探索的データ分析(Explanatory Data Analysis: EDA)のチュートリアルが新しくなっていました。
以下のサンプルノートブックを翻訳しながら実行していきます。いろいろな切り口で可視化を行い、洞察が加えられているのでとても勉強になりました。
翻訳したノートブックはこちらです。
🌍🔋 EDAチュートリアル: 世界のエネルギーと排出データの探索 🔍🌱
このノートブックでは、世界のエネルギー消費と温室効果ガス排出データを深く掘り下げ、グローバルな傾向、地域の格差、再生可能エネルギーの影響の増大を強調する洞察を探ります。一連のデータビジュアライゼーションと分析を通じて、以下のトピックを調査します:
- エネルギー消費が多い国と再生可能エネルギーのリーダー 🌍🔋
- 地域ごとの温室効果ガス排出の傾向 🏭🌱
- 世界のエネルギー需要の予測 📊👥
エネルギー使用のダイナミクスと持続可能な未来への影響を理解するためのこの探索に参加してください! 🌱
データセットのダウンロード
このチュートリアルでは、グローバルなエネルギーと排出データを調査することで、EDA技術を実演します。以下のリンクからKaggleのOur World in Dataによるエネルギー消費データセットをダウンロードしてください。このチュートリアルでは、owid-energy-data.csvファイルを使用します。
このノートブックからデータセットをDatabricksワークスペースにインポートするには:
- 左側のフォルダーアイコンをクリックしてワークスペースサイドパネルを開きます。
- CSVファイル
owid-energy-data.csvをパネルにドラッグアンドドロップします。あるいは、ケバブメニューをクリックしてインポートを選択し、ファイルを選択します。 - インポートをクリックします。ファイルがワークスペースに表示されるはずです。
データセットのファイルパスに注意してください。このノートブックで使用する必要があります。ファイル名を右クリックして、URL/パスをコピー > フルパスを選択すると、ファイルパスをクリップボードにコピーできます。
データのロード
import numpy as np
import pandas as pd # データ処理、CSVファイルの入出力(例:pd.read_csv)
df=pd.read_csv('/Workspace/Users/takaaki.yayoi@databricks.com/20250507_databricks_eda/owid-energy-data.csv') # 最後のステップでコピーしたデータのフルパスにここを置き換えてください
データを理解する
データセットの基本を理解することは、データサイエンスプロジェクトにおいて重要です。これは、データの構造、種類、および品質に慣れることを含みます。
Databricksでは、display(df)コマンドを使用してデータセットを表示できます。データセットが10,000行を超えるため、このコマンドは切り捨てられたデータセットを返します。各列の左側には、列のデータ型が表示されます。
display(df)

pandasを使用してデータの洞察を得る
データセットを効果的に理解するために、以下のpandasコマンドを使用します:
-
df.shapeコマンドはDataFrameの寸法を返し、行と列の数をすばやく把握できます。 -
df.dtypesコマンドは各列のデータ型を提供し、扱っているデータの種類を理解するのに役立ちます。結果テーブルでも各列のデータ型を確認できます。 -
df.describe()コマンドは、平均、標準偏差、パーセンタイルなどの数値列に関する記述統計を生成し、パターンの特定、異常の検出、データの分布の理解に役立ちます。また、行と列の数も教えてくれます。
df.shape # データフレームの行数と列数を返します
(21812, 130)
df.dtypes # 各列とそのデータ型のリストを返します
country object
year int64
iso_code object
population float64
gdp float64
...
wind_elec_per_capita float64
wind_electricity float64
wind_energy_per_capita float64
wind_share_elec float64
wind_share_energy float64
Length: 130, dtype: object
# データセットの要約統計量を返します
df.describe()

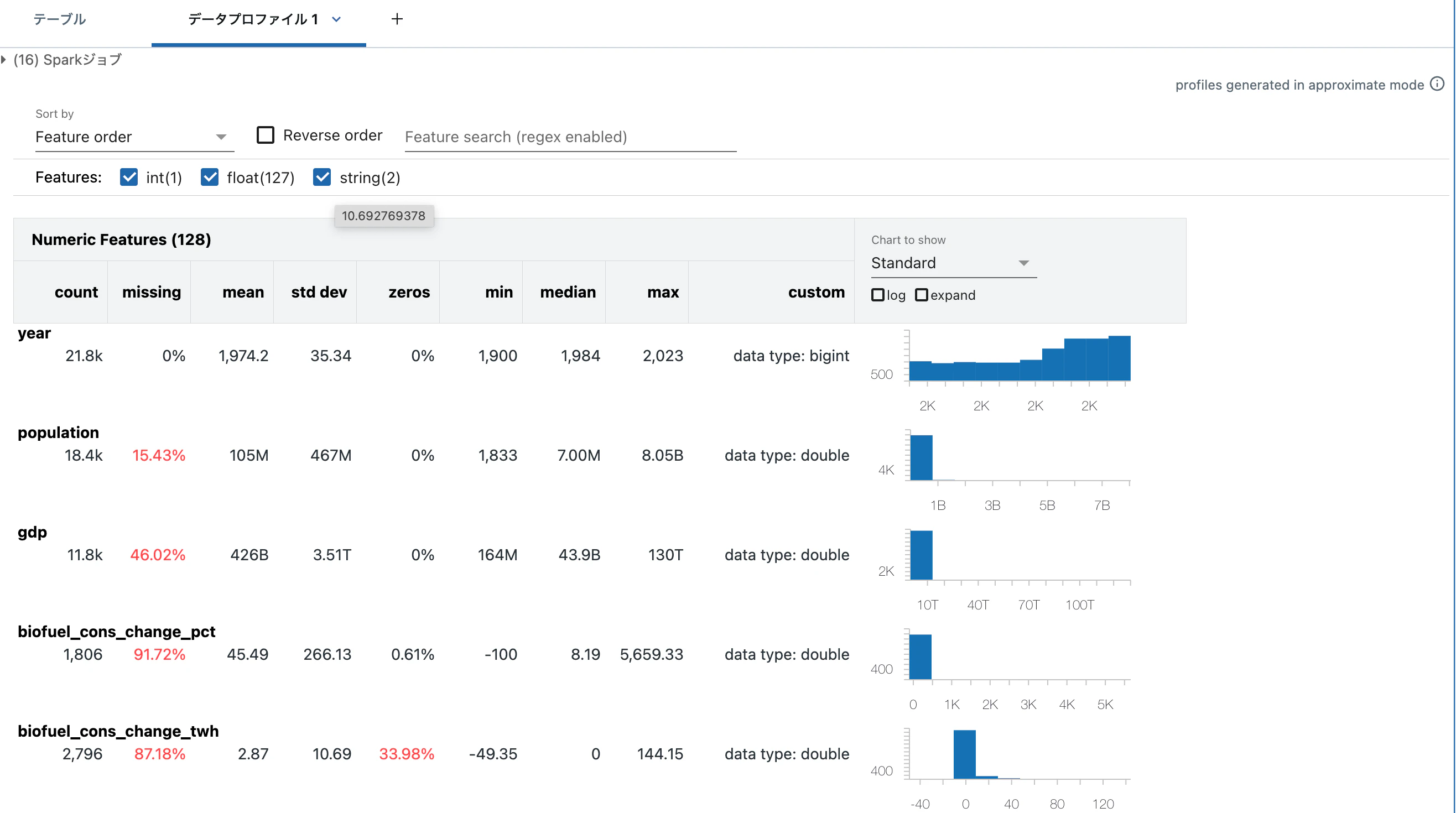
データプロファイルを生成する
Databricksノートブックには、組み込みのデータプロファイリング機能が含まれています。Databricksのdisplay関数を使用してDataFrameを表示する際に、データプロファイルを生成できます。
