Productionizing Machine Learning with Delta Lake - Databricks Blogの翻訳です。
Databricksで一連のノートブックをトライしてみてください。
多くのデータサイエンティストにとって、機械学習モデルの構築、チューニングのプロセスは、毎日の作業のほんの一部です。彼らの時間の多くは、ETLの実施、データパイプラインの構築、モデルの本格運用への投入を行うための魅力的ではない(しかし、重要な)作業に費やされています。
この記事では、ステップバイステップで本格運用のデータサイエンスパイプラインの構築手順をウォークスルーします。途中では、データサイエンス、データエンジニアリング、プロダクションワークフローを統合するツール、機能を提供するDelta Lakeがなぜ機械学習のライフサイクルに対する理想的なプラットフォームであるのかを説明します。提供機能には以下のようなものが含まれます。
- 新規データフローを継続的に処理するテーブル 履歴データ、リアルタイムストリーミングソース両方に対応することで、データサイエンスプロダクションパイプラインを劇的にシンプルにします。
- スキーマ強制 カラム汚染を避けテーブルをきれいな状態に保つことができ、機械学習にすぐに活用できます。
- スキーマエボリューション プロダクションで使用されているテーブルであっても、破損させることなしに既存テーブルに対して新規カラムを追加できます。
- タイムトラベル、データバージョン管理 Delta Lakeテーブルに対する変更の監査、再現を可能にし、ユーザーエラーによる意図しない変更などが起きた場合、必要に応じてロールバックすることができます。
- MLflowとのインテグレーション エクスペリメントで用いたパラメーター、結果、モデルやプロットを自動で記録することでエクスペリメントのトラッキングと再現を可能にします。
Delta Lakeのこれらの機能によって、データエンジニアやデータサイエンティストは信頼性が高く、回復力の強い、自動化されたデータパイプラインや機械学習モデルをこれまで以上に高速に設計できるようになります。
Delta Lakeによる機械学習データパイプラインの構築
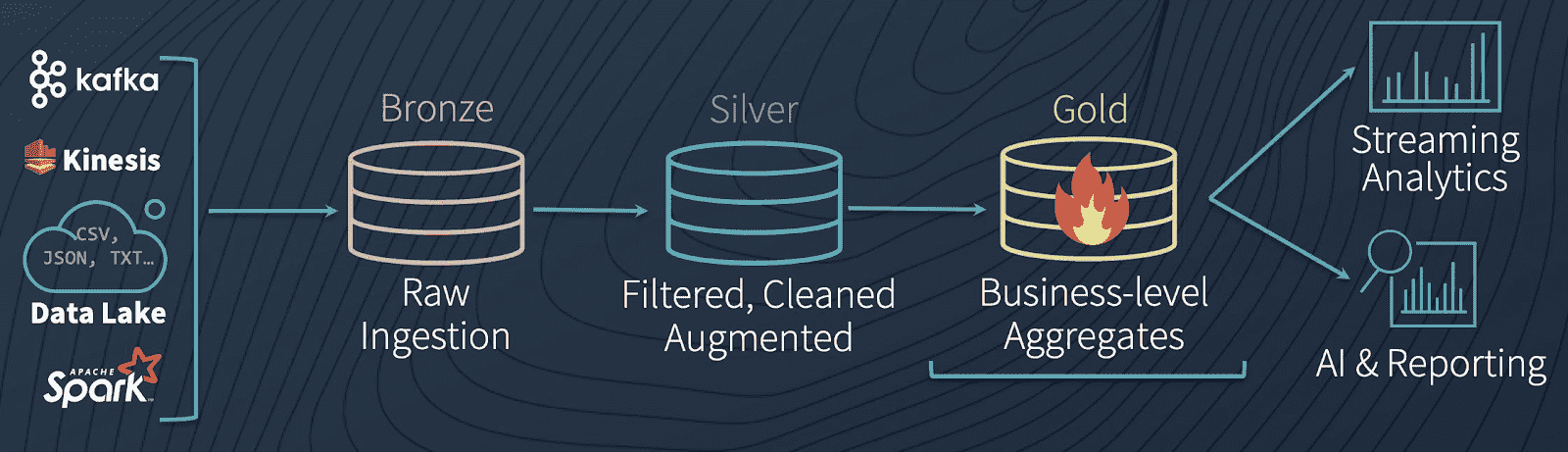
マルチホップアーキテクチャ
一般的なアーキテクチャにおいては、データエンジニアリングパイプラインにおいて異なる品質レベルに対応するテーブルを使用し、徐々にデータに対して構造を追加していきます。データ取り込み("ブロンズ"テーブル)、変換/特徴量エンジニアリング("シルバー"テーブル)、機械学習トレーニング/予測("ゴールド"テーブル)から構成されます。これらを合わせて、我々はこれを"マルチホップ"アーキテクチャと呼んでいます。これによって、データエンジニアは生データから以降のすべてが流れることになる**"信頼できる唯一の情報源(single source of truth)"**からスタートするパイプラインを構築することができます。後段のユーザーがデータを整形したり、文脈固有の構造を導入したとしても、ビジネスレベルの集計テーブルが背後のデータを反映し続けるように、以降の変換と集約処理は再計算され検証されます。
