こちらのノートブックをウォークスルーした内容となっています。
ノートブックの日本語訳はこちらにあります。
Delta Lake: Apache Spark™とビッグデータワークロードにACIDトランザクションを提供するオープンソースストレージフォーマット
これは、いくつかのDelta Lakeの機能を説明する入門ノートブックです。
- オープンフォーマット: blobストレージ上のParquetフォーマットとして格納されます。
- ACIDトランザクション: 複雑かつ同時実行されるデータパイプラインでデータの完全性と読み取りの一貫性を保証します。
- スキーマ強制、スキーマ進化: 予期しない書き込みをブロックすることでデータの綺麗さを保持します。
- 監査履歴: テーブルに生じた全てのオペレーションの履歴。
- タイムトラベル: 時間あるいはバージョン番号による以前のバージョンのテーブルへのクエリー。
- deleteとupsert: プログラミングAPIによるテーブルのdeleteとupsert(update + insert)のサポート。
- スケーラブルなメタデータ管理: Sparkを用いることでメタデータのオペレーションをスケールさせ、数百万のファイルを取り扱うことができます。
- バッチ、ストリーミングソース、ストリーミングシンクの統合: Delta Lakeのテーブルはバッチテーブルでもあり、ストリーミングのソースとシンクでもあります。ストリーミングデータの取り込み、バッチによる過去のバックフィル、インタラクティブなクエリーすべてをすぐに活用することができます。
このノートブックはSAIS EU 2019 Delta Lake Tutorialの修正バージョンです。使用データは、Lending Clubの公開データの修正バージョンです。2012年から2017年の間にファンディングされた全てのローンが含まれています。それぞれのローンには、申請者の情報、現在のローンのステータス(Current, Late, Fully Paid, etc.)、最新の支払い情報が含まれています。データの完全なビューに関しては、こちらのデータ辞書を参照してください。
Delta Lakeテーブルへのデータのロード
最初にデータを読み込み、Delta Lakeテーブルとして保存しましょう。
import re
from pyspark.sql.types import *
# Username を取得
username_raw = dbutils.notebook.entry_point.getDbutils().notebook().getContext().tags().apply('user')
# Username の英数字以外を除去し、全て小文字化
username = re.sub('[^A-Za-z0-9]+', '', username_raw).lower()
# ファイル格納パス
work_path = f"dbfs:/tmp/databricks_handson/{username}/delta_introduction"
# パスを表示
print(f"path_name: {work_path}")
spark.sql("set spark.sql.shuffle.partitions = 1")
# 読み込むデータ
sourcePath = "/databricks-datasets/learning-spark-v2/loans/loan-risks.snappy.parquet"
# Delta Lakeのパスの設定
deltaPath = f"{work_path}/loans_delta"
# フォルダーが存在する場合には削除
dbutils.fs.rm(deltaPath, recurse=True)
# 同じローンデータを用いたDeltaテーブルの作成
(spark.read.format("parquet").load(sourcePath)
.write.format("delta").save(deltaPath))
spark.read.format("delta").load(deltaPath).createOrReplaceTempView("loans_delta")
print("Defined view 'loans_delta'")
データの探索
データを探索してみましょう。
spark.sql("SELECT count(*) FROM loans_delta").show()

display(spark.sql("SELECT * FROM loans_delta LIMIT 5"))