以下のコードを実行し、出力のTableの横にある + -> データプロファイル をクリックします。これにより、データフレーム内のデータのプロファイルを生成する新しいコマンドが自動的に実行されます。プロファイルには、数値、文字列、および日付列の要約統計と、各列の値分布のヒストグラムが含まれます。このコマンドは、テーブルに表示される部分(切り捨てられることがあります)ではなく、データフレームまたはSQLクエリ結果の全体データセットをプロファイルします。
# データフレームを表示し、次に「+ -> データプロファイル」をクリックしてデータプロファイルを生成します
display(df)
データのクリーンアップ
データのクリーンアップは、データセットが正確で一貫性があり、意味のある分析に準備が整っていることを確認するためのEDAの重要なステップです。このプロセスには、データを分析に適した状態にするためのいくつかの重要なタスクが含まれます。
- 重複データの特定と削除。
- 欠損値の処理。特定の値で置き換えるか、影響を受ける行を削除することが含まれます。
- データ型の標準化(例:文字列を
datetimeに変換)を通じて一貫性を確保する。作業しやすい形式にデータを変換することも考慮します。
このクリーンアップフェーズは、データの品質と信頼性を向上させ、より正確で洞察に満ちた分析を可能にします。
ヒント: アシスタントにデータクリーンアップのコード生成を依頼してみてください
Databricksアシスタントを使用してコードを生成することができます。新しいコードセルを作成し、「生成」リンクをクリックするか、右上のアシスタントアイコンを使用してアシスタントを開きます。アシスタントにクエリを入力します。例えば、アシスタントにデータを説明するように依頼します。
例えば、次のプロンプトを使用してデータクリーンアップのコードを迅速に生成してみてください:
- dfに重複する列や行が含まれているか確認します。重複を表示し、削除します。
- 日付列の形式は何ですか? 'YYYY-MM-DD' に変更します。
- XXX列は使用しないので、削除します。
重複データの削除
重複する行の数: 0
重複する列: []
null値または欠損値の処理
# すべてのNaN(Not a Number)値を0に置換
df = df.fillna(0)
display(df.head())
日付の再フォーマット
# 'year'列が正しいデータ型(年の整数)に変換されていることを確認
df['year'] = pd.to_datetime(df['year'], format='%Y', errors='coerce').dt.year
# 変更を確認
df.year.dtype
dtype('int64')
Databricksノートブックの出力テーブルを使用してデータを探索する
Databricksは、出力テーブルを使用してデータを探索するための組み込み機能を提供しています。
新しいセルで、display(df)を使用してデータセットをテーブルとして表示します。
出力テーブルからは以下のことができます:
-
特定の文字列や値を検索する。 テーブルの右上にある検索アイコンをクリックし、検索内容を入力します。
-
特定の条件でフィルタリングする。 組み込みのテーブルフィルタを使用して、特定の条件で列をフィルタリングできます。
ヒント: フィルタを生成するためにアシスタントを使用します。フィルタアイコンをクリックし、希望するフィルタ条件を入力します。

-
データセットを使用して可視化を作成する。 出力テーブルの上部で、+ > Visualizationをクリックして可視化エディタを開きます。
以下の画像は、複数の折れ線グラフを追加して、さまざまな再生可能エネルギー源の消費を時系列で表示する方法を示しています。

display(df)

Pythonライブラリを使用してデータを探索および可視化する
可視化を通じたデータの探索は、EDAの基本的な側面です。可視化は、数値分析だけではすぐには明らかにならないデータ内のパターン、トレンド、および関係を明らかにするのに役立ちます。散布図、棒グラフ、折れ線グラフ、ヒストグラムなどの一般的な可視化手法には、PlotlyやMatplotlibなどのライブラリを使用します。これらの視覚的ツールを使用することで、データサイエンティストは異常値を特定し、データの分布を理解し、変数間の相関関係を観察できます。例えば、散布図は外れ値を強調し、時系列プロットはトレンドや季節性を明らかにすることができます。
ユニークな国の配列を作成する
# ユニークな国を取得
unique_countries = df['country'].unique()
unique_countries
array(['ASEAN (Ember)', 'Afghanistan', 'Africa', 'Africa (EI)',
'Africa (EIA)', 'Africa (Ember)', 'Africa (Shift)', 'Albania',
'Algeria', 'American Samoa', 'Angola', 'Antarctica',
'Antigua and Barbuda', 'Argentina', 'Armenia', 'Aruba', 'Asia',
'Asia & Oceania (EIA)', 'Asia (Ember)', 'Asia Pacific (EI)',