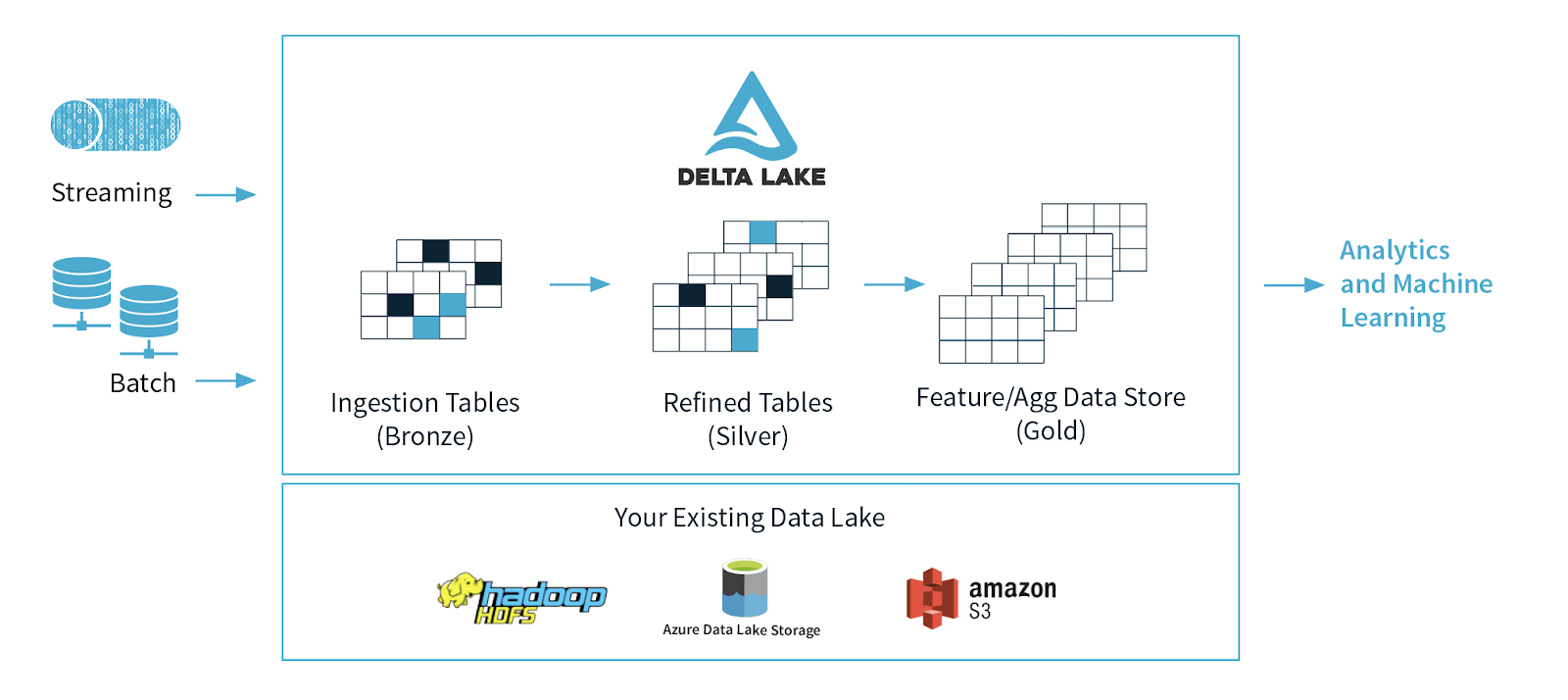
どのようにDelta Lakeのパイプラインが動作するのかを理解するために(追加のサンプルを説明させていただけるのであれば)、データを水に例えるアナロジーにディープダイブすることには価値があります。複数ステージのパイプラインを通じてデータを移動するために、異なる一連のバッチジョブをスケジューリングするのではなく、Delta Lakeにおいては、リアルタイムでシームレスかつ定常的にデータを水のように流すことが可能となります。
ブロンズテーブルは、継続的に大量の水(データ)が流れ込む典型的なレイクとして動作します。到着した際には、異なるデータソース(いくつかはきれいではありません)からやってきているため汚い状態となっています。ここから、データはレイクにつながる川のように定常的かつ急激な流れとしてシルバーテーブルに流れ込みます。水(ここではデータ)は下流に流れていき、流れの蛇行によってきれいにフィルタリングされていき、より純粋なものになっていきます。下流の水処理プラント(ゴールドテーブル)に到着するまでには、消費できるように最終的な浄化と厳格なテストが行われます。これは、最終消費者(このケースではMLアルゴリズム)は非常にえり好みをし、汚染された水を許容しないためです。最後に、浄化プラントから、全ての下流の消費者(MLアルゴリズム、BIアナリスト)の水道管に接続され、もっとも純粋な状態で消費される準備が整います。
機械学習におけるデータの準備の最初のステップは、データを捕捉し生の状態で保持するブロンズテーブルの作成です。これからどのようにしてそれを行うのかを見ていきますが、なぜ皆様がお使いのデータレイクに対してDelta Lakeが明確な選択肢となっているのかを説明させてください。
データレイクのジレンマ
最近我々が見る最も一般的なパターンは、企業がAzure Event HubsやAWS Kinesisを用いてリアルタイムストリーミングデータ(ウェブサイトにおける顧客のクリックストリームなど)をBlogストレージやS3バケットのように安価かつ豊富なクラウドストレージに収集するというものです。多くのケースで企業は、過去と現在の完全な絵を得るために、このリアルタイムストリーミングデータを履歴データ(顧客の過去の購買履歴など)で補完したいと考えます。
結果として、企業は様々なデータソースから収集した大量の生、非構造化データを汚いままの状態でレイクに抱えることになります。信頼性を持って履歴データとリアルタイムストリーミングデータを組み合わせ、機械学習モデルに提供できるように構造を付与する方法なしには、これらのデータレイクはすぐに複雑かつ整理されていないゴミの山にになってしまいます。これには「データスワンプ」という名前までもつけられています。
単一のデータポイントを変換し分析する前に、データエンジニアはすでに最初のジレンマに遭遇します。履歴(バッチ)データとリアルタイムのストリーミングデータをどのように統合すればいいのでしょうか。伝統的には、このギャップを埋めるためにラムダアーキテクチャが用いられる場合がありますが、ラムダの複雑性から生じる問題、データの損失、破損を起こす傾向に直面することになります。
