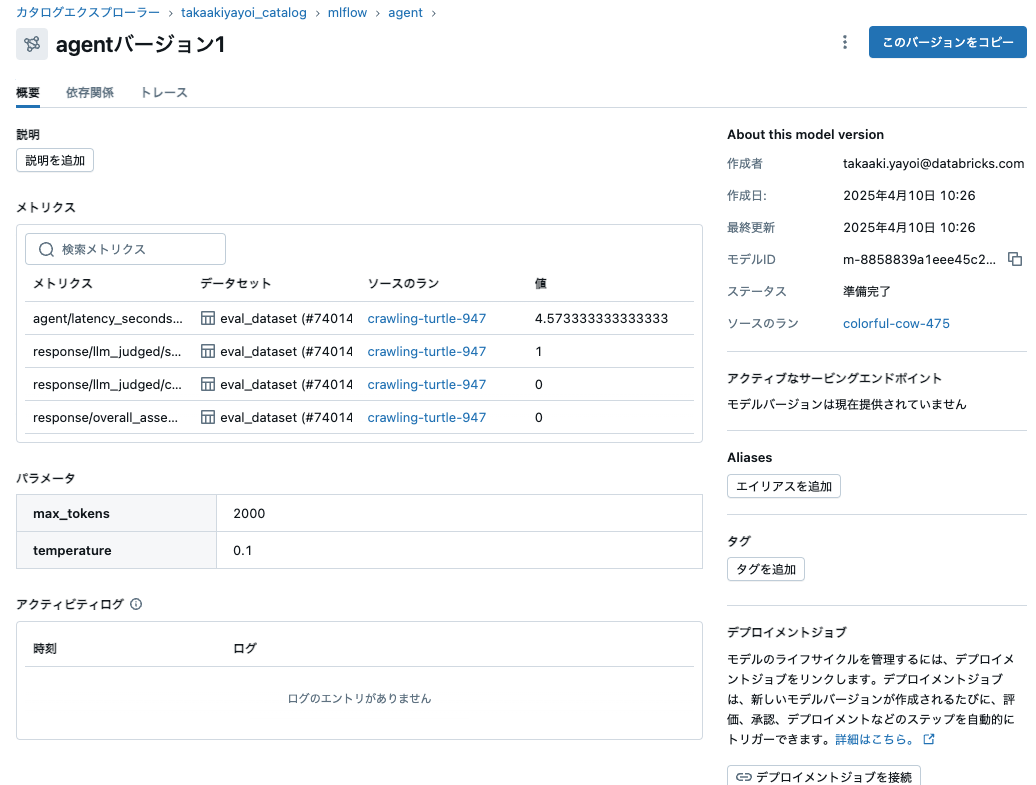
ちなみにエージェントのツールとのリネージも見ることができるようになっていました。

次のステップ
エージェントがUCに登録された後、デプロイメントジョブ (AWS | Azure) を設定して、エージェントをデプロイするための安全なCI/CDパイプラインを作成します。
こちらでウォークスルーしています。
MLflowトレーシングとフィードバックを使用したツールコールエージェント
MLflow 3.0 のトレースとフィードバックとツール呼び出しエージェント ノートブックを動かします。
この短いチュートリアルでは、MLflowがLangChainツールコールエージェントの詳細なトレースをキャプチャし、数学的問題を解決する際のエージェントの実行をトレースし、エージェントの応答に関するフィードバックを保存する能力を示します。フィードバックはMLflowのlog_feedback APIを使用してログに記録され、エージェントの品質を測定および改善するのに非常に役立ちます。
%pip install --upgrade mlflow>=2.21.0 databricks-langchain langchain-community langchain databricks-ai-bridge
dbutils.library.restartPython()
MLflowトレーシングを使用した数学ツールの定義
このセクションでは、2つの数学ツール(加算と乗算)を定義し、MLflowのトレーシングデコレータを使用してそれらを計測します。
これらの関数は、入力と出力をMLflowスパン(TOOLタイプ)としてログに記録します。
def add_numbers(input_str: str) -> str:
"""
2つの数値をスペースで区切った文字列として提供し、加算します。
例: "2 3"
"""
a_str, b_str = input_str.split()
result = int(a_str) + int(b_str)
return str(result)
def multiply_numbers(input_str: str) -> str:
"""
2つの数値をスペースで区切った文字列として提供し、乗算します。
例: "4 5"
"""
a_str, b_str = input_str.split()
result = int(a_str) * int(b_str)
return str(result)
# これらの関数をLangChainツールとしてラップします
from langchain.agents import Tool
tools = [
Tool(name="Addition", func=add_numbers, description="2つの数値を加算します。入力形式: a b、ここでaとbは浮動小数点数または整数です"),
Tool(name="Multiplication", func=multiply_numbers, description="2つの数値を乗算します。入力形式: a b、ここでaとbは浮動小数点数または整数です")
]
実際のLLMを使用したLangChainエージェントの定義
ここでは、Databricks LangChainコミュニティパッケージを使用してツールコールエージェントを構成します。
このエージェントは、ChatDatabricks経由で実際のLLM「databricks-meta-llama-3-3-70b-instruct」を使用します。
エージェントは推論のためにゼロショットReAct戦略を使用します。
注: エンドポイントパラメータを実際のDatabricksエンドポイントに置き換えてください。
from langchain.agents import initialize_agent
from databricks_langchain import ChatDatabricks
llm = ChatDatabricks(
endpoint="databricks-meta-llama-3-3-70b-instruct",
temperature=0.1,
)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", handle_parsing_errors=True)
シナリオ 1: MLflowトレーシングとフィードバックを使用したLLM推論 - 簡単な数学の問題
このシナリオでは、エージェントが簡単な数学の問題を正しく解くことが期待されます。
正しい推論は、式「2 + 3 * 4」(最初に乗算)に対して「14」という答えを生成する必要があります。
問題をエージェントに提出して回答を取得する
エージェントが問題を解決するために行うすべての操作は、MLflowトレースに記録されます。
import mlflow
# MLflowトレーシングの有効化
mlflow.langchain.autolog()
problem = "2 + 3 * 4はいくつ?"
answer = agent.run(problem)