'Asia and Oceania (Shift)', 'Australia',
'Australia and New Zealand (EIA)', 'Austria', 'Azerbaijan',
'Bahamas', 'Bahrain', 'Bangladesh', 'Barbados', 'Belarus',
'Belgium', 'Belize', 'Benin', 'Bermuda', 'Bhutan', 'Bolivia',
'Bosnia and Herzegovina', 'Botswana', 'Brazil',
'British Virgin Islands', 'Brunei', 'Bulgaria', 'Burkina Faso',
'Burundi', 'CIS (EI)', 'Cambodia', 'Cameroon', 'Canada',
'Cape Verde', 'Cayman Islands', 'Central & South America (EIA)',
'Central African Republic', 'Central America (EI)',
'Central and South America (Shift)', 'Chad', 'Chile', 'China',
'Colombia', 'Comoros', 'Congo', 'Cook Islands', 'Costa Rica',
"Cote d'Ivoire", 'Croatia', 'Cuba', 'Curacao', 'Cyprus', 'Czechia',
'Czechoslovakia', 'Democratic Republic of Congo', 'Denmark',
'Djibouti', 'Dominica', 'Dominican Republic', 'EU28 (Shift)',
'East Germany', 'East Timor', 'Eastern Africa (EI)', 'Ecuador',
'Egypt', 'El Salvador', 'Equatorial Guinea', 'Eritrea', 'Estonia',
'Eswatini', 'Ethiopia', 'Eurasia (EIA)', 'Eurasia (Shift)',
'Europe', 'Europe (EI)', 'Europe (EIA)', 'Europe (Ember)',
'Europe (Shift)', 'European Union (27)', 'Falkland Islands',
'Faroe Islands', 'Fiji', 'Finland', 'France', 'French Guiana',
'French Polynesia', 'G20 (Ember)', 'G7 (Ember)', 'Gabon', 'Gambia',
'Georgia', 'Germany', 'Ghana', 'Gibraltar', 'Greece', 'Greenland',
'Grenada', 'Guadeloupe', 'Guam', 'Guatemala', 'Guinea',
'Guinea-Bissau', 'Guyana', 'Haiti', 'High-income countries',
'Honduras', 'Hong Kong', 'Hungary', 'Iceland', 'India',
'Indonesia', 'Iran', 'Iraq', 'Ireland', 'Israel', 'Italy',
'Jamaica', 'Japan', 'Jordan', 'Kazakhstan', 'Kenya', 'Kiribati',
'Kosovo', 'Kuwait', 'Kyrgyzstan', 'Laos',
'Latin America and Caribbean (Ember)', 'Latvia', 'Lebanon',
'Lesotho', 'Liberia', 'Libya', 'Lithuania', 'Low-income countries',
'Lower-middle-income countries', 'Luxembourg', 'Macao',
'Madagascar', 'Malawi', 'Malaysia', 'Maldives', 'Mali', 'Malta',
'Martinique', 'Mauritania', 'Mauritius', 'Mexico',
'Micronesia (country)', 'Middle Africa (EI)', 'Middle East (EI)',
'Middle East (EIA)', 'Middle East (Ember)', 'Middle East (Shift)',
'Moldova', 'Mongolia', 'Montenegro', 'Montserrat', 'Morocco',
'Mozambique', 'Myanmar', 'Namibia', 'Nauru', 'Nepal',
'Netherlands', 'Netherlands Antilles', 'New Caledonia',