Delta Lakeのソリューション: 過去と現在を一つのテーブルに統合
「データレイクのジレンマ」に対するソリューションはDelta Lakeを活用することです。Delta Lakeはお使いのデータレイク上で稼働するオープンソースストレージレイヤーです。これは分散コンピューティング向けに設計されており、Apache Sparkとの100%の互換性があるので、以下に示すようにお好きな Spark APIを用いて、あらゆるフォーマット(CSV、Parquetなど)の既存のデータテーブルを簡単に変換することができ、Delta Lakeフォーマットでブロンズテーブルを保存することができます。
# Read loanstats_2012_2017.parquet
loan_stats_ce = spark.read.parquet(PARQUET_FILE_PATH)
# Save table as Delta Lake
loan_stats_ce.write.format("delta").mode("overwrite").save(DELTALAKE_FILE_PATH)
# Re-read as Delta Lake
loan_stats = spark.read.format("delta").load(DELTALAKE_FILE_PATH)
生データに対するブロンズテーブルを構築し、既存テーブルをDelta Lakeフォーマットに変換することで、データエンジニアの最初のジレンマ、過去と現在のデータの統合を解決したことになります。でも、どうやって?Delta Lakeテーブルは履歴データとリアルタイムストリーミングソースの両方をシームレスに取り扱うことができます。ここでは、Sparkを使用しているので、異なるストリーミングデータ入力フォーマットとKafka、Cassandraなどのソースシステムとほぼ完全な互換性を持つことができます。
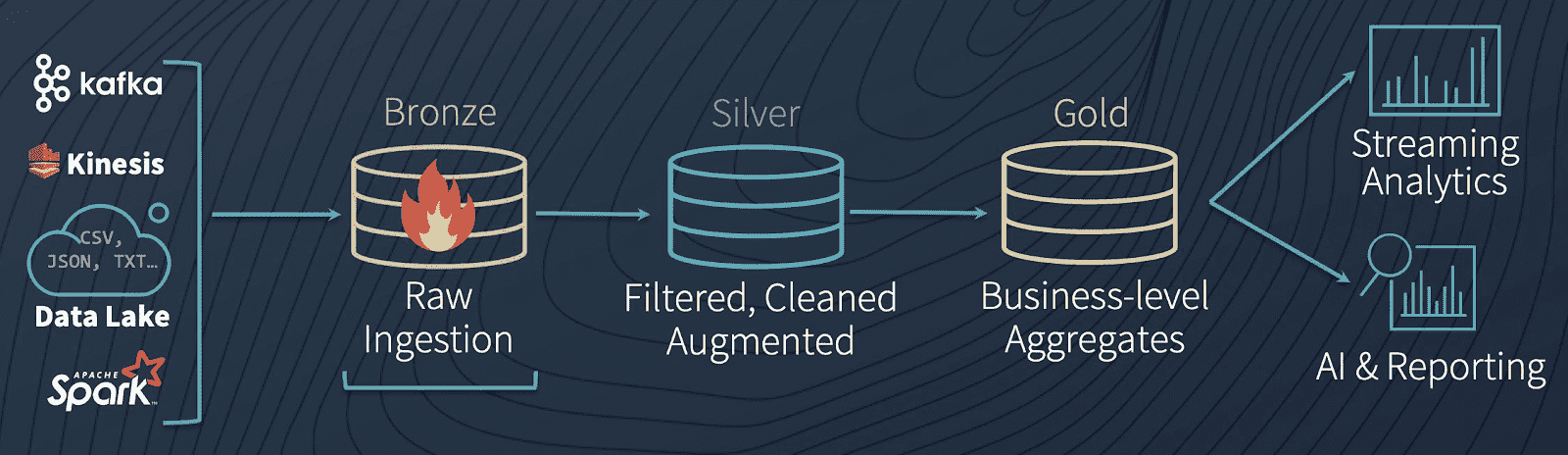
どのようにDelta Lakeがバッチとストリーミングデータを同時に処理できるのかをデモンストレーションするために、以下のコードを見てみましょう。DELTALAKE_FILE_PATHフォルダーから初期データセットをDelta Lakeテーブルにロード(以前のコードブロックに示しています)した後で、テーブルに新規データを流し込む前に、現在のデータに対するバッチクエリーを実行するために、慣れ親しんだSQLシンタックスを使用することができます。
%sql
SELECT addr_state, SUM(`count`) AS loans
FROM loan_by_state_delta
GROUP BY addr_state
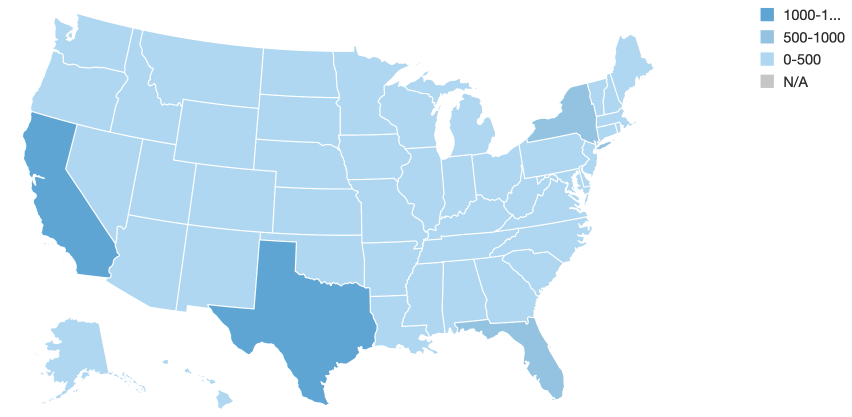
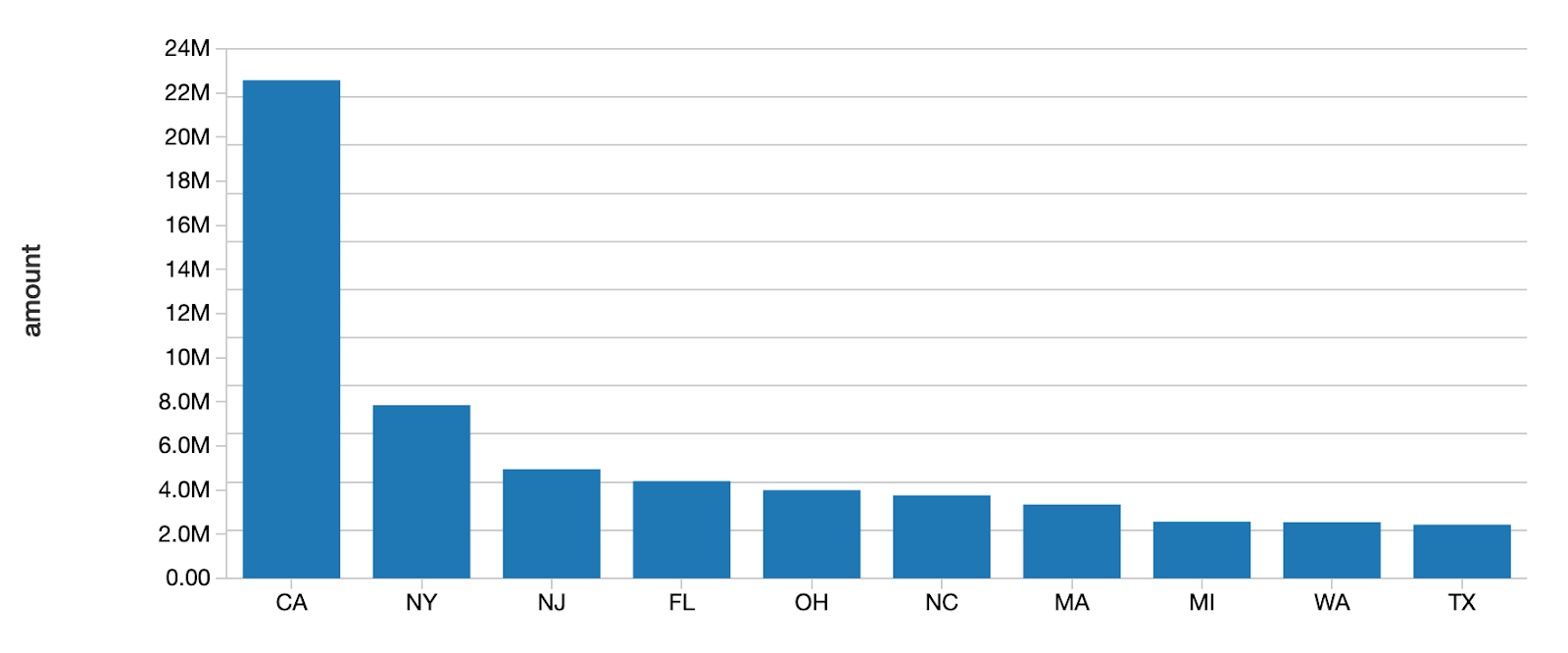
上で確認できるように、初期状態においてはカリフォルニアとテキサスで高いローンの値を示しています。