マジックコマンド%sqlを用いても同様の処理が可能です。
%sql
SELECT * FROM loans_delta LIMIT 5

Delta Lakeテーブルへのデータストリームのロード
Deltaテーブルを作成することのメリットの一つに、「バッチデータ処理だけでなくストリーミング処理」でも利用できるというものがあります。具体的にはストリーミングのソースやシンクとしてDeltaテーブルを使用することができます。
ここでは、ランダムに生成されるローンIDと金額によるデータストリームを作成します。さらに、有用なユーティリティ関数をいくつか定義します。
import random
import os
from pyspark.sql.functions import *
from pyspark.sql.types import *
def random_checkpoint_dir():
return f"{work_path}/tmp/chkpt/%s" % str(random.randint(0, 10000))
# 州をランダムに生成するユーザー定義関数
states = ["CA", "TX", "NY", "WA"]
@udf(returnType=StringType())
def random_state():
return str(random.choice(states))
# ランダムに生成されたデータのストリームによるストリーミングクエリーを起動し、Deltaテーブルにデータを追加する関数
def generate_and_append_data_stream():
newLoanStreamDF = (spark.readStream.format("rate").option("rowsPerSecond", 5).load()
.withColumn("loan_id", 10000 + col("value"))
.withColumn("funded_amnt", (rand() * 5000 + 5000).cast("integer"))
.withColumn("paid_amnt", col("funded_amnt") - (rand() * 2000))
.withColumn("addr_state", random_state())
.select("loan_id", "funded_amnt", "paid_amnt", "addr_state"))
checkpointDir = f"{work_path}/chkpt"
streamingQuery = (newLoanStreamDF.writeStream
.format("delta")
.option("checkpointLocation", checkpointDir)
.trigger(processingTime = "10 seconds")
.start(deltaPath))
return streamingQuery
# 全てのストリーミングクエリーを停止する関数
def stop_all_streams():
# 全てのストリームを停止
print("Stopping all streams")
for s in spark.streams.active:
s.stop()
print("Stopped all streams")
print("Deleting checkpoints")
dbutils.fs.rm(f"{work_path}/chkpt", True)