'New Zealand', 'Nicaragua', 'Niger', 'Nigeria', 'Niue',
'Non-OECD (EI)', 'Non-OECD (EIA)', 'Non-OPEC (EI)',
'Non-OPEC (EIA)', 'North America', 'North America (EI)',
'North America (Ember)', 'North America (Shift)', 'North Korea',
'North Macedonia', 'Northern Mariana Islands', 'Norway',
'OECD (EI)', 'OECD (EIA)', 'OECD (Ember)', 'OECD (Shift)',
'OPEC (EI)', 'OPEC (EIA)', 'OPEC (Shift)', 'Oceania',
'Oceania (Ember)', 'Oman', 'Pakistan', 'Palestine', 'Panama',
'Papua New Guinea', 'Paraguay', 'Persian Gulf (EIA)',
'Persian Gulf (Shift)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto Rico', 'Qatar', 'Reunion', 'Romania', 'Russia',
'Rwanda', 'Saint Helena', 'Saint Kitts and Nevis', 'Saint Lucia',
'Saint Pierre and Miquelon', 'Saint Vincent and the Grenadines',
'Samoa', 'Sao Tome and Principe', 'Saudi Arabia', 'Senegal',
'Serbia', 'Serbia and Montenegro', 'Seychelles', 'Sierra Leone',
'Singapore', 'Slovakia', 'Slovenia', 'Solomon Islands', 'Somalia',
'South Africa', 'South America', 'South Korea', 'South Sudan',
'South and Central America (EI)', 'Spain', 'Sri Lanka', 'Sudan',
'Suriname', 'Sweden', 'Switzerland', 'Syria', 'Taiwan',
'Tajikistan', 'Tanzania', 'Thailand', 'Togo', 'Tonga',
'Trinidad and Tobago', 'Tunisia', 'Turkey', 'Turkmenistan',
'Turks and Caicos Islands', 'Tuvalu', 'U.S. Pacific Islands (EIA)',
'U.S. Territories (EIA)', 'USSR', 'Uganda', 'Ukraine',
'United Arab Emirates', 'United Kingdom', 'United States',
'United States Pacific Islands (Shift)',
'United States Territories (Shift)',
'United States Virgin Islands', 'Upper-middle-income countries',
'Uruguay', 'Uzbekistan', 'Vanuatu', 'Venezuela', 'Vietnam',
'Wake Island (EIA)', 'Wake Island (Shift)', 'West Germany',
'Western Africa (EI)', 'Western Sahara', 'World', 'Yemen',
'Yugoslavia', 'Zambia', 'Zimbabwe'], dtype=object)
洞察: これにより、国の列には、世界、高所得国、アジア、アメリカ合衆国など、必ずしも直接比較できないさまざまなエンティティが含まれていることがわかります。データを地域別にフィルタリングする方が有用かもしれません。
主要10カ国の排出量の傾向をチャート化 (2000 - 2022)
import plotly.express as px
# データを2000年から2022年までの年にフィルタリング
filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
# フィルタリングされたデータで排出量が最も多い上位10か国を取得
top_countries = filtered_data.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
# これらの上位国のデータをフィルタリング
top_countries_data = filtered_data[filtered_data['country'].isin(top_countries)]