Delta Lakeのバッチクエリーを実行できる能力をデモンストレーションしたので、次のステップは同時にストリーミングデータに対してクエリーを実行できる能力を説明します。
Delta Lakeに新規データを追加し続けるストリーミングデータソースを作成し、上でプロットした既存バッチデータと統合します。以前のコードブロックでバッチクエリーが行ったのと同じ場所DELTALAKE_FILE_PATHからloan_by_state_readStreamがどのように読み込みを行っているのかに注意してください。
loan_by_state_readStream = spark.readStream.format("delta").load(DELTALAKE_FILE_PATH)
loan_by_state_readStream.createOrReplaceTempView("loan_by_state_readStream")
効率的にバッチとストリーミングデータを同じ場所(DELTALAKE_FILE_PATH)に取り込むことができ、Delta Lakeは両方のタイプのデータに対するクエリーに同時に対応することできます。これがDelta Lakeテーブルによる「バッチ・ストリーミングのソース・シンクの統合」です。
Delta Lakeではストリームを処理するので、あなたの目の前でビジュアライゼーションが更新され、異なるパターンが生じる様子を確認することができます。
最新のストリームデータによれば、アイオワ(中西部の州の色が濃くなっています)が最大のローンとなっていることがわかります。loan_by_state_deltaテーブルは、loan_by_state_readStreamを用いて新規データがストリームとしてテーブルに流れ込み続けていく際にも更新されます。
Delta Lakeを用いることで信頼性高くバッチ、ストリーミングのソースデータを同時に取り扱えることを見ましたので、次のステップにおいては、機械学習ジョブに使用できるようにいくつかのデータクレンジング、変換処理、特徴量エンジニアリングを行っていきます。
Delta Lakeによる高品質特徴量ストアの作成
データクレンジング、変換処理
ここまでを通じて、無事にデータをDelta Lakeフォーマットに変換し、履歴データ、リアルタイムデータをシームレスに処理するためのランディングゾーンとして動作するブロンズテーブルを作成しました。現時点では、データは正しい場所にありますが、現在の状態では使えるものとは言えません。多大なクレンジング、変換処理、そして、機械学習モデルで使用する前に構造化を行う必要があります。MLモデリングライブラリはデータタイプ、null値、欠損値に対する柔軟性はそれほど提供しません(あったらいいのですが!)ので、生データの処理、クレンジングがデータエンジニアの次の作業になります。Delta LakeはApache Sparkと100%互換性があるので、以下のようにSparkの慣れ親しんだAPIを用いてDelta Lakeのコンテンツに対するデータ加工を行うことができます。
print("Map multiple levels into one factor level for verification_status...")