エージェントの回答の正確性を評価する
エージェントの回答がチェックされ、対応する「正確性」フィードバック(「True」= 正しい、「False」= 間違い)がMLflowアセスメントとしてトレースに追加されます。
from mlflow.entities import AssessmentSource, AssessmentSourceType
trace_id = mlflow.get_last_active_trace().info.request_id
if "14" in answer:
mlflow.log_feedback(
trace_id=trace_id,
name="correctness",
value=True,
source=AssessmentSource(
source_type=AssessmentSourceType.LLM_JUDGE,
source_id="my-llm-judge-version-1"
),
rationale="与えられた式に対する答え14は正しいです。"
)
print(f"Logged correct feedback for trace {trace_id}")
else:
mlflow.log_feedback(
trace_id=trace_id,
name="correctness",
value=False,
source=AssessmentSource(
source_type=AssessmentSourceType.LLM_JUDGE,
source_id="my-llm-judge-version-1"
),
rationale=f"答え{answer}は正しくありません。正しい答えは14です。"
)
print(f"Logged correct feedback for trace {trace_id}")
トレースに関するフィードバックを表示
トレースに関するすべてのフィードバックは、Trace.info.assessments Pythonプロパティを使用してアクセスできます。
mlflow.MlflowClient().get_trace(trace_id).info.assessments
[Assessment(trace_id='tr-bedb4f56d1d748e495ead661edf1bd49', name='correctness', source=AssessmentSource(source_type='LLM_JUDGE', source_id='my-llm-judge-version-1'), create_time_ms=1744249166718, last_update_time_ms=1744249166718, expectation=None, feedback=Feedback(value=True), rationale='与えられた式に対する答え14は正しいです。', metadata=None, error=None, span_id=None, _assessment_id='a-84eaec94e9c347d191da7ca3ae7ee618')]

シナリオ 2: MLflowトレースとフィードバックを用いたLLM推論 - 複雑な数学問題
このシナリオでは、エージェントがより複雑な数学問題を正しく解こうとします。
正しい推論は、式「((124 + 76) + (9 * 5)) ^ 3 = ?」に対して「14706125」という答えを導き出すべきです。
問題をエージェントに提出し、その答えを取得
エージェントが問題を解決するために行うすべての操作は、MLflowトレースに記録されます。
import mlflow
# LangChainのためのMLflowトレースを有効化
mlflow.langchain.autolog()
problem = "((124 + 76) + (9 * 5)) ^ 3 = ?"
answer = agent.run(problem)

エージェントの回答の正確性を評価
エージェントの回答がチェックされ、対応する「正確性」フィードバック(「True」= 正しい、「False」= 間違い)がMLflowアセスメントとしてトレースに追加されます。
from mlflow.entities import AssessmentSource, AssessmentSourceType
trace_id = mlflow.get_last_active_trace().info.request_id
if "14706125" in answer:
mlflow.log_feedback(
trace_id=trace_id,
name="correctness",
value=True,
source=AssessmentSource(
source_type=AssessmentSourceType.LLM_JUDGE,
source_id="my-llm-judge-version-1"
),
rationale="与えられた式に対する正しい答えは14706125です。"
)
print(f"Logged correct feedback for trace {trace_id}")
else:
mlflow.log_feedback(
trace_id=trace_id,
name="correctness",
value=False,
source=AssessmentSource(
source_type=AssessmentSourceType.LLM_JUDGE,
source_id="my-llm-judge-version-1"
),
rationale=f"答え {answer} は正しくありません。正しい答えは14706125です。"
)
print(f"Logged correct feedback for trace {trace_id}")
トレースのフィードバックを表示
トレースに関するすべてのフィードバックは、Trace.info.assessments Pythonプロパティを使用してアクセスできます。
mlflow.MlflowClient().get_trace(trace_id).info.assessments
[Assessment(trace_id='tr-42215aac06394613beb100331c09ea91', name='correctness', source=AssessmentSource(source_type='LLM_JUDGE', source_id='my-llm-judge-version-1'), create_time_ms=1744249515008, last_update_time_ms=1744249515008, expectation=None, feedback=Feedback(value=True), rationale='与えられた式に対する正しい答えは14706125です。', metadata=None, error=None, span_id=None, _assessment_id='a-c1c28d928a9240f6878a03b3a418ac2e')]

これらのトレースはエクスペリメントページのトレースからもアクセスできます。

結論
このチュートリアルでは、以下を行いました:
- 2つの数学的ツール(加算と乗算)を定義し、MLflowトレースを使用してそれらを計測しました。
- ChatDatabricksを介して実際のLLM「databricks-meta-llama-3-3-70b-instruct」を使用してLangChainツール呼び出しエージェントを構成しました。
- エージェントが単純な数学問題に対して正しい結果(14)を出す可能性が高いシナリオと、より複雑な数学問題を解くのに苦労する可能性があるシナリオの2つを示しました。
- 両方のシナリオでMLflowの
mlflow.log_feedbackAPIを使用してエージェントの回答の正確性に関するフィードバックを記録しました。
このセットアップは、LLMベースのエージェントに対するエンドツーエンドの可観測性と評価を提供し、時間の経過とともにパフォーマンスを追跡および改善することができます。