# これらの国の排出量の傾向をプロット
fig = px.line(top_countries_data, x='year', y='greenhouse_gas_emissions', color='country',
title="Greenhouse Gas Emissions Trends for Top 10 Countries (2000 - 2022)")
fig.show()
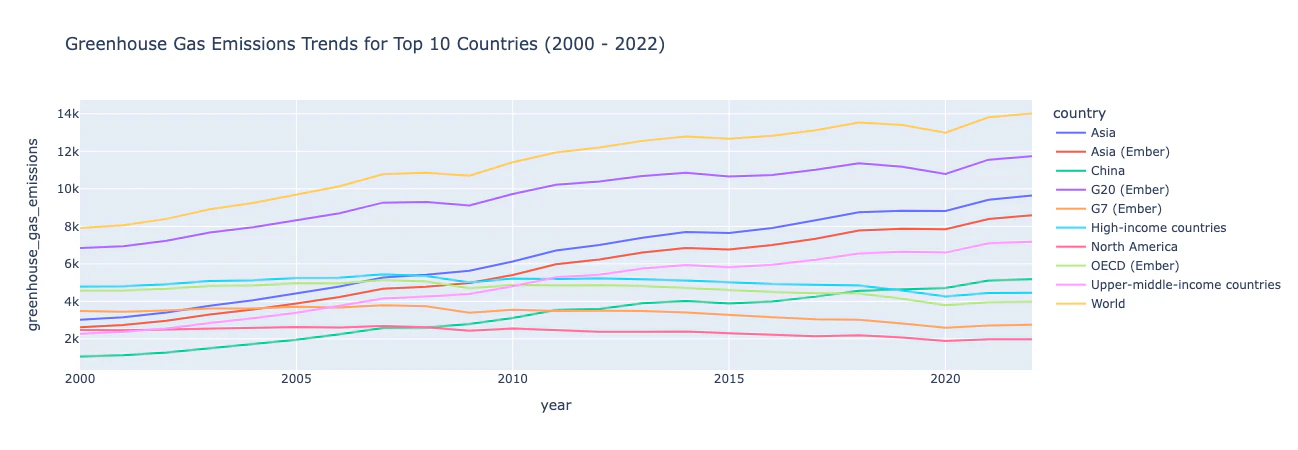
洞察: このチャートから、2000年から2022年にかけて全体的な温室効果ガス排出量が増加傾向にあることがわかります。ただし、いくつかの国では排出量が比較的安定しており、その期間中にわずかに減少していることが見受けられます。
棒グラフ: 地域別の排出量をフィルタリングしてチャート化
# 地域エンティティを除外
regions = ['Africa', 'Asia', 'Europe', 'North America', 'South America', 'Oceania']
# 各地域の総排出量を計算
regional_emissions = df[df['country'].isin(regions)].groupby('country')['greenhouse_gas_emissions'].sum()
# 比較をプロット
fig = px.bar(regional_emissions, title="Greenhouse Gas Emissions by Region")
fig.show()

洞察: このチャートから、アジアが最も多くの温室効果ガスを排出している地域であることがわかります。オセアニア、南アメリカ、アフリカは最も少ない温室効果ガスを排出しています。
主要な再生可能エネルギーリーダー10カ国の再生可能エネルギーシェアの成長を計算してグラフ化 (2000-2022)
# 再生可能エネルギーのシェアを計算し、新しい列「renewable_share」として保存
df['renewable_share'] = df['renewables_consumption'] / df['primary_energy_consumption']
# 各国の平均再生可能エネルギーシェアでランク付け
renewable_ranking = df.groupby('country')['renewable_share'].mean().sort_values(ascending=False)
# 再生可能エネルギーシェアで上位の国をフィルタリング
leading_renewable_countries = renewable_ranking.head(10).index
leading_renewable_data = df[df['country'].isin(leading_renewable_countries)]
# データを2000年から2022年までの年にフィルタリング
leading_renewable_data_filter = leading_renewable_data[(leading_renewable_data['year'] >= 2000) & (leading_renewable_data['year'] <= 2022)]
# 上位の再生可能エネルギー国の再生可能エネルギーシェアの成長をプロット
fig = px.line(leading_renewable_data_filter, x='year', y='renewable_share', color='country',
title="Renewable Energy Share Growth Over Time for Leading Countries")
fig.show()
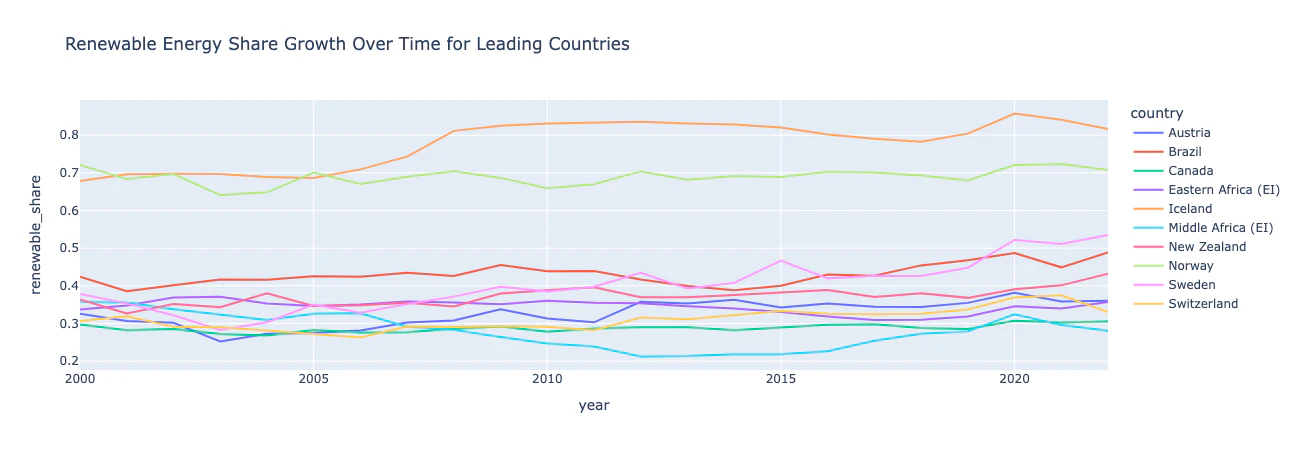
洞察: ノルウェーとアイスランドは再生可能エネルギーの分野で世界をリードしており、消費の半分以上が再生可能エネルギーから来ています。アイスランドとスウェーデンは再生可能エネルギーシェアの最大の成長を遂げました。すべての国で時折の減少と増加が見られ、再生可能エネルギーシェアが直線的に成長していないことがわかります。興味深いことに、中部アフリカは2010年代初頭に減少を見せましたが、2020年に回復しました。
散布図: 主要な排出国10カ国における再生可能エネルギーが排出量に与える影響を示す
# 上位の排出国を選択し、再生可能エネルギーシェアと排出量を計算
top_emitters = df.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
top_emitters_data = df[df['country'].isin(top_emitters)]
# 再生可能エネルギーシェアと温室効果ガス排出量の関係をプロット
fig = px.scatter(top_emitters_data, x='renewable_share', y='greenhouse_gas_emissions',