loan_stats = loan_stats.withColumn('verification_status', trim(regexp_replace(loan_stats.verification_status, 'Source Verified', 'Verified')))
print("Calculate the total amount of money earned or lost per loan...")
loan_stats = loan_stats.withColumn('net', round( loan_stats.total_pymnt - loan_stats.loan_amnt, 2))
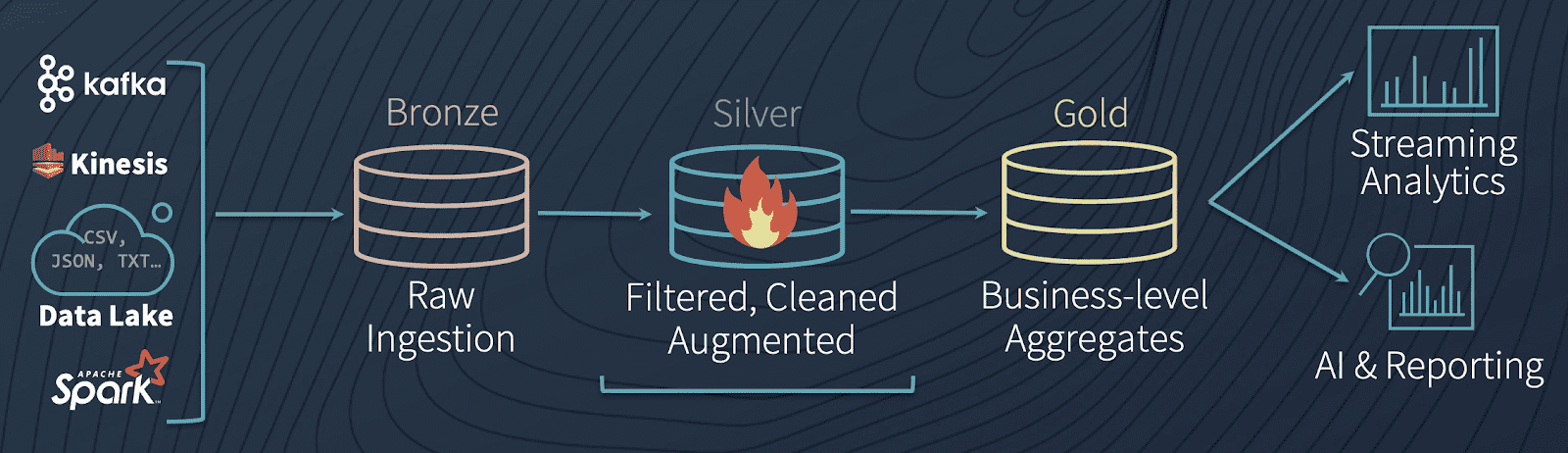
ETLを実行した後で、オリジナルのデータを変更することなしに、新たなDelta Lakeのシルバーテーブルにクレンジングされた、処理されたデータを保存することができます。
中間ステップの重要性
異なるビジネスユニット、ユーザーによって制御される複数の後段のゴールドテーブルのソースとして動作する中間のシルバーテーブルは重要となります。例えば、サプライチェーンのダッシュボードの更新、営業員のボーナス支払いの計算、経営層に対するハイレベルのKPIの提供など異なる用途向けのいくつかのゴールドテーブルにつながる「Product Sales」を表現するシルバーテーブルをイメージすることができます。
ブロンズテーブルに保持されている生データをゴールドテーブルに直接接続しない理由は、これによって重複する多大な労力が必要になるためです。この場合、それぞれのビジネスユニットがデータに対して同じETLを行う必要があります。そうではなく、確実に一度だけ実行することになります。副次的な効果として、このステップにより、別のビジネスユニットが同じメトリクスを若干異なるロジックで計算してしまうなど、データを派生させることによる混乱を避けることができます。
この設計図に従うことで、最終的なゴールドテーブルに保存、流れ込むデータがクリーンかつ一貫性があることを保証できます。
スキーマ強制
データを変換したので、次のステップはスキーマを強制することでDelta Lakeのシルバーテーブルに構造を導入することになります。スキーマ強制は、テーブルを汚れひとつない状態に保つことができるため、データサイエンティスト、データエンジニアにとって重要な機能となります。スキーマ強制なしには、あるカラムに異なるデータ型が混入してしまい、データの信頼性に大きな災厄をもたらします。例えば、FloatTypeデータのカラムに間違ってStringTypeを持ち込んでしまうと、機械学習モデルでは二度と読み込めなkなってしまい、我々の素晴らしいデータパイプラインを破壊してしまうことになります。
Delta Lakeは書き込み時のスキーマ検証を行います。これは、テーブルに新規レコードを書き込む際に、Delta Lakeが事前定義済みのスキーマにレコードが合致しているかどうかをチェックすることを意味します。レコードがテーブルスキーマに一致しない場合、Delta Lakeは例外を起こし、競合するデータタイプでカラムを汚染してしまうことを防ぎます。このアプローチは、データタイプの汚染がカラムに生じてしまうと、「魔神をボトルに戻す」ことは難しいため、読み取り時のスキーマ検証よりも好ましいものとなります。
Delta Lakeはスキーマのテー技を容易にし、以下のコードを用いることで強制することができます。テーブルのスキーマにマッチしないため、入力データがどのようにリジェクトされているのかに注意してください。
# Generate sample loans with dollar amounts
loans = sql("select addr_state, cast(rand(10)*count as bigint) as count, cast(rand(10) * 10000 * count as double) as amount from loan_by_state_delta")
display(loans)
# Let's write this data out to our Delta table
loans.write.format("delta").mode("append").save(DELTALAKE_SILVER_PATH)
// AnalysisException: A schema mismatch detected when writing to the Delta table.