print("Deleted checkpoints")
以下のコマンドを実行してストリームを起動します。
streamingQuery = generate_and_append_data_stream()
ストリーミングクエリーが起動すると専用のダッシュボードが表示されます。こちらのダッシュボードを用いることで、リアルタイムにストリーミングの流量などを確認することができます。
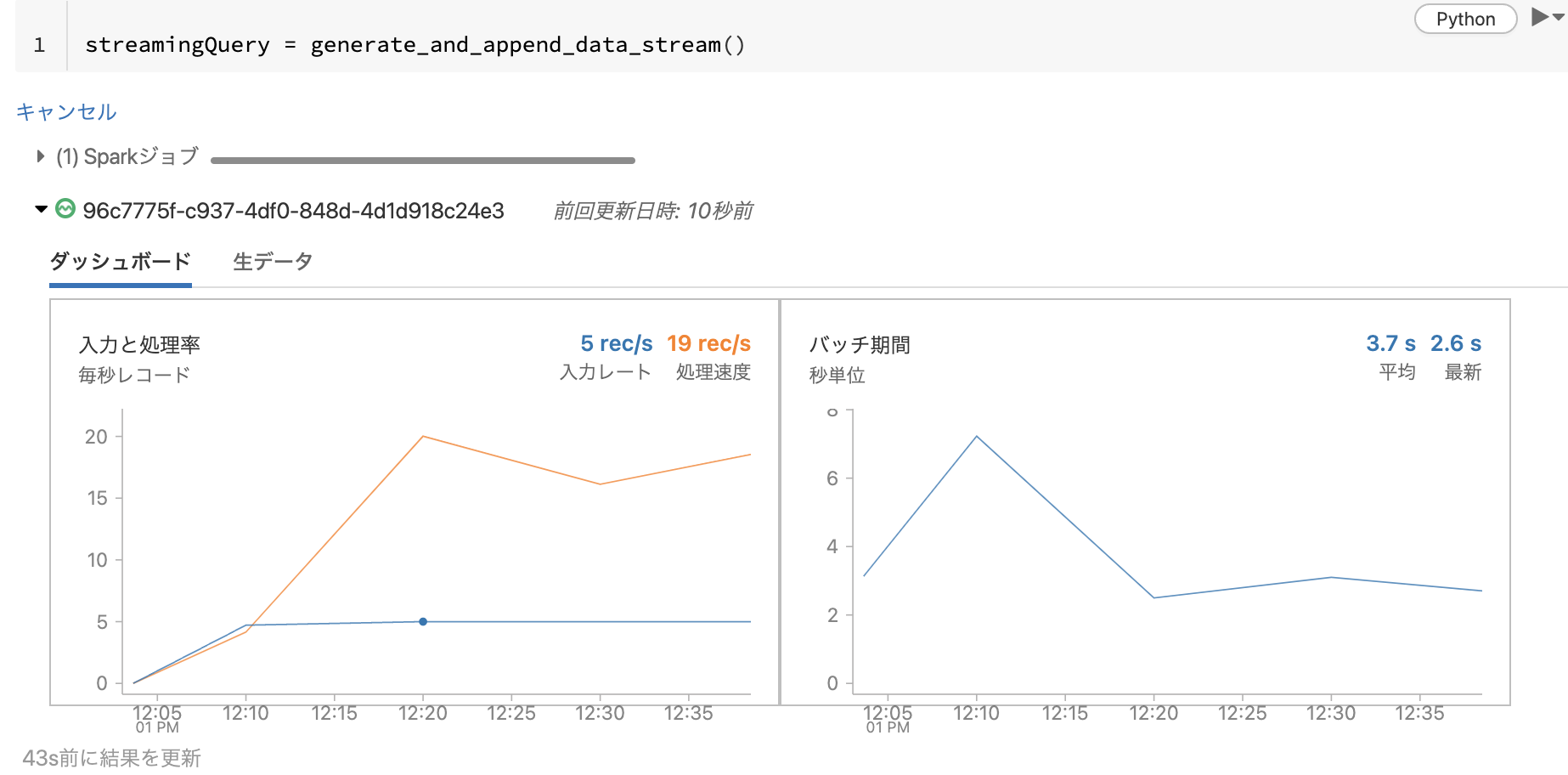
このケースでは、Deltaテーブルがストリーミングのシンクになっています。通常のテーブルと同様にテーブルに対してクエリーを実行することができます。
テーブルのレコード数をカウントすることで、ストリーミングクエリーがテーブルにデータが追加されていることを確認することができます。以下のセルを複数回実行してください。実行の都度カウントアップしていく様子を確認することができます。
display(spark.sql("SELECT count(*) FROM loans_delta"))
処理が不要になったら、全てのストリーミングクエリーを停止することを忘れないでください。
重要!
ストリーミング処理は明示的に停止しない限り処理を続行します。クラスターの自動停止も効かないのでコスト増に注意してください。
stop_all_streams()
データ破損を防ぐために書き込み時のスキーマを強制
ローンが停止されたかどうかを示す追加のカラムclosedを含むデータを書き込むことで、この機能をテストしてみましょう。このカラムはテーブルには存在しないことに注意してください。
cols = ['loan_id', 'funded_amnt', 'paid_amnt', 'addr_state', 'closed']
items = [
(1111111, 1000, 1000.0, 'TX', True),
(2222222, 2000, 0.0, 'CA', False)
]
from pyspark.sql.functions import *
loanUpdates = (spark
.createDataFrame(items, cols)
.withColumn("funded_amnt", col("funded_amnt").cast("int")))
# 以下の行のコメントを解除して実行ししてください。エラーになるはずです。
loanUpdates.write.format("delta").mode("append").save(deltaPath)
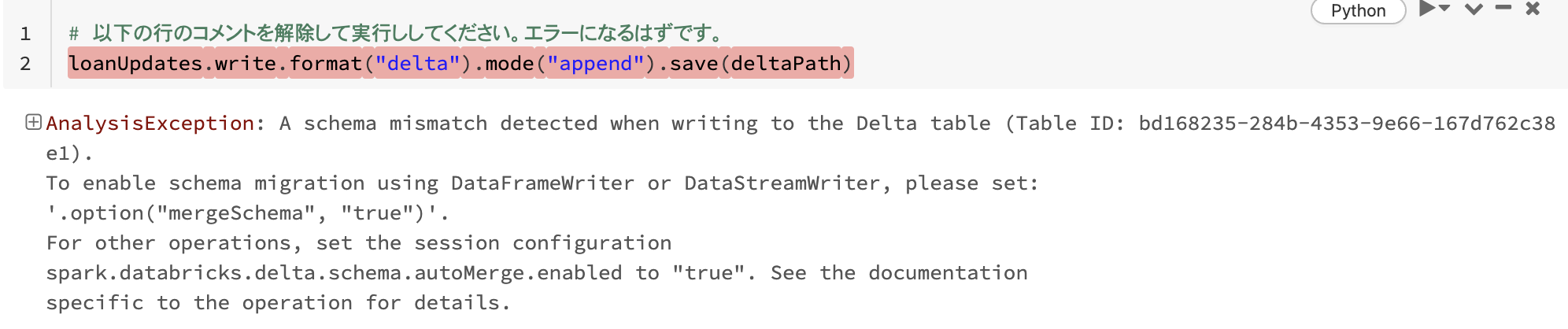
変化するデータに対応するためにスキーマを進化
スキーマ強制は意図しないスキーマの汚染を防御するためのものですが、ビジネス要件の変化に合わせて明示的にスキーマを変更しなくてはならないケースがあります。この場合、オプションmergeSchemaにtrueを設定します。
(loanUpdates.write.format("delta").mode("append")
.option("mergeSchema", "true")
.save(deltaPath))
スキーマを確認するために再度テーブルにクエリーを実行してみましょう。
display(spark.read.format("delta").load(deltaPath).filter("loan_id = 1111111"))