color='country', title="上位排出国における再生可能エネルギーの排出量への影響")
fig.show()
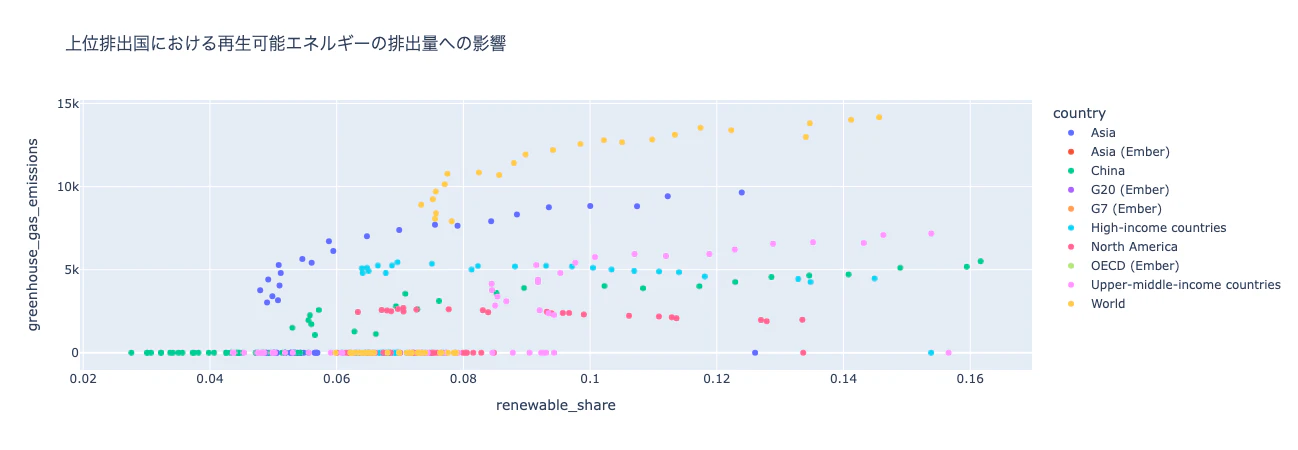
洞察: 国が再生可能エネルギーを多く使用するほど、温室効果ガスの排出量も増加し、総エネルギー消費量が再生可能エネルギー消費量よりも速く増加します。北アメリカは例外で、再生可能エネルギーの割合が増加するにつれて温室効果ガスの排出量は年間を通じて比較的一定のままでした。
モデルが予測した世界のエネルギー消費量
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
# 年ごとの世界の一次エネルギー消費量を集計
global_energy = df[df['country'] == 'World'].groupby('year')['primary_energy_consumption'].sum()
# 予測のためのARIMAモデルを構築
model = ARIMA(global_energy, order=(1, 1, 1))
model_fit = model.fit()
forecast = model_fit.forecast(steps=10) # 10年間の予測
# 過去のエネルギー消費量と予測値をプロット
plt.plot(global_energy, label='Historical')
plt.plot(range(global_energy.index[-1] + 1, global_energy.index[-1] + 11), forecast, label='Forecast')
plt.xlabel("Year")
plt.ylabel("Primary Energy Consumption")
plt.title("Projected Global Energy Consumption")
plt.legend()
plt.show()
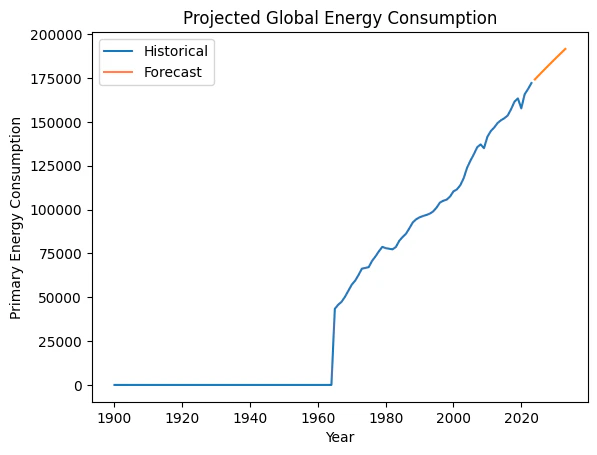
洞察: このモデルは、世界のエネルギー消費量が今後も増加し続けると予測しています。
次のステップ
データセットに対して初期の探索的データ分析を行ったので、次のステップを試してみてください:
- このノートブックのAppendixセクションで追加のEDA可視化例を参照してください。
- このチュートリアルを進める際にエラーが発生した場合は、組み込みのデバッガーを使用してコードをステップ実行してみてください。ノートブックのデバッグ方法については、以下を参照してください (AWS | Azure | GCP)。
- ノートブックをチームと共有して、分析内容を理解してもらいましょう。付与する権限に応じて、チームメンバーが分析を進めるためのコードを開発したり、さらなる調査のためのコメントや提案を追加したりすることができます。ノートブックの共有方法については、以下を参照してください (AWS | Azure | GCP)。
- 分析が完了したら、主要な可視化を含むノートブックダッシュボードを作成して、ステークホルダーと共有しましょう (AWS | Azure | GCP)。または、AI/BIダッシュボードを作成して共有することもできます (AWS | Azure | GCP)。
付録: EDA可視化の追加の例
エネルギー消費量が多い上位20か国をランク付け
# 国ごとにグループ化し、一次エネルギー消費量の合計を計算
energy_ranking = df.groupby('country')['primary_energy_consumption'].sum().sort_values(ascending=False)
# エネルギー消費量が多い上位20か国を表示
display(energy_ranking.head(20))
country
World 6197106.982
Non-OPEC (EIA) 5052815.719
High-income countries 3389649.472
OECD (EI) 3282817.155
Non-OECD (EI) 2914289.793
OECD (EIA) 2728025.856
Non-OECD (EIA) 2605829.267
Asia 2225982.180
Upper-middle-income countries 2090189.327
Asia Pacific (EI) 1919272.563
Europe 1798407.409
Asia & Oceania (EIA) 1726397.338
North America 1651620.139
North America (EI) 1621734.299
United States 1353940.248
Europe (EI) 1291118.177
Europe (EIA) 992879.247
European Union (27) 960543.284
China 922517.262
CIS (EI) 625926.089
Name: primary_energy_consumption, dtype: float64