誤ったデータタイプを含むカラムによるエラーではなく、現状のスキーマには反映されていない新たなカラムを(意図的に)追加したことによるエラーである場合、後ほど説明するスキーマエボリューションを用いることでエラーを修正し、カラムを追加することができます。
ここまでのステージでデータがスキーマ強制を通過したら、Delta Lakeのゴールドテーブルとして最終形態を保存することができます。これで完全にきれいで変換され、機械学習モデルで利用できる状態になりました。どのようにデータが構造化されるかがこんなに大変だとは!ブロンズ、シルバーテーブルと生データからデータが流れていくことで、全ての新規データを受け取り、MLで利用できる状態に変換する再現可能なデータサイエンスパイプラインをセットアップしました。これらのストリームは、従来のパイプラインにおけるスケジュール、ジョブ管理の必要性を排除し、低レーテンシーあるいはマニュアルで実行することができます。
Delta LakeのタイムトラベルとMLflowによる実験の再現
ここまでで、データを変換し、スキーマ強制による構造の追加を行い、データに対して実験を開始し、モデルを構築する準備が整いました。ここでまさにデータサイエンスの「サイエンス」が行われるのです。ここで帰無仮説、代替仮説を作成し、モデルの構築、テストを行い、モデルがどれだけうまく依存変数を予測できるのかを計測します。本当にこのステージで我々の多くが輝くのです!
データサイエンティストは再現可能な実験を行える必要があります。再現性は科学的問いの全ての土台となります。観測が検証、再検証、そして再現されないのであれば、真実に近づくことは不可能です。さらに、同じ問題にアプローチするための方法があまりにたくさんあったら、我々の誰が厳密な線形の進捗を出すことができるのでしょうか?
ほとんどの人は、物事を勧める際に使用できる「魔法」のようなものはほとんど存在せず、目的地に到達するためには不確実性のある、そして、遠回りの道のりを辿って探究を進めなくてはならないと信じています。そしてこれは、この狂気に対してわずかな科学的手法を加えることで、我々の作業を明らかにし、ステップを再追跡可能にし、後ろにパンク図を残すことができるツールを持っている限り、問題のないことです。Delta LakeのタイムトラベルとMLflowを用いることで、上述したすべてが全て実現します。
Delta Lakeのタイムトラベル
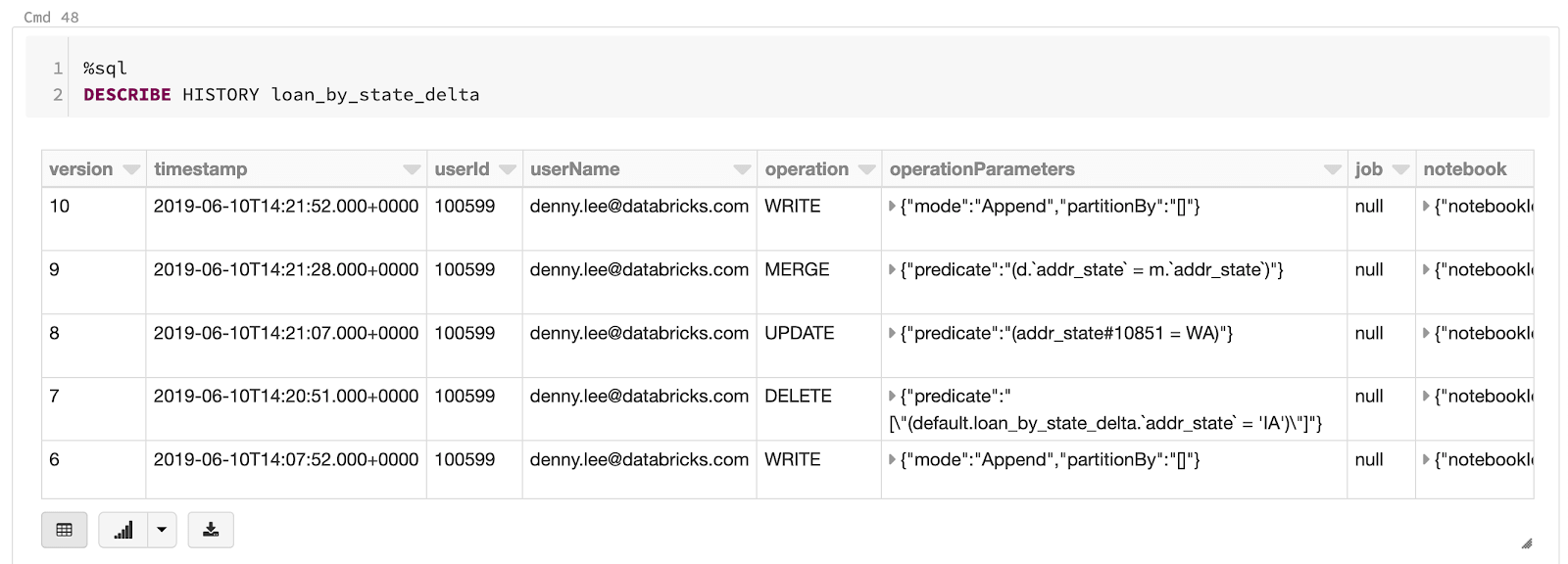
データサイエンティストにとって、Delta Lakeの最も有用な機能は、データバージョン管理機能、「タイムトラベル」を用いて任意の時間に戻すことができる機能です。Delta LakeはあらゆるDelta ぁけテーブルで実行された全てのオペレーションのトランザクションログを保持するので、以前のバージョンのテーブルに戻したいのであれば、意図しないオペレーションを取り消したり、単に任意の断面のデータを見ることができます。
以前のバージョンのテーブルのデータを参照するためにタイムトラベルを使用するのは簡単です。ユーザーはテーブルの履歴を参照でき、バージョン履歴番号(以下のコードのように、テーブルにSELECTを行う際にloan_by_state_delta VERSION AS OF 0を指定)やタイムスタンプを用いて任意のタイミングのデータがどのように見えるのかを確認することができます。
%sql
DESCRIBE HISTORY loan_by_state_delta
以前のバージョンのテーブルをSELECTするには、以下のように馴染み深いSQLシンタックスを使用できます。
%sql
SELECT * FROM loan_by_state_delta VERSION AS OF 0
バージョン番号の代わりに、特定の時点におけるデータがどのように見えるのか「データのスナップショット」を取得するためにタイムスタンプを使用することも可能です。
%sql
SELECT * FROM loan_by_state_delta TIMESTAMP AS OF '2019-07-14 16:30:00'
MLflowと組み合わせることで、Delta Lakeのタイムトラベルは、あなたがデータに対して行う全ての変換処理、エクスペリメントを追跡可能、再現可能、そして可逆なものにします。これによって以下のようなことが可能となります。
- 特定の時点におけるデータセット、テーブルの状態を再現(データの「スナップショット」を作成)
- トレーニングデータセット、テストデータセットを再現し、実験を再現
- テーブルに対する意図しない変更や変換処理をロールバック