既存のレコードを読み込んだ際、新規のカラムはNULLと見做されます。
display(spark.read.format("delta").load(deltaPath))

既存データの変換
既存データをどのように変換できるのかをみていきましょう。でも最初に、スキーマが変化したのでビューが変更に追従できるように、ビューを再定義することでテーブルに対するビューを更新しましょう。
spark.read.format("delta").load(deltaPath).createOrReplaceTempView("loans_delta")
print("Defined view 'loans_delta'")
エラーを修正するためにローンデータを更新
- データをレビューしてみると、
addr_state = 'OR'に割り当てられた全てのローンはaddr_state = 'WA'に割り当てられるべきであることがわかりました。 - Parquetで
updateを行うには以下のことが必要となります。- 更新されない全ての行を新規テーブルにコピー
- 更新される全ての行をデータフレームにコピーし、データを更新
- 新規テーブルに上述のデータフレームをinsert
- 古いテーブルを削除
- 新規テーブルの名称を古いものに更新
Deltaテーブルであれば、通常のテーブル同様にUPDATEを行うことができます。
display(spark.sql("""SELECT addr_state, count(1) FROM loans_delta WHERE addr_state IN ('OR', 'WA', 'CA', 'TX', 'NY') GROUP BY addr_state"""))

データを修正しましょう。
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, deltaPath)
deltaTable.update("addr_state = 'OR'", {"addr_state": "'WA'"})
もう一度データを確認しましょう。
display(spark.sql("""SELECT addr_state, count(1) FROM loans_delta WHERE addr_state IN ('OR', 'WA', 'CA', 'TX', 'NY') GROUP BY addr_state"""))
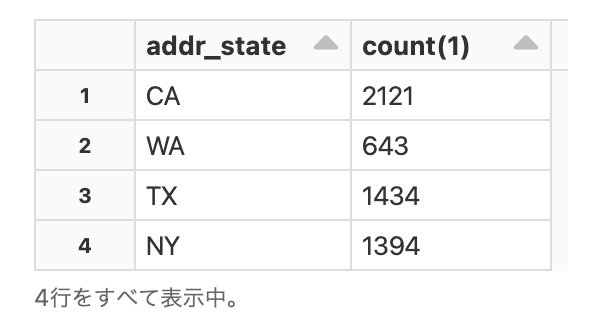
データが更新されていることがわかります。
General Data Protection Regulation (GDPR)に基づいてテーブルからユーザーデータを削除
Delta Lakeテーブルから述語にマッチするデータを削除することができます。ここでは、完済したローンすべてを削除したいものとします。最初にどれだけレコードがあるのかを確認しましょう。
display(spark.sql("SELECT COUNT(*) FROM loans_delta WHERE funded_amnt = paid_amnt"))

Parquetの場合、部分的な削除ができないためデータの総入れ替えを行わなくてはなりませんが、Deltaであればこれも通常のテーブル同様にDELETEを行うことができます。
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, deltaPath)
deltaTable.delete("funded_amnt = paid_amnt")
完済したローンの数をチェックしてみます。
display(spark.sql("SELECT COUNT(*) FROM loans_delta WHERE funded_amnt = paid_amnt"))

問題なく削除できていることがわかります。
mergeを用いた変更データのテーブルへのupsert
一般的なユースケースは、あるOLAPテーブルでなされた行の変更を、OLAPワークロードの別のテーブルに複製するチェンジデータキャプチャ(CDC)です。ここでのローンデータのサンプルで使ってみるために、新たなローンや既存のローンに対する更新情報を含む別のテーブルがあるものとします。さらに、この変更テーブルはloan_deltaテーブルと同じスキーマとなっています。SQLコマンドMERGEをベースとしたDeltaTable.merge()を用いることで、これらの変更をテーブルにupsertすることができます。
display(spark.sql("select * from loans_delta where addr_state = 'NY' and loan_id < 30"))

このデータにはいくつかの変更があり、ある1つのローンは完済され、別の新たなローンが追加されたものとします。
cols = ['loan_id', 'funded_amnt', 'paid_amnt', 'addr_state', 'closed']
items = [
(11, 1000, 1000.0, 'NY', True), # ローンの完済
(12, 1000, 0.0, 'NY', False) # 新たなローン
]
loanUpdates = spark.createDataFrame(items, cols)
次に、mergeオペレーションを用いて変更データでテーブルを更新しましょう。
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, deltaPath)
(deltaTable
.alias("t")
.merge(loanUpdates.alias("s"), "t.loan_id = s.loan_id")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute())
テーブルが更新されたことを確認しましょう。
display(spark.sql("select * from loans_delta where addr_state = 'NY' and loan_id < 30"))