洞察: 出力には国ではない地理的地域が含まれています。代わりに、このチュートリアルの他の可視化で行うように、地域ごとにデータをフィルタリングすることができます。しかし、この出力は依然として有用な洞察を提供します。例えば、アメリカ合衆国は欧州連合全体よりも多くのエネルギーを消費しました。
再生可能エネルギーの上位20か国をランク付け
# 再生可能エネルギーの割合を計算し、新しい列「renewable_share」として保存
df['renewable_share'] = df['renewables_consumption'] / df['primary_energy_consumption']
# 国ごとにグループ化し、平均再生可能エネルギー割合でランク付け
renewable_ranking = df.groupby('country')['renewable_share'].mean().sort_values(ascending=False)
# 再生可能エネルギーで上位20か国
display(renewable_ranking.head(20))
country
Norway 0.683420
Iceland 0.627102
New Zealand 0.395323
Brazil 0.392034
Sweden 0.347037
Switzerland 0.318432
Middle Africa (EI) 0.305156
Austria 0.295875
Eastern Africa (EI) 0.290730
Canada 0.284777
South America 0.281878
Peru 0.258032
Colombia 0.255221
South and Central America (EI) 0.254094
Central America (EI) 0.227808
Chile 0.220372
Croatia 0.206550
Portugal 0.204459
Latvia 0.196490
Finland 0.194696
Name: renewable_share, dtype: float64
洞察: この分析から、ノルウェーとアイスランドが再生可能エネルギーの消費において世界をリードしており、消費の半分以上が再生可能エネルギーから来ていることがわかります。
所得別の一人当たり消費量のチャート
# 所得グループでフィルタリング
income_groups = ['Low-income countries', 'High-income countries', 'Upper-middle-income countries']
# 各グループの一人当たりエネルギー消費量を計算
df['energy_per_capita'] = df['primary_energy_consumption'] / df['population']
# 国ごとにグループ化し、各所得グループの平均一人当たりエネルギー消費量を計算
income_group_comparison = df[df['country'].isin(income_groups)].groupby('country')['energy_per_capita'].mean()
# 比較をプロット
fig = px.bar(income_group_comparison, title="Energy Consumption per Capita by Income Group")
fig.show()
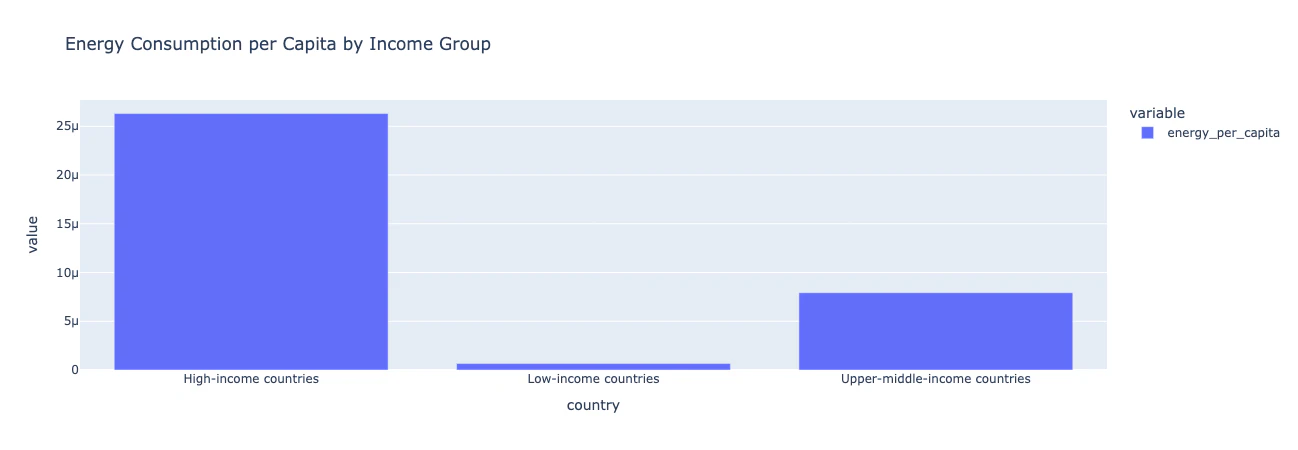
洞察: エネルギー消費は高所得国で高く、低所得国でははるかに低い。
地域別の一人当たりエネルギー消費量の計算とチャート
# 地域を定義し、各地域の一人当たりの総エネルギー消費量を計算
regions = ['Africa', 'Asia', 'Europe', 'North America', 'South America', 'Oceania']
df['energy_per_capita'] = df['primary_energy_consumption'] / df['population']
regional_energy = df[df['country'].isin(regions)].groupby('country')['energy_per_capita'].mean()
# 地域ごとの一人当たりのエネルギー消費量をプロット
fig = px.bar(regional_energy, title="Energy Consumption per Capita by Region")
fig.show()

洞察: 北アメリカは一人当たりのエネルギー消費量が最も多い。アフリカとアジアは一人当たりのエネルギー消費量が最も少ない。アジアは温室効果ガスの排出量が最も多いにもかかわらず、一人当たりのエネルギー消費量は最も低い。この相関関係はさらに調査する価値があるかもしれない。
時間経過による世界の一人当たりエネルギー消費量のプロット
# 一人当たりのエネルギー消費量を計算
df['energy_per_capita'] = df['primary_energy_consumption'] / df['population']