トランザクションログが検証可能なデータリネージュを作成するので、特にGRC(ガバナンス、リスク、コンプライアンス)のアプリケーションにおいては有用です。GDPRやCCPAのような規制に対して、企業はデータが適切に削除、匿名化されていること(全体、あるいは個人レベル)を証明する能力を必要とします。全てのアップデート、マージ、デリート、インサートなどは監査目的で確認、検証することができます。
最後に、タイムトラベルを用いることで誤った行の削除、列の計算ミスのようなヒューマンエラーは100%元に戻すことができるので、データエンジニアは安心して眠れるようになります。マーフィーの法則においては、全ての物事は悪い方向にいくと述べており、データパイプラインも例外ではありません。ヒューマンエラーによって間違いは必ず起きます。ハードウェア障害よりも人の手によって誤ってテーブルを編集してしまうことによるデータ損失の可能性が高く、これらの間違いを取り消すことはできません。
トランザクションログが役立つ別の方法は、調査しているエラーのデバックが容易になるということです。任意のタイミングに戻ることができるので、どのように問題が生じ、修正されたのか、あるいはデータセットを復旧したのかを確認することができます。
MLflowにおけるエクスペリメント、アーティファクトの追跡

MLflowはDelta Lakeと連携しつつ、データサイエンティストが苦労することなしに、メトリクス、パラメーター、ファイル、画像アーティファクトを記録できるようにするオープンソースのPythonライブラリです。ユーザーは異なる複数のエクスペリメントを実行し、入出力が記録されることを知りながら、必要に応じて変数やパラメーターを変更していきます。異なるハイパーパラメータの組み合わせで実験を行う際、トレーニング後にベストなモデルをピックアップできるように、トレーニングされたモデルを自動で記録することも可能です。
Databricksにおいては、MLflowはMLR 5.5以降で自動で有効化されているので、以下のようにMLflow Runsサイドバーを用いてMLflowのrunを参照することができます。
スキーマエボリューションによる新規・変更要件に対応するためのデータパイプラインの導入
多くのケースで、データエンジニアとデータサイエンティストはデータパイプラインの初期構築は維持管理よりも簡単であることを知ります。変化し続けるビジネス要件、ビジネスの定義、製品のアップデート、時系列データの特性のため、テーブルスキーマの変更は不可避であり、これらの変更を容易に管理できるツールの使用が重要となります。Delta lakeはスキーマ矯正のためのツールだけではなく、以下のようにmergeSchemaオプションを用いたスキーマエボリューションを提供します。
# Add the mergeSchema option
loans.write.option("mergeSchema","true").format("delta").mode("append").save(DELTALAKE_SILVER_PATH)
%sql
-- Review current loans within the `loan_by_state_delta` Delta Lake table
SELECT addr_state, sum(`amount`) AS amount
FROM loan_by_state_delta
GROUP BY addr_state
ORDER BY sum(`amount`)
DESC LIMIT 10
クエリーに.option("mergeSchema","true")を追加することで、データフレームに存在するが、ターゲッットのDelta Lakeテーブルに存在しない全てのカラムは、書き込みトランザクションの一部として自動で追加されます。データエンジニアとデータサイエンティストは従来のカラムを使用している既存モデルを破壊することなしに、既存の機械学習プロダクションテーブルに新規カラム(おそらく、新規に追跡するメトリクス、月の売り上げのカラムなど)を追加する際に、このオプションを使用することができます。
全てを試してみる: Delta Lakeテーブルから機械学習モデルを構築
MLflowがバックグラウンドでパラメーターと結果を記録してくれるので、データをトレーニングデータセットとテストデータセットに分割し、機械学習モデルをトレーニングする準備が整いました。我々はすでに、シルバーデータからデータを取得し、最終テーブルの全てのデータにはエラーがなくきれいな状態であることを確実にするためにスキーマを強制することで、モデルトレーニングに用いるゴールドテーブルを作成しています。冒頭でご紹介した「マルチホップ」アーキテクチャを用いてパイプラインを構築し、新規データが継続的にパイプラインに流れ込み、中間テーブルで処理、保存されていくようにします。