loan_idを用いて照合が行われ、行が存在する場合には更新され、存在しない場合にはインサートされていることがわかります。
オペレーション履歴を用いたデータ変更の監査
ここまで行なったDeltaテーブルに対する全ての変更は、テーブルのトランザクションログのコミットとして記録されます。Deltaテーブルやディレクトリに書き込みを行うと、全てのオペレーションは自動的にバージョン管理されます。テーブルの履歴を参照するためにHISTORYコマンドを使用することができます。
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, deltaPath)
display(deltaTable.history())
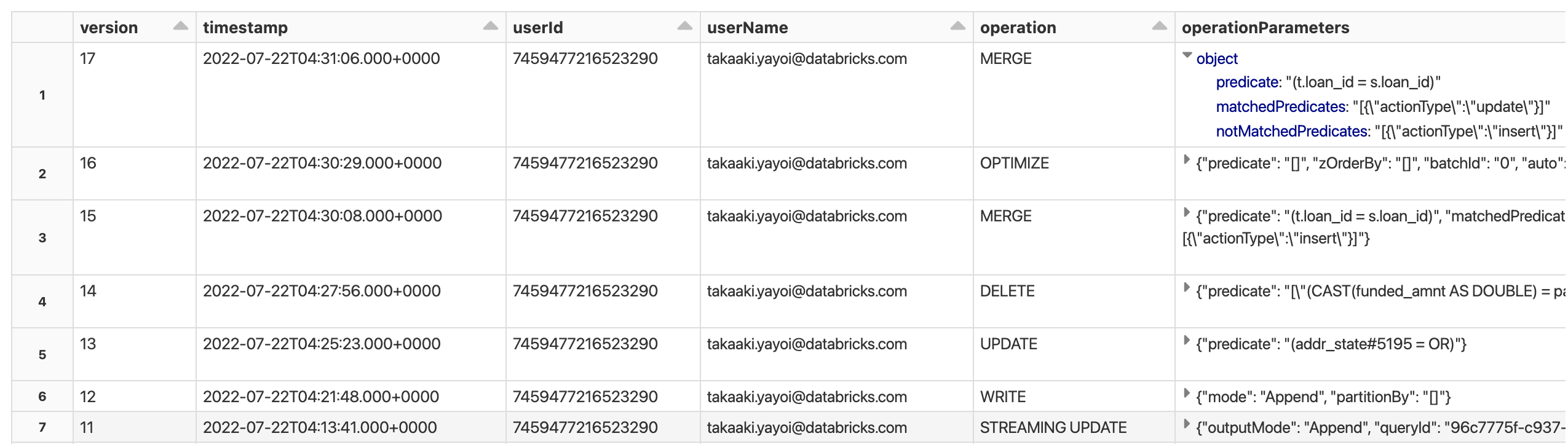
誰がいつどのような操作を行ったのかが記録されるので、監査ログとして用いることも可能です。
履歴に対してクエリーを実行することもできます。
display(deltaTable.history(4).select("version", "timestamp", "operation", "operationParameters"))

タイムトラベルを用いたテーブルの過去のスナップショットへのクエリー
Delta Lakeのタイムトラベル機能を用いることで、テーブルの以前のバージョンにアクセスすることができます。この機能を活用できるユースケースには以下のようなものがあります。
- データ変更の監査
- 実験 & レポートの再現
- ロールバック
Python、Scala、SQL文法を用いてタイムスタンプ、バージョン番号を用いてクエリーを行うことができます。この例では、Python文法を用いて特定のバージョンにクエリーを行います。
詳細に関しては、Introducing Delta Time Travel for Large Scale Data Lakesやドキュメントをご覧ください。
完済ローンを含んでいるデータの削除を行う前のテーブルをクエリーしてみましょう。
previousVersion = deltaTable.history(1).select("version").first()[0] - 3
(spark.read.format("delta")
.option("versionAsOf", previousVersion)
.load(deltaPath)
.createOrReplaceTempView("loans_delta_pre_delete"))
display(spark.sql("SELECT COUNT(*) FROM loans_delta_pre_delete WHERE funded_amnt = paid_amnt"))
削除前にはあった完済ローンと同じ数を確認することができましたので、削除前の状態を参照していることがわかります。
このように、オブジェクトストレージ上のデータをDelta Lakeで管理し、Sparkでアクセすることで、データレイク上のデータの品質を保つためのさまざまな機能を活用できるようになります。