# 世界全体の一人当たりエネルギー消費量を時系列でプロット
global_energy_per_capita = df[df['country'] == 'World']
global_energy_per_capita_filtered = global_energy_per_capita[(global_energy_per_capita['year'] >= 1966) & (global_energy_per_capita['year'] <= 2022)]
fig = px.line(global_energy_per_capita_filtered, x='year', y='energy_per_capita',
title="Global Energy Consumption per Capita Over Time")
fig.show()

洞察: 一般的に、一人当たりのエネルギー消費量は時間とともに増加する傾向があります。60年代と70年代、および2000年代初頭に大きな増加が見られます。
散布図: エネルギー消費量の増加 vs. GDPの増加
# エネルギー消費量とGDPの前年比成長率を計算
df['energy_growth'] = df.groupby('country')['primary_energy_consumption'].pct_change()
df['gdp_growth'] = df.groupby('country')['gdp'].pct_change()
# 無限大とNaNの値を除外
df.replace([np.inf, -np.inf], np.nan, inplace=True)
df.dropna(subset=['energy_growth', 'gdp_growth'], inplace=True)
# エネルギー消費量の成長率とGDPの成長率をプロット
fig = px.scatter(df, x='energy_growth', y='gdp_growth', color='country',
title="Energy Consumption Growth vs. GDP Growth")
fig.show()
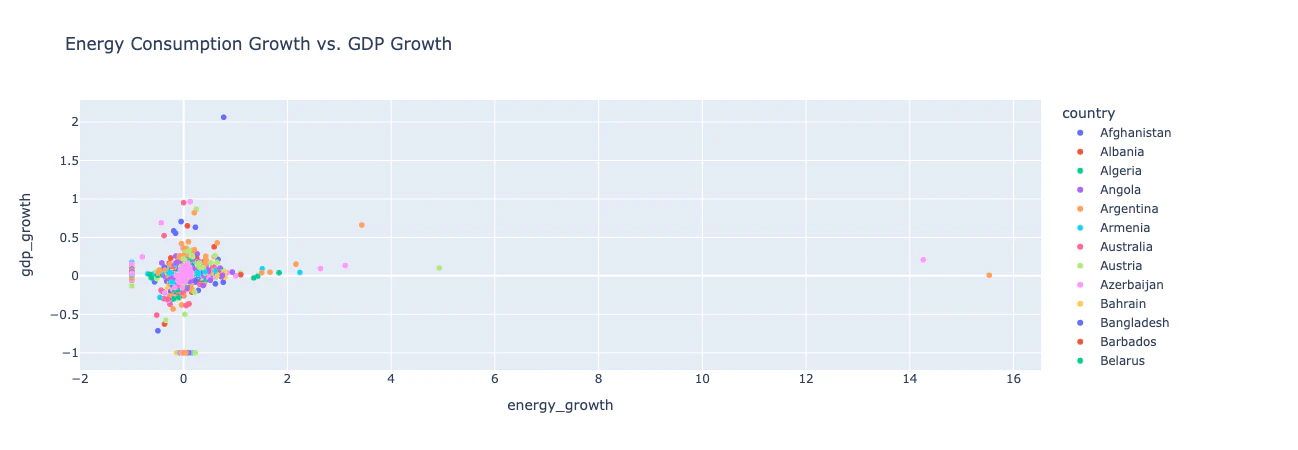
洞察: 興味深い外れ値がいくつかあります。
- クウェートは、エネルギー消費の小さな増加で大きなGDP成長を遂げました。
- オマーンと赤道ギニアは、GDPの小さな成長でエネルギー消費の大きな成長を見せました。
これらの外れ値をさらに調査し、これらの国で何が起こっていたのかを理解することは興味深いでしょう。
散布図: 人口増加 vs. エネルギー消費増加
# 人口成長率を計算
df['population_growth'] = df.groupby('country')['population'].pct_change()
# 無限大とNaNの値を除外
df.dropna(subset=['population_growth', 'energy_growth'], inplace=True)
# 人口成長率とエネルギー消費量の成長率をプロット
fig = px.scatter(df, x='population_growth', y='energy_growth', color='country',
title="Population Growth vs. Energy Consumption Growth")
fig.show()

洞察: 一般的に、人口増加はエネルギー消費に大きな影響を与えません。しかし、赤道ギニアとオマーンは、比較的小さな人口増加でエネルギー消費が大幅に増加した年がありました。
主要経済国のエネルギー強度の推移をプロット
# GDPが最も高い5カ国を取得
top_economies = df.groupby('country')['gdp'].sum().nlargest(5).index
# エネルギー強度を計算(GDPあたりの一次エネルギー消費量)
df['energy_intensity'] = df['primary_energy_consumption'] / df['gdp']
# 主要経済国のエネルギー強度の平均を時系列で計算
intensity_ranking = df[df['country'].isin(top_economies)].groupby(['year', 'country'])['energy_intensity'].mean().reset_index()
# 主要経済国のエネルギー強度の推移をプロット
fig = px.line(intensity_ranking, x='year', y='energy_intensity', color='country',
title="Energy Intensity Over Time for Top Economies")
fig.show()
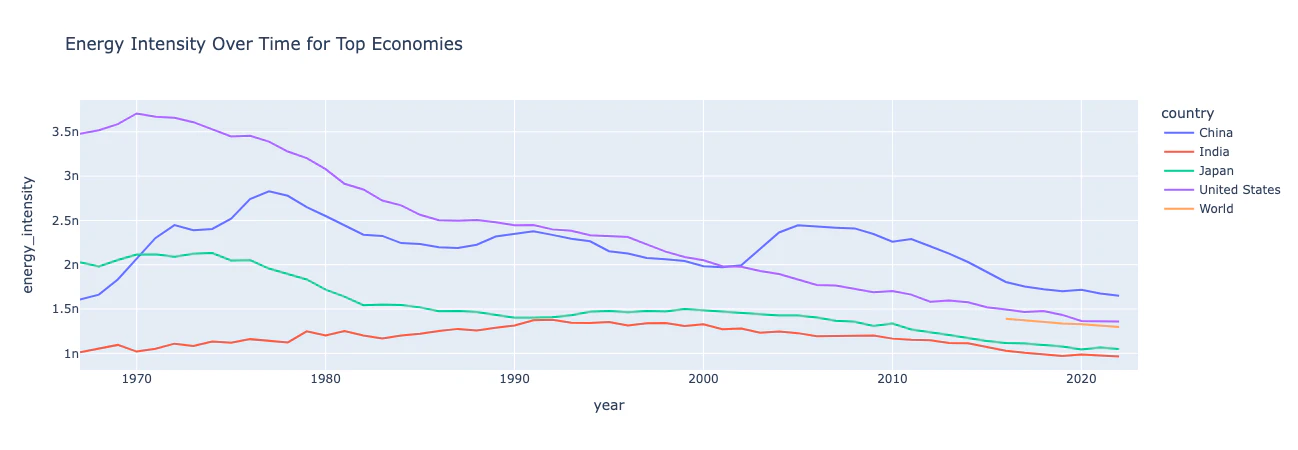
洞察: 一般的に、主要経済国のエネルギー強度は時間とともに低下しました。世界全体のデータは約2015年以前は欠落しています。