機械学習ライフサイクルを完成させるために、ここでは以下に示す一部省略されたコードのように、標準化、交差検証を用いてGLMモデルのグリッドを構築します。ここでのゴールは、ローン返済者が完済したかデフォルトしたかを予測するというものです。完全なコードはこちらからアクセスできます。
# Use logistic regression
lr = LogisticRegression(maxIter=10, elasticNetParam=0.5, featuresCol = "scaledFeatures")
# Build our ML pipeline
pipeline = Pipeline(stages=model_matrix_stages+[scaler]+[lr])
# Build the parameter grid for model tuning
paramGrid = ParamGridBuilder() \
.addGrid(lr.regParam, [0.1, 0.01]) \
.build()
# Execute CrossValidator for model tuning
crossval = CrossValidator(estimator=pipeline,
estimatorParamMaps=paramGrid,
evaluator=BinaryClassificationEvaluator(),
numFolds=5)
# Train the tuned model and establish our best model
cvModel = crossval.fit(train)
glm_model = cvModel.bestModel
# Return ROC
lr_summary = glm_model.stages[len(glm_model.stages)-1].summary
display(lr_summary.roc)
Receiver Operating Characteristic(ROC)曲線の結果プロットは以下のようになります。
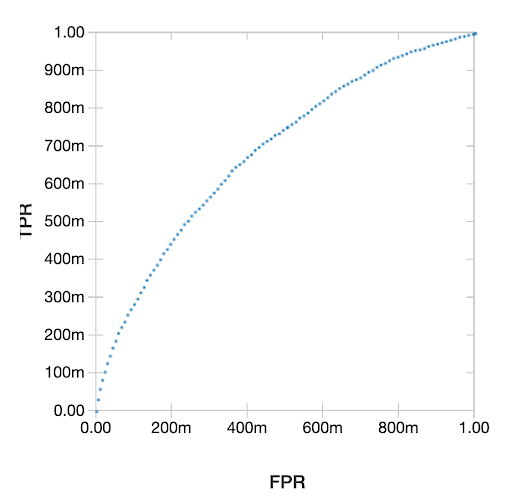
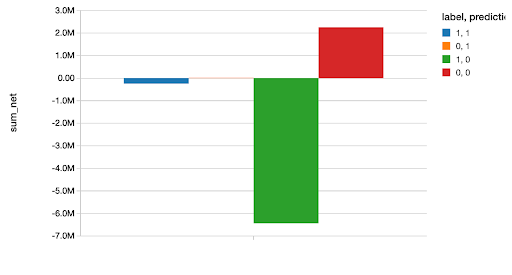
こちらにあるように、完全なノートブックでは他のいくつかの一般化線形モデルとこのモデルの比較を行っています。ベストなモデル(XGBoostモデル)を選択した後で、テストデータセットに対する予測を行い、正しい、あるいは間違った分類それぞれに基づいて、我々が節約できた、あるいは失ったお金の総量をプロットしています。データサイエンティストは知っていることですが、分析結果を明確かつ理解しやすくするために、このように分析結果をお金で表現することは常に素晴らしいアイデアです。
display(glm_valid.groupBy("label", "prediction").agg((sum(col("net"))).alias("sum_net")))
このサンプルのScalaバージョンに関しては、こちらのブログ記事が詳しいです。
まとめ
Delta Lakeは、データサイエンス、データエンジニアリング、プロダクションワークフローを統合する機能を提供するため、機械学習ライフサイクルにとって理想的なものとなります。生データから構造化された形に継続的にデータを流し込むことを可能とし、既存のプロダクションモデルが予測を行っている間であっても、新鮮なデータに対して新たなMLモデルをトレーニングすることが可能となります。機械学習が処理を行う際にデータが必要なフォーマットになっていることを保証するスキーマ強制、既存のプロダクションモデルを破壊することなしにスキーマを変更できるスキーマエボリューションを提供します。最後に、トランザクションログによって提供される「タイムトラベル」というバージョン管理機能によって、データの変更を監査、再現可能にし、必要に応じてロールバックすることが可能となります。
まとめると、Delta Lakeのこれらの機能は、データエンジニア、データサイエンティストがこれまで以上に迅速に高信頼、回復力の高い、自動化されたデータパイプラインと機械学習モデルを設計できるようにすることで、次の一歩を踏み出せるようにします。
関連コンテンツ
詳細に関しては、ウェビナーGetting Data Ready for Data Scienceをご覧ください。
